PyTorch学习3《PyTorch深度学习实践》——反向传播(Back Propagation)
Posted 小龙呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch学习3《PyTorch深度学习实践》——反向传播(Back Propagation)相关的知识,希望对你有一定的参考价值。
目录
一、Tensor
1.定义
张量的定义是一个可用来表示在一些矢量、标量和其他张量之间的线性关系的多线性函数。
在PyTorch上有这样一句话,A torch.Tensor is a multi-dimensional matrix containing elements of a single data type.而在应用时,Tensor是一个神奇的东西,注意这里的类型是<class ‘torch.Tensor’>

2.Tensor常见形式
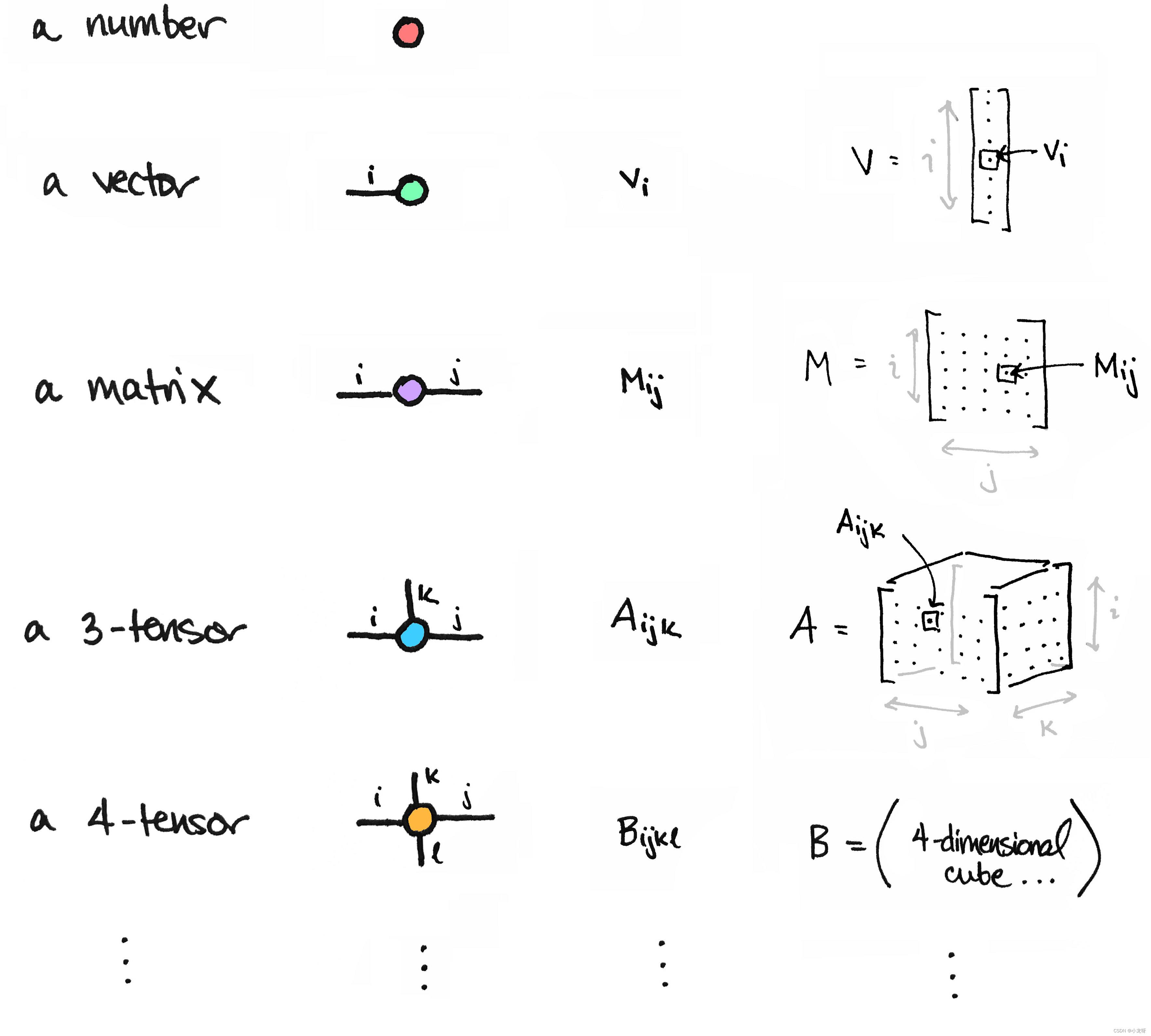
3.torch.tensor和torch.Tensor
看完下面这个代码你就知道区别了
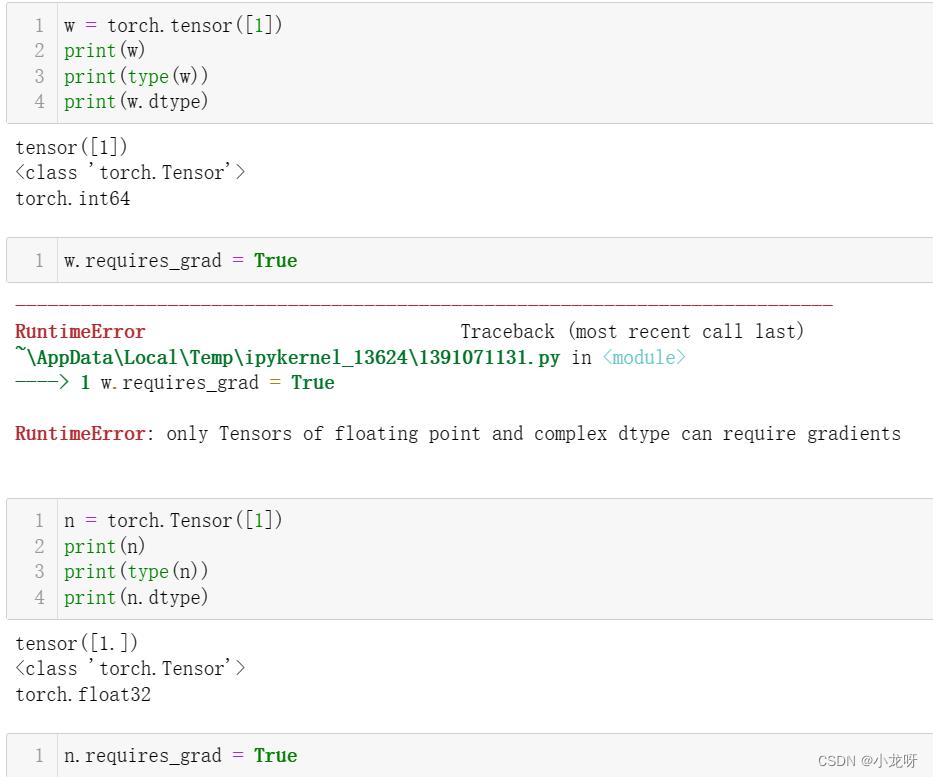
从某种意义下,或者你需要这样初始化,才能使torch.tensor和torch.Tensor看起来一样
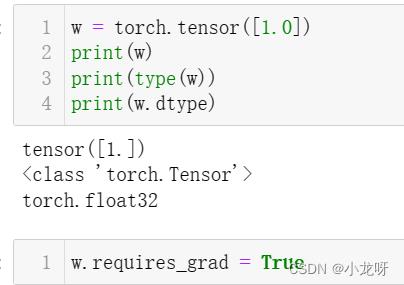
4.Tensor.grad

Tensor.grad,它的属性默认是None,当第一次调用backward()为它自己计算梯度的时候才会变成一个Tensor。这个属性将会包含这些计算的梯度,并且未来调用backward()将会把梯度累加进去。这也是为什么我们在更新梯度的时候需要清零的原因。
我就基本介绍这些啦,需要了解更多的可以查看官网:https://pytorch.org/docs/stable/tensors.html
二、反向传播
