浅谈Zookeeper客户端库Curator实现加锁的原理
Posted 默辨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈Zookeeper客户端库Curator实现加锁的原理相关的知识,希望对你有一定的参考价值。
浅谈Zookeeper客户端库Curator实现加锁的原理
一、非公平锁(互斥)
一想到加锁,我们自然就能够想到一个基本的锁机制,如下。
下图是一个非公平锁的模型,其目的是为了提高并发的。但在Zookeeper中,非公平并不一定就会提高对应的性能,所以并非完全使用这个模型(curator使用的是公平锁模型),但是大体的流程差不多
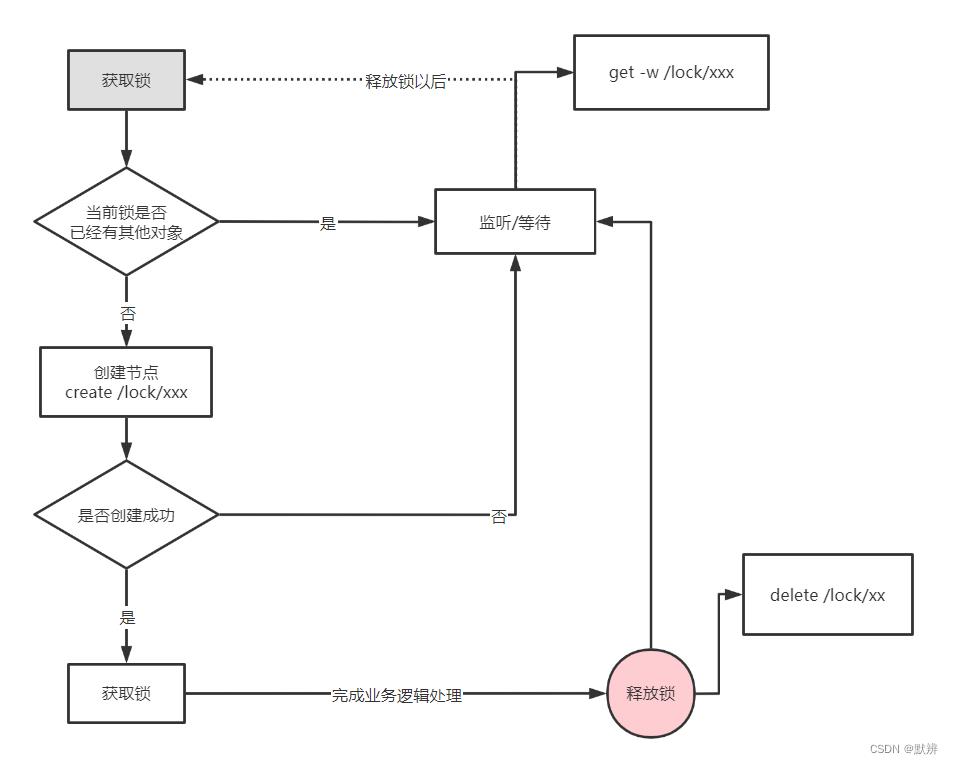
以上加锁逻辑为,对一个请求进行加锁,如果对应的加锁对象没有锁,就去创建一个节点,如果节点创建成功,则表示获取锁成功。在没有释放锁的时候,第二个请求会去判断是否有其他对象,此时判断为是,则该节点会进行阻塞监听。直到第一个请求释放锁之后,就会触发对应的监听机制通知等待的请求,第二个请求再次进行获取锁的判断操作。
如上实现方式在并发问题比较严重的情况下,性能会下降的比较厉害,主要原因是,所有的连接都在对同一个节点进行监听,当服务器检测到删除事件时,要通知所有的连接,所有的连接同时收到事件,再次并发竞争,这就是惊群效应。这种加锁方式是非公平的。
想要避免惊群效应带来的性能损耗,可以使用公平锁的机制对其优化,提高响应性能。
