Python采集某手视频,1080P高清无水印,完整数据来源分析+完整代码
Posted 松鼠爱吃饼干
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python采集某手视频,1080P高清无水印,完整数据来源分析+完整代码相关的知识,希望对你有一定的参考价值。
知识点
- 动态数据抓包
- 动态页面分析
- requests携带参数发送请求
- json数据解析
开发环境
- python 3.8 更加新 稳定 运行代码
- pycharm 2021.2 辅助敲代码
- requests 第三方模块
一. 数据来源分析(思路分析)
1. 打开开发者工具刷新网页
-
右键点击检查 或者 F12 打开
-
选择network 然后刷新网页

-
随便点击打开一个视频

-
点击搜到的内容

-
依次展开查看, 去找到我们需要的视频地址

2. 确定url地址, 请求方式, 请求参数, 请求头参数
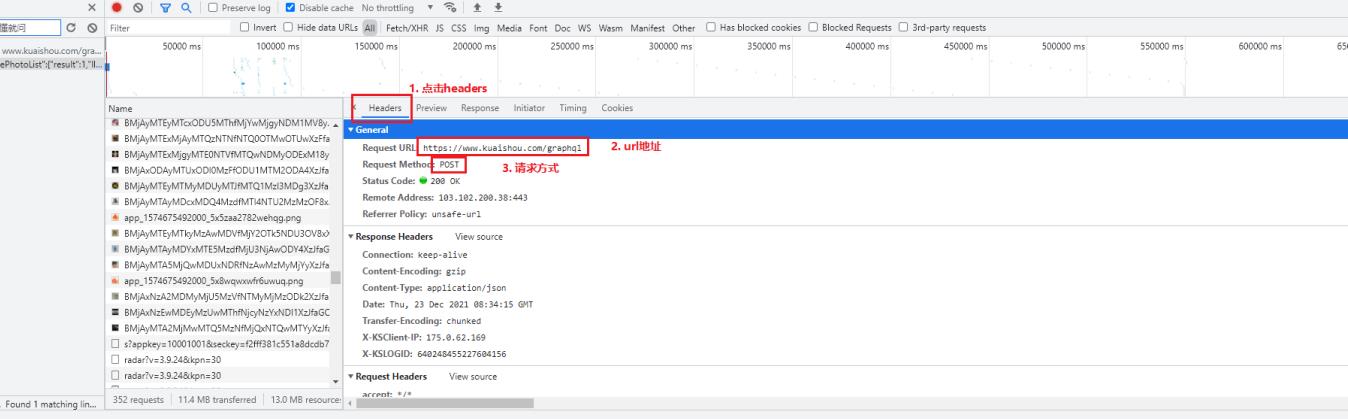
-
请求头参数
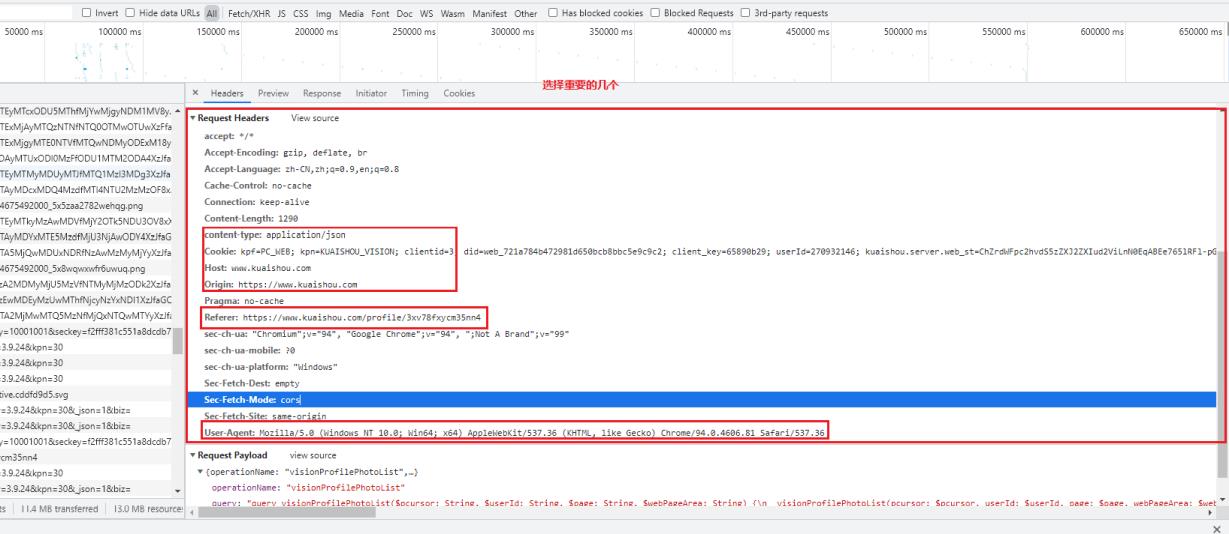
-
请求参数
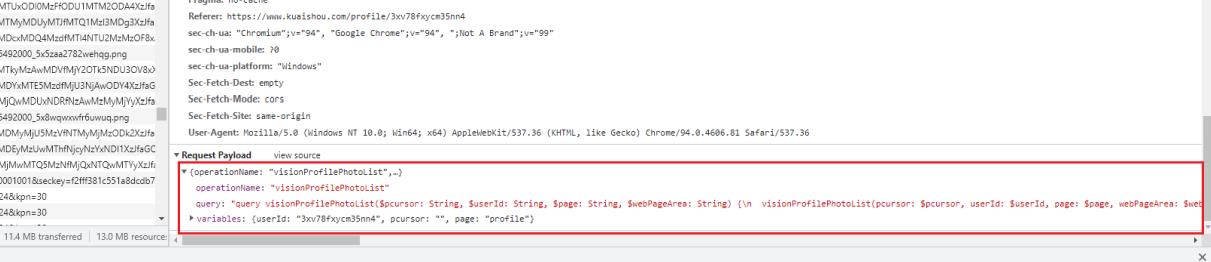
3. 总结
- 请求方式: POST
- 请求头(伪装):
headers =
'content-type': 'application/json',
'Cookie': '你自己的cookie',
'Host': 'www.kuaishou.com',
'Origin': 'https://www.kuaishou.com',
'Referer': 'https://www.kuaishou.com/profile/3xv78fxycm35nn4',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
(Khtml, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
- 请求参数:
data =
'operationName': "visionProfilePhotoList",
'query': "query visionProfilePhotoList($pcursor: String, $userId: String, $page:
String, $webPageArea: String) \\n visionProfilePhotoList(pcursor: $pcursor, userId:
$userId, page: $page, webPageArea: $webPageArea) \\n result\\n llsid\\n
webPageArea\\n feeds \\n type\\n author \\n id\\n name\\n
following\\n headerUrl\\n headerUrls \\n cdn\\n url\\n
__typename\\n \\n __typename\\n \\n tags \\n type\\n
name\\n __typename\\n \\n photo \\n id\\n
duration\\n caption\\n likeCount\\n realLikeCount\\n
coverUrl\\n coverUrls \\n cdn\\n url\\n __typename\\n
\\n photoUrls \\n cdn\\n url\\n __typename\\n
\\n photoUrl\\n liked\\n timestamp\\n expTag\\n
