推荐系统从入门到入门——基于MapReuduce与Spark的分布式推荐系统构建
Posted @李忆如
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统从入门到入门——基于MapReuduce与Spark的分布式推荐系统构建相关的知识,希望对你有一定的参考价值。
本系列博客总结了不同框架、不同算法、不同界面的推荐系统,完整阅读需要大量时间(又臭又长),建议根据目录选择需要的内容查看,欢迎讨论与指出问题。
目录
2.2.2 基于MapReduce的WordCount(实现)
系列文章梗概
系列文章目录
第一章 推荐系统从入门到入门(1)——推荐系统综述与协同过滤_@李忆如的博客-CSDN博客
第二章 推荐系统从入门到入门(2)——简单推荐系统构建(无框架、Tensorflow)_@李忆如
第三章 推荐系统从入门到入门(3)——基于MapReuduce与Spark的分布式推荐系统构建
三、MapReduce
在上一章中,我们从不同类别、角度简单综述了推荐系统中的各种算法,详细介绍了不同协同过滤的原理与数学推导,并在本地使用几种方式构建了电影推荐系统并进行效果对比。经分析,在缺乏算力与框架(计算平台)的情况下,直接构建的电影推荐系统难以处理大数据问题,故本部分将介绍云计算与大数据领域的经典框架(计算平台)——MapReduce,并尝试在腾学汇平台与本地(已配好Hadoop)上构建基于MapReduce框架的电影推荐系统。
1.MapReduce详解
1.1 MapReduce简介
MapReduce是一种编程模型(框架、计算平台),属于Hadoop生态的一员,用于大规模数据集(大于1TB)的并行运算。核心概念为"Map(映射)"和"Reduce(归约)",极大地方便了分布式系统的构建与运行。
当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。流程可视化如图41所示,原理与样例代码详解可见:Hadoop Map/Reduce教程 (apache.org)
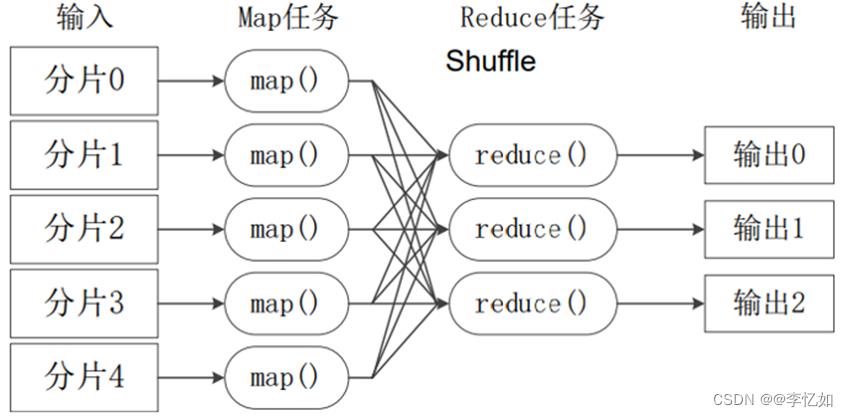
图41 MapReduce工作流程概述
1.2 MapReduce背景
实际上,在MapReduce之前也有不少成熟的并行计算框架,例如MPI,作为背景补充,MapReduce与传统并行计算框架的对比总结如表18:
表18 不同计算框架对比
| 传统并行计算框架 | MapReduce | |
| 集群架构/容错性 | 共享式(共享内存/储存),容错性差 | 非共享式,容错性好 |
| 硬件/价格/扩展性 | 刀片服务器、高速网、SAN,价 格贵,扩展性差 | 普通PC机,便宜,扩展性好 |
| 编程/学习难度 | what-how,难 | what,简单 |
| 适用场景 | 实时、细粒度计算、计算密集型 | 批处理、非实时、数据密集型 |
分析:根据表18所示,对于不同场景,不同编程人员、不同需求的情况下,需要选择不同的计算框架。
1.3 MapReduce全流程详解