二、公平锁(互斥)
使用了公平锁,获取锁的情况就根据请求先后进行决定,使用的样例代码如下
@PostMapping("/stock/deduct")
public Object reduceStock(Integer id) throws Exception
InterProcessMutex interProcessMutex = new InterProcessMutex(curatorFramework, "/product_" + id);
try
// 加锁
interProcessMutex.acquire();
// 业务逻辑
orderService.reduceStock(id);
catch (Exception e)
if (e instanceof RuntimeException)
throw e;
finally
// 释放锁
interProcessMutex.release();
return "ok:" + port;
1、概念
主体流程:
- 与上面的非公平锁的逻辑大体相同
- 主要区别为将获取锁对象和创建节点两个步骤合二为一了,并且添加了一些逻辑判断来筛选出具体的获取锁的节点
- 还有一个区别是,对应的监听机制不再是对一个节点进行监听,而是对他的上一个节点进行监听

如上借助于临时顺序节点,节点顺序监听,可以避免同时多个节点的并发竞争锁,缓解了服务端压力。这种实现方式所有加锁请求都进行排队加锁,是公平锁的具体实现。
2、源码
1、初始化基础配置,包含对应的zookeeper客户端、未来使用的加锁目录,以及加锁驱动类
public InterProcessMutex(CuratorFramework client, String path)
this(client, path, new StandardLockInternalsDriver());
2、处理可重入锁逻辑
第一步:如果能获取到数据,表示曾经完成过加锁逻辑,如今再次加锁,直接使用可重入锁逻辑即可。即直接加锁数量+1,然后返回;
第二步:进行加锁逻辑;
第三步:如果加锁成功,会返回加锁成功的路径,将其封装为一个lockData对象,再放进本地缓存Map。未来第一步就能直接获取到。

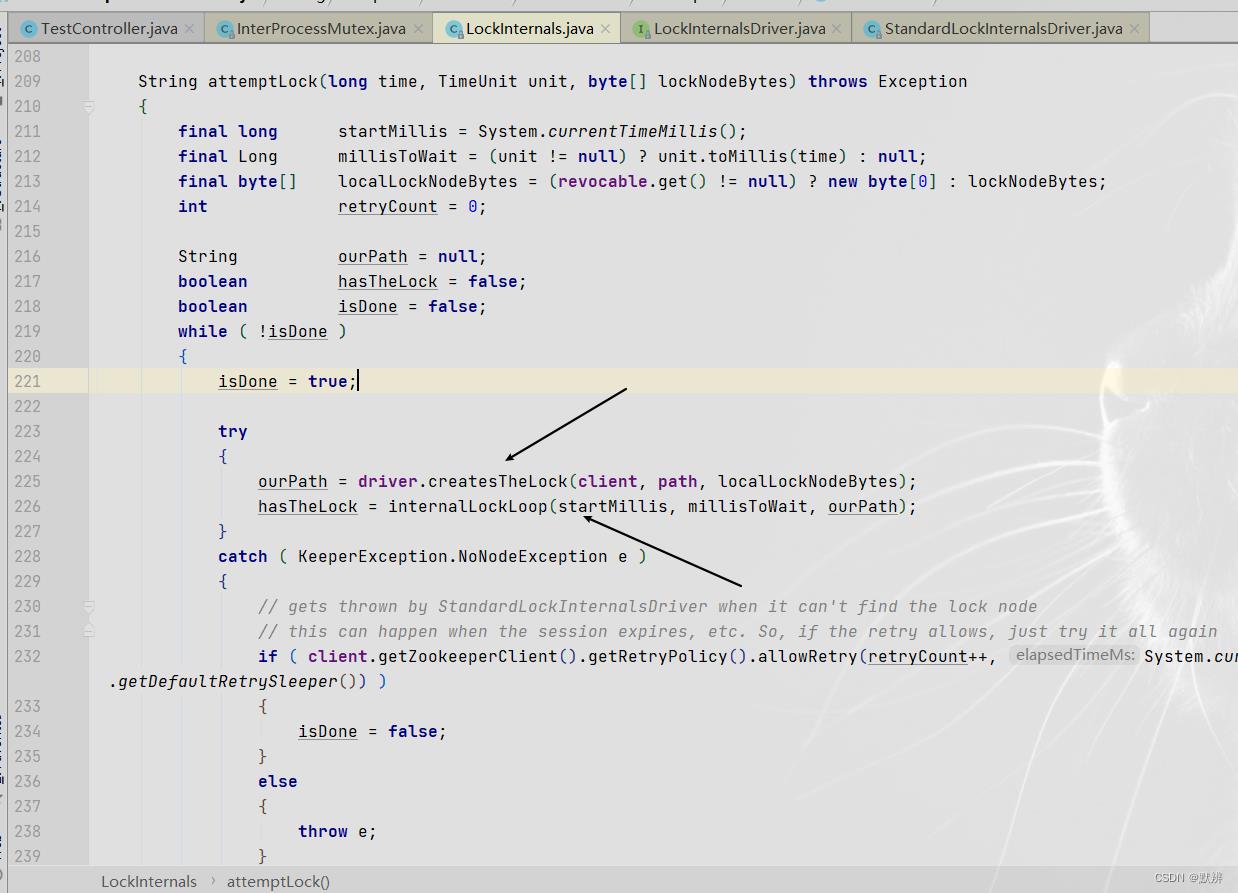
3、attemptLock方法中核心逻辑在createsTheLock和internalLockLoop两个方法中
- createsTheLock:创建对应的节点。这里的driver对象,就是初始化的时候传入的对象
- internalLockLoop:对该节点进行逻辑判断(能加锁成功,怎么走;不能加锁成功,又怎么走)
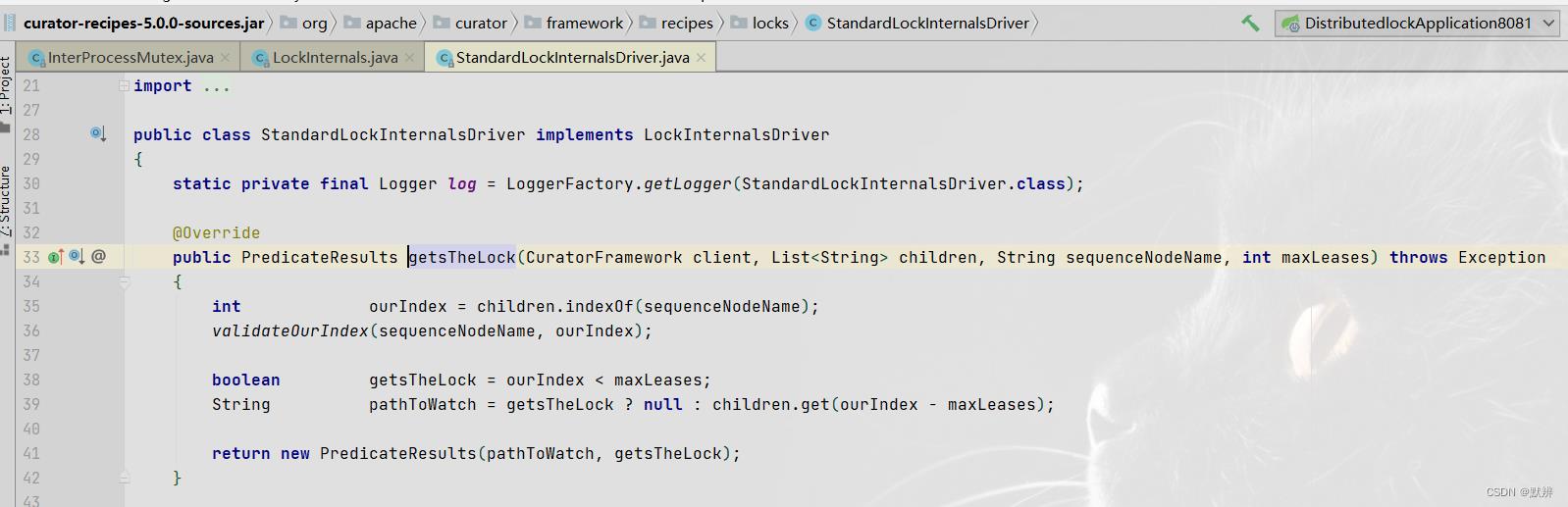
4、createsTheLock
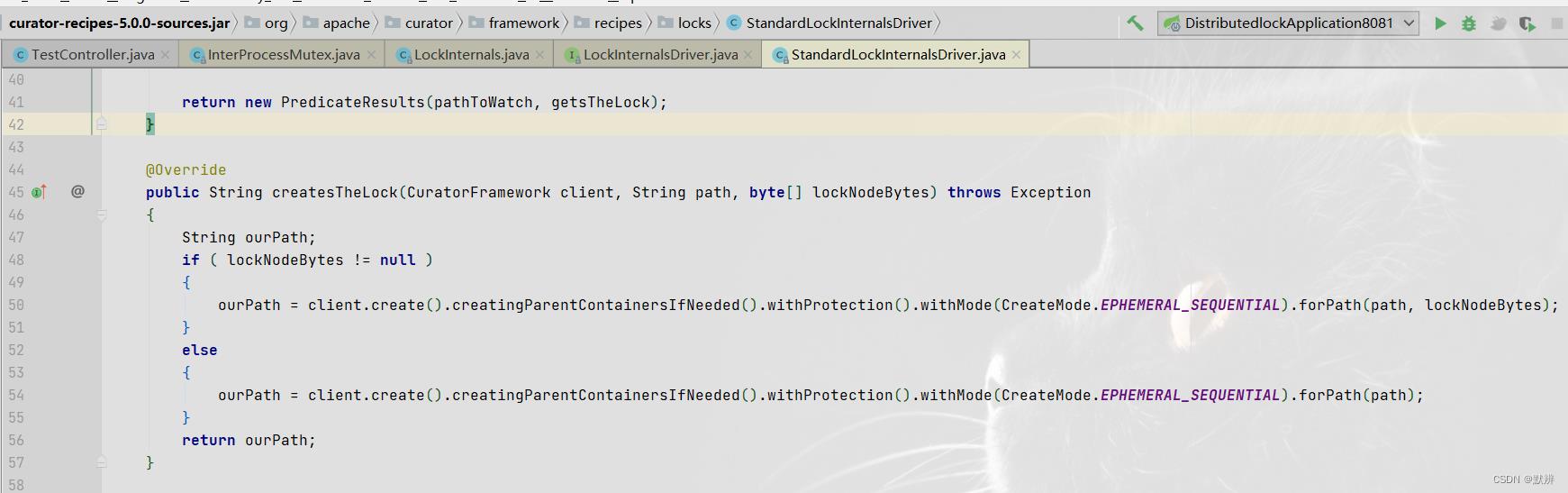
熟悉的链式编程风格,又是一个构建者设计模式,核心方法可直接看forPath方法。
