Oracle LiveLabs实验:Manage and Monitor Autonomous Database
Posted dingdingfish
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Oracle LiveLabs实验:Manage and Monitor Autonomous Database相关的知识,希望对你有一定的参考价值。
概述
本研讨会中的实验将引导您完成开始使用 Oracle 自治数据库的所有步骤。 首先,您将创建一个 Oracle 自治数据库实例。 然后,您将练习使用自治数据库工具和 API 从不同位置以不同格式加载数据的几种方法。 您将使用 SQL 分析数据并使用 Oracle Analytics Cloud 构建分析仪表板。
此实验申请地址在这里。
实验帮助在这里。
此实验预估完成时间3小时。此实验不提供实验环境。可刷新克隆和Autonomous Data Guard在LiveLabs环境中不支持,其它的可以复用此实验的前半部分Oracle LiveLabs实验:Load and Analyze Your Data with Autonomous Database的环境。
本实验的作者为Rick Green等,包括RWP的成员。
实验 6:使用或不使用 Connection Wallet 进行安全连接
介绍
Oracle 自治数据仓库 (ADW) 和自治事务处理 (ATP) 仅接受与 Oracle 自治数据库的安全连接。 本实验将引导您完成将 Oracle SQL Developer 桌面客户端安全连接到您的自治数据库的步骤,无论是否使用连接钱包。 首先,您将学习如何在没有钱包的情况下使用 TLS 连接安全地通过 SQL Developer连接。 然后,您将下载并配置一个连接钱包作为另一种将 SQL Developer 安全连接到您的自治数据库的方法。
(本次研讨会之前的实验室使用 Database Actions 中的 SQL Worksheet,无需连接钱包即可直接从云控制台访问自治数据库。SQL Worksheet 是一个方便的基于浏览器的工具,提供 Oracle SQL Developer 中的部分特性和功能 .)
任务 1:无需钱包即可将 SQL Developer 安全连接到数据库
我们将学习建立与自治数据库的安全 SQL Developer 连接的两种方法中的第一种:使用 TLS 身份验证在没有钱包的情况下安全连接。
当您使用“Secure access from everywhere”的网络访问类型来配置自治数据库实例时,默认情况下需要 mTLS (mutual TLS)身份验证,并且除了 mTLS 之外启用 TLS 的唯一方法是定义访问控制列表 (ACL) 或使用私有端点。 在本实验中,您将配置一个 IP ACL(访问控制列表)。 然后,您将能够取消选中“需要相互 TLS”复选框,这反过来将启用 TLS 以在没有钱包的情况下进行连接。
注意:有关允许 TLS 连接的详细信息,请参阅文档更新您的自治数据库实例以允许 TLS 和 mTLS 身份验证。
首先,定义一个 IP ACL(访问控制列表)。 在自治数据库详细信息页面的Network 部分中,单击Access control list旁边的编辑按钮。
在Edit Access Control List对话框中,单击Add My IP Address。
注意,系统会自动填写 My IP Address,启用或不启用VPN时,My IP Address是不同的
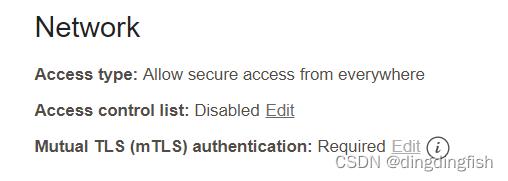
在自治数据库详细信息页面的网络部分中,请注意,访问类型已自动从您在配置数据库时使用的默认访问类型(Allow secure access from everywhere)更改为Allow secure access from specified IPs and VCNs。 单击Mutual TLS (mTLS) 身份验证旁边的编辑按钮。
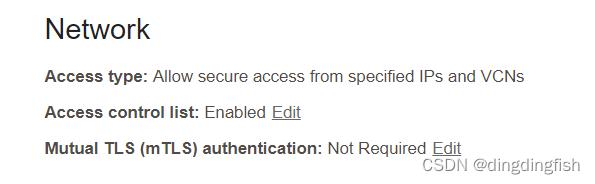
在 Edit Mutual TLS Authentication 对话框中,取消选中Require mutual TLS (mTLS) authentication复选框,然后单击 Save Changes。 等待一分钟,让数据库状态从 UPDATING 更改为 AVAILABLE。
接下来,执行以下步骤以获取 TLS 连接字符串。
在自治数据库详细信息页面中,单击DB Connection按钮。
弹出数据库连接对话框。 在 Connection Strings 部分中,将 TLS Authentication 选择从 Mutual TLS 更改为 TLS。 这将使 SQL Developer 和其他应用程序无需钱包即可安全地连接到您的自治数据库。
选择其中一个连接字符串,例如 adwfinance_high,并可选择单击显示以查看连接字符串的内容。 然后单击复制以复制该连接字符串。 将连接字符串粘贴到记事本中以供下一步使用。 然后单击关闭关闭数据库连接对话框。
以下是Mutual TLS和TLS网络服务名的区别:
-- Mutual TLS
(description= (retry_count=20)(retry_delay=3)(address=(protocol=tcps)(port=1522)(host=adb.ap-seoul-1.oraclecloud.com))(connect_data=(service_name=t5o0ykysocwb58j_o1vbz1q0bsnht7qv_high.adb.oraclecloud.com))(security=(ssl_server_cert_dn="CN=adb.ap-seoul-1.oraclecloud.com, OU=Oracle ADB SEOUL, O=Oracle Corporation, L=Redwood City, ST=California, C=US")))
-- TLS,无需wallet
(description= (retry_count=20)(retry_delay=3)(address=(protocol=tcps)(port=1521)(host=adb.ap-seoul-1.oraclecloud.com))(connect_data=(service_name=t5o0ykysocwb58j_o1vbz1q0bsnht7qv_high.adb.oraclecloud.com))(security=(ssl_server_dn_match=yes)))
有关查看和复制连接字符串的更多信息,请参阅文档View TNS Names and Connection Strings for an Autonomous Database Instance。
在SQL Developer中创建连接,其中:
- Connection Type: 选择 Custom JDBC.
- jdbc:oracle:thin:@ 加上之前的TLS连接串。
- 用户名:ADMIN
拼接后的连接串为:
jdbc:oracle:thin:@(description= (retry_count=20)(retry_delay=3)(address=(protocol=tcps)(port=1521)(host=adb.ap-seoul-1.oraclecloud.com))(connect_data=(service_name=t5o0ykysocwb58j_o1vbz1q0bsnht7qv_high.adb.oraclecloud.com))(security=(ssl_server_dn_match=yes)))
测试连接成功。
任务 2:下载连接钱包
单击DB Connection按钮,下载client credentials (Wallet),实际是一个zip文件。Wallet Type选择Instance Wallet(此钱包类型仅适用于单个数据库。 这提供了一个特定于数据库的钱包。)。另一种钱包类型为Regional Wallet。
注意:Oracle 建议您提供特定于数据库的钱包,即尽可能提供实例钱包给最终用户和应用程序使用。 区域钱包应仅用于需要潜在访问区域内所有自治数据库的管理目的。
指定您选择的钱包密码。 稍后通过 SQL Developer 连接到数据库时,您将需要此密码。 该密码还用作使用 JKS 进行安全性的 JDBC 应用程序的 JKS Keystore 密码。
任务 3:使用 Wallet 将 SQL Developer 安全连接到数据库
使用 SQL Developer创建连接:
- 连接类型:Cloud Wallet
- Configuration File:刚刚下载的钱包文件,例如
Wallet_O1VBZ1Q0BSNHT7QV.zip。
测试连接成功。
如果您在 VPN 或防火墙后面并且此测试失败,请确保您拥有 SQL Developer 18.3 或更高版本。 此版本及更高版本将允许您为云钱包类型的连接选择“使用 HTTP 代理主机”选项。 在此处创建新的 ADW 连接时,请提供代理的主机和端口。 如果您不确定在哪里可以找到它,您可以查看计算机的连接设置或联系您的网络管理员。
任务 4:使用 SQL Developer 查询您的自治数据库
在默认的SH schema中,可以运行以下SQL:
SELECT channel_desc, TO_CHAR(SUM(amount_sold),'9,999,999,999') SALES$,
RANK() OVER (ORDER BY SUM(amount_sold)) AS default_rank,
RANK() OVER (ORDER BY SUM(amount_sold) DESC NULLS LAST) AS custom_rank
FROM sh.sales, sh.products, sh.customers, sh.times, sh.channels, sh.countries
WHERE sales.prod_id=products.prod_id AND sales.cust_id=customers.cust_id
AND customers.country_id = countries.country_id AND sales.time_id=times.time_id
AND sales.channel_id=channels.channel_id
AND times.calendar_month_desc IN ('2000-09', '2000-10')
AND country_iso_code='US'
GROUP BY channel_desc;
CHANNEL_DESC SALES$ DEFAULT_RANK CUSTOM_RANK
-------------------- -------------- ------------ -----------
Direct Sales 1,320,497 3 1
Partners 800,871 2 2
Internet 261,278 1 3
想了解更多?
