从Curator实现分布式锁的源码再到羊群效应
Posted SunAlwaysOnline
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从Curator实现分布式锁的源码再到羊群效应相关的知识,希望对你有一定的参考价值。
一、前言
Curator是一款由Java编写的,操作Zookeeper的客户端工具,在其内部封装了分布式锁、选举等高级功能。
今天主要是分析其实现分布式锁的主要原理,有关分布式锁的一些介绍或其他实现,有兴趣的同学可以翻阅以下文章:
我用了上万字,走了一遍Redis实现分布式锁的坎坷之路,从单机到主从再到多实例,原来会发生这么多的问题
在使用Curator获取分布式锁时,Curator会在指定的path下创建一个有序的临时节点,如果该节点是最小的,则代表获取锁成功。
接下来,在准备工作中,我们可以观察是否会创建出一个临时节点出来。
二、准备工作
首先我们需要搭建一个zookeeper集群,当然你使用单机也行。
在这篇文章面试官:能给我画个Zookeeper选举的图吗?,介绍了一种使用docker-compose方式快速搭建zk集群的方式。
在pom中引入依赖:
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.12.0</version>
</dependency>Curator客户端的配置项:
/**
* @author qcy
* @create 2022/01/01 22:59:34
*/
@Configuration
public class CuratorFrameworkConfig
//zk各节点地址
private static final String CONNECT_STRING = "localhost:2181,localhost:2182,localhost:2183";
//连接超时时间(单位:毫秒)
private static final int CONNECTION_TIME_OUT_MS = 10 * 1000;
//会话超时时间(单位:毫秒)
private static final int SESSION_TIME_OUT_MS = 30 * 1000;
//重试的初始等待时间(单位:毫秒)
private static final int BASE_SLEEP_TIME_MS = 2 * 1000;
//最大重试次数
private static final int MAX_RETRIES = 3;
@Bean
public CuratorFramework getCuratorFramework()
CuratorFramework curatorFramework = CuratorFrameworkFactory.builder()
.connectString(CONNECT_STRING)
.connectionTimeoutMs(CONNECTION_TIME_OUT_MS)
.sessionTimeoutMs(SESSION_TIME_OUT_MS)
.retryPolicy(new ExponentialBackoffRetry(BASE_SLEEP_TIME_MS, MAX_RETRIES))
.build();
curatorFramework.start();
return curatorFramework;
SESSION_TIME_OUT_MS参数则会保证,在某个客户端获取到锁之后突然宕机,zk能在该时间内删除当前客户端创建的临时有序节点。
测试代码如下:
//临时节点路径,qcy是博主名字缩写哈
private static final String LOCK_PATH = "/lockqcy";
@Resource
CuratorFramework curatorFramework;
public void testCurator() throws Exception
InterProcessMutex interProcessMutex = new InterProcessMutex(curatorFramework, LOCK_PATH);
interProcessMutex.acquire();
try
//模拟业务耗时
Thread.sleep(30 * 1000);
catch (Exception e)
e.printStackTrace();
finally
interProcessMutex.release();
当使用接口调用该方法时,在Thread.sleep处打上断点,进入到zk容器中观察创建出来的节点。
使用 docker exec -it zk容器名 /bin/bash 以交互模式进入容器,接着使用 ./bin/zkCli.sh 连接到zk的server端。
然后使用 ls path 查看节点

这三个节点都是持久节点,可以使用 get path 查看节点的数据结构信息

若一个节点的ephemeralOwner值为0,即该节点的临时拥有者的会话id为0,则代表该节点为持久节点。
当走到断点Thread.sleep时,确实发现在lockqcy下创建出来一个临时节点
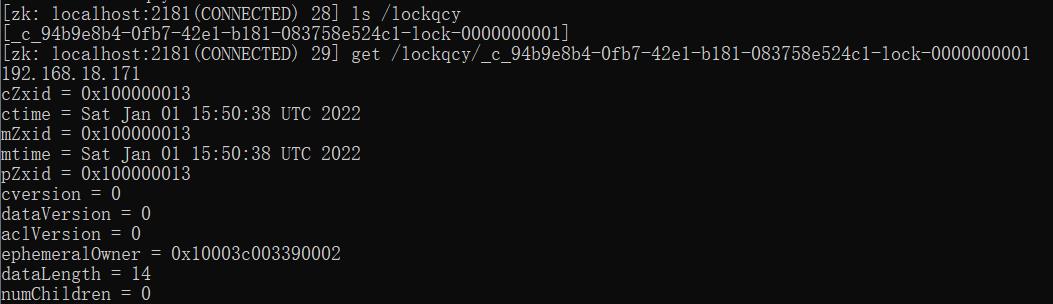
到这里吗,准备工作已经做完了,接下来分析interProcessMutex.acquire与release的流程
三、源码分析
Curator支持多种类型的锁,例如
- InterProcessMutex,可重入锁排它锁
- InterProcessReadWriteLock,读写锁
- InterProcessSemaphoreMutex,不可重入排它锁
今天主要是分析InterProcessMutex的加解锁过程,先看加锁过程