1.3.1 MapReduce原理
在简单了解MapReduce及其与传统并行框架对比后,在本部分对于其原理进行详细解析。
在1.1中我们知道,MapReduce的核心是构造Map和Reduce两个函数,形式如图42所示:
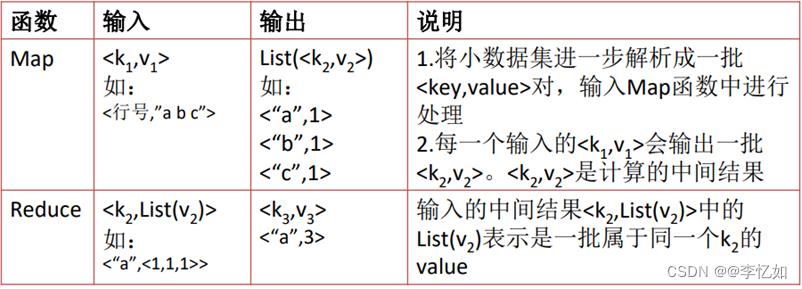
图42 MapReduce核心函数形式
展开来说,MapReduce可以理解为把一堆杂乱无章的数据按照某种特征归纳起来,然后处理并得到最后的结果。Map面对的是杂乱无章的互不相关的数据,它解析每个数据,从中提取出key和value,也就是提取了数据的特征。经过MapReduce的Shuffle阶段之后,在Reduce阶段看到的都是已经归纳好的数据了,在此基础上我们可以做进一步的处理以便得到结果。
根据MapReduce的原理、工作流程、形式,参考相关文档将其主要功能、技术特征、模型简介等原理总结如表19:
表19 MapReduce原理总结
| 1、模型简介:
2、主要功能:
3、技术特征:
|
1.3.2 MapReduce体系结构
MapReduce体系结构主要由四个部分组成,分别是:Client、JobTracker、TaskTracker以及Task,如图43所示,各部分作用总结如表20:
 图43 MapReduce体系结构
图43 MapReduce体系结构
表20 MapReduce体系结构分部作用简介
| 名称 | 作用 |
| Client(客户端) | 提交程序与作业状态查看 |
| JobTracker(作业跟踪器) | 资源监控和作业调度 |
| TaskTracker(任务调度器) | 汇报资源使用情况与任务运行进度 |
| Task(任务) | 分Map Task 和Reduce Task ,由TaskTracker 启动 |
1.3.3 MapReduce工作流程
在1.1的图41中简述了MapReduce工作流程图,在此给出四点补充:
◼ 不同的Map任务之间不会进行通信
◼ 不同的Reduce任务之间也不会发生任何信息交换
◼ 用户不能显式地从一台机器向另一台机器发送消息
◼ 所有的数据交换都是通过MapReduce框架自身去实现的
结合MapReduce体系结构与工作流程简述,其分层工作流(各个执行阶段)如图44所示:
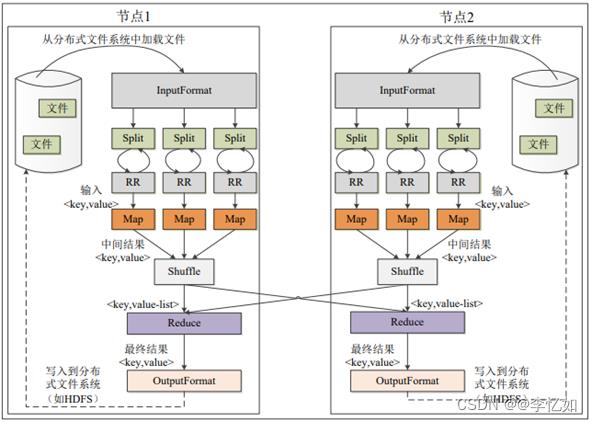
图44 MapReduce分阶段工作流程图
接下来对MapReduce的不同阶段做详解。
(1)Split
HDFS 以固定大小的block 为基本单位存储数据,而对于MapReduce 而言,其处理单位是split。
split 是一个逻辑概念,它只包含一些元数据信息,比如数据起始位置、数据长度、数据所在节点等。
划分方法完全由用户自己决定,样例如图45所示:
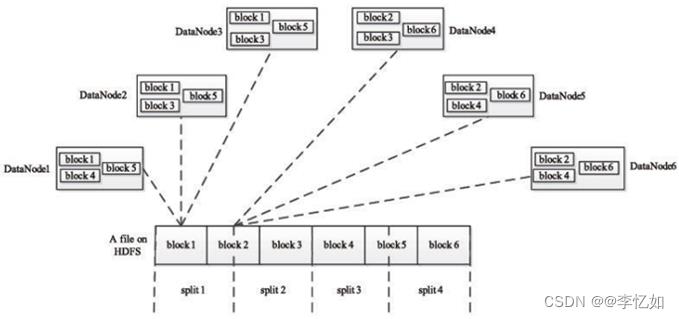
图45 Split的执行过程
(2)Map
Map的执行过程如图46所示:
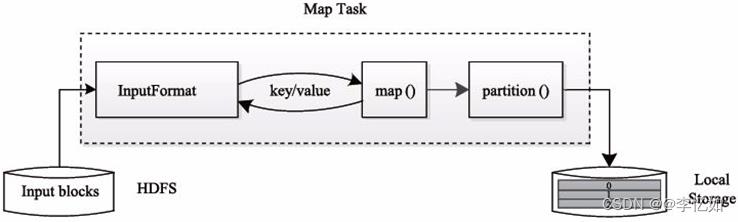