在自治数据库共享中查看连接选项的文档。
在自治数据库共享中查看网络配置选项的文档。
查看博客文章“连接到您的自治数据库从未如此简单”,了解如何使用单向传输层安全 (TLS) 身份验证将您的客户端工具安全地连接到没有钱包的自治数据库。
实验室 7:监控和管理
介绍
在本实验中,您将探索可用于自治数据库 (ADB) 的监控功能。
Oracle 提供了多种工具来监视自治数据库的性能和活动。 其中有:
- 数据库服务控制台(Service Console),面向数据库管理员、开发人员、数据科学家
- OCI 监控控制台(OCI Monitoring Console),面向云管理员和业务用户
- 性能中心(Performance Hub)
- 自治数据库指标
本实验覆盖前3项。
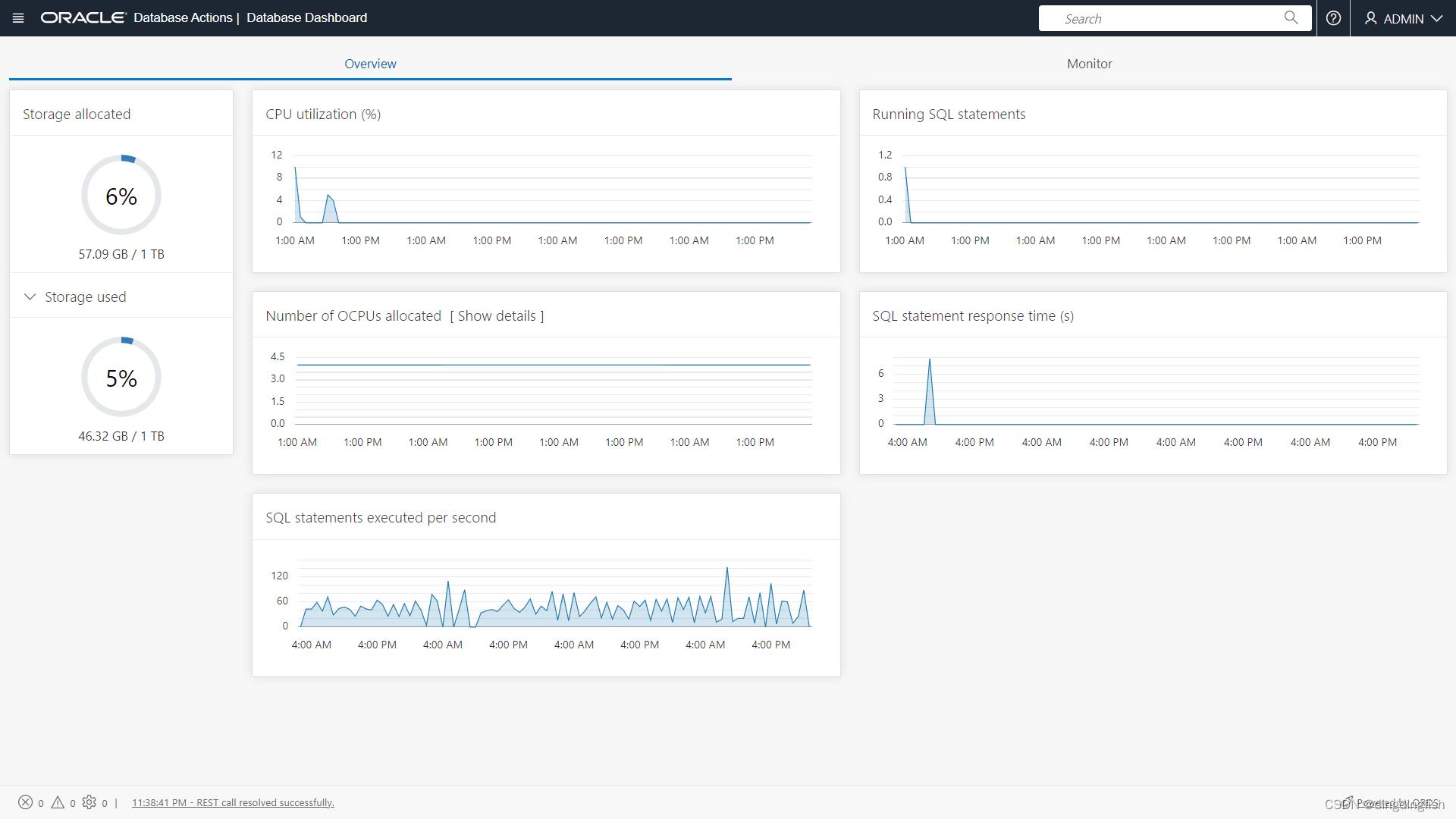
ADB 服务控制台提供仪表板来监控实时和历史 CPU 和存储利用率,以及数据库活动,例如正在运行或排队的语句的数量。 它还提供实时 SQL 监控以查看您的实例中当前和过去长时间运行的 SQL 语句,并允许您取消长时间运行的查询或为 ADW 或 ATP 设置阈值以自动为您取消它们。
