解析全闪对象存储
Posted 刘爱贵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解析全闪对象存储相关的知识,希望对你有一定的参考价值。
1 序言
从文件存储开始,我们开始定义信息的存储:
人们对存储的认知,大多都是从文件开始的。文件保存了信息,可进行随机读改,文件按目录进行组织,等等。
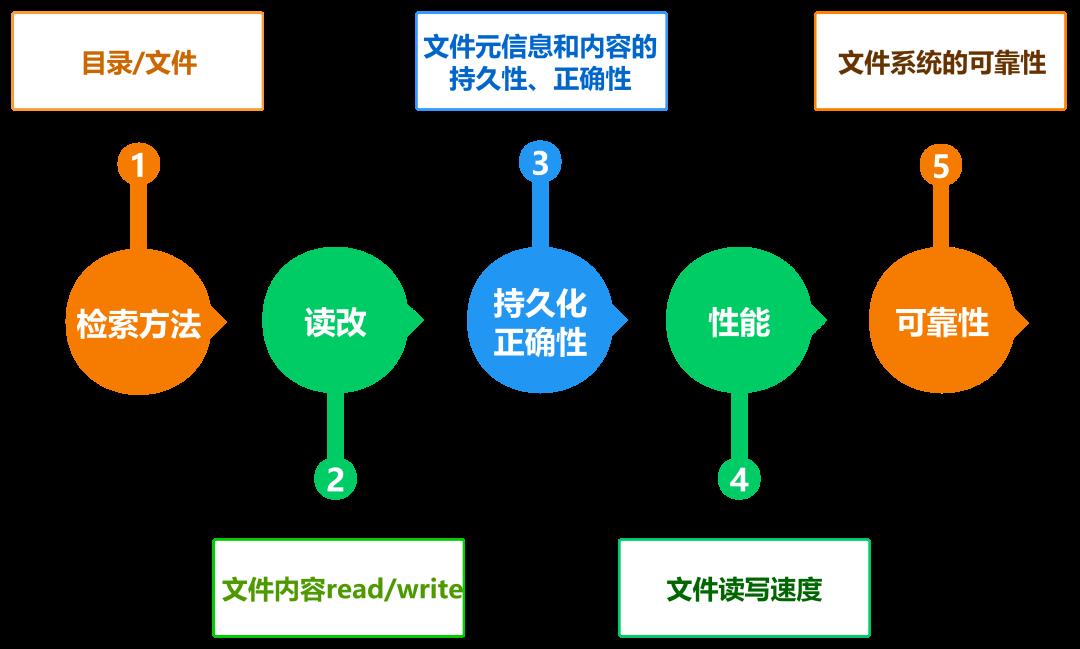
存储系统的升级、进化过程:
随着信息化世界的开始,高价值数据量高速增长,对数据存储系统的需求也不断变化,推动了存储系统的不断进化。
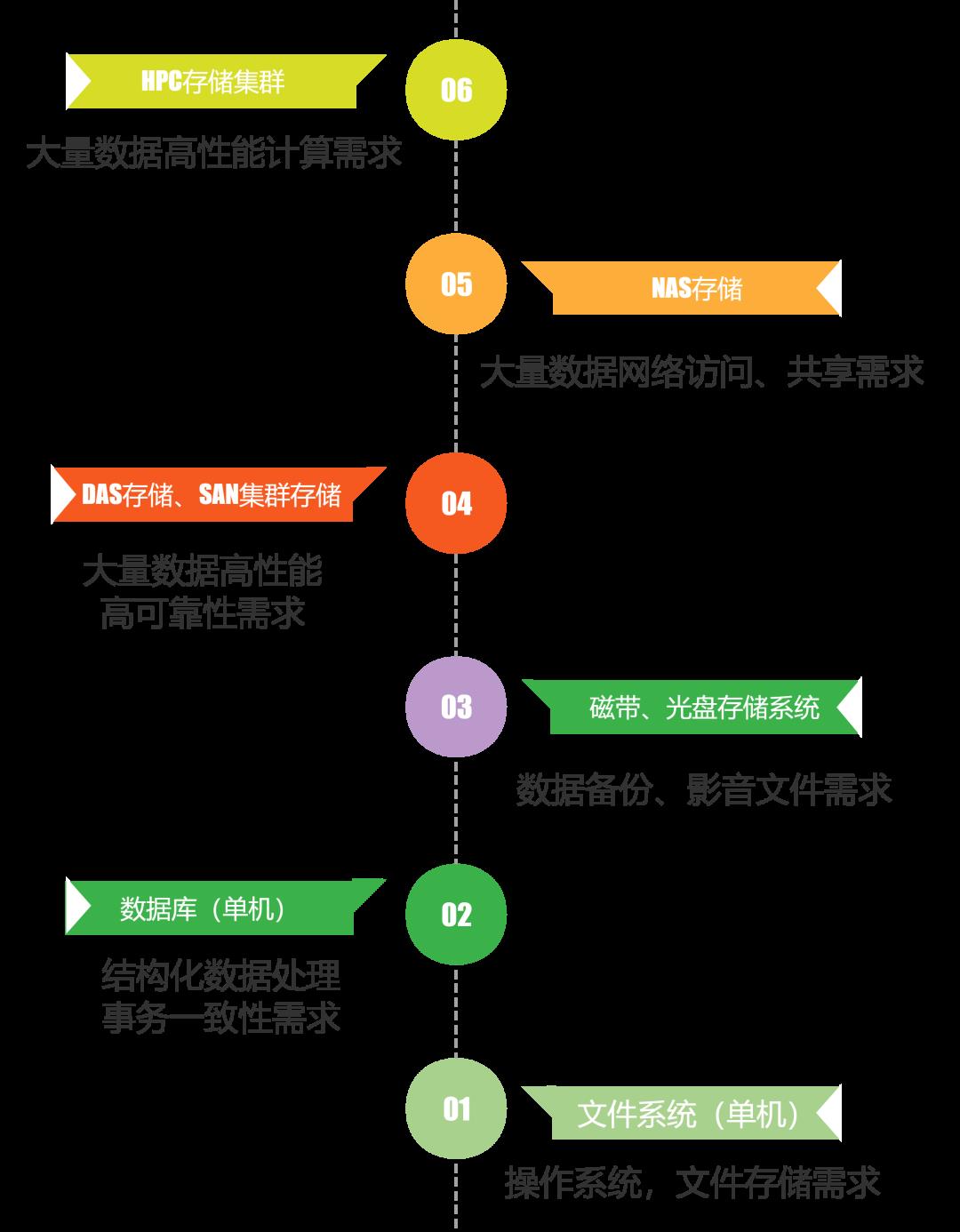
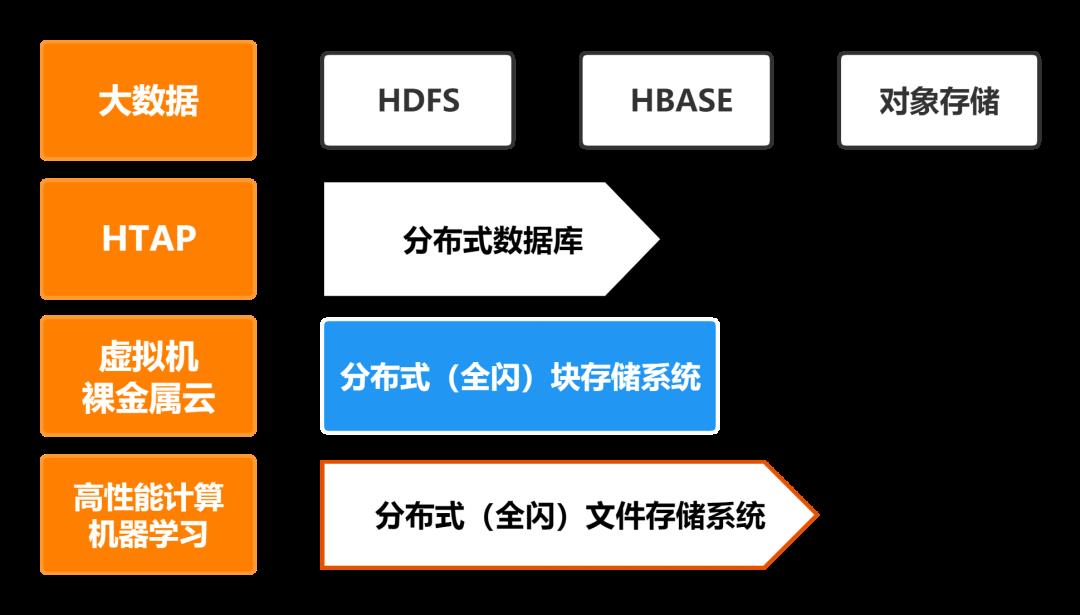
不同场景下的分布式架构存储系统:
进入互联网、AI时代后,数据量增长速度远远大于硬件能力增长速度,分布式架构取代集中架构就成了必然,适用于不同场景的大量分布式架构的存储系统如雨后春笋一般涌现出来。
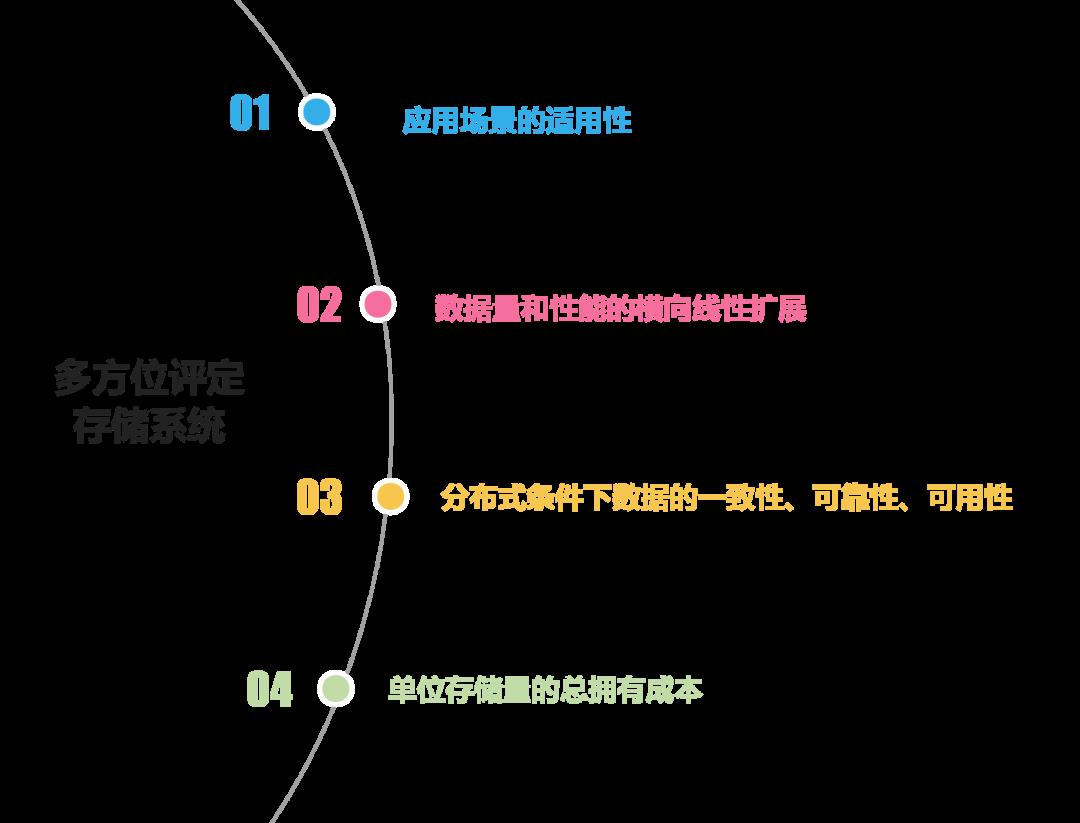
总体上,存储系统的进化是由下面几个因素决定的:
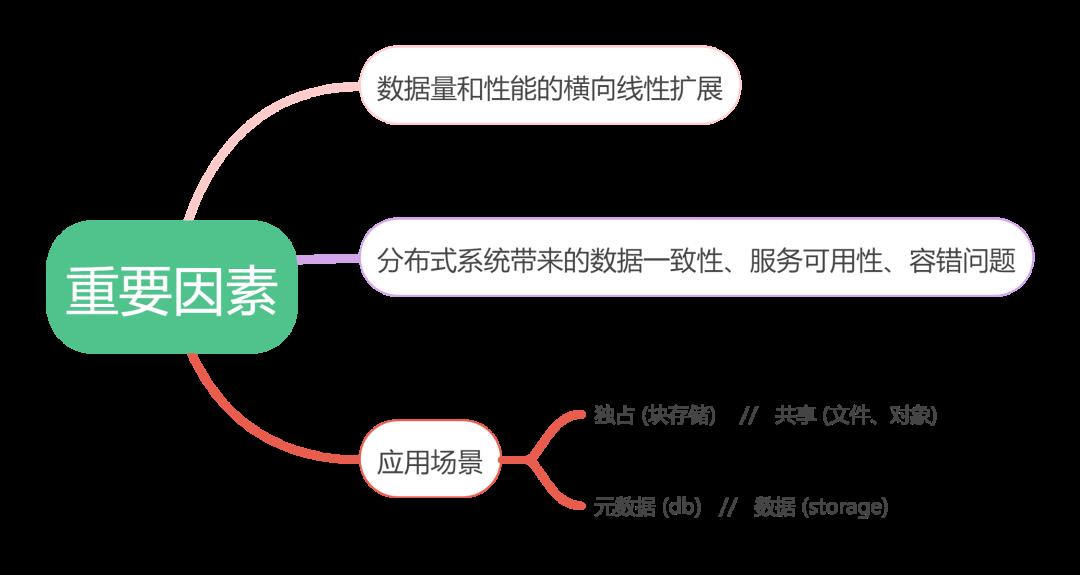
衡量一个存储系统的好坏,也要从以下几个方面出发:
2 对象存储的简介
对象存储 简而言之就是基于key/value的存储。逻辑上,对象存储可看作是一个无穷大的key/value表。
很多同学都熟悉基于kv的缓存,比如redis和memcache。当kv能完善的进行持久化,就具备了对象存储的雏形。
基于kv的数据库,也是一种对象存储,只是存储容量有限,限定用于存储元数据。
一般意义上的对象存储,是存储数据的存储系统,具有容量和性能的良好的横向扩展能力,适用于存储大量的非结构化数据。
对象存储产生的原因,是为了应对大量非结构化数据的存储需求 - 这些数据量太大了,使用传统存储成本太高,规模极大扩展导致的管理和使用复杂性也大大增加。因此急需一种部署、管理、使用简单的,易于横向扩展的,适用非结构化数据的,低成本的存储系统,这就是对象存储。
相应的,对象存储的主要目的,就是简单、低成本的存取和管理大量的非结构化数据。当对象存储和云存储需求结合后,对象存储被赋予了云端数据生命全周期管理的使命。
