推荐系统入门到项目实战:基于相似度推荐(含代码)
Posted JOJO数据科学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统入门到项目实战:基于相似度推荐(含代码)相关的知识,希望对你有一定的参考价值。
【推荐系统】
- 🌸个人主页:JOJO数据科学
- 📝个人介绍:统计学top3高校统计学硕士在读
- 💌如果文章对你有帮助,欢迎✌
关注、👍点赞、✌收藏、👍订阅专栏- ✨本文收录于【推荐系统入门到项目实战】本系列主要分享一些学习推荐系统领域的方法和代码实现。
推荐系统:基于相似度推荐(含代码)
今天我们考虑一个很简单的问题,假设上线了两部新电影《黑豹2》和《简爱》,我们要给一个用户推荐一部电影看,我们很自然的一个想法是根据这个用户的历史观影情况来进行推荐,例如我们现在一个用户看过《蜘蛛侠》、《复仇者联盟》、《钢铁侠》,那么我相信大部分人会很自然的推荐《黑豹2》给他,大家问问自己为什么会这样推荐?
这背后的sense其实是因为我们认为《黑豹2》和他之前看过的电影是一个类型的,那么如何定义这些电影属于一个类型,这里其实就是根据相似度来进行推荐的。下面我们就来详细看看如何使用相似度来进行推荐
1.数据与问题定义
我们尝试建模的原数据可能包含user和item之间的历史交互数据,我们可能有一个电影评级集合,例如:

这种格式在许多流行的推荐数据集和任务中无处不在,包括非常流行的Netflix数据集。 这样的数据可能包括 “隐含信息”,比如评论、关于用户的个人信息或关于电影的元数据。
与其他类型的机器学习相比,推荐系统的主要区别在于其目标是根据历史模式对用户和所消费的物品之间的互动进行明确的建模。这一特点使模型能够理解哪些物品与哪些用户更相匹配,从而以个性化的方式向每个用户提出不同的建议,可以看做成是下面这个模型

如果我们对每个用户的推荐都只是具有最高预测评分 f(i) 的电影。换句话说,每个用户都会简单地被推荐具有与高评分相关的特征的电影。这样的模型无法个性化的进行个人用户的推荐。即使该模型在预测评分方面达到了合理的均方误差,它也不是一个有效的推荐系统。为了克服这个限制,模型必须以某种方式捕获用户和项目之间的交互,例如用户与特定电影的匹配度如何。研究用户和物品之间的交互是推荐系统的主要目标,也是将它们与其他类型的机器学习区分开来的主要特征
2.表示交互数据
我们现在知道了推荐系统主要是研究交互数据的,那我们如何表示这些交互数据以便于我们建立模型呢?
从集合或矩阵的角度来考虑这些数据会更方便。在建立用户之间在他们所消费的物品方面的相似性时,集合表示将是有用的;在建立基于矩阵分解(或降维)的模型时,矩阵表示将是有用的。
- 集合表示法:
I u = 用户 u 消费的物品 I_u = 用户u消费的物品 Iu=用户u消费的物品
U i = 消费物品 i 的用户 U_i = 消费物品i的用户 Ui=消费物品i的用户
- 矩阵表示法:
我们可以通过矩阵来表示用户/物品互动的数据集。交互矩阵可以描述用户与哪些物品进行了交互(C),或者可以提升我们之前的表示方法,得到代表真实含义的交互信息,例如评分(R)。
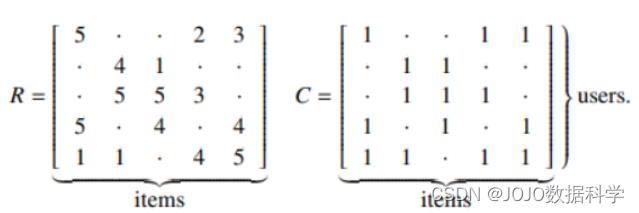
我们现在能够表示这些交互数据了,接下来就是如何通过这些数据来建模,之前我们介绍了推荐系统的整体框架,包括基于模型、基于领域、基于内容等,今天我们要介绍的相似度计算就属于基于领域的方法。
3.相似度计算
我们先来思考两个问题:
- 如何测量两个用户之间的相似度?