任务 1:导航到服务控制台
现在叫Database Dashboard了,在Database Actions菜单里。
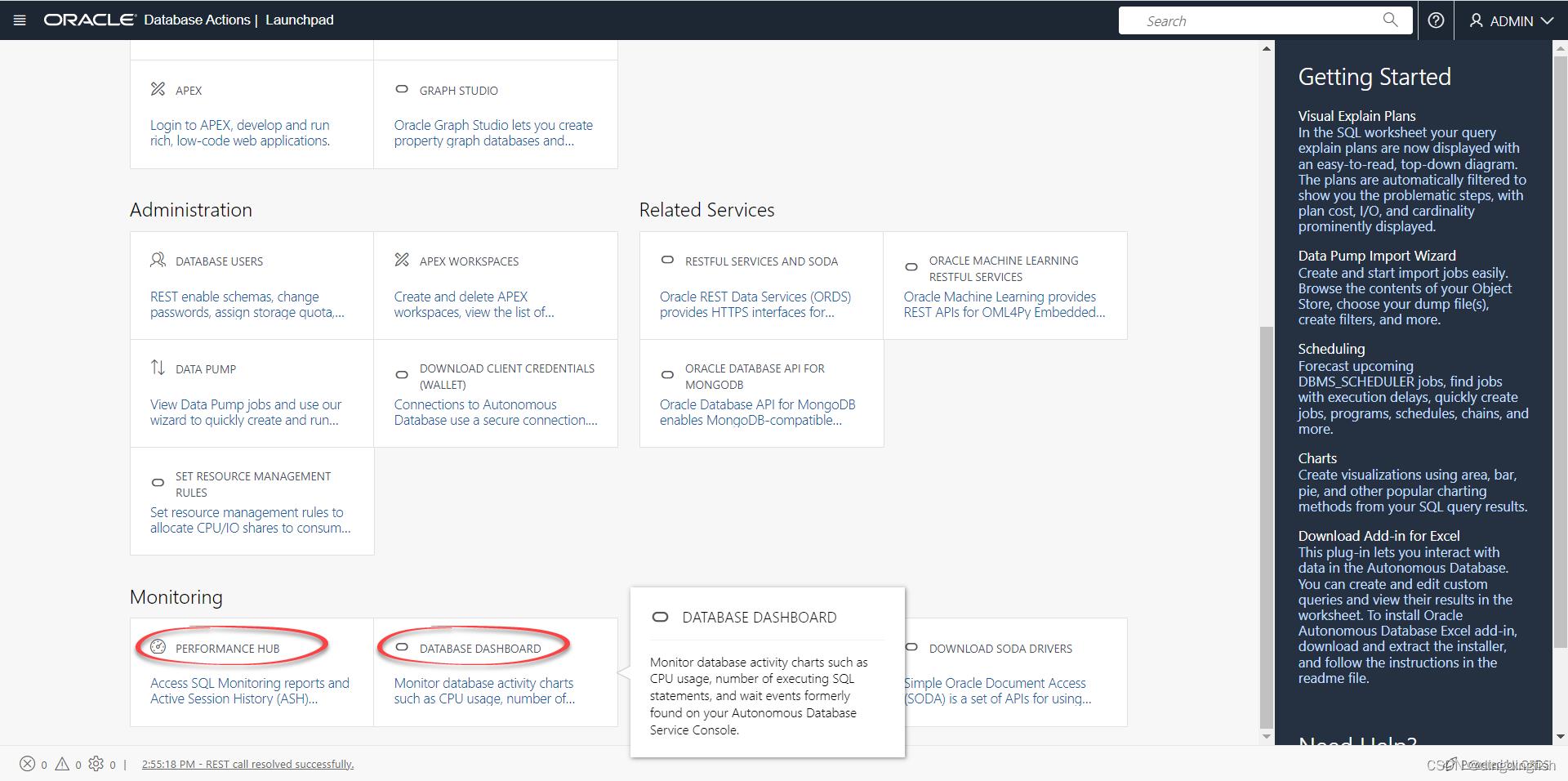
检查数据库活动:Database Activity、CPU Utilization、Running Statements、Queued Statements。
任务 2:检查控制台概览页面
在Database Dashboard中,有Overview和Monitor两个标签页。
任务 3:检查控制台活动页面
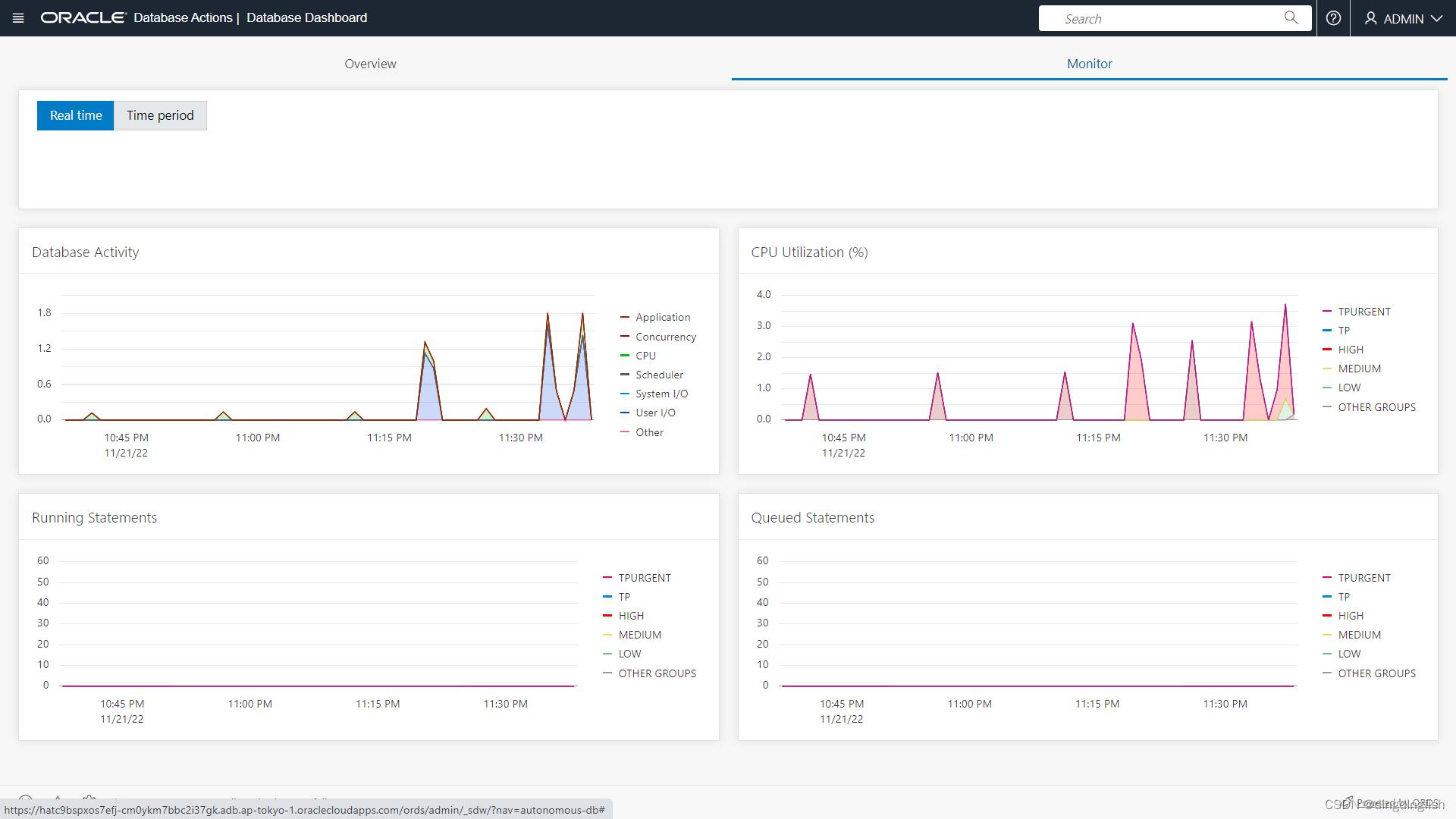
在Monitor标签页,可以查询实时(Real Time)的和历史(Time Period)的性能数据。性能数据的默认保留期为八天。
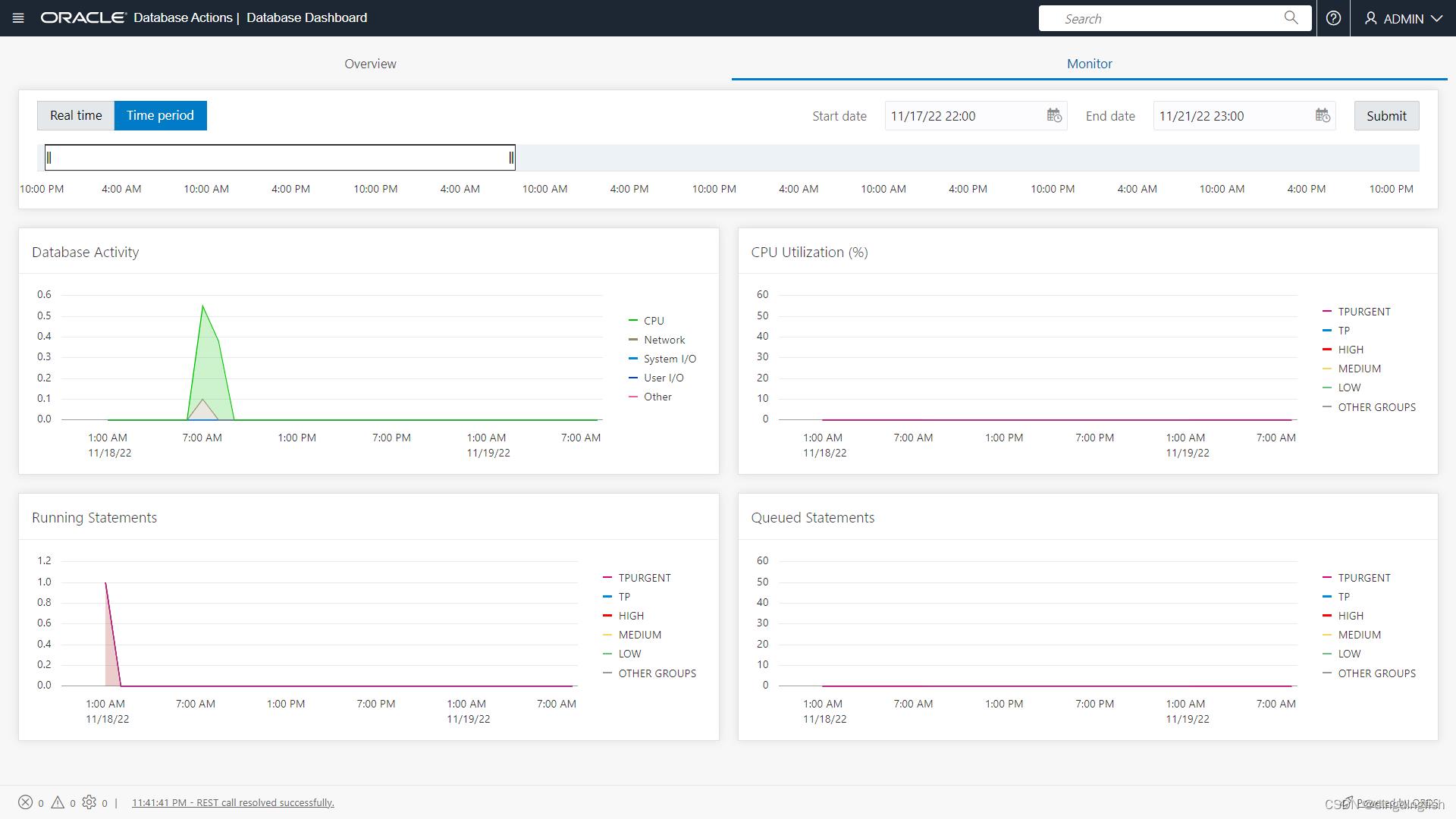
在时间段视图中,您可以使用日历查看过去八天的特定时间段。 您还可以使用时间滑块更改显示性能数据的时间段。
