Python怎么爬取Request UR动态api页面数据,怎么下1080P无水印视频?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python怎么爬取Request UR动态api页面数据,怎么下1080P无水印视频?相关的知识,希望对你有一定的参考价值。
问题1:每页只有16个视频,每次往下刷新页面,Request UR后面的时间ctime会变动,导致只能下载16个视频。
2:下载的视频都是2M左右的高清,请问怎么下载超清无水印的视频?
3:出现错误PEP 8: E501 line too long (1534 > 120 characters),请问有么影响?
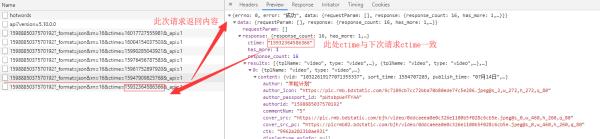
1、第一个问题:下一个的ctime来源于上一个的api返回内容中,所以导致你频繁在重复采集第一个页面数据;
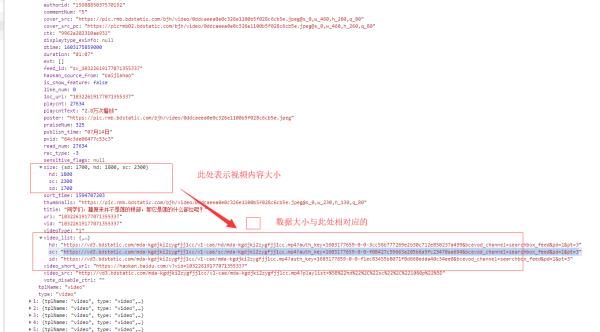
2、第二个问题:高清视频可以下载,但水印是必然存在,因为此处接口未提供无印视频,
3、第三个问题:pep8规范,就是说你那一行编写的太长了,好几千个字符串呢....其实不影响程序运行...
python爬取百度搜索结果ur汇总
写了两篇之后,我觉得关于爬虫,重点还是分析过程
分析些什么呢:
1)首先明确自己要爬取的目标
比如这次我们需要爬取的是使用百度搜索之后所有出来的url结果
2)分析手动进行的获取目标的过程,以便以程序实现
比如百度,我们先进行输入关键词搜索,然后百度反馈给我们搜索结果页,我们再一个个进行点击查询
3)思考程序如何实现,并克服实现中的具体困难
那么我们就先按上面的步骤来,我们首先认识到所搜引擎,提供一个搜索框,让用户进行输入,然后点击执行
我们可以先模拟进行搜索,发现点击搜索之后的完整url中有一项很关键,如下
http://www.baidu.com/s?wd=搜索内容......
后面的内容我们尝试去除之后再次请求上面的url,发现返回的信息一样,我们就可以断定请求的url只需要填入wd这个参数即可
接着我们就应该进行尝试requests.get()查看是否能正常返回页面,防止百度的反爬虫
嘿,幸运的是返回页面正常哈哈~
(当然如果没有返回到正常信息,只要设置好headers或者严格的cookies就行了)
import requests url = ‘http://www.baidu.com/s?wd=......‘ r = requests.get(url) print r.status_code,r.content
好,接下来我们就想知道怎么爬取所有的结果
我么再次对url进行分析,发现url中还有一项很关键,是控制页码的项:
http://www.baidu.com/s?wd=...&pn=x
这个x是每10为一页,第一页为0,而且一共76页,也就是750最大值,大于750则返回第一页
接下来我们就可以对抓取到的页面进行分析
还是使用友好的beautifulsoup
我们通过分析发现我们所需要的url在标签a中的href里,而且格式是这样:
http://www.baidu.com/link?url=......
因为还存在很多别的url混淆,所以我们只需要进行一个筛选就行了
而且这个获得的url并不是我们想要的url结果,这只是百度的一个跳转链接
但是让我欣慰的是,当我们队这个跳转链接进行get请求后,直接返回get对象的url便是我们想要的结果链接了
然后我们再次进行尝试,发现还是没有别的反爬虫机制哈哈
本来的想法是,我们是否要先进行一个对新的url返回的状态码进行一个筛选,不是200就不行(甚至还需要些headers)
但是我发现,其实就算不是200,我们只要返回请求对象的url就行了,和能不能正常返回没关系
因为我们的目的并不是请求的页面结果,而是请求的url
所以只需要全部打印出来就行了
当然我建议写一个简单的笼统的headers写入get,这样至少能排除一些不必要的结果
接着我们请求的完整思路就差不多了
上代码:
#coding=utf-8 import requests import sys import Queue import threading from bs4 import BeautifulSoup as bs import re headers = { ...... } class baiduSpider(threading.Thread): def __init__(self,queue,name): threading.Thread.__init__(self) self._queue = queue self._name = name def run(self): while not self._queue.empty(): url = self._queue.get() try: self.get_url(url) except Exception,e: print e pass #一定要异常处理!!!不然中途会停下,爬取的内容就不完整了!!! def get_url(self,url): r = requests.get(url = url,headers = headers) soup = bs(r.content,"html.parser") urls = soup.find_all(name=‘a‘,attrs={‘href‘:re.compile((‘.‘))}) # for i in urls: # print i #抓取百度搜索结果中的a标签,其中href是包含了百度的跳转地址 for i in urls: if ‘www.baidu.com/link?url=‘ in i[‘href‘]: a = requests.get(url = i[‘href‘],headers = headers) #对跳转地址进行一次访问,返回访问的url就能得到我们需要抓取的url结果了 #if a.status_code == 200: #print a.url with open(‘E:/url/‘+self._name+‘.txt‘) as f: if a.url not in f.read(): f = open(‘E:/url/‘+self._name+‘.txt‘,‘a‘) f.write(a.url+‘\n‘) f.close() def main(keyword): name = keyword f = open(‘E:/url/‘+name+‘.txt‘,‘w‘) f.close() queue = Queue.Queue() for i in range(0,760,10): queue.put(‘http://www.baidu.com/s?wd=%s&pn=%s‘%(keyword,str(i))) threads = [] thread_count = 10 for i in range(thread_count): spider = baiduSpider(queue,name) threads.append(spider) for i in threads: i.start() for i in threads: i.join() print "It‘s down,sir!" if __name__ == ‘__main__‘: if len(sys.argv) != 2: print ‘no keyword‘ print ‘Please enter keyword ‘ sys.exit(-1) else: main(sys.argv[1])
我们工具的功能就是:
python 123.py keyword
就能将url结果写入文件
这边sys我有话讲
在if __name__ == ‘__main__‘:中先进行一个判断,如果输入的字段是一个,那么我们就返回提醒信息,让用户进行键入
如果是两个,那么就将第二个键入记为keyword进行操作
当然这边逻辑有个缺陷,就是大于两个字符会不会有别的问题(别的问题哦!!!)
值得研究一下,但这不是我们这篇的重点
好啦,今天的百度url结果手收集就那么多啦!
谢谢观看哦!
以上是关于Python怎么爬取Request UR动态api页面数据,怎么下1080P无水印视频?的主要内容,如果未能解决你的问题,请参考以下文章