markdown 基于检索式聊天机器人设计
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了markdown 基于检索式聊天机器人设计相关的知识,希望对你有一定的参考价值。
基于检索的聊天机器人的架构,该架构分为离线和在线两部分:
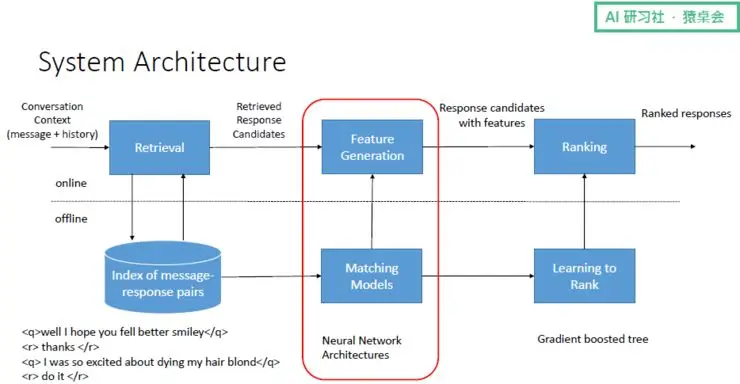
- 离线部分:首先需要准备存储了大量人机交互数据的 Index;之后 Matching Model 能够评估输入与输出的相似度,并给出一个相似度的评分——Matching Model 越多,相似度得分个数也越多,其可以评估输出对于输入来说是否是一个比较合适的输出;然后这些得分通过分类器(设置一个预值,大于预值的都认为是可作为选择的输出),合成一个最终得分列表,并由排序模型对得分进行排序,选择排在最前面的输出作为对当前输入的回复。
- 在线部分:有了这些离线准备,我们可以将当前的上下文输入到存储了大量人机交互数据的 Index 中进行检索,并检索出一些候选回复;接着,回复候选和当前上下文一起通过 Matching Model 来进行打分,每一个得分都作为一个 Feature,每一个候选回复和上下文因而就产生了 Feature Vector;之后,这些 Feature Vector 通过排序模型或者分类器变成最后的得分;最终,排序模型对得分进行排序,并从排序列表中选出合适的回复。
其中,基于检索的聊天机器人很大程度上借鉴了搜索引擎的成果,比如 learning to rank,其新的地方主要在于——当给定上下文和候选回复时,通过建立一个 Matching Model 来度量候选回复是否能够作为上下文的回复。基于检索的聊天机器人本质上是重用已有的人的回复,来对人的新的输入进行回复。
目前,基于检索的方法是当前构建聊天机器人的主流方法,而怎样通过神经网络的方法来构建 Matching Model,则是检索中的重点。
source:[AI研习社](https://mp.weixin.qq.com/s?__biz=MjM5ODU3OTIyOA==&mid=2650674855&idx=3&sn=571933afffb3e0a3d0d7988e10e5a7af&pass_ticket=PHW1zbe18Lx5%2BSrUgvvtfroW%2FsC1lrdSwfrzg40LhM2zvFOI2pHeGAN2t3Ff0HOj)
- 社区问答,是基于从问答网站抓取的问答对进行问答任务。具体来说,给的输入问题,社区问答从问答对中检索到与输入问题语义最为相关匹配的已有问题,并采用该已有问题洗
答案作为当前问题的答案。
- 由此可见,该类问答最为关键的环节是计算问题与已有问题之间的语义相似度,以及计算问题与答案间的语义相关度。
以上是关于markdown 基于检索式聊天机器人设计的主要内容,如果未能解决你的问题,请参考以下文章
论文泛读174基于相关知识和目标的主动检索式聊天机器人
两种开源聊天机器人的性能测试——基于tensorflow的chatbot
综述 | 检索式聊天机器人技术
构建聊天机器人:检索seq2seqRLSeqGAN
构建聊天机器人:检索seq2seqRLSeqGAN
基于python以及AIUI WebSocket,WeChatPYAPI实现的微信聊天机器人