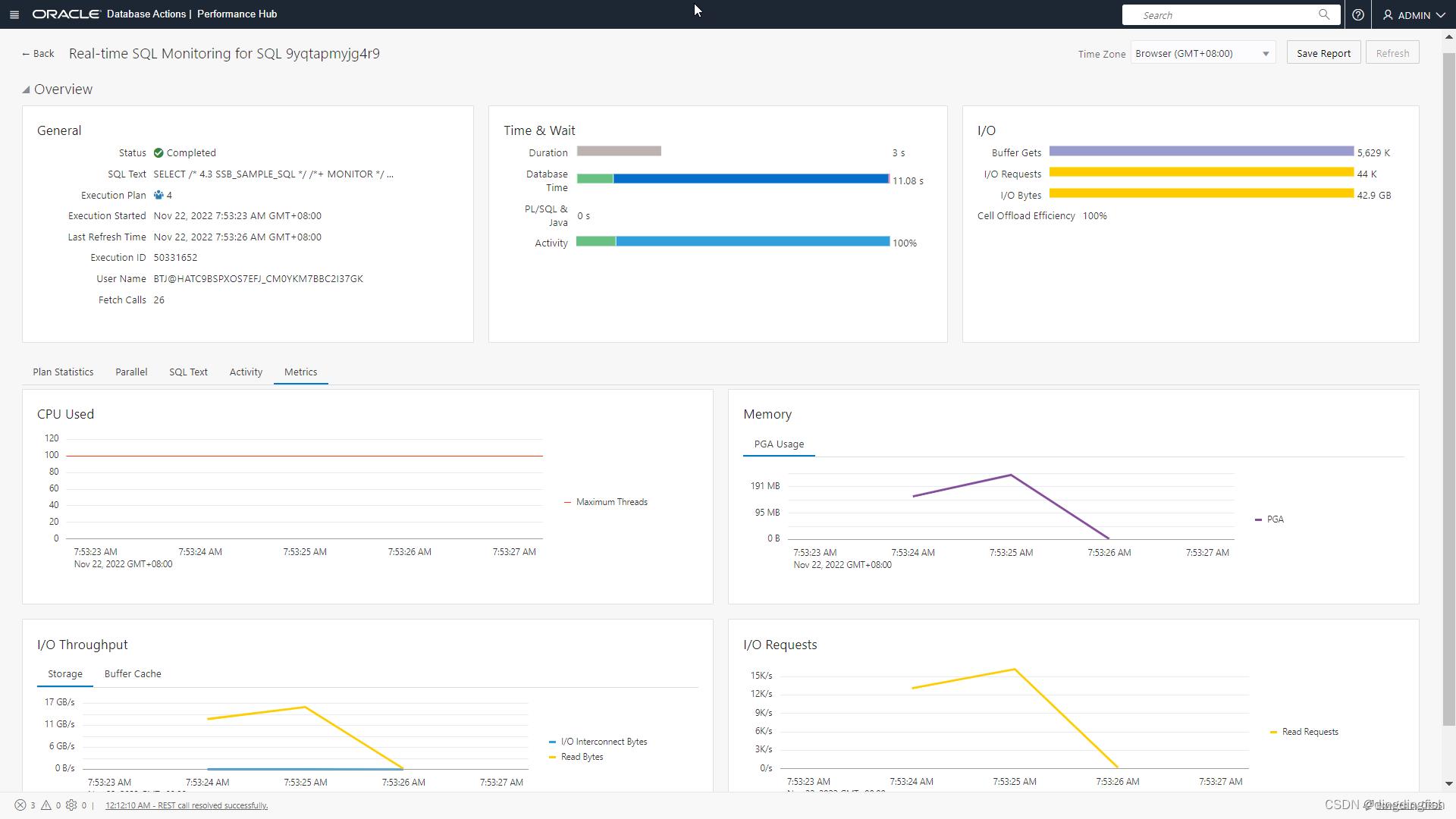
任务 4:监控 SQL 语句
此功能目前在Database Actions的Performance Hub中。
任务 5:检查 OCI 监控控制台
进入菜单“Observability & Management>Service Metrics”
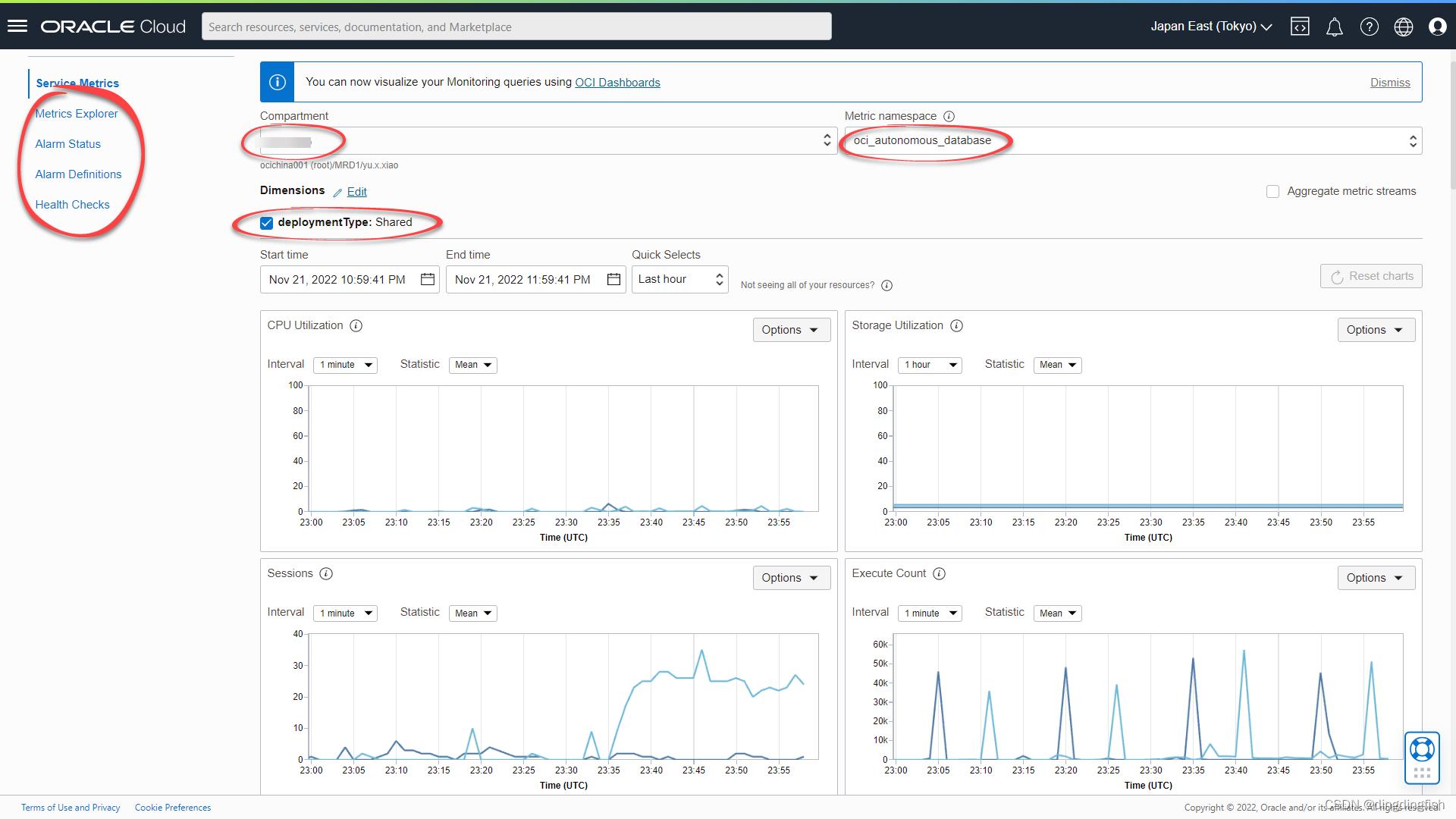
现在,您可以使用OCI仪表板对监控查询进行可视化。
任务 6:从性能中心查看性能数据
此功能目前在自治数据库的Performance Hub中。大部分信息都在SQL Monitor Report中。
注意,在自治数据库主页面和Database Actions中都有Performance Hub,前者更加全面和详细
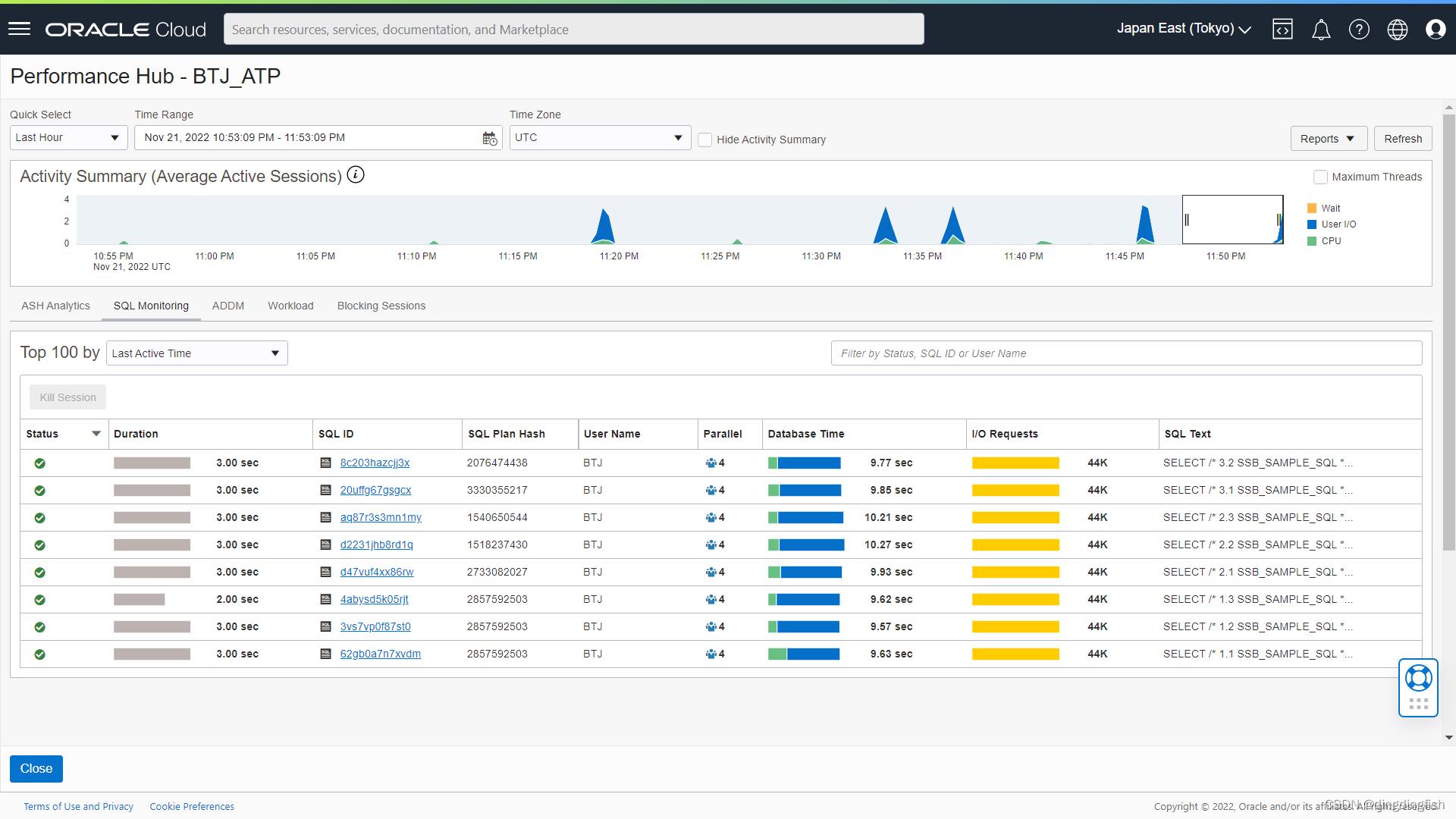
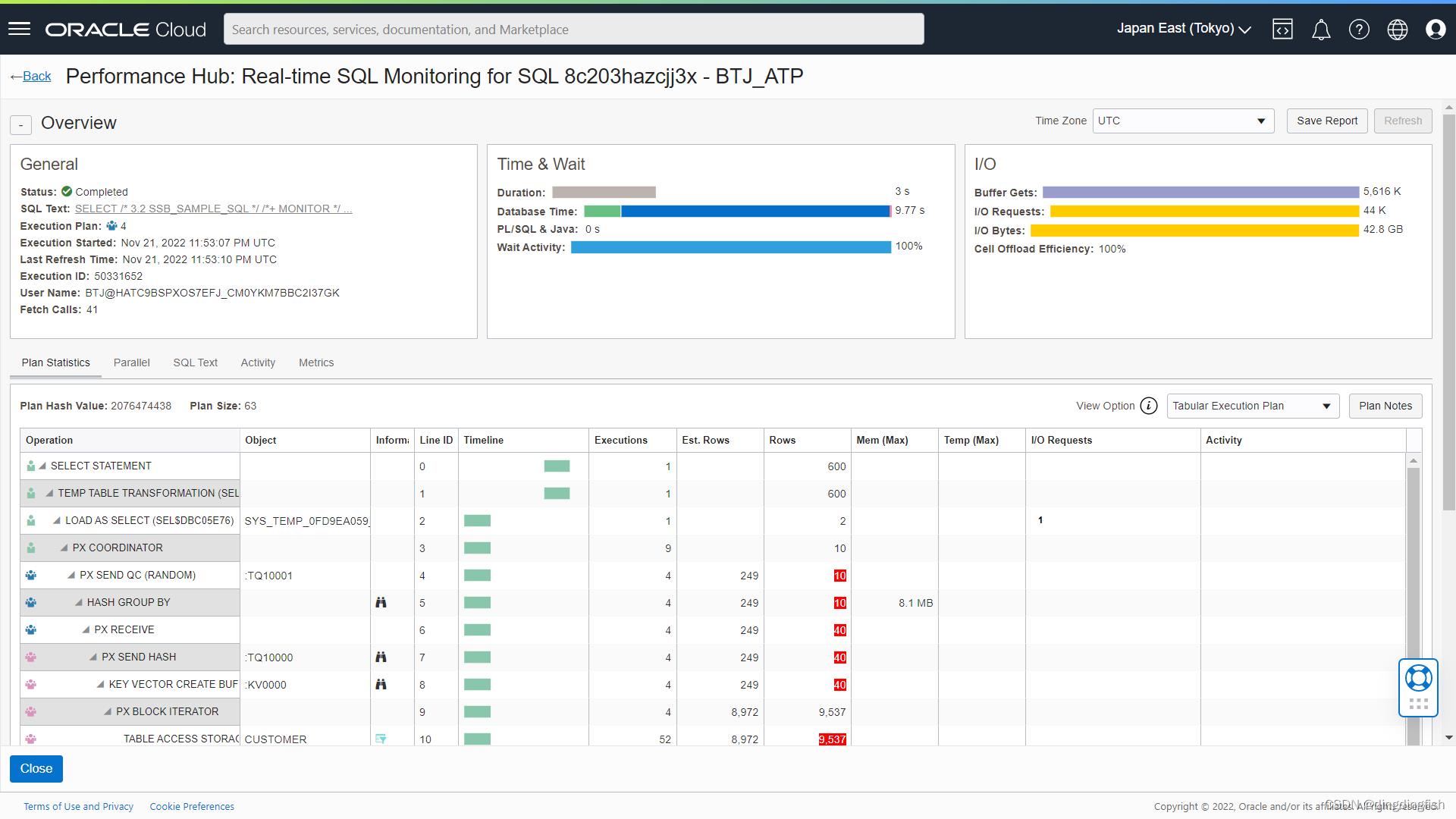
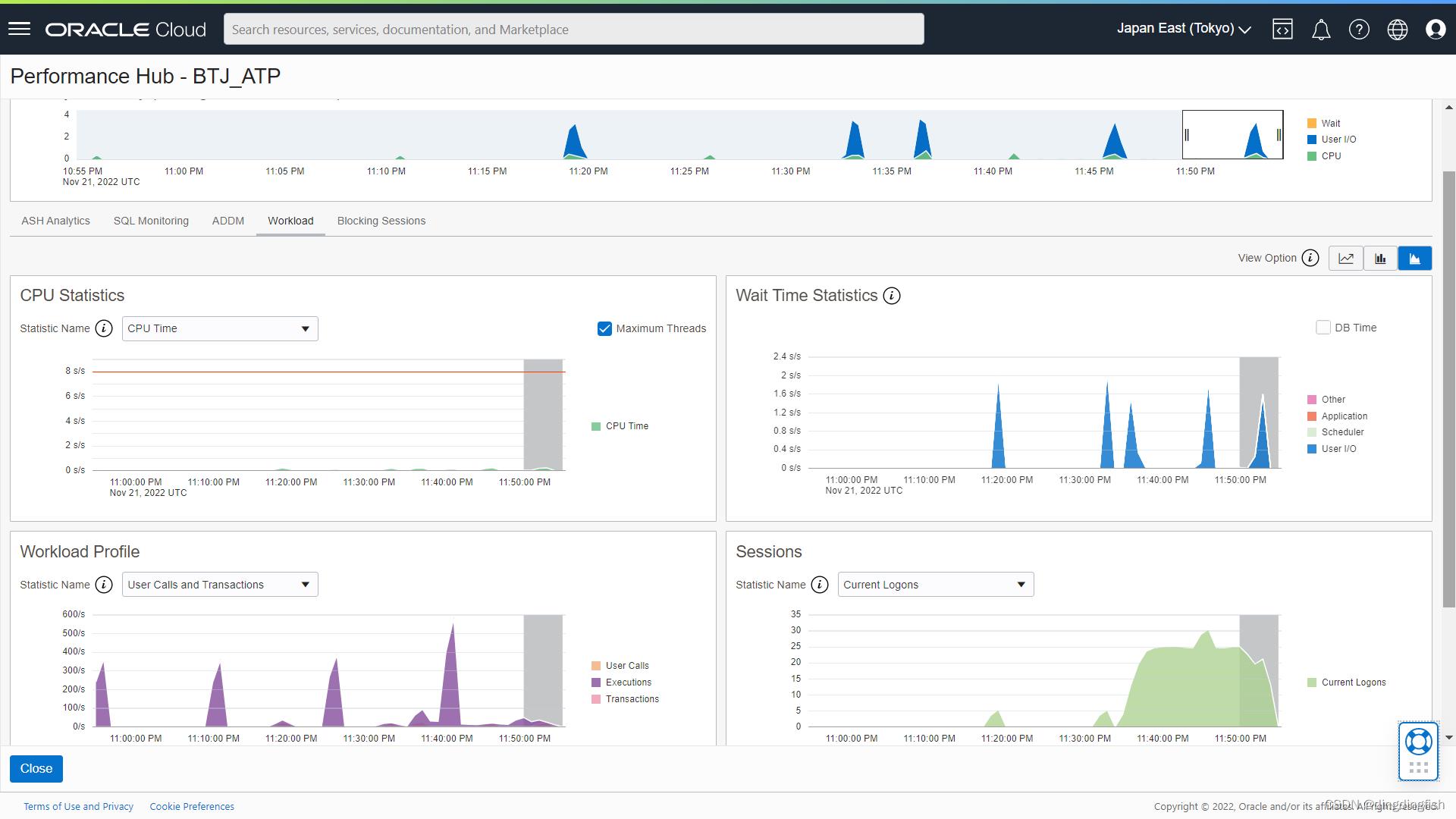
想了解更多?