图46 Map的执行过程
分析:如图46可知,Map Task 先将对应的split迭代解析成一个个key-value对,依次调用用户自定义的map()函数进行处理,最终将临时结果存放到本地磁盘上。其中,临时数据被分成若干个partition,每个partition将被一个Reduce Task处理。
(3)Shuffle
Shuffle的执行过程如图47所示:
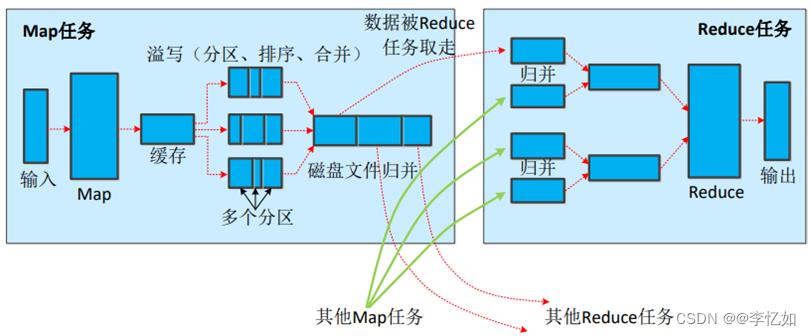
图47 Shuffle执行过程
分析:如图47所示,Shuffle过程实际上分为Map端与Reduce端,对于不同端按图47使用不同处理。
(4)Reduce
一般来说,Reduce过程分为三个阶段:
Ⅰ、从远程节点上读取Map Task中间结果(称为“Shuffle 阶段”)
Ⅱ、按照 key 对 key-value 对进行排序(称为 “Sort 阶段”)
Ⅲ、依次读取< key, value list >,调用用户自定义的Reduce函数处理,并将最终结果存到HDFS上(称为“Reduce阶段”)
执行过程如图48所示:
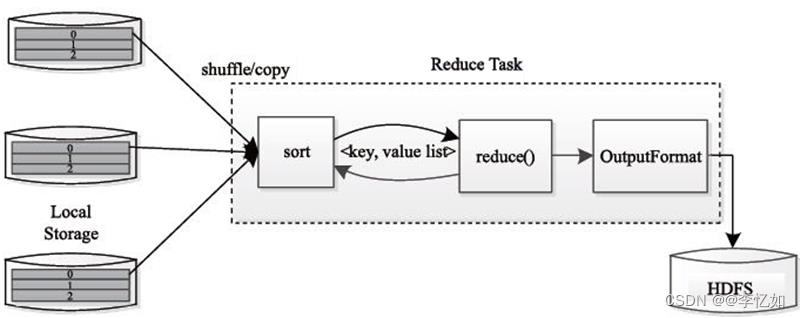
图48 Reduce执行过程
至此,MapReduce的工作流程的分阶段详解完成。
2.MapReduce配置与简单应用
在上一部分对MapReduce的原理、体系结构、工作流程做了详解,在本部分进行MapReduce的配置与简单应用实践。
2.1 MapReduce配置
由于MapReduce隶属Hadoop生态,故其配置核心是Hadoop的配置与启动(+一些配置文件的修改与Yarn的启动配置等)。
Tips:本地已配置Haddop环境(核心为虚拟机与环境配置,在本部分不详述),本部分以腾学汇的Hadoop环境构建为例展示MapReduce配置。
(1)云主机登录与更名
要求:登录3台云主机,创建用户:用户名为学生名称加学号,即liwen_2020155023
在“实验资源信息”中点击“登录”对三台云主机进行登录,使用如图49命令对主机进行用户创建与名称设置:

图49 主机更名代码
结果如图50所示(以master为例):

图50 更名验证样例
Tips:更名后需使用bash命令或重新登录。
(2)设置IP地址
使用ip a命令可以查看当前机器的IP,以master的IP查看命令与结果为例,结果如图51(透明框为IP):

图51 IP地址查看命令与结果样例
(3)配置hosts文件
使用vi /etc/hosts命令在master机器上打开hosts文件,打开文档后输入i进入插入模式,在文档末尾插入如图52配置(以2步中查看到的实际IP为准),保存退出即可。

图52 hosts配置
(4)刷新slave1和slave2的免密登录信息
在matser机器下,刷新slave1和slave2的免密登录信息命令为ssh-keygen -R slave1与ssh-keygen -R slave2,操作与结果如图53:
图53 免密登录信息刷新操作与结果