根据他们购买的物品
- 如何测量两个物品之间的相似度
根据购买他们的用户
接下来,我们要定义相似度函数,对于物品和物品之间的相似度计算,我们定义为:
S
i
m
(
i
,
j
)
Sim(i,j)
Sim(i,j)
然后,给定一个物品i,我们推荐一系列物品j使得这个相似度最大。
我们如何衡量这个相似度呢?
我们可以这样认为,两个集合,它们相同的元素越多,它们越相似。
那么,我们可以根据两个集合的交集来判断他们有多少个元素,但是为了避免集合本身大小的问题,我们再除以它们的并集,我们以这个结果来作为两个集合的相似度,这也就是我们所说的雅克比相似度
3.1 雅克比相似度(Jaccard Similarity)
J a c c a r d ( i , j ) = ∣ U i ∣ ⋂ ∣ U j ∣ ∣ U i ∣ ⋃ ∣ U j ∣ Jaccard(i,j) = \\frac|U_i|\\bigcap|U_j||U_i|\\bigcup|U_j| Jaccard(i,j)=∣Ui∣⋃∣Uj∣∣Ui∣⋂∣Uj∣
如果两个用户购买了完全相同的一组物品(或两个物品由同一组用户购买),则为最大值1。
如果两个用户购买完全不同的物品(或两个物品由完全不同的用户购买),则为最小值0
接下来我们再来思考一个问题,假设现在的数据集不再是交互集,而是一个向量,其中包含了用户对物品的态度
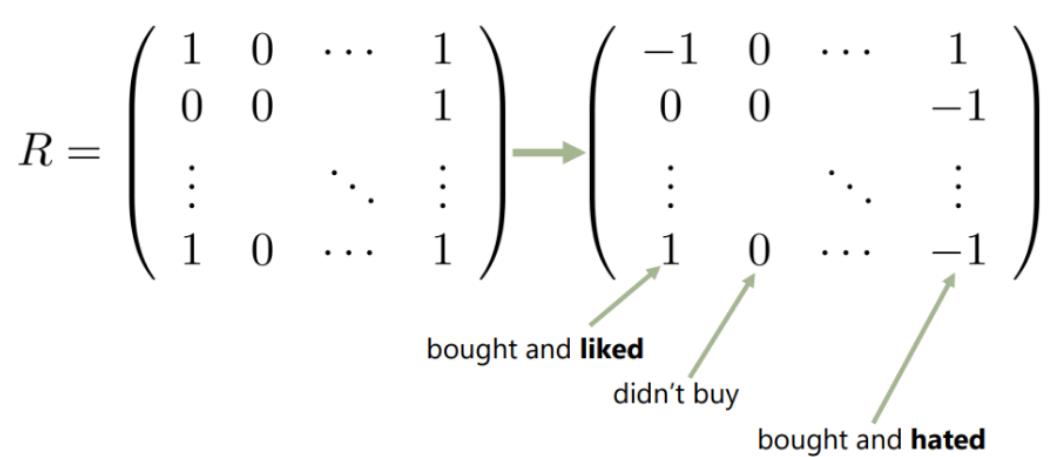
例如-1表示买了但是讨厌,1表示买了而且喜欢,这个时候如果我们用雅克比相似度,无法判断出用户对物品的评价,得出的结果会有问题。雅卡德相似度从直觉上告诉了我们关于哪些物品应该相互相似,但只有在这些交互被表示为集合时才会被定义。 对于反馈与每个交互相关的数据,我们希望有更细微的相似度测量;例如,如果两个用户都看了哈利波特的电影,我们可能不会将其视为 “相似”,因为他们中的一个喜欢这个系列,另一个不喜欢
因此,我们需要使用一种新的计算相似度的方法
3.2 余弦相似度(Cosine)
余弦相似度是根据向量 u1 和 u2 之间的夹角定义。
回想一下,两个向量 a 和 b 之间的夹角定义为:
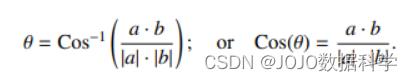
角度
θ
\\theta
θ测量两个向量指向同一方向的程度。现在假设有两个用户,我们定义他们之间的相似度为:
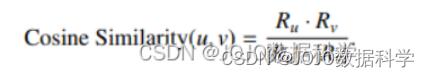
根据 Jaccard 相似度(仅基于交互),我们认为这两个用户是相同的(Jaccard 相似度为 1);根据余弦相似度,我们认为它们非常相似(两个向量之间的角度很小),当他们符号相反时,我们认为这两个用户具有相反的意见。
但是如果我们有一个评分数据集将5星视为正面评级,将3星视为负面评级,那么这两个用户确实具有相反的意见。但是余弦相似性的定义并不能解释这种行为,主要是因为它取决于已经具有明确正向或负向的相互作用。为了纠正这个问题,我们可能会适当地标准化我们的评级:如果我们将每个用户的评级减去平均数(u1和u2都是4颗星),我们会发现他们的评级都比平均数高或低一颗星。这个时候就和我们上一个例子的情况一样解决
3.3皮尔逊相关系数(Pearson coefficient)
上述情况基本上是皮尔逊相关系数所体现的思想。皮尔逊相关系数是评估两个变量之间关系的经典测量方法,也就是说,无论两个变量之间的规模和常数差异如何,它们是否有相同的趋势。两个向量x和y之间的皮尔逊相关系数被定义为
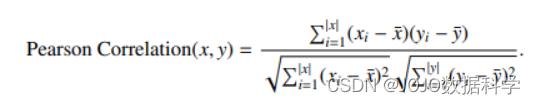
当把这个概念应用于评分数据时,我们应该注意不要把未观察到的评分视为零–这样做会影响我们对用户平均值的估计。因此,我们可以将两个用户u和v(或物品)之间的相似性只定义为他们都曾购买的物品。
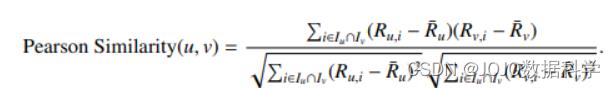
我们选择只考虑他们之间的共同物品来定义皮尔逊相似度是有点随意的;我们可以考虑在分母中为用户评价的所有项目。然后再使用我们的定义,如果用户之间评价较多相同的物品,且评价相似,我们就认为他们是较大的相似性;如果他们也评价了一些许多不同的物品,我们就认为用户的相似性较低。但是,这些相似度函数只是启发式的——任何一个选项都不应该被认为是更 "正确 "的,而是我们应该在特定情况下选择适合我们直觉的定义(或者产生最令人满意的结果)
4.实际应用
在 2003 年的一篇论文(Linden 等人,2003 年)中,研究人员描述了亚马逊推荐技术的基础技术。该论文描述了推荐相关项目的系统