以上就是对象存储的由来和发展方向。
3 对象存储的特点和优点
简单易用,适用范围广
标准Restful API(和基于API封装的SDK)方式访问,不依赖OS/平台,随时随地访问数据(无论是虚拟机、容器、嵌入式系统,只要有网络就可以访问)
数据组织扁平简单,本质上就是通过key去访问(value,attribute)。在此基础上,支持根据key读写value、根据key范围scan出attribute等能力。数据管理能力简洁而强大,在数据量大的情况下,元数据管理性能远超文件系统。
天然云存储
1)AWS S3是被最广泛兼容的对象存储接口协议,是对象存储接口协议的实践上的通用标准。S3是为支持云存储而定义的,天然支持云原生。
2)多租户数据生命周期全程云端管理(授权;访问控制;压缩;加密;标签;日志审计;法规依从;WORM;数据配额;Qos;多版本;分层;远程复制;...)。
3)容器通过S3即时访问对象存储,无需挂载。
4)扩展性好,存储空间和性能按需(声明式 API)弹性供给,供给量上限极大。
5)故障容忍和自愈。
6)自动化运维。
低成本
数据只读,不可修改,在此前提下可优化存储系统,降低成本。
部署、管理简单,维护成本低。
4 对象存储的限制
适用数据类型范围限制
适用数据类型为非结构化数据,不适用需要随机修改的结构化数据。
访问接口的兼容性
只能通过Restful接口访问,不兼容Posix/Nas,多数老的应用如果要适用对象存储,必须通过Posix/Nas网关。
性能限制
访问延迟高(云存储软件栈,协议层和存储层分离等原因导致)。
在上一节“对象存储的来龙去脉”中,我们介绍了驱动存储系统进化的要素,对象存储的起因、发展方向和特点。本节,我们结合对象存储的使用场景,阐述对象存储的应用。
第1则 -- 对象存储和非结构化数据 --
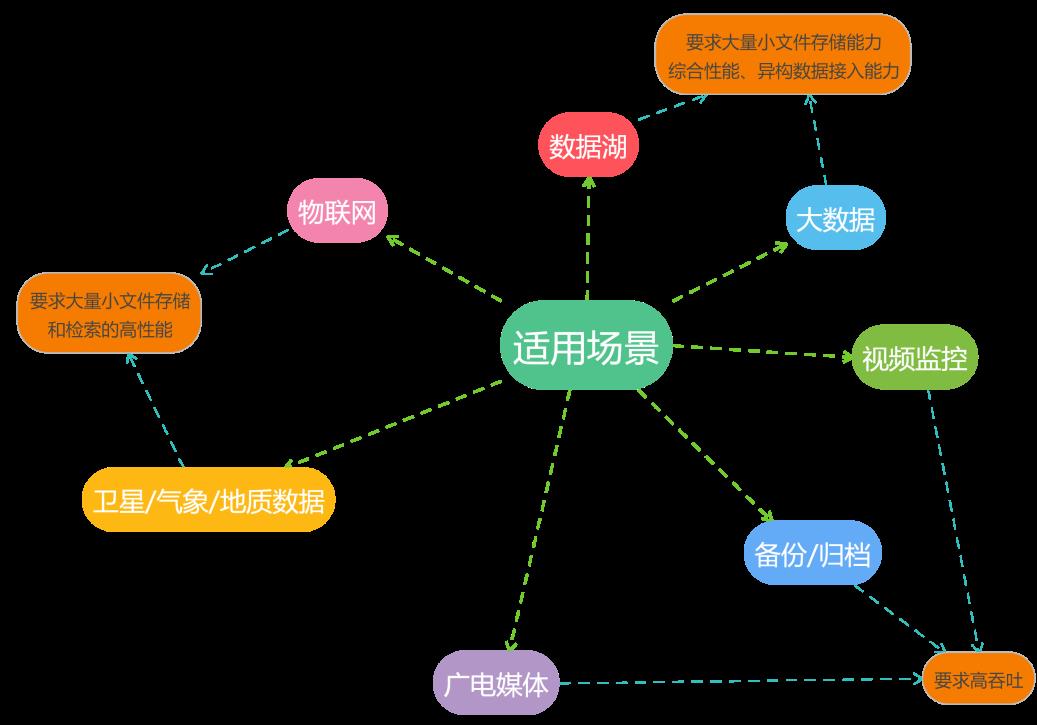
我们知道,对象存储是为了解决大规模非结构化数据存储的痛点而诞生的。所以,对象存储非常适合大量文档、图片、视频存储和处理的场景,包括媒体、备份/归档、视频监控、卫星/气象/地质数据、物联网、大数据、数据湖等等。这些场景的基本要求都是低成本、高性能的存取和处理大量的文档数据,同时,在文件大小、数量、IOPS性能等方面的侧重点不同。比如,媒体、备份/归档、视频监控场景一般都是大文件,要求高吞吐能力;卫星/气象/地质数据、物联网场景可能会有大量小文件,要求大量小文件存储和检索的高性能;大数据、数据湖场景的要求则更全面,包括大量小文件存储能力、综合性能、异构数据接入能力。