(5)分发hosts文件
在matser机器下,分发hosts文件命令为scp -P 10011 /etc/hosts slave1:/etc/与scp -P 10011 /etc/hosts slave2:/etc/,操作与结果如图 54所示:
图54 分发hosts文件操作与结果
(6)启动hadoop
机器:在matser机器下
①使用start-dfs.sh和start-yarn.sh命令启动hadoop,命令及效果如图55所示:
图55 hadoop启动命令与效果
②使用mr-jobhistory-daemon.sh start historyserver命令开启历史日志记录,并使用hadoop dfsadmin -safemode leave命令关闭hdfs的safemode,操作与效果如图56所示:

图56 历史日志记录开启与safemode关闭操作与效果
(7)验证启动成功
①使用jps命令可以查看进程如图57与图58(以master与slave1进程展示为例)所示,可以看到master跟启动之前相比,会增加NameNode和SecondaryNameNode进程;而slave跟启动之前相比,会增加DataNode和NodeManager进程。
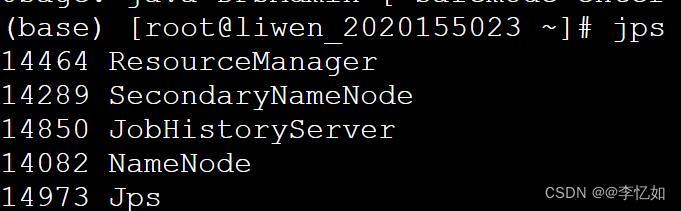
图57 进程展示样例(master)
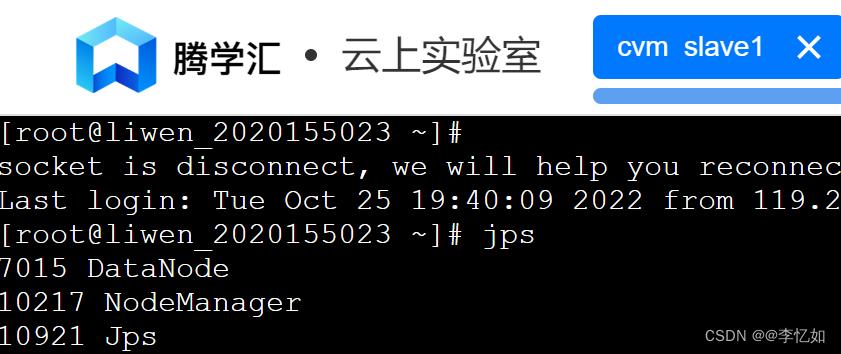
图58 进程展示样例(slave1)
Tips:至此,hadoop基础环境准备完毕。
②可以在master的可视化界面中打开浏览器,输入http://masterIP:8188,可以看到图59界面:

图59 hadoop可视化界面
③点击左侧的Nodes,可以看到当前已经有两个slave节点已经在运行,如图60所示:

图60 节点运行可视化界面
至此,Hadoop环境正式配置完成,且被验证正常运行。
2.2 MapReduce简单应用
在配置好MapReduce环境后,在本部分先以其简单应用做应用程序的探究。根据1中MapReduce详解,总结其应用程序执行过程如图61所示:
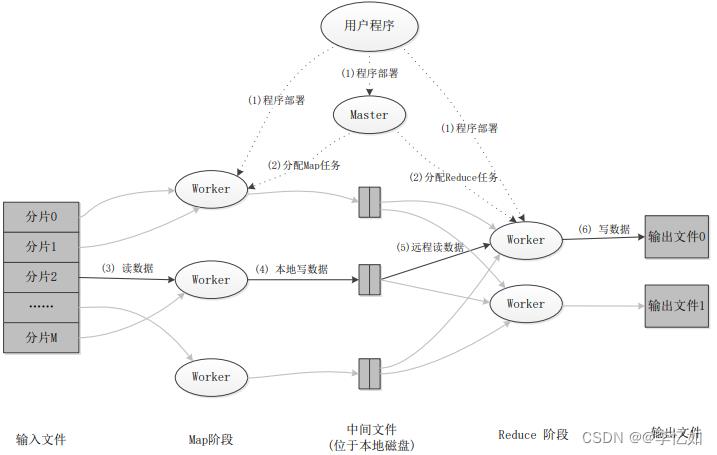
图61 MapReduce应用程序执行过程
本部分以经典的WordCoun为例子做MapReduce简单应用的实践。
2.2.1 基于MapReduce的WordCount(原理与流程)
WordCount为MapReuduce简单应用的经典样例,顾名思义即对文件(数据中)的单词进行统计,并输出文件中每个单词及其出现次数(频数),样例如图62所示:
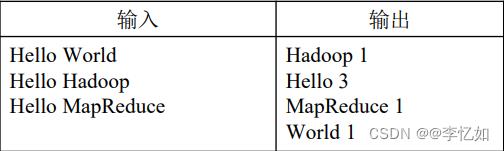
图62 WordCount样例
根据2.1中MapReduce的工作流程,先对基于MapReduce的WordCount实现过程做设计,即本应用能不能采用MapReduce实现,如何设计,如何执行三大问题。最终WordCount执行过程(以有定义Combiner为例,未定义则使用Combine代替Shuffle)总结如图63所示:
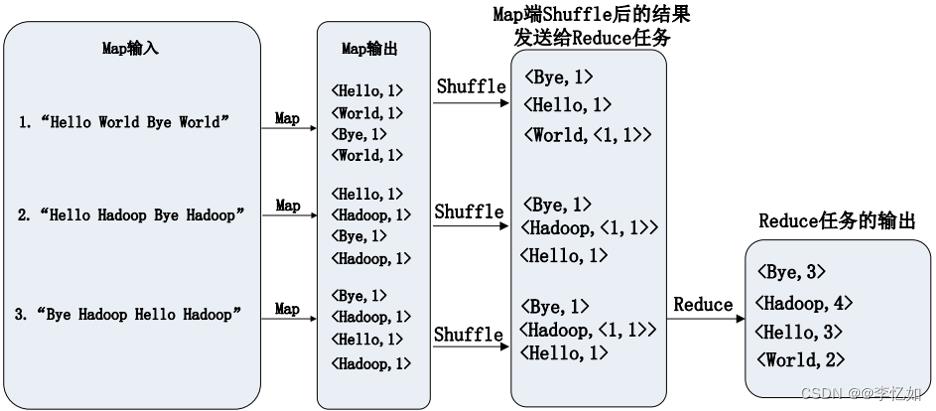
图63 WordCount执行过程
2.2.2 基于MapReduce的WordCount(实现)
基于MapReduce的WordCount一般有两种方式,分别是使用官方样例与自构建,详解如下:
(1)官方样例
由于WordCount为MapReduce官方经典样例,故在对于jar包(例如hadoop-mapreduce-examples-2.5.2.jar)中有定义供用户调用实践,定义好对应data调用jar包即可(具体过程与命令与自构建类似,后文给出)。
(2)自构建
①代码实现
自购建即自己编写基于MapReduce的代码实现WordCount,然后在Input从HDFS里面并行读取文本中的内容,经过MapReduce模型,最终把分析出来的结果用Output封装,持久化到HDFS中。
按图63中WordCount执行过程的逻辑编写代码,自购建的实现核心是Map(切分,遍历,计数)+Reduce(遍历计数,累加)+提交主类。核心代码如图64与图65所示:
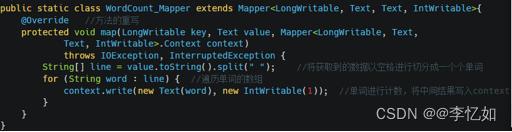
图64 WordCount中的Map构造
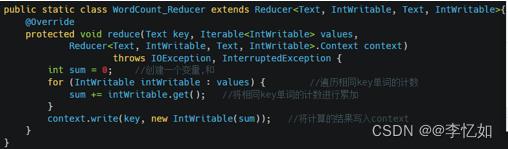
图65 WordCount中的Reduce构造
②代码打包
此处以腾学汇平台测试为例(本地配置好Hadoop的虚拟机直接jar化使用即可),在本地编写好WordCount.java,通过“实验资源”中的“上传文件”将代码上传到云平台(/tmp下),“桌面连接”后在Eclipse中构建项目,如图66所示:

图66 平台迁移后的项目构建
项目构建成功后,类似实验五的操作,点击“file”的“export”,选定对应位置,构造Jar文件。
③代码运行
Ⅰ、数据创建与上传
首先要使用vi input.txt命令进行数据的创建,样例如图67所示,并使用hadoop fs -put input.txt /(hdfs dfs -copyFromLocal …)命令将数据上传到HDFS中。
图67 数据样例
Ⅱ、代码运行与结果查看
使用jar命令hadoop jar wordcount.jar hadoop.mapreduce.MyWordCount执行WordCount,并使用hadoop fs -cat 位置查看样例输出结果,如图68所示:
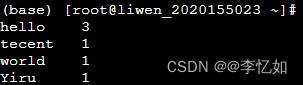
图68 WordCount结果样例
分析:如图68所示,程序可以按任务定义与规则输出样例中各个单词及数量,验证了基于MapReduce的WordCount程序设计与实现的合理性。
补充:实际上,MapReduce可以很好地应用于各种计算问题,如关系代数运算、分组与聚合运算、矩阵-向量乘法等,在实验五中的PageRank实际上也是基于MapReduce的简单应用。
3.基于MapReduce的电影推荐系统