单击此处获取有关管理和监视自主数据库的文档。
实验 8:性能扩展
介绍
在此实验中,您将扩展Oracle自治数据仓库(ADW)或自治事务处理(ATP)服务,以拥有更多的CPU。并展示在线扩展服务对性能和并发性的影响。
任务1:扩展自主数据库实例
CPU和存储都可以在线扩展,以及自动在线扩展(最多3倍)。扩展指可以增加或减少。
任务2:动态缩放的性能和并发优势
观看视频,演示了将CPU数量从2个增加到8个,将事务吞吐量从每秒2000个增加到7500个。
了解更多信息
参见文档。
自治数据库Service Concurrency的文档参见这里。
实验 9:应用 Auto Scaling
介绍
在本实验中,您将了解 Auto Scaling Oracle Autonomous Database 的优势。 本实验室使用自治数据仓库 (ADW) 中现有的 SSB 模式。 实验室执行一个 PL/SQL 过程,该过程循环执行两次查询。 您将从 3 个 SQL Developer Web 工作表会话中同时运行此过程,以查看在使用和不使用自动缩放的情况下 CPU 的使用情况。
预计时间:30分钟
什么是 Auto Scaling 以及它是如何工作的?
启用自动缩放后,数据库使用的 CPU 和 IO 资源最多可比 Scale Up/Down 对话框中当前显示的基本 OCPU 数量指定的多三倍。
启用 Auto Scaling 后,如果您的工作负载需要额外的 CPU 和 IO 资源,数据库会自动使用这些资源,无需任何人工干预。
注意:您不需要执行“触发操作”,之后您的数据库就可以开始扩展; 额外的 CPU 和 IO 始终可供您使用。
创建自治数据库时,默认情况下会启用自动缩放复选框。 创建数据库后,您可以使用 Oracle Cloud Infrastructure 控制台上的 Scale Up/Down 来禁用或启用自动扩展。
如果您的组织在不同时间执行密集查询,Auto Scaling 将在需要时增加和减少 CPU 资源。
如下面的实验室示例所示,如果客户预置了一个具有 1 个基本 OCPU 的自治数据库并启用了自动扩展,他们将立即可以访问 3 倍于预置的 1 个基本 OCPU,即 3 个 OCPU。 他们还可以立即访问 3 倍的 IO。
客户只需为每小时使用的实际平均 OCPU 数量(1 到 3 个 OCPU)付费。
测试 1 - 禁用自动缩放
在禁用自动缩放的任务 1 到 3 中,您将有 3 个 SQL Developer Web 会话执行共享 CPU 和 IO 资源的查询,并且您将检查查询时间。
任务 1:禁用 Auto Scaling 并在 SQL Developer Web 中创建四个到 ADW 数据库的连接
创建一个自治数据库,本例为ADW。禁用OCPU auto scaling,其它保持默认值。
进入Database Actions中的SQL菜单,创建4个workshhet,分别命名为Setup, Query 1, Query 2, 和Query 3。
在后面的任务中,您将使用这 3 个工作表同时使用 HIGH 使用者组运行测试查询。 对于实际生产工作负载,您通常会使用 MEDIUM 或 HIGH 消费者组,因为它们具有更高的并行度和更低的并发性。 使用 HIGH 消费者组的工作表获得最高优先级。
任务 2:创建 test_proc 过程以生成测试工作负载
在Setup Worksheet中,使用 LOW 消费者组运行以下脚本创建测试用存储过程:
-- Create a sequence to increment the number of tests running
create sequence test_run_seq order nocache;
create table test_run_data
(test_no number,
cpu_count number,
sid number,
query_no number,
start_time timestamp,
end_time timestamp
);
create or replace procedure test_proc(i_executions number := 2) as
v_sid number;
v_loop number := 0;
v_test_sql varchar2(32767);
v_test_sql_1 varchar2(32767);
v_test_sql_2 varchar2(32767);
v_end_date date;
v_begin_date date;
v_begin_sql_time timestamp;
v_end_sql_time timestamp;
v_minute number;
v_result number;
v_last_test_no number;
v_test_no number;
v_test_start_time date;
v_last_test_start_time date;
v_cpu_count number;
function get_test_no return number is
v_last_test_no number;
v_last_test_start_time date;
v_test_no number;
v_test_start_time date;
begin
select test_no, start_time into v_last_test_no, v_last_test_start_time
from test_run_data
where start_time = (select max(start_time)
from test_run_data);
if v_last_test_start_time > (sysdate - 1/1440)
then v_test_no := v_last_test_no;
else v_test_no:= test_run_seq.nextval;
end if;
return v_test_no;
exception
when others then
v_test_no:= test_run_seq.nextval;
return v_test_no;
end get_test_no;
begin
v_test_no := get_test_no;
select userenv('SID') into v_sid from dual;
select sum(value) into v_cpu_count from gv$parameter where name = 'cpu_count';
insert into test_run_data values(v_test_no, v_cpu_count, v_sid, null, systimestamp, null);
commit;
v_begin_date := sysdate;
v_test_sql_1 := q'#select /* #';
v_test_sql_2 := q'# */ /*+ NO_RESULT_CACHE */ count(*) from (
-- This query will summarize orders by month and city for customers in the US in the Fall of 1992
SELECT
d.d_month,
d.d_year,
c.c_city,
SUM(lo.lo_quantity),
SUM(lo.lo_ordtotalprice),
SUM(lo.lo_revenue),
SUM(lo.lo_supplycost)
FROM
ssb.lineorder lo,