在对象存储大规模应用之前,大部分非结构化数据是保存在以NAS为代表的廉价、简便的存储系统上。对象存储系统必须要考虑如何兼容旧的存储系统和应用系统。在一个很长的产品替代期间,新部署的对象存储系统必须能同时适配新、旧数据和应用。这就需要存储网关和存储纳管系统。
以视频监控行业的存储为例。年代比较老的视频监控系统大部分用NAS存储数据。对象存储系统相比NAS系统,有可靠性高、扩展性好、成本低、全局命名空间、易于数据处理等诸多优势。但要用对象存储替代NAS存储,而不修改应用系统(只支持NAS协议),则需要通过NAS转对象存储网关。同时,旧的NAS存储系统和新的对象存储系统会在一段时间周期内并存,需要统一纳管、数据导入(NAS数据导入对象存储)等功能。
在老版本的大数据系统中使用对象存储,也需要部署HDFS转对象网关。新版本的大数据系统可直接使用S3兼容的对象存储。
第2则 -- 对象存储和云 --
对象存储不仅仅是解决了海量非结构化存储的难题,进一步,还成为云存储的标准。
云存储发展到今天,主要目标是给基于容器、微服务架构的云端应用提供敏捷、高可用、可靠、安全的存储。
从数据和服务的可用性层面看,云存储具备以下特点:
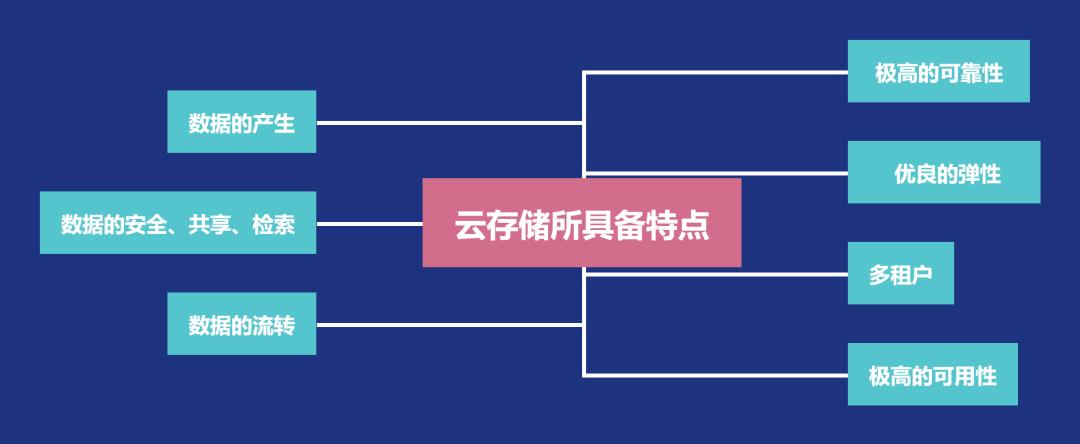
极高的可靠性
相比传统存储,云应用对数据可靠性的标准大大提高。比如,公有云存储的可靠性标准可达99.99999999%
极高的可用性
相比传统存储,云应用对存储服务可用性的标准非常高。比如,公有云存储的可用性标准可达99.995%
优良的弹性
按需存储 - 不用预先分配大量的资源,而是动态供给
应存尽存 - 应用可以存储任意多的数据,不需要为此修改程序、扩容和中断服务
性能弹性 - 性能线性、敏捷的水平扩展;在业务高峰期,要求迅速的启动更多的服务资源,业务请求回落,回收资源
多租户
租户的资源分配可依照策略进行,达成不同租户数据的安全、可用性和性能隔离
从数据的应用层面看,云存储管理数据的整个生命周期。
数据的产生
从云外导入,或在云内产生
压缩、去重
配额、QoS
数据的安全、共享、检索
