机器学习-特征提取(one-hotTF-IDF)
Posted 吾仄lo咚锵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习-特征提取(one-hotTF-IDF)相关的知识,希望对你有一定的参考价值。
文章目录
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。
简介
特征工程是机器学习中的第一步,会直接影响机器学习的结果。可以说数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限。特征工程包括特征提取、特征预处理和特征降维等。
特征提取是将数据(如⽂本、图像等)转换为可⽤于机器学习的数字特征。对计算机来说,如ASCII编码理解字符更直观,使用二进制表示数字等,对人来说更直观的表达方式反而使计算机理解起来很困难。
特征提取包括字典特征提取、文本特征提取和图像特征提取。
字典特征提取
将字典数据转换为one-hot独热编码。one-hot不难理解,也就是将特征的取值范围组成列名,然后一行样本取什么值,就在对应列下面标1,其余标0即可。
使用sklearn中DictVectorizer()函数提取特征。
from sklearn.feature_extraction import DictVectorizer
data = ['name': 'Alice', 'age': 18, 'sex': '女',
'name': 'Bob', 'age': 19, 'sex': '男',
'name': 'Cherry', 'age': 20, 'sex': '女']
transfer = DictVectorizer(sparse=False)
data = transfer.fit_transform(data)
print("特征名字:\\n", transfer.get_feature_names_out())
print("独热编码:\\n", data)

特征name为数字视为1列,特征name取值有3个即3列,sex取值有2个即2列,即独热编码的特征名是[‘age’ ‘name=Alice’ ‘name=Bob’ ‘name=Cherry’ ‘sex=女’ ‘sex=男’],共6列。
| ‘age’ | ‘name=Alice’ | ‘name=Bob’ | ‘name=Cherry’ | ‘sex=女’ | ‘sex=男’ |
|---|---|---|---|---|---|
| 18. | 1. | 0. | 0. | 1. | 0. |
| 19. | 0. | 1. | 0. | 0. | 1. |
| 20. | 0. | 0. | 1. | 1. | 0. |
比如第一行[18. 1. 0. 0. 1. 0.]表示age=18,name=Alice,name≠Bob,name≠Cherry,sex=女,sex≠男。1表示是,0表示否。
DictVectorizer()函数会自动判断特征中的取值,并转换为独热编码。但是对于大数据集来说,如果特征的取值过多,或者样本数太多,就会导致独热编码的矩阵中有很多0,也就是稀疏矩阵,而这些0可以说都是无用信息,十分冗余。
上述为了展示独热编码,实例化字典转换器时,设置参数sparse=False。其默认为Ture,表示压缩稀疏矩阵:
from sklearn.feature_extraction import DictVectorizer
data = ['name': 'Alice', 'age': 18, 'sex': '女',
'name': 'Bob', 'age': 19, 'sex': '男',
'name': 'Cherry', 'age': 20, 'sex': '女']
transfer = DictVectorizer()
data = transfer.fit_transform(data)
print("特征名字:\\n", transfer.get_feature_names_out())
print("独热编码:\\n", data)

上面是对稀疏矩阵压缩存储的结果,也就是说非0元素的下标和所存数据。如(0,0) 18.0表示第0行第0列的数据是18,(0,1) 1.0表示第0行第1列的数据是1,一一对应之前独热编码表示的矩阵,极大降低冗余。
对于机器学习中的CSV数据集,使用字典特征提取就能完成特征提取,方便的完成了独热编码转换。比如对我们来说更直观的yes和no,转成one-hot中的0和1后,计算机更好操作。
文本特征提取
对文本数据进行特征提取,统计词频。根据这些特征可以进行文章分类、相关文章推荐等操作。
英文
英文文本由于有空格作为两个单词的分隔,所以是比较好处理的。
使用seklearn中的CountVectorizer()函数,可以设置编码格式、分隔符等。
from sklearn.feature_extraction.text import CountVectorizer
data = ["Get busy living, Or get busy dying.",
"No pains, no gains."]
transfer = CountVectorizer()
data = transfer.fit_transform(data)
print("特征名字:\\n", transfer.get_feature_names_out())
print("独热编码:\\n", data.toarray())
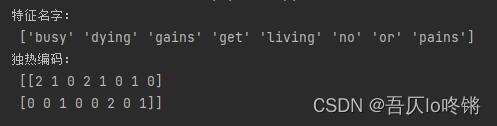
也就是将两句英文句子转为独热编码:
| ‘busy’ | ‘dying’ | ‘gains’ | ‘get’ | ‘living’ | ‘no’ | ‘or’ | ‘pains’ |
|---|---|---|---|---|---|---|---|
| 2 | 1 | 0 | 2 | 1 | 0 | 1 | 1 |
| 0 | 0 | 1 | 0 | 0 | 2 | 0 | 1 |
自动处理了大小写问题,且自动处理了逗号、句号等标点符号,筛选出单词,统计出现次数。
中文
中文由于没有空格等分隔符对词语进行分离,导致分词困难,往往很多时候会出现歧义。比如“南京市长江大桥”,可以是“南京市/长江大桥”,也可以是“南京/市长/江大桥”,我们基于经验可以很好分词,相应的产生了许多中文分词库,这里介绍结巴中文分词库。
使用pip安装:
pip install jieba
使用函数jieba.cut()便可分词,返回一个词语列表,我们对每个词语前加一个空格,组成新的句子,然后再调用CountVectorizer()函数便可进行词频统计,完成特征提取。
import jieba
from sklearn.feature_extraction.text import CountVectorizer
data = ["南京市长江大桥",
"一分耕耘一分收获。"]
text_list = []
for sent in data:
words = " ".join(list(jieba.cut(sent)))
text_list.append(words)
print("分词:\\n", text_list)
transfer = CountVectorizer()
data = transfer.fit_transform(text_list)
print("特征名字:\\n", transfer.get_feature_names_out())
print("独热编码:\\n", data.toarray())