该论文描述的第一个推荐方法是基于余弦相似。有趣的是,余弦相似度是在用户之间定义的,而不是像我们在 ;然后,目标是推荐类似客户以前购买过的商品。该论文讨论了将这种相似性计算扩展到大量亚马逊用户的问题,并讨论了一种基于用户到用户相似性指标对用户进行聚类的替代策略;然后可以通过确定用户的集群成员资格(这被视为分类问题)来找到与给定用户相似的客户。虽然论文很少详细介绍亚马逊实施的细节,他们的工作确实强调了现实世界中的关键点,大规模推荐系统不需要基于复杂的模型。相反,主要考虑因素包括构建简单但可扩展性好的模型,后续,有论文描述了亚马逊上更现代的推荐技术(Smith 和 Linden,2017)。该论文首先描述了对以上算法的微小修改,他们描述了一种基于物品对物品的方法,并描述了这种类型的问题的大部分计算可以离线完成。Smith和Linden(2017)还强调了选择一个好的相似性启发式的重要性,并讨论了一些这样做的策略。最后,Smith和Linden(2017)讨论了在设计推荐者时考虑时间因素的重要性。后续我们会进行相关讨论
现在我们可以总结亚马逊最初的推荐方案:
- 使用余弦相似度
- 用户之间的相似性是确定的:目标是推荐类似客户以前购买过的商品
- 主要挑战涉及可扩展性:如何对用户进行分组,以便我们能够快速识别类似的用户
这里我们可以发现。我们只用交互数据构建了一些非常有用的东西——我们没有利用物品(或用户)的任何特征
但是:我们仍然有一些问题需要解决
- 1.要在数据集足够大的情况下才有效,这实际上是有点慢的–如果一个用户购买了一个项目,这将改变其他所有至少被一个用户共同购买的项目的排名
- 2.对新用户和新项目没有用处("冷启动 "问题)
- 3.不一定会鼓励多样化的结果(推荐的广度问题,这也是需要trade-off的)
5.代码实现
import gzip
import math
import random
from collections import defaultdict
亚马逊乐器评论数据。来自
https://s3.amazonaws.com/amazon-reviews-pds/tsv/index.txt
下载链接https://drive.google.com/file/d/1mIAjz1YHcL56n0MtA3PmbcoqCd_RZZg9/view
5.1 数据准备
# 读取数据
path = "amazon_reviews_us_Musical_Instruments_v1_00.tsv.gz"
f = gzip.open(path, 'rt', encoding="utf8")
header = f.readline()
header = header.strip().split('\\t')
数据集有如下信息
header
['marketplace',
'customer_id',
'review_id',
'product_id',
'product_parent',
'product_title',
'product_category',
'star_rating',
'helpful_votes',
'total_votes',
'vine',
'verified_purchase',
'review_headline',
'review_body',
'review_date']
解析数据并在需要时将字段转换为整数
dataset = []
for line in f:
fields = line.strip().split('\\t')
d = dict(zip(header, fields))
d['star_rating'] = int(d['star_rating'])
d['helpful_votes'] = int(d['helpful_votes'])
d['total_votes'] = int(d['total_votes'])
dataset.append(d)
dataset[0]
'marketplace': 'US',
'customer_id': '45610553',
'review_id': 'RMDCHWD0Y5OZ9',
'product_id': 'B00HH62VB6',
'product_parent': '618218723',
'product_title': 'AGPtek® 10 Isolated Output 9V 12V 18V Guitar Pedal Board Power Supply Effect Pedals with Isolated Short Cricuit / Overcurrent Protection',
'product_category': 'Musical Instruments',
'star_rating': 3,
'helpful_votes': 0,
'total_votes': 1,
'vine': 'N',
'verified_purchase': 'N',
'review_headline': 'Three Stars',
'review_body': 'Works very good, but induces ALOT of noise.',