安全合规(多版本;加密;日志审计、法规依从;WORM...)
授权、访问控制
标签检索
数据的流转
生命周期
分层
复制和迁移
云存储包括块存储、文件存储和对象存储。其中只有对象存储,是最符合云原生规范的,能最好的达成云存储数据的可靠性、可用性、弹性、多租户、全生命周期管理。对象存储,是云存储的基石和未来。
第3则 -- 对象存储和数据湖 --
大量数据存储的用途主要是数据分析。基于大数据的数据分析、机器学习、智能化是未来数字化的方向。但是,当前大数据处理系统存在数据源分散、信息系统孤岛等问题,导致数据处理的困难和低效。数据湖是为了解决信息孤岛问题,统一高效处理数据而诞生的。
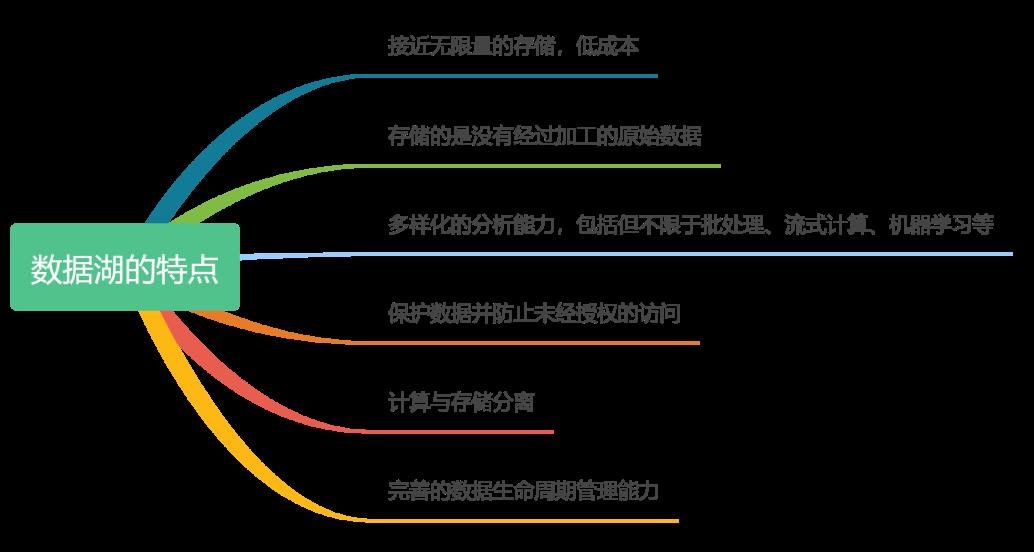
数据湖是一个架构体系。通过数据湖可以快速、安全合规的存储、处理、分析海量的数据;以数据为导向,通过接口和外部的计算资源交互集成,实现任意来源、任意速度、任意规模、任意类型数据的获取、存储和全生命周期管理。
有了数据湖,数据分析系统不用在不同的数据仓库和文件存储之间进行频繁切换,也不需要重复的写抽取、加载的逻辑,极大提升了效率。
数据湖的存储依托于S3兼容的对象存储,S3是数据湖最重要的一部分,这缘于其强大的特性:
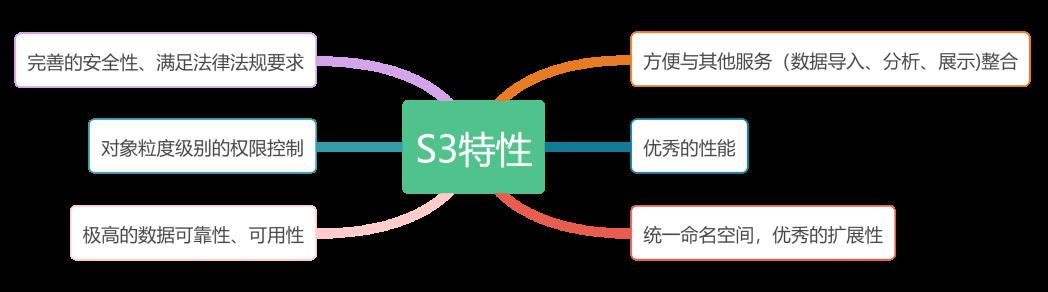
亚马逊云计算服务(AWS)明确的将S3存储作为数据湖的底座,数据流转的中枢。S3兼容的对象存储,是数据湖存储的不二选择。
在上一节“对象存储的使用场景”中,我们介绍了对象存储在大规模非结构化数据存储、云存储、大数据和数据湖等场景的使用。
那么,优秀对象存储产品是怎样的?如何设计、实现?本节,我们来分析、探讨这些问题。
通过前两节的学习,我们应该了解了对象存储的特点和要素,进而可以勾画出一个比较完美的对象存储的轮廓。但实践上,很多优点是难以共存的,或者说是无法一步到位的,必须做取舍。比如高性能和低成本,一般的,性能的增高会带来成本的上升。又比如全功能和精简功能,全功能适用面广,但会带来软件bug多、难以维护的后果。所以,不同特点的对象存储产品,有不同的受众和适用范围。
以开源对象存储MinIO为例
MinIO的设计哲学是架构上极简,功能上做好兼容S3。安装、部署、使用MinIO都是非常简单的,同时MinIO在功能上兼容S3做的较好,非常适合小规模云原生应用场景。凭借这两个主要特点,MinIO的开源社区非常活跃,MinIO作为一个轻量、优秀的对象存储被广泛使用。
