NeurIPS | 达摩院联合华科开源基于流形结构对齐的零样本学习框架HSVA
Posted AI记忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NeurIPS | 达摩院联合华科开源基于流形结构对齐的零样本学习框架HSVA相关的知识,希望对你有一定的参考价值。
一、论文&代码
论文链接:HSVA: Hierarchical Semantic-Visual Adaptation for Zero-Shot Learning
开源代码:https://github.com/shiming-chen/HSVA
二、背景
本文介绍我们被机器学习顶会NeurIPS 2021 接收的论文 “HSVA: Hierarchical Semantic-Visual Adaptationfor Zero-Shot Learning”。Zero-shot learning (ZSL) 解决了unseen的类别识别问题,将语义知识从看得见的类别迁移到看不见的类别。通常,为了保证理想的知识迁移,采用公共(潜在)空间来关联 ZSL 中的视觉和语义域。然而,现有的通用空间学习方法仅通过一步适应来减轻分布不一致,从而对齐语义和视觉域。由于两个域中特征表示的异质性,这种策略通常是无效的,这两个域本质上包含分布和结构变化。为了解决这个问题,我们提出了一种新颖的层次化语义-视觉适应 (HSVA) 框架。
1.)Zero-shot Learning
如何将机器学习模型从已知的知识泛化到未知的场景?

2.) Formal Formulation of ZSL

3.)HSVA Motication
ZSL核心需要解决的是如何把已见类的语义知识迁移到未见类上。目前的方法更倾向于设计一个可以拉近语义和视觉分布的commonspace, 如下图的(a)。 但是由于视觉和语义信息是异构的,这就使得这两种信息之间的差异还应该包含结构上的不同,如下图(a),传统的ZSL之拉近视觉和语义信息之间的分布,会导致语义信息和视觉信息还是保留本身的流形结构。进一步,通过(c)和(d)的可视化也可以看到如果不加上流形结构上的对齐,不同类之间的边界不是很明显。

三、方法

基于上述的分析,我们在传统的one-stepzsl算法中(上图中的backbone net + distribution-adptation module)引入了structure-adaptionmodule来拉近视觉和语义信息之间的结构差异。
1.)Structure-Adaptation
●Semantic and Visual Embedding Classification
训练语义和视觉的分类器

●Discrepancy Maximization for Classifiers.
固定Encoder中的参数,最大化两个分类器之间的差异,使得视觉和语义信息的决策边界更明显

●Discrepancy Minimization for Encoders.
固定分类器中的参数,缩小encoder生成的视觉和语义信息的差异,使得视觉和语义信息的距离更近。
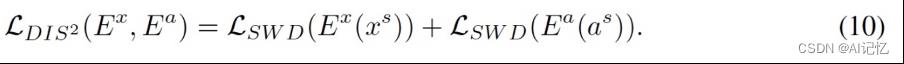
2.)Distribution Adaptation
为了保留structureadaption对齐的结构信息,这个模块跟[1],[2],[3],[4],[5]中所阐述的one-step zsl 采用2个encoder不同, 我们采用了一个commonencoder.
●拉近视觉和语义信息潜在的多元高斯分布的距离
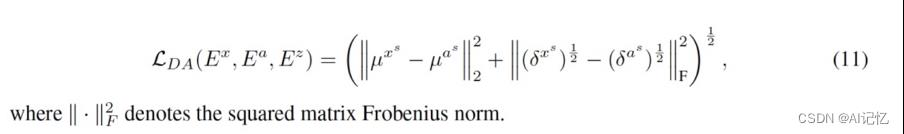
●为了避免未见类拟合到已见类,由于CORA可以很好地解决非对称性变化的域适应问题,我们用CORAL来衡量已见类和未见类之间的差异并增大。
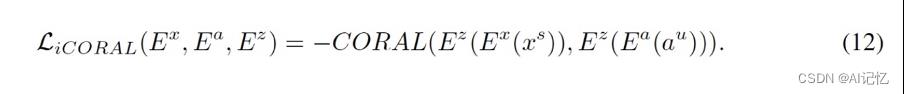
3.)Optimization

四、结果

五、应用
本文模型可以灵活应用在视觉任务的冷启动训练上。另外给大家介绍下CV域上的开源免费模型,欢迎大家体验、下载(大部分手机端即可体验):
https://modelscope.cn/models/damo/cv_resnet50_face-detection_retinaface/summary
https://modelscope.cn/models/damo/cv_resnet101_face-detection_cvpr22papermogface/summary
https://modelscope.cn/models/damo/cv_manual_face-detection_tinymog/summary
https://modelscope.cn/models/damo/cv_manual_face-detection_ulfd/summary
https://modelscope.cn/models/damo/cv_manual_face-detection_mtcnn/summary
https://modelscope.cn/models/damo/cv_resnet_face-recognition_facemask/summary
https://modelscope.cn/models/damo/cv_ir50_face-recognition_arcface/summary
https://modelscope.cn/models/damo/cv_manual_face-liveness_flir/summary
https://modelscope.cn/models/damo/cv_manual_face-liveness_flrgb/summary
https://modelscope.cn/models/damo/cv_manual_facial-landmark-confidence_flcm/summary
https://modelscope.cn/models/damo/cv_vgg19_facial-expression-recognition_fer/summary
https://modelscope.cn/models/damo/cv_resnet34_face-attribute-recognition_fairface/summary
以上是关于NeurIPS | 达摩院联合华科开源基于流形结构对齐的零样本学习框架HSVA的主要内容,如果未能解决你的问题,请参考以下文章