加锁
public void acquire() throws Exception
if (!internalLock(-1, null))
throw new IOException("Lost connection while trying to acquire lock: " + basePath);
这里是阻塞式获取锁,获取不到锁,就一直进行阻塞。所以对于internalLock方法,超时时间设置为-1,时间单位设置成null。
private boolean internalLock(long time, TimeUnit unit) throws Exception
Thread currentThread = Thread.currentThread();
//通过能否在map中取到该线程的LockData信息,来判断该线程是否已经持有锁
LockData lockData = threadData.get(currentThread);
if (lockData != null)
//进行可重入,直接返回加锁成功
lockData.lockCount.incrementAndGet();
return true;
//进行加锁
String lockPath = internals.attemptLock(time, unit, getLockNodeBytes());
if (lockPath != null)
//加锁成功,保存到map中
LockData newLockData = new LockData(currentThread, lockPath);
threadData.put(currentThread, newLockData);
return true;
return false;
其中threadData是一个map,key线程对象,value为该线程绑定的锁数据。
LockData中保存了加锁线程owningThread,重入计数lockCount与加锁路径lockPath,例如/lockqcy/_c_c46513c3-ace0-405f-aa1e-a531ce28fb47-lock-0000000005
private final ConcurrentMap<Thread, LockData> threadData = Maps.newConcurrentMap();
private static class LockData
final Thread owningThread;
final String lockPath;
final AtomicInteger lockCount = new AtomicInteger(1);
private LockData(Thread owningThread, String lockPath)
this.owningThread = owningThread;
this.lockPath = lockPath;
进入到internals.attemptLock方法中
String attemptLock(long time, TimeUnit unit, byte[] lockNodeBytes) throws Exception
//开始时间
final long startMillis = System.currentTimeMillis();
//将超时时间统一转化为毫秒单位
final Long millisToWait = (unit != null) ? unit.toMillis(time) : null;
//节点数据,这里为null
final byte[] localLockNodeBytes = (revocable.get() != null) ? new byte[0] : lockNodeBytes;
//重试次数
int retryCount = 0;
//锁路径
String ourPath = null;
//是否获取到锁
boolean hasTheLock = false;
//是否完成
boolean isDone = false;
while (!isDone)
isDone = true;
try
//创建一个临时有序节点,并返回节点路径
//内部调用client.create().creatingParentContainersIfNeeded().withProtection().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(path);
ourPath = driver.createsTheLock(client, path, localLockNodeBytes);
//依据返回的节点路径,判断是否抢到了锁
hasTheLock = internalLockLoop(startMillis, millisToWait, ourPath);
catch (KeeperException.NoNodeException e)
//在会话过期时,可能导致driver找不到临时有序节点,从而抛出NoNodeException
//这里就进行重试
if (client.getZookeeperClient().getRetryPolicy().allowRetry(retryCount++, System.currentTimeMillis() - startMillis, RetryLoop.getDefaultRetrySleeper()))
isDone = false;
else
throw e;
//获取到锁,则返回节点路径,供调用方记录到map中
if (hasTheLock)
return ourPath;
return null;
接下来,将会在internalLockLoop中利用刚才创建出来的临时有序节点,判断是否获取到了锁。