ssb.dwdate d,
ssb.customer c
WHERE
lo.lo_orderdate = d.d_datekey
AND lo.lo_custkey = c.c_custkey
AND d.d_year = 1992
AND d.d_sellingseason='Fall'
AND c.c_nation = 'UNITED STATES'
GROUP BY
d.d_month,
d.d_year,
c.c_city
)
#';
loop
v_loop := v_loop + 1;
v_minute := round((sysdate - v_begin_date) * 1440, 1);
v_test_sql := v_test_sql_1 || 'test no:' || v_test_no || ', sid:' || v_sid || ', loop:' || v_loop || v_test_sql_2;
v_begin_sql_time := systimestamp;
execute immediate v_test_sql into v_result;
v_end_sql_time := systimestamp;
insert into test_run_data values(v_test_no, v_cpu_count, v_sid, v_loop, v_begin_sql_time, v_end_sql_time);
commit;
exit when v_loop = i_executions;
end loop;
end;
/
任务 3:在三个工作表中同时运行 test_proc 过程
在Query 1, Query 2, 和Query 3 这三个worksheet中同时以HIGH消费组运行以下脚本:
exec test_proc;
当 3 个过程实例同时运行时,在我们的测试中,它们在 1 个 OCPU 系统上运行大约 7.5 分钟(您可能会看到不同的执行时间),转到自治数据库的控制台页面并单击性能中心。 在 Performance Hub 中,单击 SQL 监控选项卡,然后查看受监控的 SQL 以查看每个工作表都在运行您的过程。
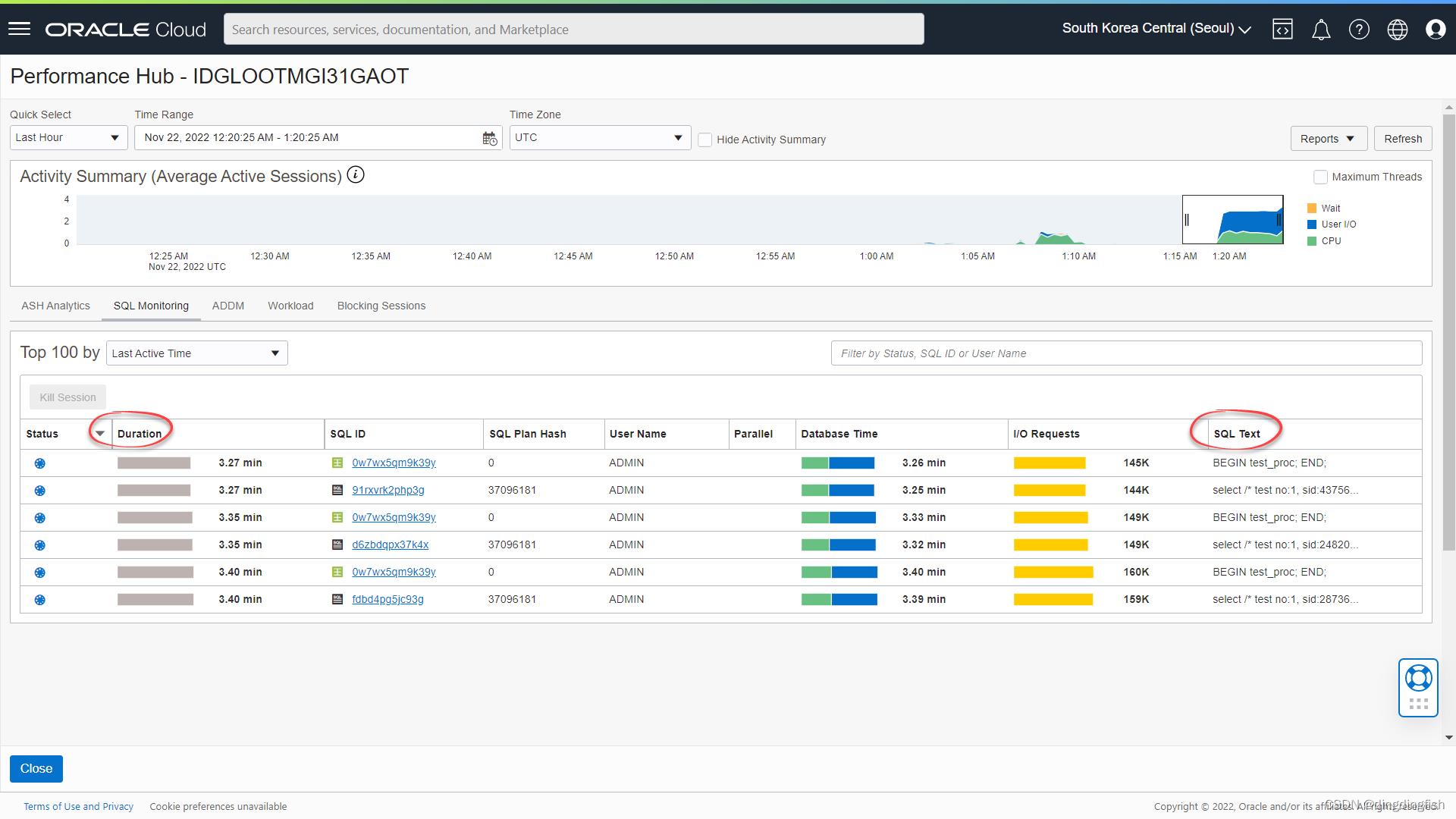
等待3个worksheet中的查询运行完成,即左侧的图标变为绿色的√: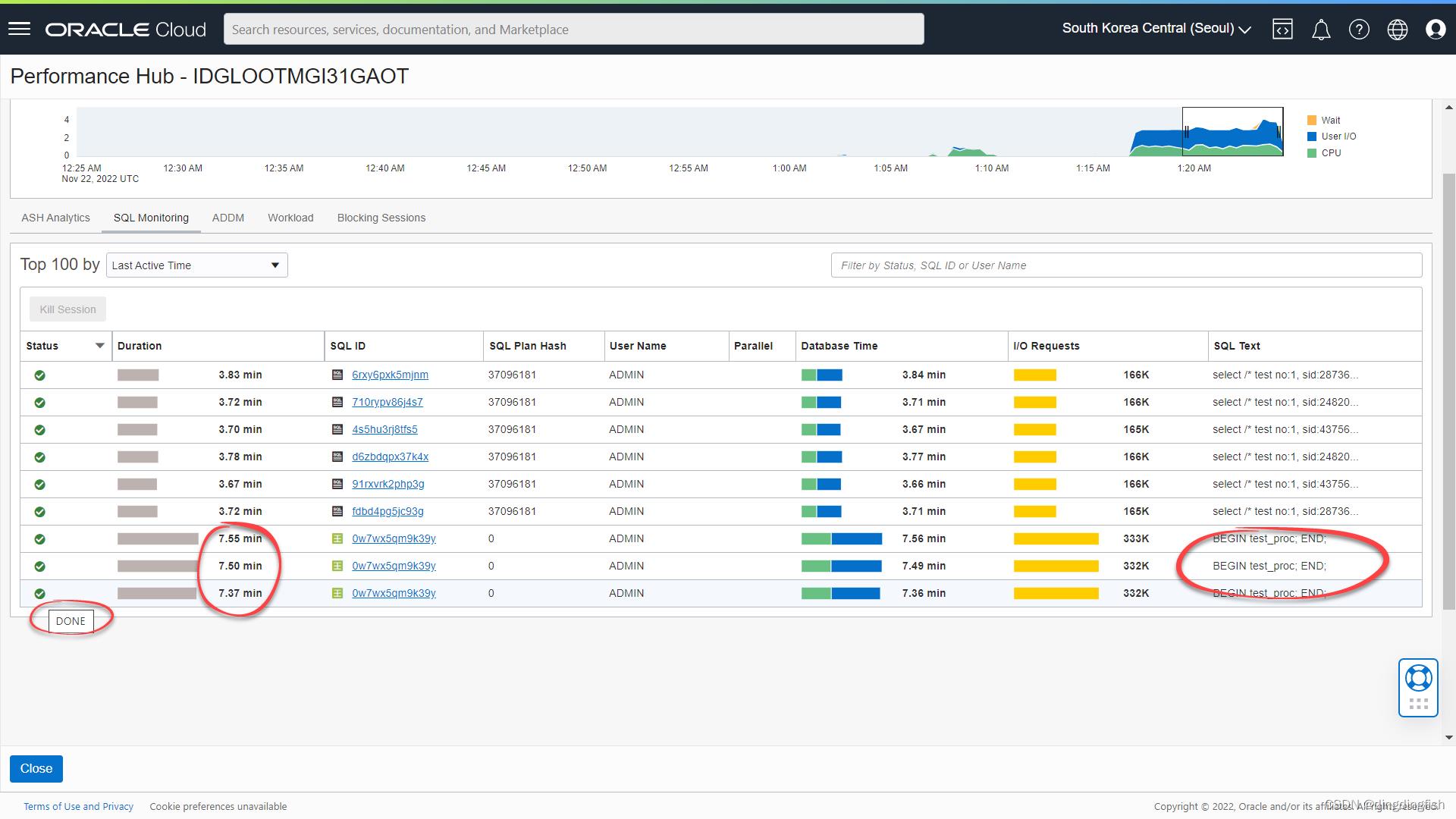
在您的Setup工作表中,运行以下脚本来查看您的测试结果:
alter session set nls_date_format='DD-MM-YYYY HH24:MI:SS';
select test_no,
cpu_count,
sessions,
queries_finished,
test_duration_in_seconds,
avg_query_time
from (select test_no,
cpu_count,
count(distinct sid) sessions,
sum(nvl2(end_time,1,0)) queries_finished,
round(extract(minute from (max(end_time) - min(start_time))) * 60 + extract(second from (max(end_time) - min(start_time))),1) test_duration_in_seconds,
round(avg(to_number(extract(minute from (end_time - start_time)) * 60 + extract(second from (end_time - start_time)))),1) avg_query_time
from test_run_data
group by test_no,
cpu_count)
order by 1;
结果如下:
TEST_NO CPU_COUNT SESSIONS QUERIES_FINISHED TEST_DURATION_IN_SECONDS AVG_QUERY_TIME
------- --------- -------- ---------------- ------------------------ --------------
1 2 3 6 453.5 224.1
Elapsed: 00:00:00.038
1 rows selected.
测试 2 - 启用 Auto Scaling,提供 3 倍的 CPU 和 IO 资源
任务 4:启用 Auto Scaling
启用OCPU auto scaling,其它都是默认配置。等待变更生效。
任务 5:启用 Auto Scaling 后在三个工作表上再次同时运行该过程
重新同时运行3个查询,以HIGH消费组。等到查询全部运行结束。
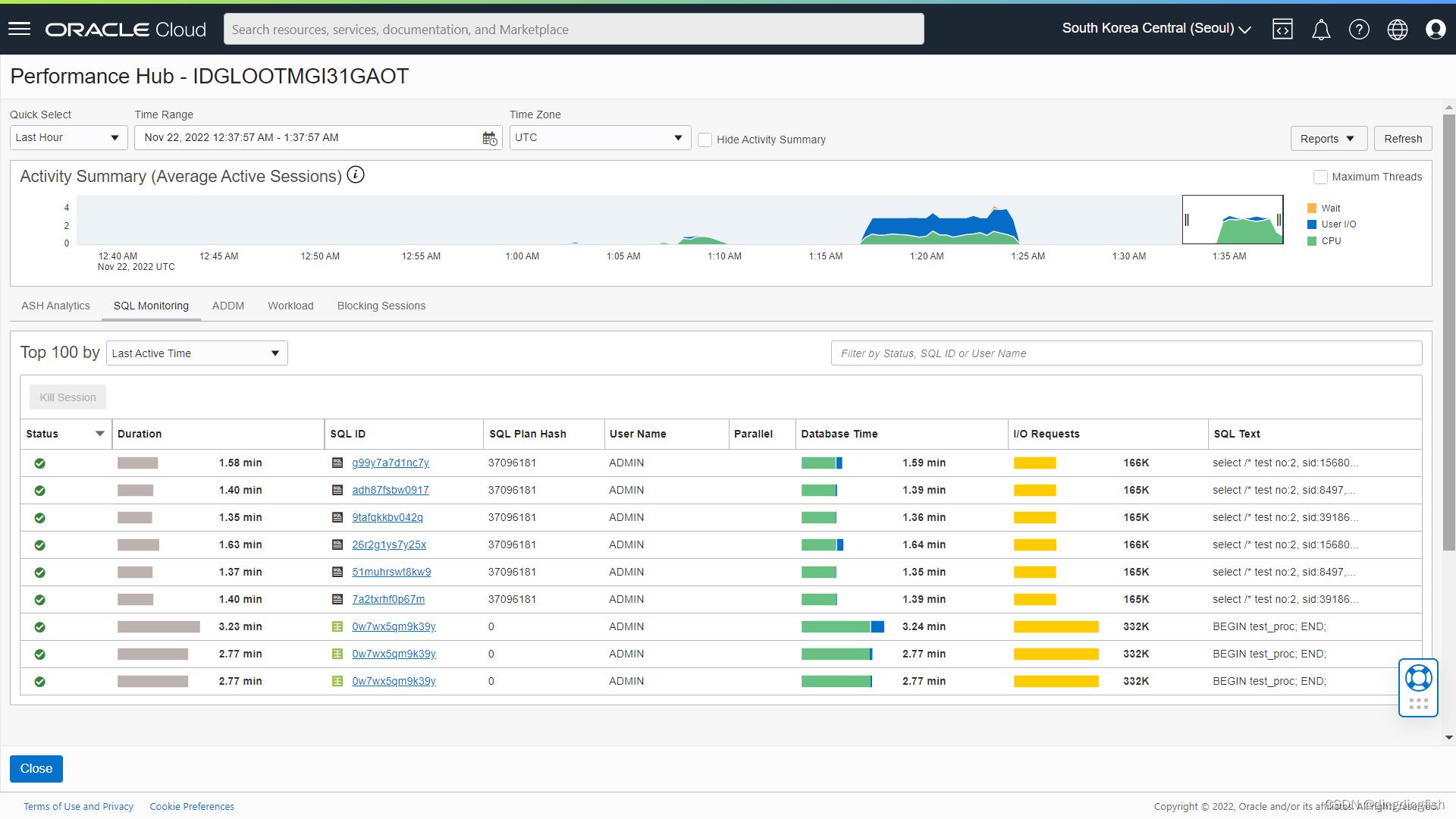
任务 6:查看启用 Auto Scaling 后改进的性能
在Setup worksheet中,仍然运行之前的查询查看性能结果:
TEST_NO CPU_COUNT SESSIONS QUERIES_FINISHED TEST_DURATION_IN_SECONDS AVG_QUERY_TIME
------- --------- -------- ---------------- ------------------------ --------------
1 2 3 6 453.5 224.1
2 6 3 6 200.9 87.7
这些数字看起来很棒! 启用自动缩放后,我们看到:
- 数据库可用的 OCPU 数量增加了 3 倍; 在我们的示例中,从 1 个 OCPU 到 3 个 OCPU。
(注意:CPU_COUNT 值显示了可用 OCPU 数量的 2 倍,因为每个 OCPU 有 2 个 CPU 线程。因此,我们看到显示的 CPU_COUNT 值从 2 跳到 6。) - 现在所有 3 个正在运行的会话都可以访问 3 倍的 CPU 和 IO。
- 因此,平均查询时间从约 224秒减少到约 87 秒,因此同时运行 3 个工作表会话的总测试的持续时间从约 453秒减少到约 200秒。基本上是3倍。
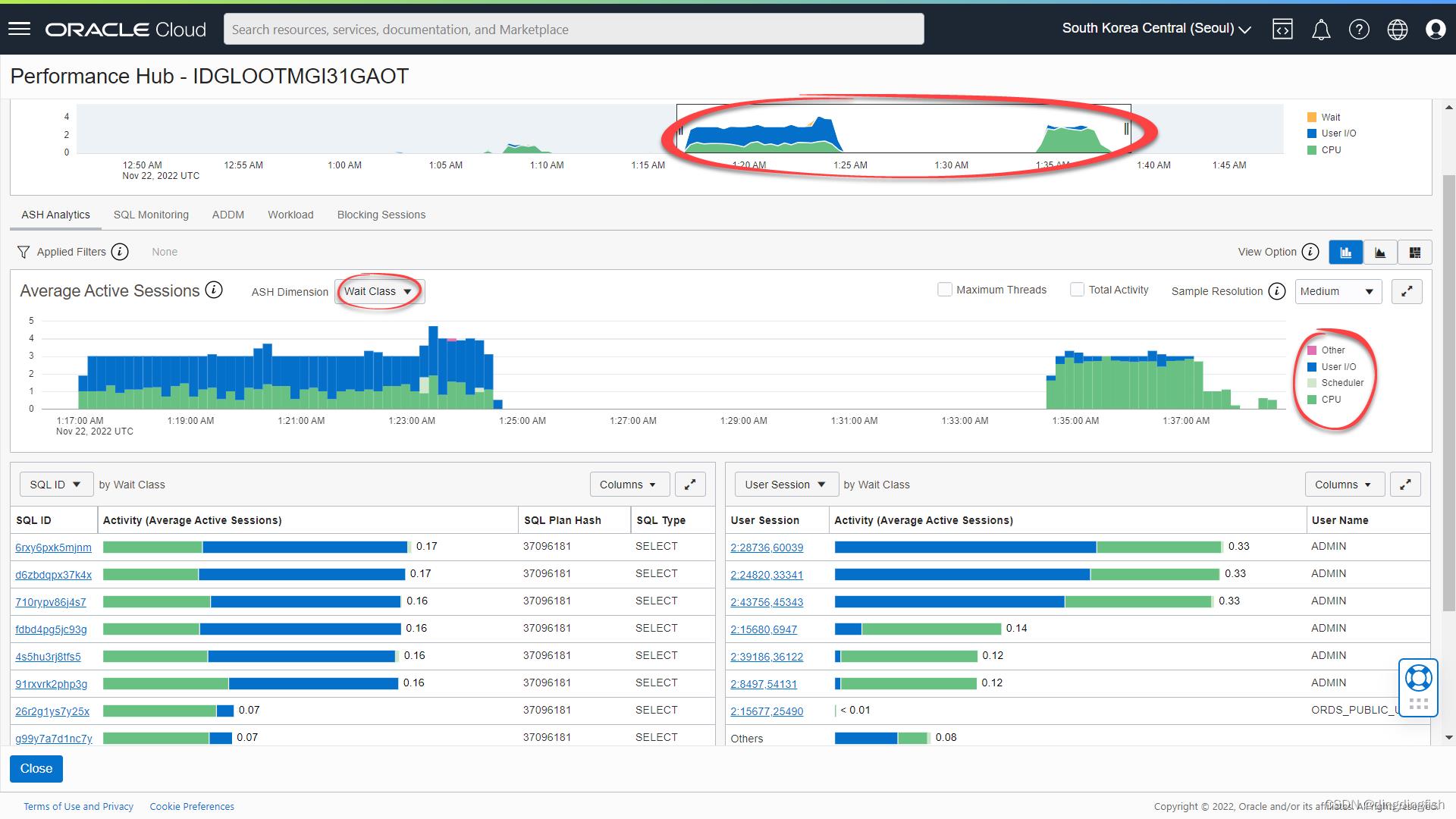
查看Performance Hub中的ASH Analytics,向下滚动并查看平均活动会话图表。 开启 Auto Scaling 后,在第二次测试中按 Wait Class 查看 Average Active Sessions 图表。 由于有 3 个 OCPU 可用于正在运行的查询,我们现在看到:
- 由于资源不可用而导致的膨胀 **I/O 等待(蓝色)**显著减少。
- 因此,工作负载变得更加高效(受 CPU 限制)并且能够利用更多 CPU(深绿色),从而减少了运行每个查询所花费的平均时间。
- 调度程序在 CPU/IO 资源上的等待(浅绿色)几乎完全消失了。
注意事项
- 启用自动缩放后,IO 也会缩放到 OCPU 分配的 3 倍。 因此,即使只有一个会话正在执行一条 SQL 语句,它也会从额外的 IO 中受益。
- 要查看一小时内使用的平均 OCPU 数,您可以使用自治数据仓库服务控制台的概览页面上的“分配的 OCPU 数”图表。 注意:这些概览图每小时更新一次,因此您将能够在下一小时内看到此数据。
- 启用 Auto Scaling 后,只有数据库可用的 OCPU 和 IO 数量增加了 3 倍。 其他数据库参数,包括内存、并发和并行语句队列,不会自动扩展。 根据您的业务查询工作负载的瓶颈所在,您可能会看到不同的性能提升。
想了解更多?