其实,MinIO也有明显的短板,但这并不妨碍它在小规模云原生场景下的使用。
MinIO的短板在扩展性、规模和性能的限制
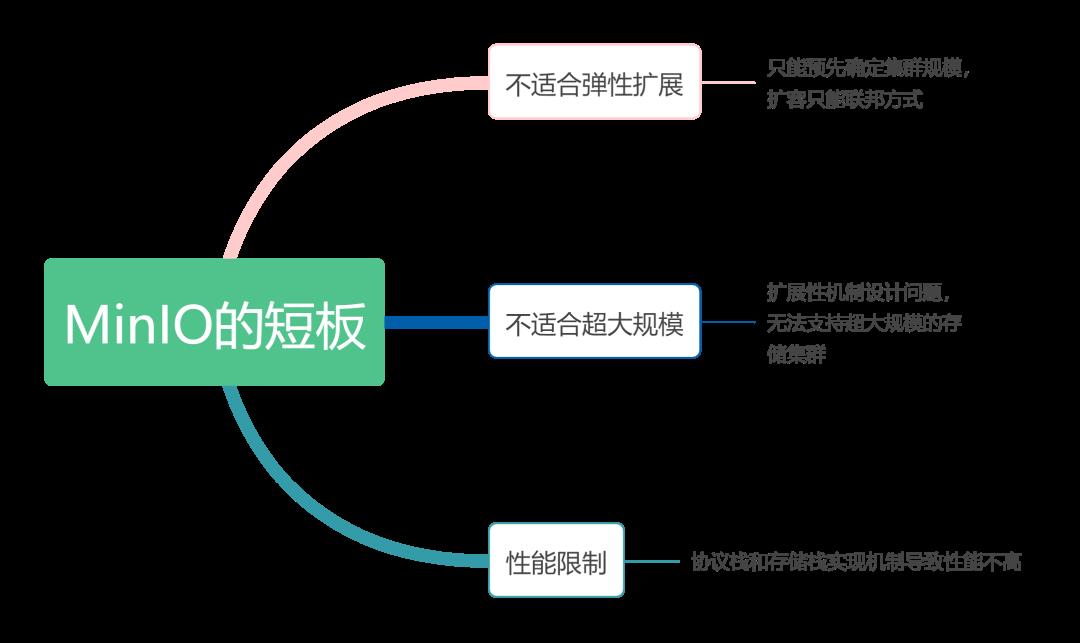
目前其他对象存储产品,在功能、弹性、规模、性能等方面也都有所取舍,总体上,都是规模相对大(相对分布式文件,但没做到极大规模)、成本低、性能一般。
对象存储的主要用途是大规模数据处理,从需求上,应该不限于大文件和较高延迟的场景,机器学习等要求高IOPS、低延迟的场景,对象存储也应该可以胜任。这种场景,只有新一代的高性能、全闪对象存储产品能够胜任。
下面我们一起探讨新一代高性能对象存储产品的需求和应该具备的能力。
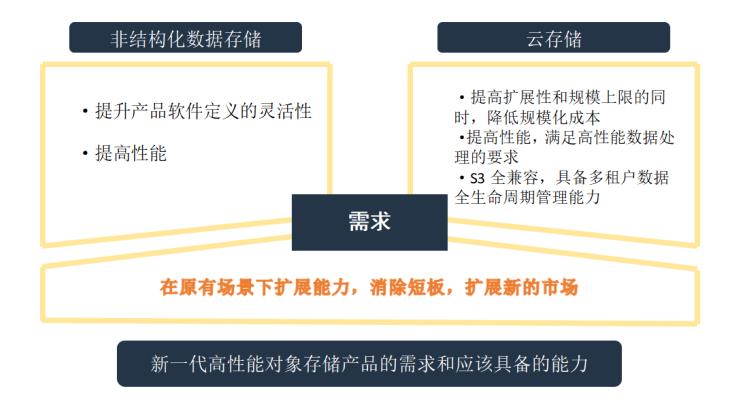
1 需求:在原有场景下扩展能力,消除短板扩展
新的市场
→ 非结构化数据存储
提升产品软件定义的灵活性
提高性能
→ 云存储(私有云、混合云、数据湖)
提高扩展性和规模上限的同时,降低规模化成本
提高性能,满足高性能数据处理的要求
S3全兼容,具备多租户数据全生命周期管理能力
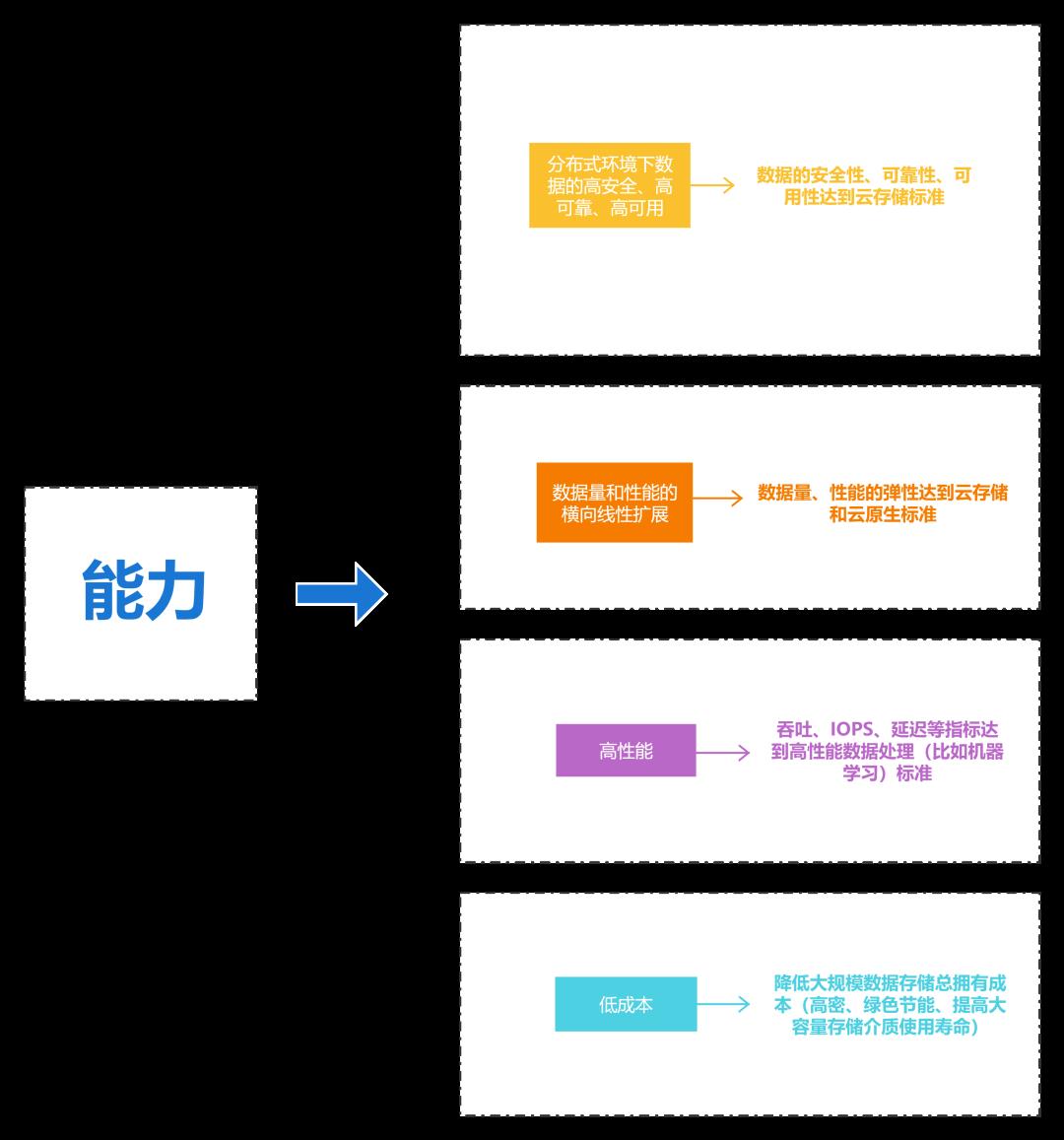
2 能力
→ 分布式环境下数据的高安全、高可靠、高可用
数据的安全性、可靠性、可用性达到云存储标准
→数据量和性能的横向线性扩展
数据量、性能的弹性达到云存储和云原生标准
→ 高性能
吞吐、IOPS、延迟等指标达到高性能数据处理(比如机器学习)标准
→ 低成本
降低大规模数据存储总拥有成本(高密、绿色节能、提高大容量存储介质使用寿命)
以上需求和能力,最核心的问题是,如何达成顶级性能,同时支持超大规模数据弹性、低成本的存储。针对核心问题,我们逐步分析设计要点。
3 设计要点
→ 达成顶级性能,必须采用全闪存储架构,降低软件栈数据流延迟
软件栈数据流(以写入为例),包括协议层处理、链路层(RPC和RDMA)、存储层处理。其中存储层处理包括数据冗余计算、资源分配、写数据、写元数据(资源元数据和对象元数据)事务,IOPS瓶颈和延迟大部分发生在存储层。
要降低存储层的延迟,最关键点在于分布式元数据服务。