在详解完MapReduce,并根据MapReduce实践了简单应用后,在本部分回到实验内容,正式构建基于MapReduce的电影推荐系统。
Tips:MapReduce只是一种框架,不同实现、不同环境仍会大大影响同一数据集的运行性能。
3.1 原理与系统设计
在对MapReduce熟悉了之后,对于特定的任务需要做原理的迁移与系统的设计。MapReduce框架的核心是Map与Reduce的设计与构建,故本电影推荐系统也是一样。对于基于MapReduce的电影推荐系统,具体系统设计如表21,执行过程(以Combiner为例)如图69所示:
表21 基于MapReduce的电影推荐系统设计
| 输入: 电影数据集(主要使用:movies.csv(dat)和ratings.csv(dat)) |
| 过程: |
| 1、数据处理与读取:将数据集上传到HDFS文件系统并读取 |
| 2、初始化:创建电影评分矩阵和评分(用户)同现矩阵 |
| 3、MapReduce处理:构造<电影,用户>键值对输入处理,并行计算相似度,排序 |
| 4、推荐:对输出进行规范化,并给目标用户对应推荐 |
| 5、系统构建(后文详解):数据可视化,搭建Web服务(or APP or uni-app) |
| 输出:电影推荐列表 |
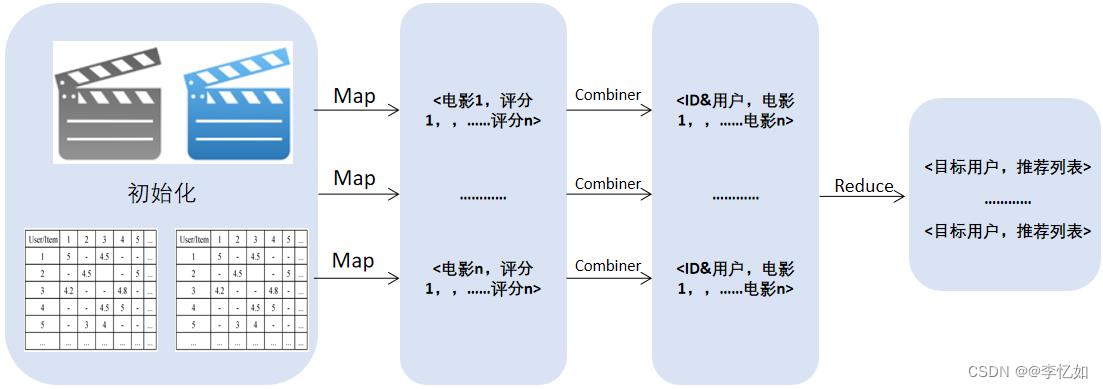
图69 电影推荐系统执行过程
3.2 代码实现与系统构建
在了解特定任务的原理与完成系统设计后,在本部分进入基于MapReduce的协同过滤电影推荐系统的构建,在二(2)中我们知道协同过滤是一类算法,故本系统构建以基于用户与基于项目的电影推荐系统为例,构建流程符合设计与执行过程的逻辑,此处仅做核心代码的解析。
(1)Map构造
对于MapReduce框架下基于用户的协同过滤,在Map部分实际上就是将构造好的“用户-项目矩阵”键值对化,在实现上主要是按读取的顺序,将用户赋予users数组,并将用户对所有电影评分写入userinfo变量,代码如图70所示:
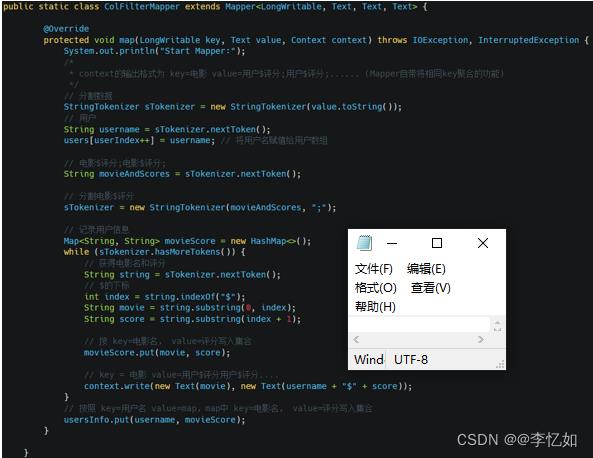
图70 Map构造代码
(2)Combiner构造
本系统未使用Shuffle,对于Combiner部分,主要是做键值对的形式变换。在实现上,将key值(电影名)辅导一维数组movies,并在后续利用不同用户评分差值(可使用其他相似度度量,总结如二(2.2.2))构造相似度,在保存与形式变换后按用户数量输出,核心代码如图71所示:
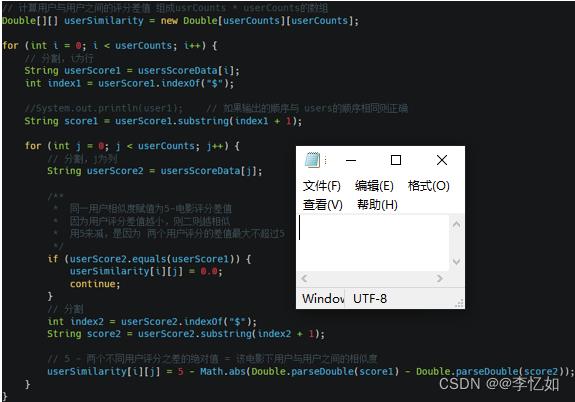
图71 Combiner构造核心代码
(3)Reduce构造
在本系统的Reduce部分,主要是将Combiner构造出的新键值对集合与相似性Map排序并按一定规则(例:该电影的推荐值大于所有电影对该用户的推荐度的平均值)对用户做电影推荐。核心代码如图72所示:

图72 Reduce构造核心代码
Tips:MapReduce框架下基于用户的协同过滤核心代码及解析到此结束,若要构建基于项目的,即将寻找相似用户转变为寻找相似电影即可。