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.tensor([1.0]) # w的初值为1.0
w.requires_grad = True # 需要计算梯度
def forward(x):
return x * w # w是一个Tensor
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
print("predict (before training)", 4, forward(4).item(), '\\n') #Tensor.item()只会返回一个元素的Tensor
for epoch in range(10):
for x, y in zip(x_data, y_data):
l = loss(x, y)
l.backward() # 反向传播
print('\\tgrad:', x, y, w.grad.item())
print(w.grad.data, type(w.grad.data))
print(w, type(w), '\\n')
w.data = w.data - 0.01 * w.grad.data
w.grad.data.zero_() # 更新后,梯度清零
print('progress:', epoch, l.item(), type(l), '\\n')
print("predict (after training)", 4, forward(4).item())
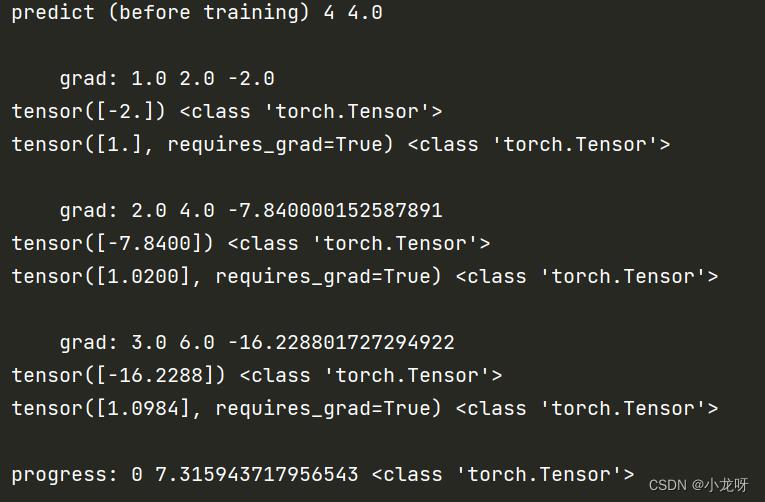
这个代码实现是很简单的,但是里面的各种类的定义和嵌套,可以好好对应这个输出结果查看一下,加深理解。
以上是关于PyTorch学习3《PyTorch深度学习实践》——反向传播(Back Propagation)的主要内容,如果未能解决你的问题,请参考以下文章