animatedCoverUrl\\n stereoType\\n videoRatio\\n
profileUserTopPhoto\\n __typename\\n \\n canAddComment\\n
currentPcursor\\n llsid\\n status\\n __typename\\n \\n hostName\\n
pcursor\\n __typename\\n \\n\\n",
'variables': 'userId': "3x9dquvtb9n9fps", 'pcursor': "", 'page': "profile"
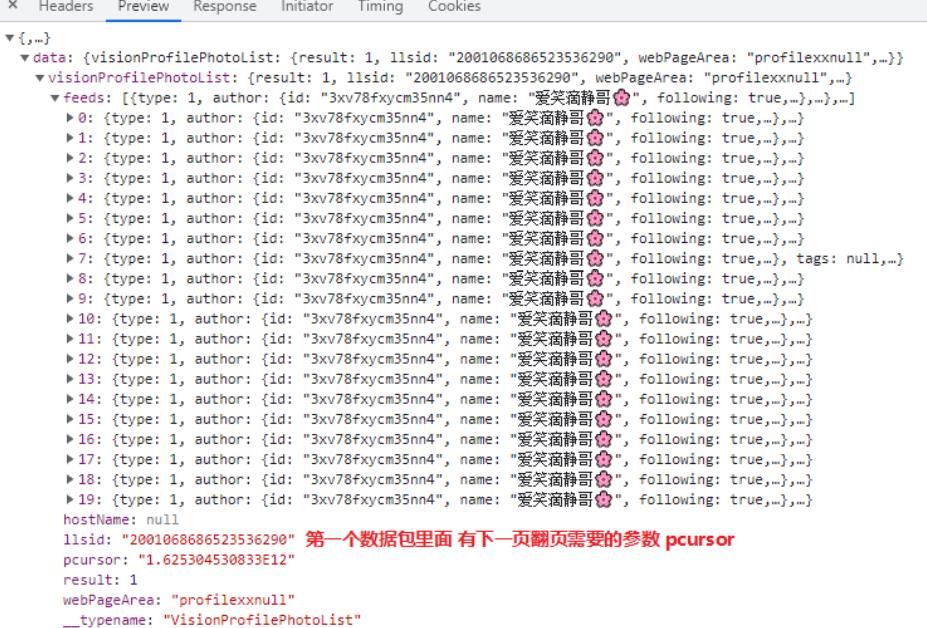
- 后续如果需要翻页爬取, 需要使用递归实现
二. 代码实现
1. 发送请求 访问网站
url = 'https://www.kuaishou.com/graphql'
# 伪装
headers =
# 控制data类型 json类型字符串
'content-type': 'application/json',
'Cookie': 'kpf=PC_WEB; kpn=KUAISHOU_VISION; clientid=3; did=web_ea128125517a46bd491ae9ccb255e242; client_key=65890b29; userId=270932146; kuaishou.server.web_st=ChZrdWFpc2hvdS5zZXJ2ZXIud2ViLnN0EqABnjkpJPZ-QanEQnI0XWMVZxXtIqPj-hwjsXBn9DHaTzispQcLjGR-5Xr-rY4VFaIC-egxv508oQoRYdgafhxSBpZYqLnApsaeuAaoLj2xMbRoytYGCrTLF6vVWJvzz3nzBVzNSyrXyhz-RTlRJP4xe1VjSp7XLNLRnVFVEtGPuBz0xkOnemy7-1-k6FEwoPIbOau9qgO5mukNg0qQ2NLz_xoSKS0sDuL1vMmNDXbwL4KX-qDmIiCWJ_fVUQoL5jjg3553H5iUdvpNxx97u6I6MkKEzwOaSigFMAE; kuaishou.server.web_ph=b282f9af819333f3d13e9c45765ed62560a1',
'Host': 'www.kuaishou.com',
'Origin': 'https://www.kuaishou.com',
'Referer': 'https://www.kuaishou.com/profile/3xauthkq46ftgkg',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36',
# <Response [200]>: 发送请求成功结果
response = requests.post(url=url, headers=headers, json=data)
2. 获取数据
json_data = response.json()
3. 解析数据 去除不想要的内容
feeds = json_data['data']['visionProfilePhotoList']['feeds']
# 下一页需要的参数
pcursor = json_data['data']['visionProfilePhotoList']['pcursor']
# print(pcursor)
for feed in feeds:
caption = feed['photo']['caption'] # 标题
