ICCV | 达摩院联合开源融合不确定度的自监督MVS框架
Posted AI记忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ICCV | 达摩院联合开源融合不确定度的自监督MVS框架相关的知识,希望对你有一定的参考价值。
一、论文&代码
论文链接:Digging into Uncertainty inSelf-supervised Multi-view Stereo
开源代码:https://github.com/ToughStoneX/U-MVS
二、背景
多视图立体视觉作为计算机视觉领域的一项基本的任务,利用同一场景在不同视角下的多张图片来重构3D的信息。如下图所示:

自监督多视角立体视觉(MVS)近年来取得了显著的进展。然而,以往的方法缺乏对自监督MVS中pretext任务提供的监督信号进行有效性的全面解释。本文首次提出在自监督MVS中估计认知不确定性(epistemic uncertainty)。具体而言,信号不确定可分为两类:前景的监督信号模棱两可性和背景监督信号无效性。为了解决这些问题,本文提出了一个新的减少不确定性的多视角立体(U-MVS)自监督学习框架:1.)本文引入了额外的光流深度一致性损失,利用光流的密集二维对应关系来正则化MVS中的三维立体对应关系,缓解前景监督的模凌两可。2.)为了处理背景的无效监督信号,本文使用Monte-Carlo Dropout获取不确定性映射,进一步过滤无效区域上的不可靠的监督信号。
最后通过在DTU和Tank&Temples数据集的大量实验表明,本文提出的U-MVS框架在无监督MVS方法中取得了最好的性能,与完全监督的MVS方法相比具有相媲美的性能。
2.1 完全监督MVS
随着深度学习的蓬勃发展,在多视角立体视觉领域已经出现越来越多的神经网络方法。作为新型技术的代表,MVSNet构建了端到端的基于神经网络来进行多视角重建的pipeline。首先利用2D的卷积网络来获得多视角图片的特征,然后运用3D CNN对由feature构建得到的costvolume进行正则化操作,而后基于soft argmin操作回归得到深度信息。如下图所示:

为了缓解存储和计算3D cost volume消耗大量的资源的压力,一些方法运用coarse-to-fine的机制将之前单步的cost volume的计算变为多阶段的cost volume 计算。CascadeMVSNet提出基于特征金字塔编码的cost volume,缩小每个阶段的深度(或视差)范围的预测,随着分辨率的逐渐提高和深度(或视差)间隔的自适应调整,输出coarse-to-fine的深度估计。如下图所示:

2.2 无监督MVS
此外,完全监督学习存在一个不可忽视的问题,标注large scale的数据集对于场景重建来讲,需要繁琐和昂贵的程序。近年来人们致力于发展自监督学习来替代有监督学习。Unsup MVS 利用预测的深度信息结合相机内外参数,通过homographywarping来重构图像,并通过减小重构图像和原始图像之间的差异来优化深度信息。如下图所示:
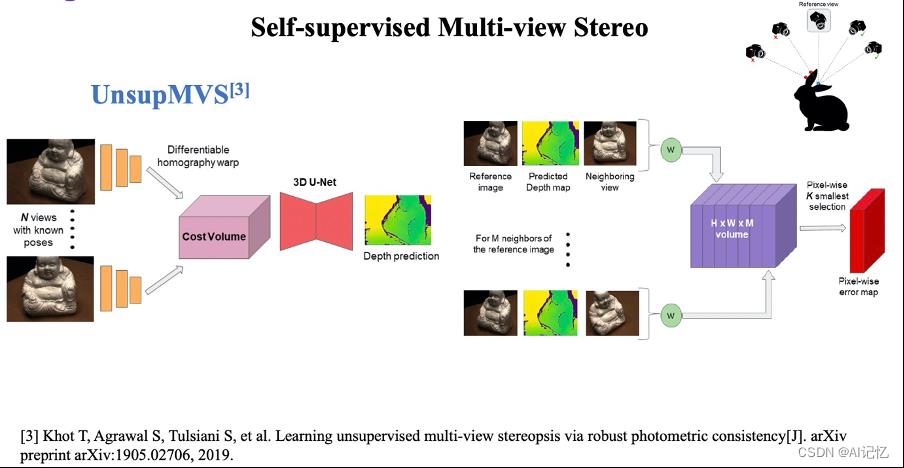
M^ 3VSNet在Unsup MVS 的基础上,增加了深度信息和法向的一致性loss来进一步优化pipiline,而JDACS则利用非负矩阵分解(Non-Negative-Factorization)来生成Co-Segmentationmaps,借鉴photometric loss,构造更鲁棒的cross-viewsemantic consistency,同时利用数据增强模块来提升泛化能力。如下图所示:


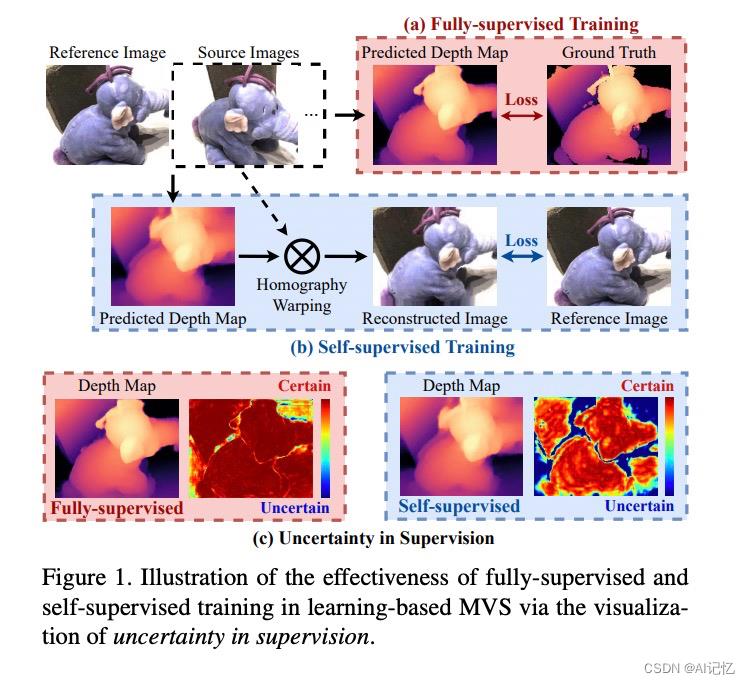
之前这些方法都是基于对于自监督学习的直观的分析,缺乏对于自监督信号有效性的研究和解释。对于完全监督学习,如Figure 1 (a)所示,有效监督信号因为ground truth的原因是显性可用的,然而对于自监督框架来讲,如Figure 1 (b)所示,基于图像重建的pretext任务提供的监督信号是模糊不确定的,这将直接影响深度估计的效果。
2.3 核心解决问题
为了更直接地提供监督信号的有效性描述,本文利用了Monte-Carlo Dropout方法来可视化epistemic uncertainty,如上图Figure 1(c)所示。那么不确定性到底可以给我们哪一些启示呢?

如上图Figure 2 所示,本文提供了完全监督和自监督信号的不确定性直观比较,来加深理解导致自监督信号失败的原因。由图可知,自监督信号相比完全监督的信号有更多不确定性,基于自监督作为图像重建任务的前提,将不确定性归结为两类:第一类为图像前景中的监督信号的模凌两可性,主要来自于不同视角下像素点的颜色变化以及物体之间的遮挡,导致了reference image和source image的部分像素点没法很好的匹配;第二类为背景的监督信号的无效性,譬如无纹理区域没法提供有效信息。
三、方法
3.1 前景监督信号
为了解决前景监督信号的模凌两可,本文通过增加额外的先验相关性来增强自监督信号的可靠性,并引入一种新的多视图中的光流深度一致性损失。如下图所示:

直观地说,在自监督MVS中,可以利用光流来构造图像对的像素点之间密集的相关性来正则化3D的相关性。本文提出了一个可微的Depth2Flow模块,将视图间的深度图转换为虚拟光流。如下图所示:

RGB2Flow模块可以无监督地预测相应视图的光流。然后强制虚拟光流和真实光流保持一致,起到正则化的作用。如下图所示:

3.2 背景监督信号
为了缓解背景信号的无效性,本文建议除去不可靠的监督信号在完全无监督的情况下。首先使用自监督预训练模型标注数据集,并用Monte-Carlo-Dropout算法获取不确定性映射。如下图所示:

然后利用不确定性映射过滤之后的伪标签对模型进行监督。同时对输入的多视图图像进行随机数据增强,增强有效监督区域对干扰的鲁棒性。如下图所示:


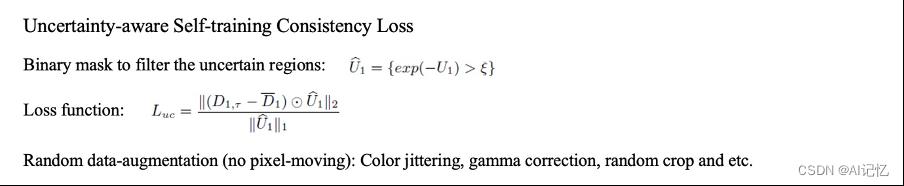
四、结果
为了评价本文提出的方法的性能,在DTU数据集上进行了验证。在Table 1,本文给出了UMVS与最好的(SOTA)完全监督/自监督和传统方法的性能对比。从表中可以看出,本文提出的方法比之前的自监督方法性能更好。在整体误差(overall)的指标下,当前SOTA的完全监督方法的性能约为0.351 - 0.355mm。在没有利用任何ground truth标签的前提下,本文基于CascadeMVSNet的backbone可以在overall达到0.3537,这与完全监督的SOTA相媲美。Figure 5 给出了DTU数据集上多个场景的三维重建结果的定性比较。如下图所示:


为了评价本文方法的泛化能力,给出了Tanks and Temples数据集上(intermediate/advanced)与SOTA的完全监督和无监督方法的性能比较(Table 4和Table 5)。
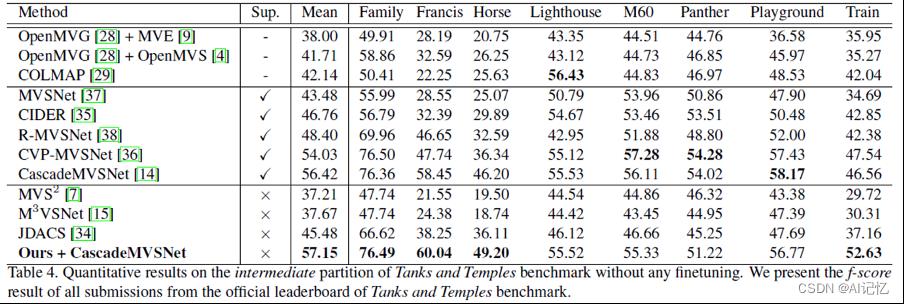

如下图例为Tanks&Temples的intermediate/advancedpartition部分的效果可视化。


五、应用
本文模型将在maas上呈现,敬请期待。另外给大家介绍下其他域上的开源免费模型,欢迎大家体验、下载(大部分手机端即可体验):
https://modelscope.cn/models/damo/cv_resnet50_face-detection_retinaface/summary
https://modelscope.cn/models/damo/cv_resnet101_face-detection_cvpr22papermogface/summary
https://modelscope.cn/models/damo/cv_manual_face-detection_tinymog/summary
https://modelscope.cn/models/damo/cv_manual_face-detection_ulfd/summary
https://modelscope.cn/models/damo/cv_manual_face-detection_mtcnn/summary
https://modelscope.cn/models/damo/cv_resnet_face-recognition_facemask/summary
https://modelscope.cn/models/damo/cv_ir50_face-recognition_arcface/summary
https://modelscope.cn/models/damo/cv_manual_face-liveness_flir/summary
https://modelscope.cn/models/damo/cv_manual_face-liveness_flrgb/summary
https://modelscope.cn/models/damo/cv_manual_facial-landmark-confidence_flcm/summary
https://modelscope.cn/models/damo/cv_vgg19_facial-expression-recognition_fer/summary
https://modelscope.cn/models/damo/cv_resnet34_face-attribute-recognition_fairface/summary
以上是关于ICCV | 达摩院联合开源融合不确定度的自监督MVS框架的主要内容,如果未能解决你的问题,请参考以下文章
NeurIPS | 达摩院联合华科开源基于流形结构对齐的零样本学习框架HSVA
达摩院发布2023十大科技趋势,多领域“日进一寸”式融合创新