'review_date': '2015-08-31'
usersPerItem = defaultdict(set) # Maps an item to the users who rated it
itemsPerUser = defaultdict(set) # Maps a user to the items that they rated
itemNames =
ratingDict =
for d in dataset:
user,item = d['customer_id'], d['product_id']
usersPerItem[item].add(user)
itemsPerUser[user].add(item)
ratingDict[(user,item)] = d['star_rating']
itemNames[item] = d['product_title']
得到每一个用户和物品的平均值
userAverages =
itemAverages =
for u in itemsPerUser:
rs = [ratingDict[(u,i)] for i in itemsPerUser[u]]
userAverages[u] = sum(rs) / len(rs)
for i in usersPerItem:
rs = [ratingDict[(u,i)] for u in usersPerItem[i]]
itemAverages[i] = sum(rs) / len(rs)
5.2 相似度计算
Jaccard
def Jaccard(s1, s2):
number = len(s1.intersection(s2))#求交集
denom = len(s1.union(s2))#求并集
if denom == 0:
return 0
return number/denom
Cosine
对于集合数据集,我们定义如下
def CosineSet(s1, s2):
number = len(s1.intersection(s2))
denom = math.sqrt(len(s1))*math.sqrt(len(s2))
if denom == 0:
return 0
return number / denom
如果是评分数据集,我们定义如下:
def Cosine(i1, i2):
inter = usersPerItem[i1].intersection(usersPerItem[i2])#两者都有的物品
numer = 0
denom1 = 0
denom2 = 0
for u in inter:
numer += ratingDict[(u,i1)]*ratingDict[(u,i2)]
for u in usersPerItem[i1]:
denom1 += ratingDict[(u,i1)]**2
for u in usersPerItem[i2]:
denom2 += ratingDict[(u,i2)]**2
denom = math.sqrt(denom1) * math.sqrt(denom2)
if denom == 0:
return 0
return numer / denom
Person
def Pearson(i1, i2):
iBar1 = itemAverages[i1]
iBar2 = itemAverages[i2]
inter = usersPerItem[i1].intersection(usersPerItem[i2])
numer = 0
denom1 = 0
denom2 = 0
for u in inter:
numer += (ratingDict[(u,i1)] - iBar1)*(ratingDict[(u,i2)] - iBar2)
for u in inter: #usersPerItem[i1]:
denom1 += (ratingDict[(u,i1)] - iBar1)**2
#for u in usersPerItem[i2]:
denom2 += (ratingDict[(u,i2)] - iBar2)**2
denom = math.sqrt(denom1) * math.sqrt(denom2)
if denom == 0:
return 0
return numer / denom
检索与给定查询最相似的物品
def mostSimilar(i, N):
similarities = []
users = usersPerItem[i]
for i2 in usersPerItem:
if i2 == i: continue
sim = Jaccard(users, usersPerItem[i2])
similarities.append((sim,i2))