3.3 系统测试
在构建好系统后,在本部分对系统进行测试,运行系统,电影推荐样例(以基于用户推荐,n=2为例)部分数据展示如图73所示:

图73 电影推荐样例
分析:由图73所示,系统成功按给定数量给多用户推荐电影,验证了MapReduce框架下的协同过滤系统构建成功。针对性能本部分不做评估,将在第五章与Spark框架下的系统做对比分析。
四、Spark
在上一章中,我们从背景、原理、架构与工作流程详解了大数据与云计算领域的经典框架——MapReduce,并使用它进行了简单应用,并构建了不同协同过滤方法的电影推荐系统。实际上,在MapReduce框架后还有许多优秀高效的框架,如基于MapReduce优化的Spark,本章将对Spark进行详解,并使用其进行协同过滤电影推荐系统的构建。
1.前置知识
在后续Spark的详解与系统构建中,有两个很重要的前置知识,分别是理论基石——RDD与算法构建基石——ALS,故在本部分先进行引入。
1.1 RDD
1.1.1 RDD简介与设计
RDD: 弹性分布式数据集,是Spark框架的理论基石,是分布式内存的一个抽象概念,RDD提供了一种分区的、高度受限的共享内存模型,基于此抽象,使用者可以在集群中执行一系列计算,而不用将中间结果落盘。首先对于RDD的主要设计总结于表22,样例(Spark Core的RDD)如图74所示:
表22 RDD的主要设计
| 1、显式抽象: 将运算中的数据集进行显式抽象,定义了其接口和属性。由于数据集抽象的统一,从而可以将不同的计算过程组合起来进行统一的 DAG 调度。 |
| 2、基于内存: 相较于 MapReduce 中间结果必须落盘,RDD 通过将结果保存在内存中,从而大大降低了单个算子计算延迟以及不同算子之间的加载延迟。 |
| 3、宽窄依赖: 在进行 DAG 调度时,定义了宽窄依赖的概念,并以此进行阶段划分,优化调度计算。 |
| 4、谱系容错: 主要依赖谱系图计算来进行错误恢复,而非进行冗余备份,因为内存实在是有限,只能以计算换存储了。 |
| 5、交互查询: 修改了 Scala 的解释器,使得可以交互式的查询基于多机内存的大型数据集。进而支持类 SQL 等高阶查询语言。 |

图74 RDD样例
1.1.2 RDD表示
在后续Spark调度中会需要了解Spark的依赖关系,故在此对RDD的表示做一定补充。
提供 RDD 抽象的一个难点在于,如何高效的跟踪谱系并能提供丰富的变换支持。最后论文选用了基于图的调度模型,将调度和算子进行了解耦。从而能够在不改变调度模块逻辑的前提下,很方便的增加算子支持。具体来说,RDD 抽象的核心组成主要有五个部分,总结如下:
- 分区集(partition set):分区是每个 RDD 的最小构成单元
- 依赖集(dependencies set):主要是 RDD 间的父子依赖关系
- 变换函数(compute function):作用于分区上的变换函数,由几个父分区计算得到一个子分区
- 分区模式(partition scheme):该 RDD 的分区是基于哈希分片的还是直接切分的
