构建聊天机器人:检索seq2seqRLSeqGAN
Posted Young_Gy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了构建聊天机器人:检索seq2seqRLSeqGAN相关的知识,希望对你有一定的参考价值。
本文将简要介绍聊天机器人的四种构建方法:检索、seq2seq、Reinforcement Learning、seqGAN。

聊天机器人的现状
聊天机器人从应用领域分为:
- 专业型
- 通用型
从技术上分为:
- 检索型
- 生成型
目前聊天机器人在专业领域利用检索的效果较好,正朝着通用领域生成型发展。
检索
检索方法的数据库是很多对话的pair,其原理是将query编码成vector,然后在数据库中找最接近的query,然后将最接近的query的回答输出。注意点如下:
- query的编码方式LSI:使用词袋模型或tf-idf对数据库中的query集进行编码得到矩阵
A
,行代表word,列代表document;对矩阵进行SVD分解得到
A=USVT ,其中 V 表示文档在特征空间的特征向量;当新的queryq 来临时,对其做变换 S−1UTq 得到特征空间的向量,然后用余弦相似性计算与数据库中qeury的相似度即可。这种方法的缺点是当新数据越多的时候误差越大,需要重新计算SVD,同时对于同义词、一词多义等语义特征难以把握。 - query的编码方式RNN:可以采用两个RNN。第一个RNN对每句话进行编码到一个向量;第二个RNN对第一个RNN的输出继续编码成一个向量。
- query的编码方式auto-encoder,设定encoder的单元数,encoder前面加embeding等,相当于特征压缩。
- query编码好之后的问题就转变成了一个retrivel的问题,采用KNN即可,同时可采用KD-Tree、LSH优化检索速度。
seq2seq
seq2seq使用两个RNN,一个作为输入的encoder,一个作为输出的decoder。需要注意的大致包含以下几点:
- encoder中可以包含上一句,也可以包含上上一句。如果包含多个句子,可以采用启发式的encoder,训练2 step的RNN。第一个RNN负责对每个句子进行建模,第二个RNN负责对第一层RNN的输出进行建模输出变量。
- decoder每个step可以采用attention
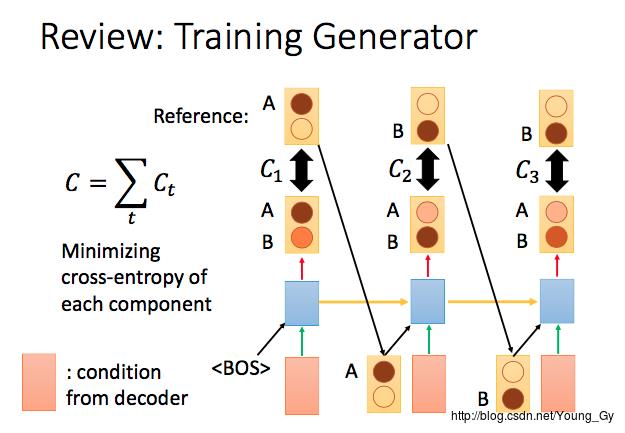
- train的时候loss为
C=∑Ct
,
Ct=−log(P(xt|x1,...,xt−1))
,最小化loss等价于最大似然
maxP(x|h)
,
h
代表encoder的输入,
x 代表decoder的输出。
RL
为什么要用强化学习
seq2seq有一些缺点:
- 只能计算前缀部分的概率(改进可用recursive neural network)
- 使用最大似然估计模型参数
第一个缺点使seq2seq不容易理解文本,因为AI-requires being able to understand bigger things from knowing about small parts.
第二个缺点使seq2seq的对话不像真实的对话,只考虑当前对话最大似然忽略了对话对未来的影响,容易出现“I don’t know”(因为其概率最大,其他方向的相互抵消);对话重复(不考虑上下文的关系)等问题。
针对第二个缺点,我们了解到概率最高的输出不一定等于好的输出,好的对话需要考虑长久的信息。可以引入强化学习,人为设计相关的reward让机器更好地学习。
强化学习的架构设计
强化学习的本质是根据reward,使模型参数朝着reward增长最大的方向移动。
强化学习的聊天机器人架构设计如下:
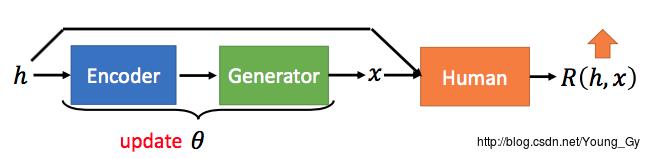
其模型本质还是seq2seq,模型参数是
θ
,模型输入是
h
,输出是
期望reward的计算公式如下:
Rθ=∑hP(h)∑xPθ(x|h)R(h,x)=Eh∼P(h),x∼Pθ(x|h)[R(h,x)]=1N∑iR(hi,xi)
我们的优化目标是:
θ∗=argmaxθRθ
Policy Gradient
在上一节中,我们得到了目标函数与优化目标,这节中,我们考虑如何求目标函数的梯度 ∇Rθ 。
上一节中得到 Rθ 的方式是通过采样,通过采样的方法自然无法计算梯度实现梯度的传递。解决的思路是:将 Rθ 转化成梯度的采样。具体实现如下:
Rθ=∑hP(h)∑xPθ(x|h)R(h,x)=Eh∼P(h),x∼Pθ(x|h)[R(h,x)]=1N∑以上是关于构建聊天机器人:检索seq2seqRLSeqGAN的主要内容,如果未能解决你的问题,请参考以下文章