similarities.sort(reverse=True)
return similarities[:10]
随机设定一个待查询的物品
dataset[2]
'marketplace': 'US',
'customer_id': '6111003',
'review_id': 'RIZR67JKUDBI0',
'product_id': 'B0006VMBHI',
'product_parent': '603261968',
'product_title': 'AudioQuest LP record clean brush',
'product_category': 'Musical Instruments',
'star_rating': 3,
'helpful_votes': 0,
'total_votes': 1,
'vine': 'N',
'verified_purchase': 'Y',
'review_headline': 'Three Stars',
'review_body': 'removes dust. does not clean',
'review_date': '2015-08-31'
得到待查询的物品id
query = dataset[2]['product_id']
找出最相似的十个物品
ms = mostSimilar(query, 10)
ms
[(0.028446389496717725, 'B00006I5SD'),
(0.01694915254237288, 'B00006I5SB'),
(0.015065913370998116, 'B000AJR482'),
(0.014204545454545454, 'B00E7MVP3S'),
(0.008955223880597015, 'B001255YL2'),
(0.008849557522123894, 'B003EIRVO8'),
(0.008333333333333333, 'B0015VEZ22'),
(0.00821917808219178, 'B00006I5UH'),
(0.008021390374331552, 'B00008BWM7'),
(0.007656967840735069, 'B000H2BC4E')]
得到检索物品的名字
itemNames[query]
'AudioQuest LP record clean brush'
[itemNames[x[1]] for x in ms]
['Shure SFG-2 Stylus Tracking Force Gauge',
'Shure M97xE High-Performance Magnetic Phono Cartridge',
'ART Pro Audio DJPRE II Phono Turntable Preamplifier',
'Signstek Blue LCD Backlight Digital Long-Playing LP Turntable Stylus Force Scale Gauge Tester',
'Audio Technica AT120E/T Standard Mount Phono Cartridge',
'Technics: 45 Adaptor for Technics 1200 (SFWE010)',
'GruvGlide GRUVGLIDE DJ Package',
'STANTON MAGNETICS Record Cleaner Kit',
'Shure M97xE High-Performance Magnetic Phono Cartridge',
'Behringer PP400 Ultra Compact Phono Preamplifier']
def mostSimilarFast(i, N):
similarities = []
users = usersPerItem[i]
candidateItems = set()
for u in users:
candidateItems = candidateItems.union(itemsPerUser[u])
for i2 in candidateItems:
if i2 == i: continue
sim = Jaccard(users, usersPerItem[i2])
similarities.append((sim,i2))
similarities.sort(reverse=True)
return similarities[:N]
mostSimilarFast(query, 10)
[(0.028446389496717725, 'B00006I5SD'),
(0.01694915254237288, 'B00006I5SB'),
(0.015065913370998116, 'B000AJR482'),