private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception
//是否获取到锁
boolean haveTheLock = false;
boolean doDelete = false;
try
if (revocable.get() != null)
//当前不会进入这里
client.getData().usingWatcher(revocableWatcher).forPath(ourPath);
//一直尝试获取锁
while ((client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock)
//返回basePath(这里是lockqcy)下所有的临时有序节点,并且按照后缀从小到大排列
List<String> children = getSortedChildren();
//取出当前线程创建出来的临时有序节点的名称,这里就是/_c_c46513c3-ace0-405f-aa1e-a531ce28fb47-lock-0000000005
String sequenceNodeName = ourPath.substring(basePath.length() + 1);
//判断当前节点是否处于排序后的首位,如果处于首位,则代表获取到了锁
PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);
if (predicateResults.getsTheLock())
//获取到锁之后,则终止循环
haveTheLock = true;
else
//这里代表没有获取到锁
//获取比当前节点索引小的前一个节点
String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch();
synchronized (this)
try
//如果前一个节点不存在,则直接抛出NoNodeException,catch中不进行处理,在下一轮中继续获取锁
//如果前一个节点存在,则给它设置一个监听器,监听它的释放事件
client.getData().usingWatcher(watcher).forPath(previousSequencePath);
if (millisToWait != null)
millisToWait -= (System.currentTimeMillis() - startMillis);
startMillis = System.currentTimeMillis();
//判断是否超时
if (millisToWait <= 0)
//获取锁超时,删除刚才创建的临时有序节点
doDelete = true;
break;
//没超时的话,在millisToWait内进行等待
wait(millisToWait);
else
//无限期阻塞等待,监听到前一个节点被删除时,才会触发唤醒操作
wait();
catch (KeeperException.NoNodeException e)
//如果前一个节点不存在,则直接抛出NoNodeException,catch中不进行处理,在下一轮中继续获取锁
catch (Exception e)
ThreadUtils.checkInterrupted(e);
doDelete = true;
throw e;
finally
if (doDelete)
//删除刚才创建出来的临时有序节点
deleteOurPath(ourPath);
return haveTheLock;
判断是否获取到锁的核心逻辑位于getsTheLock中
public PredicateResults getsTheLock(CuratorFramework client, List<String> children, String sequenceNodeName, int maxLeases) throws Exception
//获取当前节点在所有子节点排序后的索引位置
int ourIndex = children.indexOf(sequenceNodeName);
//判断当前节点是否处于子节点中
validateOurIndex(sequenceNodeName, ourIndex);
//InterProcessMutex的构造方法,会将maxLeases初始化为1
//ourIndex必须为0,才能使得getsTheLock为true,也就是说,当前节点必须是basePath下的最小节点,才能代表获取到了锁
boolean getsTheLock = ourIndex < maxLeases;
//如果获取不到锁,则返回上一个节点的名称,用作对其设置监听
String pathToWatch = getsTheLock ? null : children.get(ourIndex - maxLeases);
return new PredicateResults(pathToWatch, getsTheLock);
static void validateOurIndex(String sequenceNodeName, int ourIndex) throws KeeperException
if (ourIndex < 0)
//可能会由于连接丢失导致临时节点被删除,因此这里属于保险措施
throw new KeeperException.NoNodeException("Sequential path not found: " + sequenceNodeName);
那什么时候,在internalLockLoop处于wait的线程能被唤醒呢?