该方法不难看出,是想在zookeeper配置中心的定制路径下面,创建一个目录节点,然后返回对应的路径。
这里创建的是Zookeeper中的container节点,该节点的特性是如果该节点下面没有文件,该节点会自动删除。
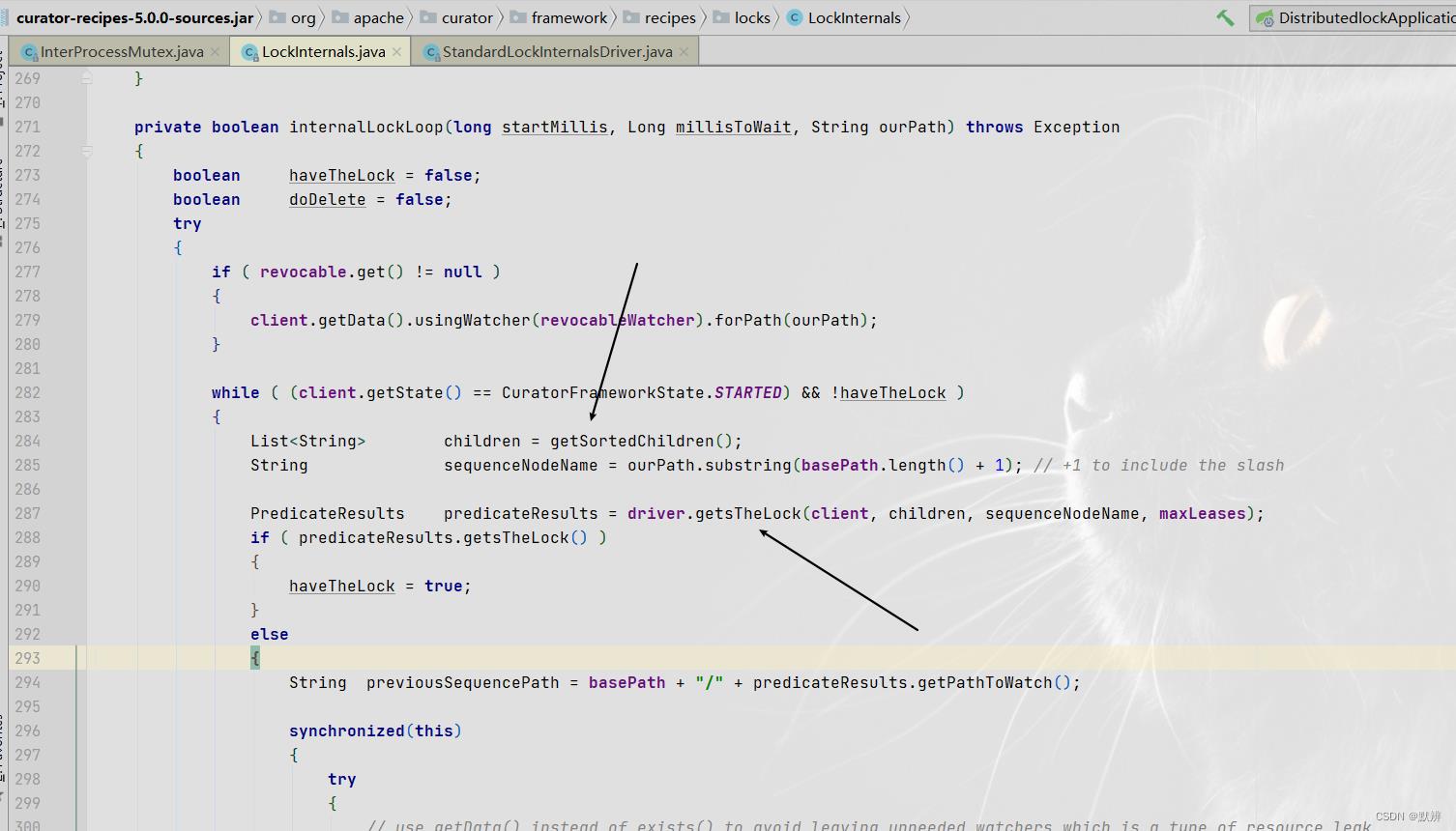
5、internalLockLoop:进行加锁判断
该方法核心逻辑也只有两步:
- getSortedChildren:获取当前路径下面所有子节点,并且完成排序
- getsTheLock:将排好序的子节点和上一步创建的节点进行判断,完成相关逻辑
- 最终选择返回加锁成功的节点,还是完成对节点进行相关的阻塞监听
6、具体判断
- 获取加锁返回节点得索引下标
- 判断我们加锁得节点是不是小于maxLeases(在初始化InterProcessMutex对象得时候,给出得默认值1)
- 如果加锁节点小于1(只有索引位置为1才会小于1),表示我们创建的节点是最小节点,0<1就会判定为true,继而第二步为null,最终返回给一个封装了null-true节点信息的加锁对象(后续为haveTheLock=true,不需要监听任何节点)
- 如果加锁节点大于1,表示我们创建的节点不是最小节点,对应的判定为flase,对应的pathToWatch表示对其前一个节点进行监听,然后返回这个封装了监听的对象(后续为调用usingWatcher方法,对基础路径+节点名称添加监听,根据对应的阻塞时间,阻塞等待wait方法)
