文本分类(机器学习方法)
Posted alivinfer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本分类(机器学习方法)相关的知识,希望对你有一定的参考价值。
文本分类实现步骤:
- 定义阶段:定义数据以及分类体系,具体分为哪些类别,需要哪些数据
- 数据预处理:对文档做分词、去停用词等准备工作
- 数据提取特征:对文档矩阵进行降维、提取训练集中最有用的特征
- 模型训练阶段:选择具体的分类模型以及算法,训练出文本分类器
- 评测阶段:在测试集上测试并评价分类器的性能
- 应用阶段:应用性能最高的分类模型对待分类文档进行分类
特征提取的几种经典方法:
- Bag-of-words:最原始的特征集,一个单词/分词就是一个特征。往往会导致一个数据集有上万个特征,有一些的简单指标可以筛选掉一些对分类没帮助的词语,如去停用词、计算互信息熵等。但总的来说,特征维度都很大,每个特征的信息量太小
- 统计特征:TF-IDF方法。主要是用词汇的统计特征来作为特征集,每个特征都有其物理意义,看起来会比 bag-of-word 好,实际效果差不多
- N-gram:一种考虑词汇顺序的模型,也就是 N 阶 Markov 链,每个样本转移成转移概率矩阵,有不错的效果
分类器方法:
-
朴素贝叶斯(Naive Bayesian, NB)
对于给定的训练集,首先基于特征条件独立学习输入、输出的联合概率分布 P(X, Y),然后基于此模型,对给定的输入 x ,利用贝叶斯定理求出后验概率最大的输出 y
假设P(X, Y)独立分布,通过训练集合学习联合概率分布 P(X, Y)
[P(X,Y)=P(Y|X)·P(X)=P(X|Y)·P(Y) ]根据上面的等式可得贝叶斯理论的一般形式
[P(Y=c_k|X=x)=frac{P(X=x|y=c_k)·P(Y=c_k)}{sum_k{P(X=x|Y=c_k)·P(Y=c_k)}} ]分母是根据全概率公式得到
因此,朴素贝叶斯可以表示为:
[y=f(x)=argmax_{c_k}frac{P(Y=c_k)prod_{j}{P(X^{(j)}=x^{(j)}|Y=c_k)}}{sum_{k}{P(Y=c_k)prod_{j}P(X^{(j)}=x^{(j)}|Y=c_k)}} ]为了简化计算,可以将相同的分母去掉
优点:实现简单,学习与预测的效率都很高
缺点:分类的性能不一定很高
-
逻辑回归(Logistic Regression, lR)
一种对数线性模型,它的输出是一个概率,而不是一个确切的类别
逻辑斯蒂函数:
[h_ heta(x)=frac{1}{1+e^{- heta Tx}},P(Y=1|X; heta)=h_{ heta}(x),P(Y=0|x; heta)=1-h_{ heta}(x) ]图像:

对于给定数据集,应用极大似然估计方法估计模型参数
[l( heta)=logL( heta)=sum_{i=1}^{N}y^{(i)}logh(x^{i})+(1-y^{i})log(1-h(x^{i})) ]优点:实现简单、分类时计算量小、速度快、存储资源低等
缺点:容易欠拟合、准确率不高等
-
支持向量机(Support Vector Machine, SVM)
在特征空间中寻找到一个尽可能将两个数据集合分开的超平面(hyper-plane)
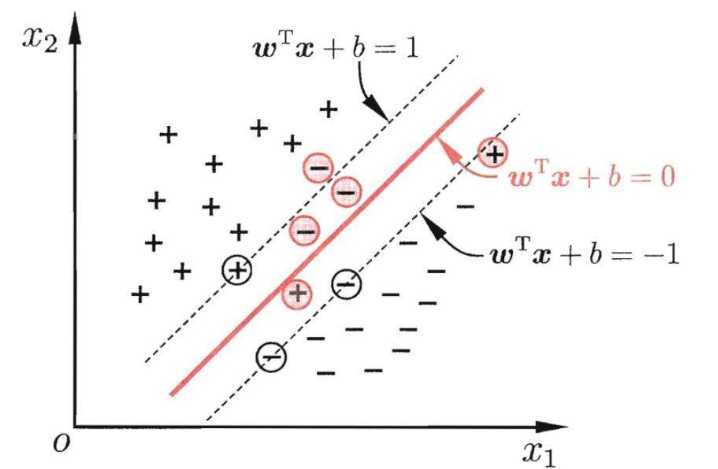
对于线性不可分的问题,需要引入核函数,将问题转换到高维空间中
优点:可用于线性/非线性分类,也可以用于回归;低泛化误差;容易解释;计算复杂度低;推导过程优美
缺点:对参数和核函数的选择敏感
中文垃圾邮件分类实战
数据集分为:ham_data.txt 和 Spam.data.txt , 对应为 正常邮件和垃圾邮件
其中每行代表着一个邮件
主要过程为:
- 数据提取
- 对数据进行归整化和预处理
- 提取特征(tfidf 和 词袋模型)
- 训练分类器
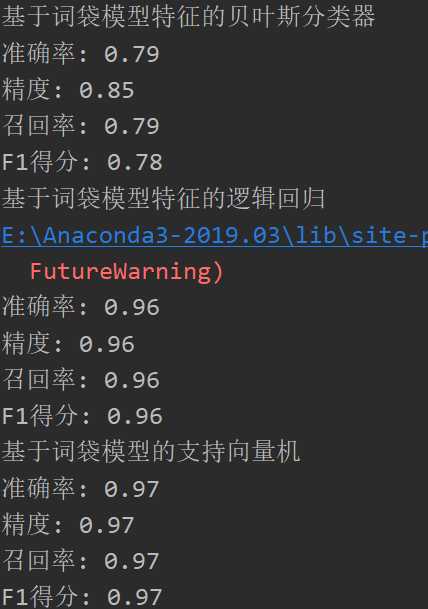
- 基于词袋模型的多项式朴素贝叶斯
- 基于词袋模型的逻辑回归
- 基于词袋模型的支持向量机
- 基于 tfidf 的多项式朴素贝叶斯
- 基于 tfidf 的逻辑回归
- 基于 tfidf 的支持向量机
- 用 准确率(Precision)、召回率(Recall)、F1测度 来评价模型
代码放在 GitHub 上了
https://github.com/CuveeFer/my-nlp
结果:

以上是关于文本分类(机器学习方法)的主要内容,如果未能解决你的问题,请参考以下文章