元数据服务必须是分布式可水平扩展的,才能支持存储产品的容量、性能的水平扩展。
无元数据服务架构,比如一致性Hash,存在两个致命缺点,在大型分布式系统中不适用。其一,没有元数据的范围查询能力,范围查询会放大到整个集群,导致在有大量对象的系统中元数据管理性能会非常差。其二,集群弹性需求导致的rebalance状态非常复杂,背离了无状态Hash的初衷。
回到元数据服务上。元数据服务的数据层一般要在Raft协议上实现MVCC集合的副本复制、水平Sharding。接口层要实现事务。这些事项使得实现低延迟的元数据服务难度非常高,需要对这些核心技术切实的掌握和优化。
低延迟元数据服务之外,还有另一个关键点,是全闪软件栈的计算调度。
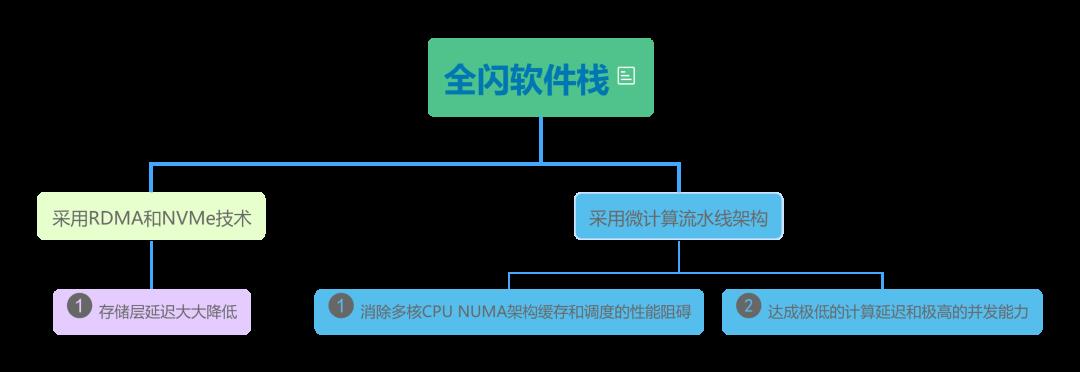
全闪软件栈采用RDMA和NVMe新技术,存储层延迟大大降低,已经不是性能瓶颈,相反,未优化的多核CPU环境下的计算和调度在极高的并发下会成为性能瓶颈。全闪软件栈采用微计算流水线架构,消除多核CPU NUMA架构缓存和调度的性能阻碍,达成极低的计算延迟和极高的并发能力。
→ 支持超大规模数据弹性存储,必须采用全分布式架构加大容量存储介质
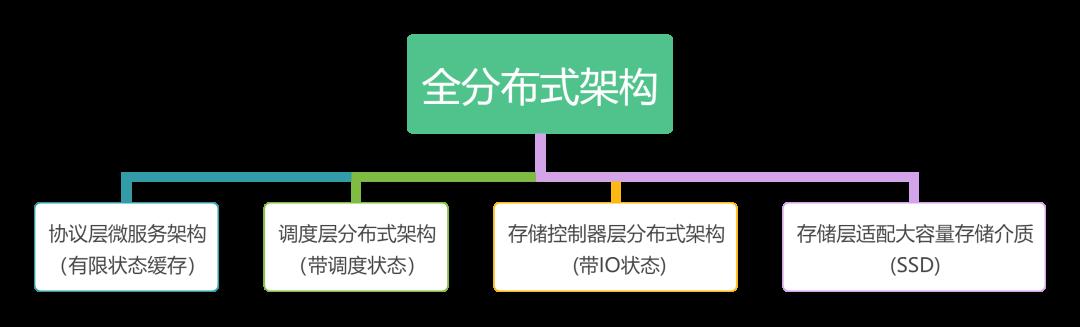
其中,带状态分布式服务集群的弹性伸缩,是核心难点。
→ 分布式环境下数据的高安全、高可靠、高可用
当前,企业级大容量QLC_SSD已经被全闪存储软件系统应用。全闪存储软件栈要解决QLC_SSD擦写次数低的问题。如果在存储集群层面处理好了SSD的GC、写放大、磨损均衡问题,我们可以做到针对集群中所有SSD的降低写放大比例和均衡擦写次数,不但可以使用擦写次数低的QLC_SSD,还大大增加了SSD的使用寿命。
ZNS_SSD是使用大容量SSD、降低成本和功耗的标准。全闪存储软件栈要适配、支持ZNS_SSD的使用。
要将大容量SSD成本做到最低,可以采用定制化的Open_Channel_SSD方案,将SSD的FTL层和纠错层放到主机端,节省了DRAM控制器,适配使用廉价的SSD颗粒,极大的降低SSD成本。
全闪存储软件栈还可以在集群资源调度上达成节能,充分利用SSD的节能状态。
→ 高性能和低成本的矛盾,通过数据分层来缓解
热数据层采用高性能全闪软件栈和高价的高性能NVMe_SSD。