- 上面两个括号里面的后续为,为5大步(上一步)的判断逻辑。
总结
上诉源码流程可以简单描述为:
- 首先会根据当前线程的加锁情况,判断是否是重入锁
- 然后会在zookeeper上根据对应的参数配置,创建一个临时的顺序节点
- 获取到返回的顺序节点,判断它是否为当前路径下最小的节点
- 如果是,则获取到锁
- 如果不是则完成对其前一个节点的监听
- 等某个节点监听的节点释放锁之后,会唤醒该节点,继而达到一条链的形式
3、补充
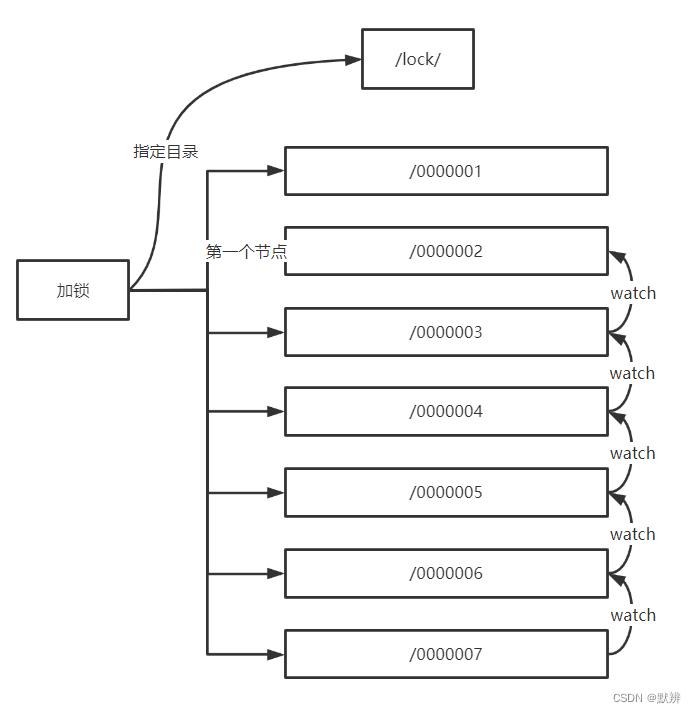
幽灵节点,以之前的图示为例。
当我们在创建01节点的时候,节点创建成功,但是返回给前台的时候网络波动,导致未能成功返回对应的节点,curator会触发对应的重试机制,会直接创建一个新的顺序节点02节点。这就会导致,未来02这个节点会对01节点完成监听,但是01节点客户端是不知道的,就会导致无法监控到01节点,最终出现01节点一直存活,这就是01节点就称为幽灵节点。
解决方式:通过 Protection模式能够避免这个问题,
1、在每次添加节点时为顺序节点拼接一个uuid的前缀
2、如果加锁失败,就会触发curator的重试机制
3、第二次加锁,会带上第一次相同的uuid
4、在创建顺序节点的时候会先判断,对应的含有uuid的节点是否存在
5、如果存在就表示曾经是创建成功的,直接返回。如果不存在就创建,然后返回。