在internalLockLoop方法中,已经使用
client.getData().usingWatcher(watcher).forPath(previousSequencePath);给前一个节点设置了监听器,当该节点被删除时,将会触发watcher中的回调
private final Watcher watcher = new Watcher()
//回调方法
@Override
public void process(WatchedEvent event)
notifyFromWatcher();
;
private synchronized void notifyFromWatcher()
//唤醒所以在LockInternals实例上等待的线程
notifyAll();
到这里,基本上已经分析完加锁的过程了,在这里总结下:
首先创建一个临时有序节点
如果该节点是basePath下最小节点,则代表获取到了锁,存入map中,下次直接进行重入。
如果该节点不是最小节点,则对前一个节点设置监听,接着进行wait等待。当前一个节点被删除时,将会通知notify该线程。
解锁
解锁的逻辑,就比较简单了,直接进入release方法中
public void release() throws Exception
Thread currentThread = Thread.currentThread();
LockData lockData = threadData.get(currentThread);
if (lockData == null)
throw new IllegalMonitorStateException("You do not own the lock: " + basePath);
int newLockCount = lockData.lockCount.decrementAndGet();
//直接减少一次重入次数
if (newLockCount > 0)
return;
if (newLockCount < 0)
throw new IllegalMonitorStateException("Lock count has gone negative for lock: " + basePath);
//到这里代表重入次数为0
try
//释放锁
internals.releaseLock(lockData.lockPath);
finally
//从map中移除
threadData.remove(currentThread);
void releaseLock(String lockPath) throws Exception
revocable.set(null);
//内部使用guaranteed,会在后台不断尝试删除节点
deleteOurPath(lockPath);
重入次数大于0,就减少重入次数。当减为0时,调用zk去删除节点,这一点和Redisson可重入锁释放时一致。
四、羊群效应
在这里谈谈使用Zookeeper实现分布式锁场景中的羊群效应
什么是羊群效应
首先,羊群是一种很散乱的组织,漫无目的,缺少管理,一般需要牧羊犬来帮助主人控制羊群。
某个时候,当其中一只羊发现前面有更加美味的草而动起来,就会导致其余的羊一哄而上,根本不管周围的情况。
所以羊群效应,指的是一个人在进行理性的行为后,导致其余人直接盲从,产生非理性的从众行为。
而Zookeeper中的羊群效应,则是指一个znode被改变后,触发了大量本可以被避免的watch通知,造成集群资源的浪费。
获取不到锁时的等待演化
sleep一段时间
如果某个线程在获取锁失败后,完全可以sleep一段时间,再尝试获取锁。
但这样的方式,效率极低。
sleep时间短的话,会频繁地进行轮询,浪费资源。
sleep时间长的话,会出现锁被释放但仍然获取不到锁的尴尬情况。
所以,这里的优化点,在于如何变主动轮询为异步通知。
watch被锁住的节点
所有的客户端要获取锁时,只去创建一个同名的node。
当znode存在时,这些客户端对其设置监听。当znode被删除后,通知所有等待锁的客户端,接着这些客户端再次尝试获取锁。
虽然这里使用watch机制来异步通知,可是当客户端的数量特别多时,会存在性能低点。
当znode被删除后,在这一瞬间,需要给大量的客户端发送通知。在此期间,其余提交给zk的正常请求可能会被延迟或者阻塞。
这就产生了羊群效应,一个点的变化(znode被删除),造成了全面的影响(通知大量的客户端)。
所以,这里的优化点,在于如何减少对一个znode的监听数量,最好的情况是只有一个。
watch前一个有序节点
如果先指定一个basePath,想要获取锁的客户端,直接在该路径下创建临时有序节点。
当创建的节点是最小节点时,代表获取到了锁。如果不是最小的节点,则只对前一个节点设置监听器,只监听前一个节点的删除行为。
这样前一个节点被删除时,只会给下一个节点代表的客户端发送通知,不会给所有客户端发送通知,从而避免了羊群效应。

在避免羊群效应的同时,使得当前锁成为公平锁。即按照申请锁的先后顺序获得锁,避免存在饥饿过度的线程。
五、后语
本文从源码角度讲解了使用Curator获取分布式锁的流程,接着从等待锁的演化过程角度出发,分析了Zookeeper在分布式锁场景下避免羊群效应的解决方案。
这是Zookeeper系列的第二篇,关于其watch原理分析、zab协议等文章也在安排的路上了。
以上是关于从Curator实现分布式锁的源码再到羊群效应的主要内容,如果未能解决你的问题,请参考以下文章