温冷数据层采用普通全闪软件栈和廉价的大容量SSD。
数据分层透明化,智能化,应用无感知。
4 设计讨论
为何提出了一个看上去完美的分布式架构,而不是以上说的取舍?
我们在介绍MinIO的时候,讨论了取舍,以架构极简和功能为主。但需求是发展的,对象存储系统的水平扩展的弹性、极高性能,已经成为当下和未来最重要的需求,可以扩展大片的市场,所以我们的重点放在最难的这两个方面上,做分布式全闪架构的企业级存储。
5 大道云行FOSS全闪分布式对象存储介绍
大道云行FOSS,是采用先进的分布式全闪架构的云存储系统,以超大规模数据长期、可靠、绿色低碳、高性能存取为目标。
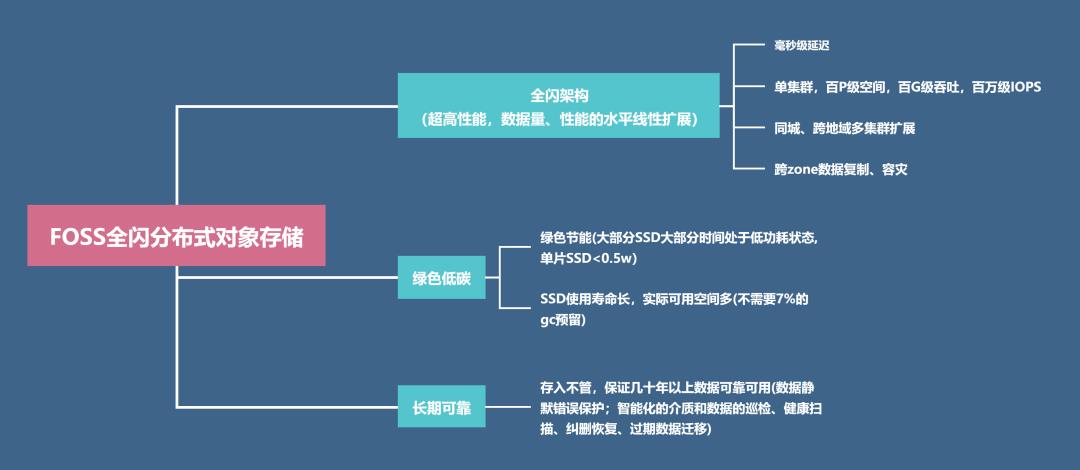
→全闪架构,超高性能,数据量、性能的水平线性扩展
毫秒级延迟
单集群,百P级空间,百G级吞吐,百万级IOPS
同城、跨地域多集群扩展
跨zone数据复制、容灾
→ 绿色低碳
绿色节能(大部分SSD大部分时间处于低功耗状态,单片SSD<0.5w)。
SSD使用寿命长,实际可用空间多(不需要7%的GC预留)。
→ 长期可靠
存入不管,保证几十年以上数据可靠可用(数据静默错误保护;智能化的介质和数据的巡检、健康扫描、纠删恢复、过期数据迁移)。
我们能够看到,两个重要过程正在发生和发展。
其一,是存储替代
当前我国大部分的非结构化数据都保存在老旧的NAS存储系统上。NAS存储系统有很多的问题:
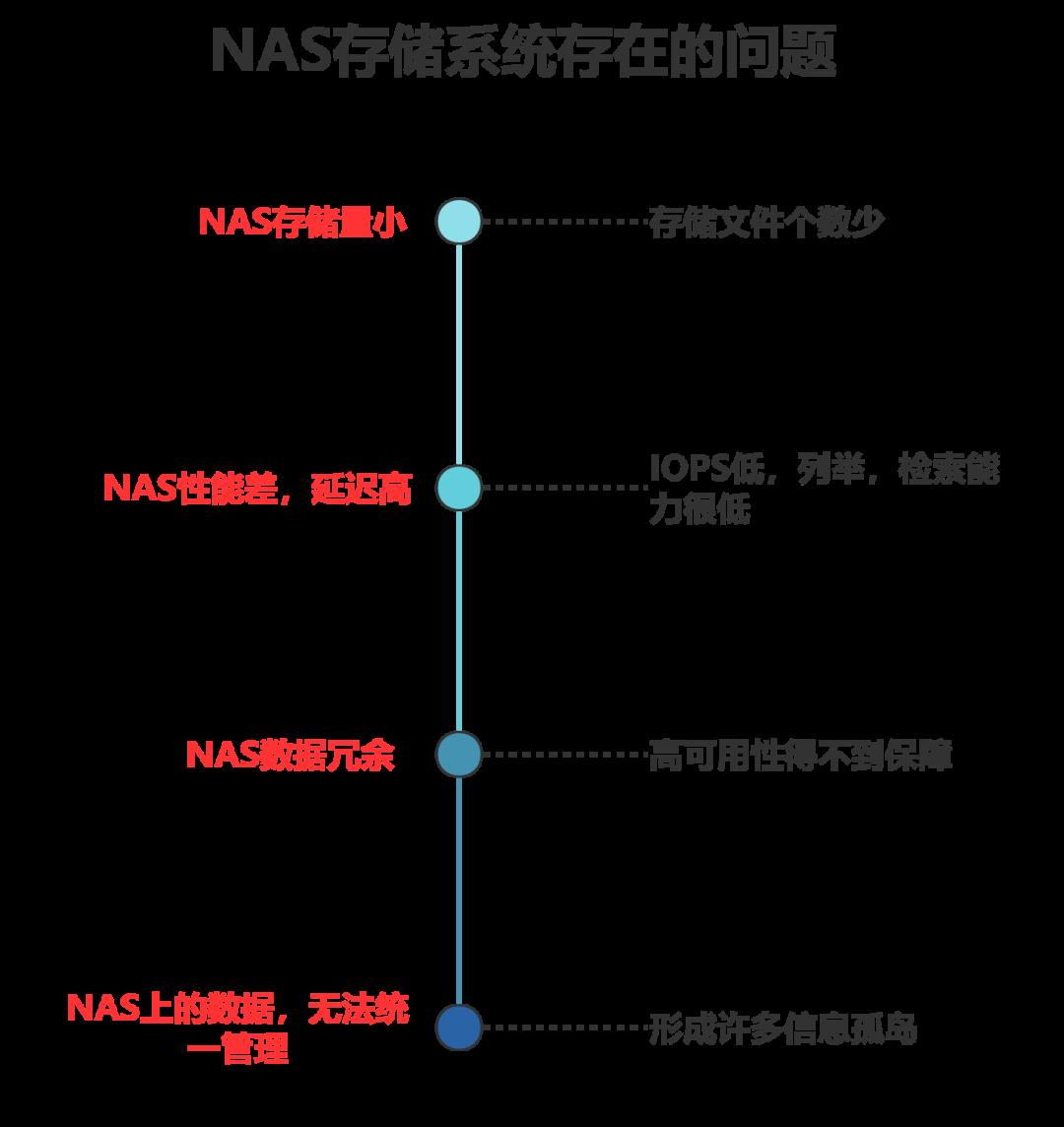
以对象存储为核心的云存储(私有云,混合云),在容量、扩展性、安全性和可靠性、性能、统一管理、多租户、数据全生命周期管理等方面全方位超越了NAS存储,且总体使用成本相当。所以,对象存储替代NAS,提高各行各业应用系统的生产力,是必然的。当然这个过程是渐进的,伴随着存储网关和纳管系统的使用。
大数据系统2.0,提出了计算和存储分离的概念,主张用数据湖统一管理所有的数据处理。大数据存储正在加速从HDFS转向(S3或Swift兼容的)对象存储。
其二,是云存储市场的蓬勃发展
广义上的云存储,包括不同规模的分布式存储,构成边缘云、私有云、混合云、公有云。
当前,以数据为驱动力的数字经济正在成为我国经济发展的新引擎,数据即价值。但数据的价值需要通过智能化的数据分析系统得以发掘和体现。未来,各行各业,都需要符合行业特点的、智能化的数据分析系统,提高生产力和竞争力。