- 数据放置(data placement):知道分区的存放位置可以进行计算优化
而对于RDD的接口设计,最重要是如何对RDD间的依赖关系做规约,一般分为两种类型,总结如下,具体如图75所示:
- 窄依赖(narrow dependencies):父 RDD 的分区最多被一个子 RDD 的分区所依赖,比如 map
- 宽依赖(wide dependencies):父 RDD 的分区可能被多个子 RDD 的分区所依赖,比如 join
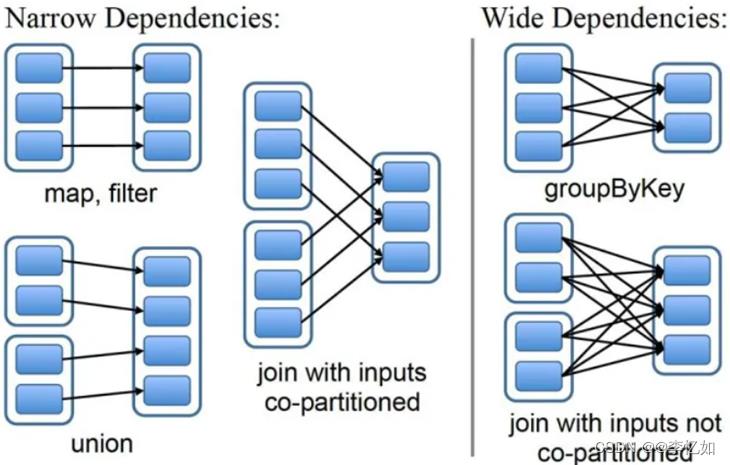
图75 RDD间依赖关系规约方式
至此,已对RDD做了理论简介,在后续Spark部分相关部分还会有提及,RDD详解可见原论文:RDD.pdf (usenix.org)。
1.2 ALS
ALS:交替最小二乘法,是Spark协同过滤的算法基础(官方实现的求解方法)。在本部分对其做简单引入与解析。
1.2.1 LS
ALS是基于LS(最小二乘法)的,故先对LS做简单引入,LS是一种数学优化技术,通过最小化误差平方和寻找数据的最佳匹配,利用最小二乘法寻找最优的未知数据,保证求的数据与已知的数据误差最小。核心是通过各种方法(直接求、Gram矩阵、QR分解等)求解目标函数(或正规方程),目标函数如式13,正规方程如式14:
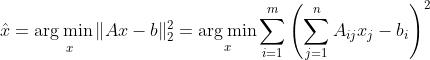
式13 最小二乘法目标函数定义
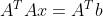
式14 最小二乘法正规方程
而正规方程实际上是由特解的梯度公式推导到全局梯度公式转化得到,核心转化如式15所示:

式15 梯度推广核心转换
补充:梯度下降(图29)实际上是简单的最小二乘法,较高效地求得局部最优解,而最小二乘法求解出全局闭式最优解。
1.2.1 ALS简介
ALS基本思想是对稀疏矩阵进行模型分解,评估出缺失项的值,以此来得到一个基本的训练模型。然后依照此模型可以针对新的用户和物品数据进行评估。ALS是采用交替的最小二乘法来算出缺失项的。其中,ALS同时考虑了User和Item两个方面,对于本任务(电影推荐)而言,ALS原理如图76所示:
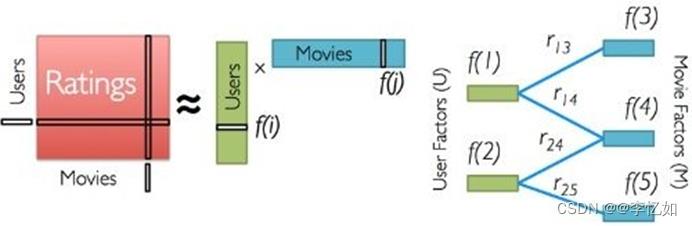
图76 电影推荐中ALS原理
如何算得因子矩阵里的因子数值是ALS要解决的问题,这需要一个明确的可量化目标,ALS用每个元素重构误差的平方和来进行量化。
在原评级矩阵中,大量未知元是我们想推断的,所以这个重构误差是包含未知数的。 而ALS的解决方案很简单:只计算已知打分的重构误差。
ALS的实现原理是迭代式求解一系列最小二乘回归问题。在每一次迭代时,固定用户因子矩阵或是物品因子矩阵中的一个,然后用固定的这个矩阵以及评级数据更新另一个矩阵。之后,被更新的矩阵被固定,再更新另外一个矩阵。如此迭代,直到模型收敛(或是迭代了预设好的次数)。
根据原理与解析,ALS的目标函数推导如式16:
推荐系统入门到项目实战:基于相似度推荐(含代码)