谷歌AI绘画4大牛携手创业,天使估值7个亿
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了谷歌AI绘画4大牛携手创业,天使估值7个亿相关的知识,希望对你有一定的参考价值。
衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
最近的谷歌像个大漏勺,这不,又有AIGC核心成员联手跑路咯!
量子位独家获悉,这回跟谷歌say byebye的,是文生图核心团队——AI绘画模型Imagen论文的四位核心作者,出走目的是要搞自己的AI公司。虽然公司名称暂未对外公布,但新公司将一以贯之的路线是很清楚的:
以Imagen为基础,沿着原来的项目做下去,不仅继续做文生图,还要做视频方向。
核心人才创业,自然少不了VC塞钱——已经按1亿美元的惊人天使估值完成了首轮融资,而且更多VC想给钱而赶不上、投不进。

这也算是文生图、文生视频、AIGC赛道上,最知名的研究团队之一了。
文生图骨干成员共创AIGC新公司
新公司联创四人,Chitwan Saharia、William Chan、Jonathan Ho以及Mohammad Norouzi,都出自谷歌。
他们之前精力重点放在AIGC的文生图板块,是谷歌用来对抗DALLE-2的大杀器Imagen的论文共同作者,位置都挺重要的那种。

先来介绍一下Chitwan Saharia,也是Imagen的共同一作。

Chitwan本科毕业于孟买理工学院计算机科学与工程专业,在孟买理工学院和蒙特利尔大学都当过程序和算法方面的研究助理。2019年加入谷歌,base多伦多,花了3年时间从二级软件工程师做到高级研究科学家,去年12月从谷歌离职。
Chitwan有语音识别、机器翻译的经验,在谷歌工作时,主要负责领导image-to-image扩散模型的工作。
第二位William Chan,也是Imagen论文共同一作。他同样出身计算机工程,先后就读于加拿大滑铁卢大学、卡内基梅隆大学,中间在新加坡国立大学当过1年交换生。

在卡内基梅隆大学拿下博士学位后,William还在加拿大最大的社区学院之一乔治布朗学院,主攻烘焙和烹饪(?),学了3年。
Willian从2012年起加入谷歌,于2016年成为谷歌大脑的一份子,去年5月离职时,他已经是谷歌大脑多伦多的研究科学家了。
然后要介绍的是Jonathan Ho,UC伯克利博士毕业。
他不仅是Imagen论文的core contribution,还是Diffusion Model奠基之作《Denoising Diffusion Probabilistic Models》的一作。

博士毕业于UC伯克利计算机科学专业的Jonathan,之前在OpenAI当过1年的研究科学家,后来在2019年加入谷歌,共工作了2年零8个月,去年11月以研究科学家的身份从谷歌离职。
新公司的最后一位联创叫Mohammad Norouzi,也是Imagen论文的共同一作。

△Mohammad Norouzi
他在多伦多大学计算机科学博士就读期间,拿到了谷歌ML博士奖学金。毕业后他加入谷歌大脑,在那儿工作了7年,在谷歌的最后title是高级研究科学家,工作重点是生成模型。
同时,Mohammad也是谷歌神经机器翻译团队的原始成员,SimCLR的联合发明人。他在GitHub主页上小小地透露了自己的最近动态:
目前,我在一家初创公司工作,公司使命是推进人工智能的发展水平,帮助人类提高创造力。
我们正在招聘!
这句话以外,关于新公司的更多信息,四人在任何社交平台都没有更详细的透露。
这已经是谷歌最近漏出去的第n波人了。
就拿刚刚过去的2个月来说,先是包括顾世翔(Shane Gu,‘让我们一步一步地思考’研究者)在内的至少4名谷歌大脑成员加入OpenAI;情人节时,Hyung Won Chung和CoT最早的一作Jason Wei携手组团叛逃OpenAI。
本周三,您猜怎么着?嘿,又跑了一个:
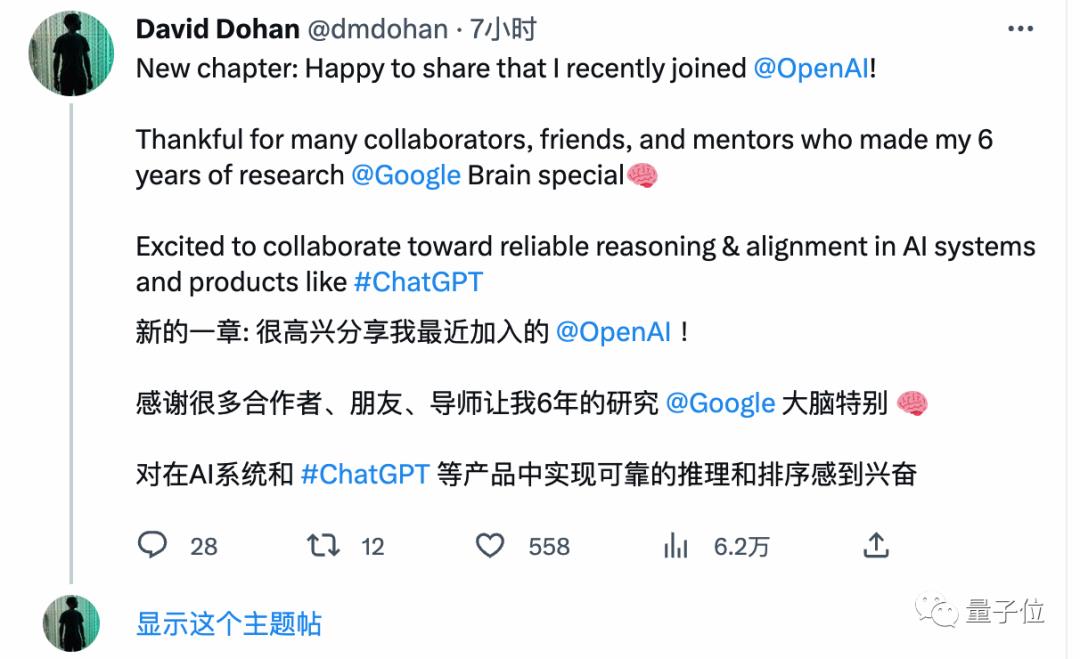
OpenAI狂喜,只有谷歌大漏勺本勺受伤的世界诞生了。
Imagen是什么?
了解完谷歌漏走的这四个人,回头来说说为他们职业生涯赢得掌声的Imagen项目。
Imagen是谷歌发布的文生图模型,发布时间在DALL-E 2新鲜出炉一个月以后。
本文开头放的熊猫震惊表情包,就是朝Imagen输入“一只非常快乐的毛茸熊猫打扮成了在厨房里做面团的厨师的高对比度画像,他身后的墙上还有一幅画了鲜花的画”后,得出的一张要素完备的AI生成画作。
(不好意思,请自行断句)