(
插播反爬信息)博主CSDN地址:https://wzlodq.blog.csdn.net/
TF-IDF
但是一些词汇在多篇文章中出现的频率都很高,比如“is”、“a”、“非常”等。若选择这些词汇作为特征,则区别度不大,为此提出了TF-IDF算法来解决这个问题。
TF-IDF(term frequency-inverse document frequency)词频和逆向文件频率,主要思想是如果某词汇在一篇文章中出现的频率很高,且在其他文章中出现得少,则认为此词汇具有很好的类别区分能力,适合用来分类。⽤来评估⼀个字词对于⼀个⽂件集或⼀个语料库中的其中⼀份⽂件的重要程度。
t
f
i
d
f
i
,
j
=
t
f
i
,
j
×
i
d
f
j
tfidf_i,j=tf_i,j×idf_j
tfidfi,j=tfi,j×idfj
比如⼀篇⽂章的总词语数是100,词语"⾮常"出现了5次,那么"⾮常"⼀词在该⽂件中的词频TF是
5
÷
100
=
0.05
5÷100=0.05
5÷100=0.05。
如果"⾮常"⼀词在500份⽂件出现过,⽽⽂件总数是1000份的话,其逆向⽂件频率IDF是
l
g
(
1000
÷
500
)
=
0.3
lg(1000÷500)=0.3
lg(1000÷500)=0.3。
最后"⾮常"对于这篇⽂档的TF-IDF的分数为
0.05
×
0.3
=
0.015
0.05×0.3=0.015
0.05×0.3=0.015
值越小表示区分度越低。
sklearn中封装了TfidfVectorizer()函数,YYDS。
from sklearn.feature_extraction.text import TfidfVectorizer
data = ["I enjoy coding.",
"I like python.",
"I dislike python."]
transfer = TfidfVectorizer()
data = transfer.fit_transform(data)
print("特征名字:\\n", transfer.get_feature_names_out())
print("文本特征抽取结果:\\n", data.toarray())
各特征的TF-IDF如下:
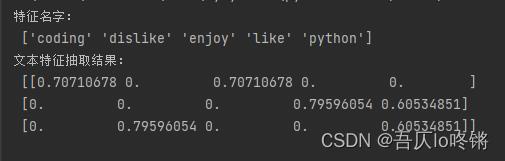
自动筛选掉了每篇都出现的“I”,也可以用stop_words手动定义要筛掉的单词。
transfer = TfidfVectorizer(stop_words=['I'])
图像特征提取
图像数据存储的信息很多,特征也有很多,如几何特征、形状特征、直方图特征、颜色特征等。对应的图像特征提取方法也有很多,如尺度不变特征转换SIFT、加速稳健特征SURF、hog特征、提取兴趣点等。
可以使用skimage库对图像进行操作,可参考文档,篇幅原因,这里不深入介绍。
使用pip安装:
pip install scikit-image
比如提取边缘和角点作为兴趣点:
from skimage.feature import corner_harris, corner_peaks
from skimage.color import rgb2gray
import matplotlib.pyplot as plt
import skimage.io as io
from skimage.exposure import equalize_hist
image = io.imread('D:\\\\test.jpg')
image = equalize_hist(rgb2gray(image))
corners = corner_peaks(corner_harris(image),min_distance=3)
plt.gray()
plt.imshow(image)
y_corner, x_corner = zip(*corners)
plt.plot(x_corner, y_corner, 'or')
plt.xlim(0, image.shape[1])
plt.ylim(image.shape[0], 0)
plt.show()

如果入门学习的话,可以先使用sklearn手写数字数据集,已经封装了图像数据,可以直接调用:
from sklearn import datasets
import matplotlib.pyplot as plt
digits = datasets.load_digits()
print('Digit:', digits.target[0])
print(digits.images[0])
plt.imshow(digits.images[0], cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()


原创不易,请勿转载(
本不富裕的访问量雪上加霜)
博主首页:https://wzlodq.blog.csdn.net/
来都来了,不评论两句吗👀
如果文章对你有帮助,记得一键三连❤
以上是关于机器学习-特征提取(one-hotTF-IDF)的主要内容,如果未能解决你的问题,请参考以下文章
机器学习---文本特征提取之词袋模型(Machine Learning Text Feature Extraction Bag of Words)