前面这两种加锁方式有一个共同的特质,就是都是互斥锁,同一时间只能有一个请求占用,如果是大量的并发上来,性能是会急剧下降的,所有的请求都得加锁,那是不是真的所有的请求都需要加锁呢?答案是否定的,比如如果数据没有进行任何修改的话,是不需要加锁的,但是如果读数据的请求还没读完,这个时候来了一个写请求,怎么办呢?有人已经在读数据了,这个时候是不能写数据的,不然数据就不正确了。直到前面读锁全部释放掉以后,写请求才能执行,所以需要给这个读请求加一个标识(读锁),让写请求知道,这个时候是不能修改数据的。不然数据就不一致了。如果已经有人在写数据了,再来一个请求写数据,也是不允许的,这样也会导致数据的不一致,所以所有的写请求,都需要加一个写锁,是为了避免同时对共享数据进行写操作。
三、共享锁
在很多并发锁中都会有共享锁的实现方案,如AQS下的ReentrantReadWriteLock锁,又比如Redisson的RedissonReadWriteLock锁,这些都是在原先互斥锁的基础上进行优化,细化锁的粒度,演化出的读写锁。
1、概念
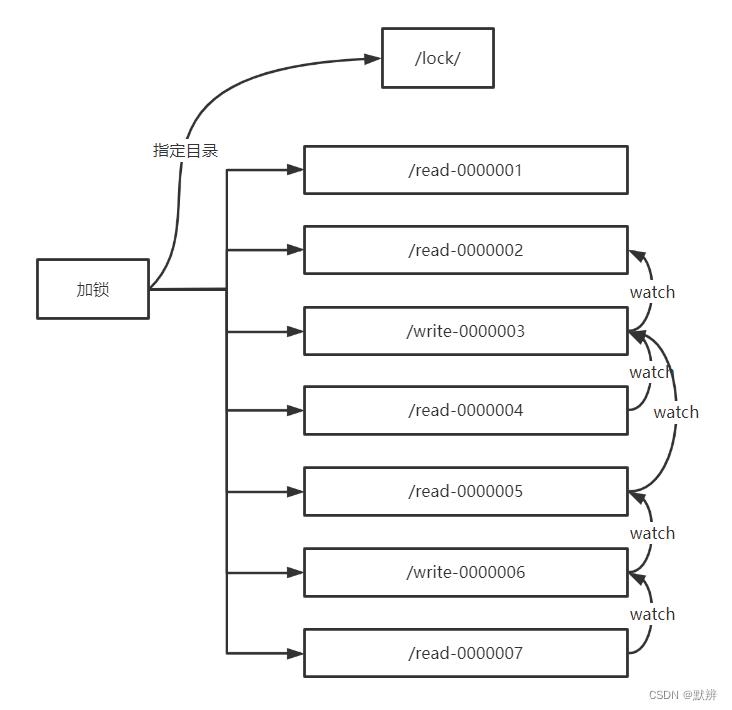
read请求,如果前面都是读锁,那就直接获取锁。如果read前面有写锁,则该请求无法直接获取锁,而是完成对离它最近的一个写锁添加监听。
如下图中,01、02节点能够直接获取到锁,并且不需要添加任何监听。03节点是一个写锁,无法直接获取锁,完成对其上一个节点的监听(类比第二节中的公平锁了逻辑)。04节点是一个读请求,会对离它最近的一个写请求进行监听,即对03节点进行监听。同理05是写请求,也监听03节点…