在Imagen出现之前,文生图都共用一个套路,那就是CLIP负责从文本特征映射到图像特征,然后指导一个GAN或Diffusion Model生成图像。
Imagen不走寻常路,开辟了text-to-image新范式:
纯语言模型只负责编码文本特征,具体text-to-image的工作,被Imagen丢给了图像生成模型。
具体来讲,Imagen包含一个冻结的语言模型T5-XXL(谷歌自家出品),当作文本编码器。T5-XXL的C4训练集包含800GB的纯文本语料,在文本理解能力上比CLIP强不少,因为后者只用有限图文对训练。
图像生成部分则用了一系列扩散模型,先生成低分辨率图像,再逐级超采样。

依赖于新的采样技术,Imagen允许使用大的引导权重,所以不会像原有工作一样使样本质量下降。这么一来,图像具有更高的保真度,并且能更好地完成图像-文本对齐。
概念说起来简单,但Imagen的效果还是令人大为震撼的。
生成的狗子飙车技术一流:

比起爆火的DALLE-2,Imagen能更准确地理解同时出现两个颜色要求的情况:

一边绘画一边写字这种要求,Imagen也成功完成,不仅写得对,还能加光影魔术手般的烟花特效(不是)。

以及对后来研究更有帮助的是,谷歌通过Imagen的研究,优化了扩散模型。
首先,增加无分类器引导(classifier-free guidance)的权重可以改善图文对齐,同时却会损害图像保真度。
为了解决这个bug,在每一步采样时引入动态阈值(dynamic thresholding)这个新的新的扩散采样技术,来防止过饱和。

第二,使用高引导权重的同时在低分辨率图像上增加噪声,可以改善扩散模型多样性不足的问题。
第三,对扩散模型的经典结构U-Net做了改进,变成了Efficient U-Net。后者改善了内存使用效率、收敛速度和推理时间。
后来在Imagen上微调,谷歌还推出了能“指哪打哪”版本的文生图模型DreamBooth。只需上传3-5张指定物体的照片,再用文字描述想要生成的背景、动作或表情,就能让指定物体“闪现”到你想要的场景中。
比如酱婶儿的:

又或者酱婶儿的:

大概是Imagen效果太过出色,劈柴哥后来亲自宣发的谷歌AI生成视频选手大将,就叫做“Imagen Video”,能生成1280*768分辨率、每秒24帧的视频片段。
啊,等等,谷歌有Imagen Vedio,这和四人的新公司不是撞方向了吗?
仔细看了下论文,无论是Imagen还是Imagen Video,各自都有大篇幅涉及风险、社会影响力的内容。
出于安全、AI伦理和公平性等方面考虑,Imagen和Imagen Vedio都没有直接开源或开放API,甚至连demo都没有。

哪怕市面上出现开源复刻版本,也不是最正宗的味道。
此前就曝出过在谷歌每年的内部员工调查“Googlegeist”中,员工表示对谷歌执行能力不佳的质疑。也许,这四人出走,继续做Imagen,并做Imagen的视频版,说不定就是为了想把项目放到一个更开放的AI环境。
而且这种出走创业,也是热钱大钱向AIGC汹涌的结果。
所以既然AIGC的创投热潮已经在太平洋那头开启,那应该在太平洋这头也不会悄无声息。
或许你已经听说了一些同样的大厂出走创业,欢迎爆料说说~~
— 联系作者 —

— 完 —
「中国AIGC产业峰会」启动
邀您共襄盛举
「中国AIGC产业峰会」即将在今年3月举办,峰会将邀请AIGC产业相关领域的专家学者,共同探讨生成新世界的过去、现在和未来。
峰会上还将发布《中国AIGC产业全景报告暨AIGC 50》,全面立体描绘我国当前AIGC产业的竞争力图谱。点击链接或下方图片查看大会详情:
寻找中国版ChatGPT,量子位邀你共同参与中国AIGC产业峰会

点这里👇关注我,记得标星哦~
以上是关于谷歌AI绘画4大牛携手创业,天使估值7个亿的主要内容,如果未能解决你的问题,请参考以下文章