大数据的最终目的是智能化,而智能化需要依赖机器学习、深度学习等AI技术。所以,未来的数据处理平台,必须支持机器学习,相应的,对存储系统的高性能(高IOPS,低延迟,文件个数多)有很高的要求。
未来,智能化数据处理平台必定是构建在云上的,而基于全闪架构的高性能、大规模、低成本的云原生存储系统,也会一直伴随着智能化云一起蓬勃发展,成为主导的存储系统。
数据处理智能化,不仅仅是高性能集中处理,还包括边缘计算、冷数据存取、备份和归档、远程复制和容灾,等等,存储系统在这里有巨大的市场空间。但越往后,智能化程度越高,对云原生存储系统的要求就越高,门槛也越高。
该怎么做?
前景虽然美好,但有效提高生产力,并用新的生产力去替代老的,是个逐步的过程。也就是说,有一个市场发展的时间窗口。
我们要聚焦在行业智能化数据分析的需求上,打造符合各行业特点的智能化数据分析平台,比如行业云、物联网、数据湖,真正有效的把数据智能化转变为生产力和竞争力,这样,我们的存储系统才拥有了高价值数据,体现了其卓越能力的价值。
具体的,就是深入参与企业、行业数据系统和物联网/云/数据湖的方案和建设,伴随着云(私有云,边缘云)在数据处理智能化方面一起发展。
参考资料:
[1] AWS. 数据湖存储
https://aws.amazon.com/cn/products/storage/data-lake-storage/?nc=sn&loc=4
[2] Minio. WhitePaper
https://storage.oak-tree.tech/acorn/documents/minio.high-performance-s3.pdf
[3] Mikito Takada. Distributed Systems for Fun and Profit
[4] Martin Kleppmann. Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems
[5] Diego Ongaro, John Ousterhout. Raft Consensus Algorithm
https://raft.github.io/raft.pdf
(TaoCloud团队原创)
以上是关于解析全闪对象存储的主要内容,如果未能解决你的问题,请参考以下文章