有关 Auto Scaling 的更多信息,请参阅文档使用 Auto Scaling。
实验 10:启用灾难恢复
介绍
如今,每个企业都需要通过高可用性、数据保护和灾难恢复来保护其数据。 企业需要一套全面的服务来创建、维护、管理和监控一个或多个备用数据库,以使生产数据库能够抵御灾难和数据损坏。 虽然 ADB 已经在高度可用的 Exadata 基础架构上运行,但此功能通过在主数据库出现故障时自动切换到备用数据库,进一步保护您的数据库免受地震、火灾、洪水、主要网络中断等不可预见的灾难场景的影响。
您可以在与其源数据库相同的区域中设置 ADG 备用数据库,并设置跨区域自治数据卫士 (X-ADG),在与其源数据库不同的(远程)区域中运行备用数据库。
预计实验室时间:15 分钟
目标
- 了解灾难恢复的好处
- 了解如何启用和禁用自治数据卫士
- 了解如何从主数据库切换和故障转移到备用数据库
- 了解如何在与主数据库相同的本地区域和远程区域中指定备用数据库
基本灾难恢复术语
- 主数据库或源数据库:用户或应用程序主动用于读取和写入的主数据库。
- 备用数据库:主数据库的副本,它不断地被动地从主数据库复制数据。此备用数据库用于主数据库发生故障的情况。在 ADG 的情况下,备用数据库可在不同的 Exadata 机器上使用(在一个区域中的不同可用性域中)以提供最高级别的保护。备用数据库也可以使用跨区域自治数据卫士在远程区域进行配置。
- 恢复点目标 (RPO):组织对数据丢失的容忍度,之后业务运营开始受到严重影响,通常以分钟表示。这应该尽可能低。
- 恢复时间目标 (RTO):组织对服务不可用(或停机)的容忍度,在此之后业务运营可能会受到严重影响,通常以分钟表示。这应该尽可能低。
自治数据卫士监控主数据库,如果自治数据库实例出现故障,则备用实例承担主实例的角色。
由于灾难而导致的不可预见的数据库故障随时可能发生。 Autonomous Data Guard 为企业的数据可用性和系统性能要求提供最高级别的保护。
如果发生灾难并且您的主数据库被关闭,您可以“故障转移”到备用数据库。 故障转移是一种角色更改,当主数据库关闭且不可用时,从主数据库切换到备用数据库,而备用数据库可用。 这必须快速发生,以便最小化 RTO 和 RPO。
从主节点到备用节点的故障转移是无缝的,不需要为用户在切换之前使用的工具下载新钱包或新 URL。 您可以继续为您的工具(APEX、OML 和 ORDS)使用现有的钱包和 URL 端点。
故障转移后,将自动为您的主库配置一个新的备用库。
可以在与主数据库相同的区域中创建备用数据库。 在这种情况下,为了获得更好的弹性,备用数据库的配置如下:
- 在具有多个可用性域的区域中,备用数据库在与主数据库不同的可用性域中自动供应。
- 在具有单个可用性域的区域中,备用数据库在与主数据库不同的物理机器上自动供应。
- 跨区域备用数据库也可以在与主数据库的本地区域不同的远程区域中创建。
任务 1:启用自治 Data Guard
启用Autonomous Data Guard(默认是关闭的),可以在本Region或不同Region,本例使用前者。
一共可以创建两个备库,一个是本地的,一个是跨区域的。 您刚刚启用了自治数据卫士来创建本地备用数据库。 如果您的 Oracle Cloud 帐户至少有两个区域,您可以选择创建第二个跨区域的备用数据库。 在自治数据库详细信息页面左下角的资源部分中,单击自治数据卫士 (1)。
注意:如果您的 Oracle Cloud 帐户至少有两个区域,则创建跨区域备用数据库是可选的。
任务 2:测试切换到备用数据库
启用Autonomous Data Guard后,如果进行切换(switchover)操作,主库变为备库,备库变为主库,不会丢失数据。 启用 Autonomous Data Guard 时,通常会进行切换以测试应用程序的故障切换过程。
切换操作完成后,Autonomous Data Guard 会执行以下操作:
- 主数据库进入可用状态,可以连接到查询和更新。
- 当备用设备准备好时,Peer State 字段将变为可用。 (如有必要,备用服务器可能会首先进入 Provisioning 状态,而不会阻塞主服务器上的操作。)
- 当您将鼠标悬停在 Peer State 字段中的工具提示图标上时,您可以查看上次切换的时间。
任务 3:(可选)禁用自治数据卫士
略。
注意:
- 禁用 Autonomous Data Guard 会终止备用数据库。 如果您稍后启用 Autonomous Data Guard,系统会创建一个新的备用数据库。
- 如果您切换到远程跨区域备用,则必须先切换回主区域,然后才能禁用跨区域备用。
发生灾难时的自动和手动故障转移选项
在主节点不可用的灾难情况下,Switchover按钮将变为Failover按钮。 使用 ADG,当用户在几分钟内无法连接到其主数据库时,自治数据库会自动触发自动故障转移(无需用户操作)。 由于这是一个自动操作,因此仅当不会发生数据丢失时,才允许自动故障转移成功。 在 ADG 中,对于自动故障转移,RTO 为 2 分钟,RPO 为 0 分钟。
注意:我们不支持跨区域的自动故障转移,因为跨区域的故障转移比本地故障转移的影响更大; 通常,用户希望将中间层/应用程序与数据库一起进行故障转移,以获得最佳性能。 您可以在需要时手动触发控制台上的切换/故障切换按钮或脚本 API 调用。 出于同样的原因,如果您同时有本地和远程备用数据库可用,我们总是建议先故障转移到本地备用数据库。
在极少数情况下,当您的主服务器关闭且自动故障转移不成功时,切换按钮将变为故障转移按钮,用户可以触发并执行手动故障转移。 在手动故障转移期间,系统会自动恢复尽可能多的数据,最大限度地减少任何潜在的数据丢失; 可能会有几秒钟或几分钟的数据丢失。 您通常只会在真正的灾难场景中执行手动故障转移,接受几分钟的潜在数据丢失,以确保尽快让您的数据库恢复在线。 对于手动故障转移,RTO 为 2 分钟,RPO 为 5 分钟。
其他注意事项
- 如果您同时拥有本地和跨区域备用数据库,Oracle 始终建议先切换到本地的备用数据库。仅当区域完全关闭并且您无法故障转移到本地区域备用时,才可以故障转移到远程区域备用。
- 我们不希望您永久在备用区域中运行。而是希望主端可用时,尽快切换回主端。
- 跨区域备用数据库(1 小时)的恢复时间对象 (RTO) 高于本地备用数据库(2 分钟)。
- 启用具有远程备用功能的 Autonomous Data Guard 后,下载一个新钱包。您从主数据库下载的钱包文件包含主区域和远程区域数据库的连接字符串。在您切换或故障转移到远程区域备用后,相同的钱包可以工作。
- 当您同时启用具有本地和跨区域备用的 Autonomous Data Guard 时,Autonomous Data Guard 不会在远程区域实例以主角色运行时提供本地备用。在主要角色中使用远程区域旨在在主要区域不可用时使用或用于测试(临时方案)。主区域数据库恢复为 Primary 角色后,本地 Standby 将可用。
想了解更多?
- 有关备用数据库的更多信息,请参阅关于备用数据库的文档。
- 要使用 OCI REST API 来启用和使用 Autonomous Data Guard,请参阅使用 API。
- 有关跨区域自治数据卫士的更多详细信息,请参阅此博客。
- 如果您的数据库在私有端点后面启用了跨区域自治数据保护,则有关所需网络设置的更多详细信息,请参阅此博客。
实验 11:创建可刷新的克隆
介绍
共享基础架构上的自治数据库 (ADB-S) 中使用最广泛的功能之一是能够克隆您的数据库,无论数据库大小,几乎毫不费力。
可刷新克隆是一个只读克隆,它与源数据库保持“连接”,并且能够通过简单的单击按钮来同步(刷新数据)其源数据库。 在以前,如果您需要从源更新克隆的数据,您有两种选择:
- 将新数据从源数据库移动到克隆(通过数据泵、数据库链接等)
- 从源数据库创建新克隆
可刷新克隆消除了上述选项的额外工作,您只需单击刷新按钮并提供要刷新到的源数据库的时间戳(恰当地称为刷新点)即可刷新克隆的数据; 克隆会自动查看源数据库的日志并将所有数据提取到您输入的时间戳。
以下是一些示例用例:
- 向组织内的不同业务部门提供定期更新的克隆以进行报告和分析
- 在组织内的业务部门之间为您的数据库创建计费或工作负载分离
- 为内部团队提供最新的只读测试数据库环境
与所有 OCI 一样,您的可刷新克隆也可以通过简单的 REST API 调用进行刷新(请参阅 API 文档)。 更好的是,通过从控制 ADB 实例调用云 REST API 的能力,您可以快速安排自动化数据刷新以适合您的数据管道,而无需部署任何服务器!