2、源码
1、读锁入口
上面为写锁、下面为读锁。写锁和上面的互斥共享锁逻辑相同
maxLeases:Integer.MAX_VALUE(区别于写锁的1)
读写锁分别会带上自己的标记READ_LOCK_NAME、WRITE_LOCK_NAME

2、进行加锁判断
- 遍历对应加锁目录下的所有子节点。node是排好顺序的,if会依次获取到写锁的索引下标位置。index表示当前遍历的索引下标,firstWriteIndex表示遍历过程中最近的一个写锁的位置。这个min最小判断就能够获取到离当前下标最近的一个写锁的位置
- 直到找到我们自己的节点就跳出循环
- 这里和前面的判断逻辑大致相同
- 判断当前节点的下标是不是小于在它前面,并且离它最近的一个写锁的位置,即它前面有没有写锁
- 如果前面没有写锁,就会为false。比如1为当前节点,写锁位置为4。那么ourIndex为1,1小于Integer.MAX_VALUE为true
- 反之,如果写锁为1,自己节点为4,firstWriteIndex就为1,ourIndex为4,对应的getsTheLock为false,然后封装一个对firstWriteIndex位置(即1节点)的监听给当前对象

以上是关于浅谈Zookeeper客户端库Curator实现加锁的原理的主要内容,如果未能解决你的问题,请参考以下文章