photoUrl = feed['photo']['photoUrl'] # 视频链接
# \\: 转义字符, 直接写\\ 匹配不到 \\
# \\\\ 才能匹配到 \\
# 用css和xpath 是必须要你拿到的数据是一个网页源代码
caption = re.sub('[\\\\/:*?"<>|\\n\\t]', '', caption)
print(caption, photoUrl)
5. 获取数据 视频数据 拿到的是视频二进制数据
video_data = requests.get(url=photoUrl).content
6. 保存视频 通过二进制的方式保存
with open(f'video/caption.mp4', mode='wb') as f:
f.write(video_data)
print(caption, '下载完成!')
翻页爬取
def get_page(pcursor):
# 需要的数据得指定好
# 递归, 自己调用自己 跳出递归
data =
'operationName': "visionProfilePhotoList",
'query': "query visionProfilePhotoList($pcursor: String, $userId: String, $page: String, $webPageArea: String) \\n visionProfilePhotoList(pcursor: $pcursor, userId: $userId, page: $page, webPageArea: $webPageArea) \\n result\\n llsid\\n webPageArea\\n feeds \\n type\\n author \\n id\\n name\\n following\\n headerUrl\\n headerUrls \\n cdn\\n url\\n __typename\\n \\n __typename\\n \\n tags \\n type\\n name\\n __typename\\n \\n photo \\n id\\n duration\\n caption\\n likeCount\\n realLikeCount\\n coverUrl\\n coverUrls \\n cdn\\n url\\n __typename\\n \\n photoUrls \\n cdn\\n url\\n __typename\\n \\n photoUrl\\n liked\\n timestamp\\n expTag\\n animatedCoverUrl\\n stereoType\\n videoRatio\\n profileUserTopPhoto\\n __typename\\n \\n canAddComment\\n currentPcursor\\n llsid\\n status\\n __typename\\n \\n hostName\\n pcursor\\n __typename\\n \\n\\n",
'variables': 'userId': "3xauthkq46ftgkg", 'pcursor': pcursor, 'page': "profile"
if pcursor == None:
print('全部下载完成')
return 0
get_page(pcursor)
get_page('')
效果展示



以上是关于Python采集某手视频,1080P高清无水印,完整数据来源分析+完整代码的主要内容,如果未能解决你的问题,请参考以下文章
Python怎么爬取Request UR动态api页面数据,怎么下1080P无水印视频?