本实验向您展示如何创建可刷新的克隆并使用其源数据库中的更新数据对其进行刷新。
预计实验室时间:15 分钟
在本实验中,您将:
- 使用源数据库中的数据创建一个测试表。
- 创建源数据库的可刷新克隆。
- 将附加数据插入源数据库。
- 定义源数据库的刷新点时间戳并刷新克隆。
- 确认源数据库中的附加数据已拉入克隆。
任务 1:在源数据库中创建表
进入Database Actions的SQL菜单,执行以下:
create table refreshclonetests (testcol varchar(255));
insert into refreshclonetests (testcol) values ('Is this great?');
commit;
任务 2:从自治数据库实例创建可刷新克隆
返回到源数据库的自治数据库详细信息页面。 从More Actions下拉菜单中,选择创建克隆。
目前支持的克隆类型包括,此处选择2:
- Full Clone
- Refreshable Clone
- Metadata Clone
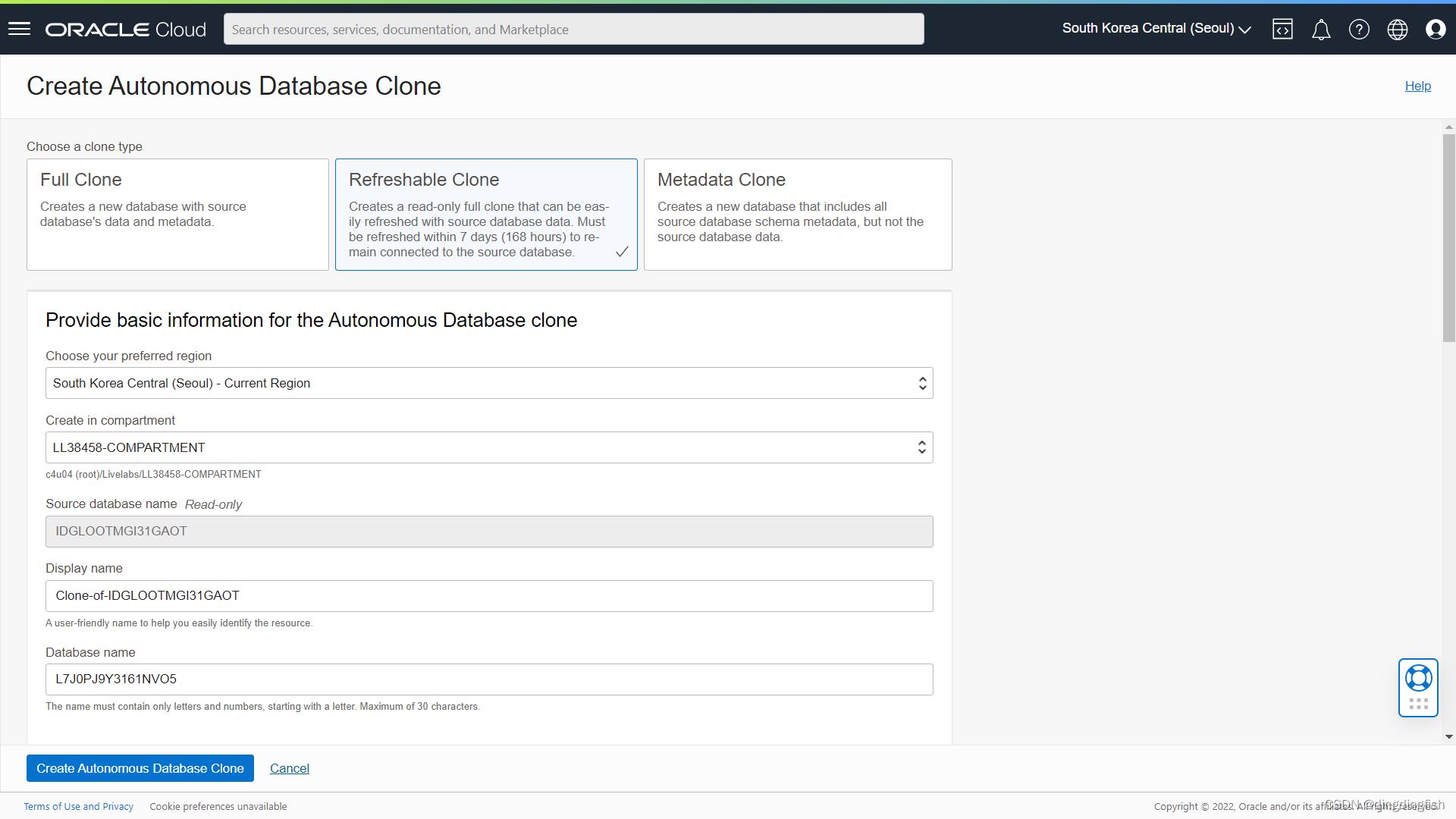
注意描述它的文字; 可刷新的克隆必须每 7 天或更短时间刷新一次,否则它与源的同步太远而无法再刷新。
选择可刷新克隆的 OCPU 数量; 不能选择存储。 由于这是一个只读克隆,仅从其源数据库中引入数据,因此以 TB 为单位选择的存储量自动与源的相同(不过Full Clone和Metadata Clone可以定制存储大小)。其它可以设置的选项包括:
- clone所在的region,可以跨region
- network access type
- license type
- database edition
创建ADB克隆的耗时如下:
Tue, Nov 22, 2022, 05:29:32 UTC Tue, Nov 22, 2022, 05:31:48 UTC
从可刷新克隆的 OCI 控制台打开数据库操作 SQL 工作表,然后查询数据库。 它显示了您在源中创建的表 refreshclonetests,以及您插入的单行数据。
select * from refreshclonetests;
TESTCOL
--------------
Is this great?
Elapsed: 00:00:00.161
1 rows selected.
任务 3:将附加数据插入源数据库
您已经证明可刷新克隆包含源数据库的表和一行数据。 现在将第二行数据添加到源中,并查看如何刷新克隆以获取第二行。
在源数据库中插入数据:
insert into refreshclonetests (testcol) values ('You can refresh whenever you need!');
commit;
任务 4:刷新克隆以查看新数据
返回克隆数据库的“数据库详细信息”页面。 单击横幅中的刷新按钮。 此横幅还显示您必须刷新克隆的日期和时间(即执行最后一次刷新后的 7 天),否则它将失去与源同步的能力。
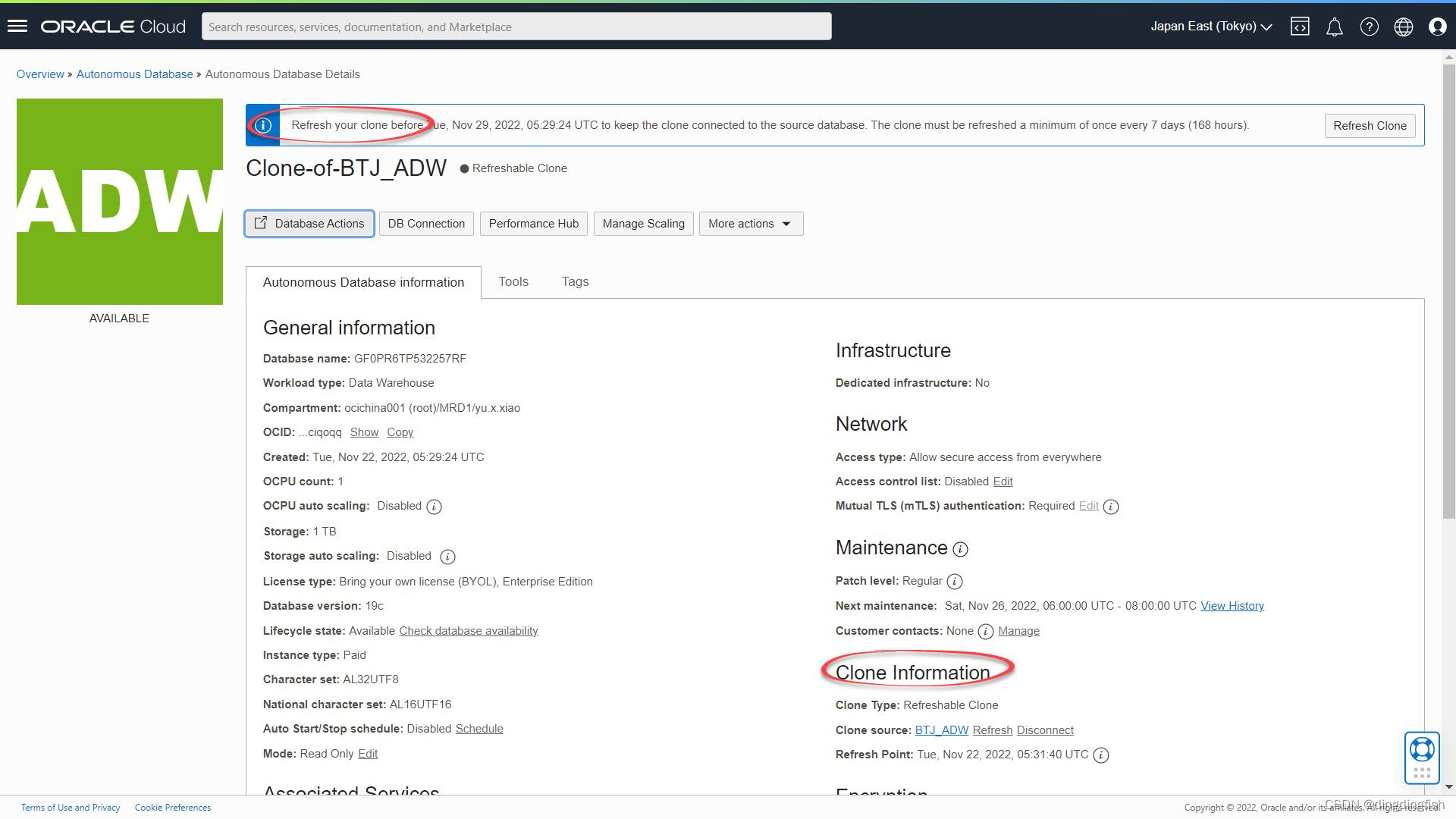
此外,请注意“更多操作”下拉菜单中的“从源数据库断开克隆”选项。 在任何时候,您都可以选择断开您的克隆与其源的连接,使其成为一个常规的、独立的、读/写数据库。
Refresh Clone 弹出对话框询问您要刷新到的源数据库的刷新点时间戳。 这使得刷新一致且易于理
以上是关于Oracle LiveLabs实验:Manage and Monitor Autonomous Database的主要内容,如果未能解决你的问题,请参考以下文章
Oracle LiveLabs实验:Manage Database Instance and Memory for Oracle Database 21c
Oracle LiveLabs实验:Manage Database Instance and Memory for Oracle Database 21c
Oracle LiveLabs实验: Oracle多租户基础
Oracle LiveLabs实验: Oracle多租户基础