(0.014204545454545454, 'B00E7MVP3S'),
(0.008955223880597015, 'B001255YL2'),
(0.008849557522123894, 'B003EIRVO8'),
(0.008333333333333333, 'B0015VEZ22'),
(0.00821917808219178, 'B00006I5UH'),
(0.008021390374331552, 'B00008BWM7'),
(0.007656967840735069, 'B000H2BC4E')]
评分预测:使用我们的相似度函数来估计评分。
从建立一些实用的数据结构开始。
reviewsPerUser = defaultdict(list)
reviewsPerItem = defaultdict(list)
for d in dataset:
user,item = d['customer_id'], d['product_id']
reviewsPerUser[user].append(d)
reviewsPerItem[item].append(d)
数据集的平均评分
ratingMean = sum([d['star_rating'] for d in dataset]) / len(dataset)
ratingMean
4.251102772543146
def predictRating(user,item):
ratings = []
similarities = []
for d in reviewsPerUser[user]:
i2 = d['product_id']
if i2 == item: continue
ratings.append(d['star_rating'] - itemAverages[i2])
similarities.append(Jaccard(usersPerItem[item],usersPerItem[i2]))
if (sum(similarities) > 0):
weightedRatings = [(x*y) for x,y in zip(ratings,similarities)]
return itemAverages[item] + sum(weightedRatings) / sum(similarities)
else:
return ratingMean
dataset[1]
'marketplace': 'US',
'customer_id': '14640079',
'review_id': 'RZSL0BALIYUNU',
'product_id': 'B003LRN53I',
'product_parent': '986692292',
'product_title': 'Sennheiser HD203 Closed-Back DJ Headphones',
'product_category': 'Musical Instruments',
'star_rating': 5,
'helpful_votes': 0,
'total_votes': 0,
'vine': 'N',
'verified_purchase': 'Y',
'review_headline': 'Five Stars',
'review_body': 'Nice headphones at a reasonable price.',
'review_date': '2015-08-31'
预测给定用户u对物品i的评分
u,i = dataset[1]['customer_id'], dataset[1]['product_id']
predictRating(u, i)
4.509357030989021
定义评估准则,这里我们使用最常用的MSE
def MSE(predictions, labels):
differences = [(x-y)**2 for x,y in zip(predictions,labels)]
return sum(differences) / len(differences)
alwaysPredictMean = [ratingMean for d in dataset]
simPredictions = [predictRating(d['customer_id'], d['product_id']) for d in dataset]
labels = [d['star_rating'] for d in dataset]
MSE(alwaysPredictMean, labels)
1.4796142779564334
MSE(simPredictions, labels)
以上是关于推荐系统入门到项目实战:基于相似度推荐(含代码)的主要内容,如果未能解决你的问题,请参考以下文章