近邻法总结
Posted 小龙呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了近邻法总结相关的知识,希望对你有一定的参考价值。
目录
1.最近邻法
- 算法思想
对于一个新样本,把它逐一与已知样本比较,找出距离新样本最近的已知样本,以该样本的类别作为新样本的类别。 - 算法描述


2.k-近邻法


3.近邻法的快速算法


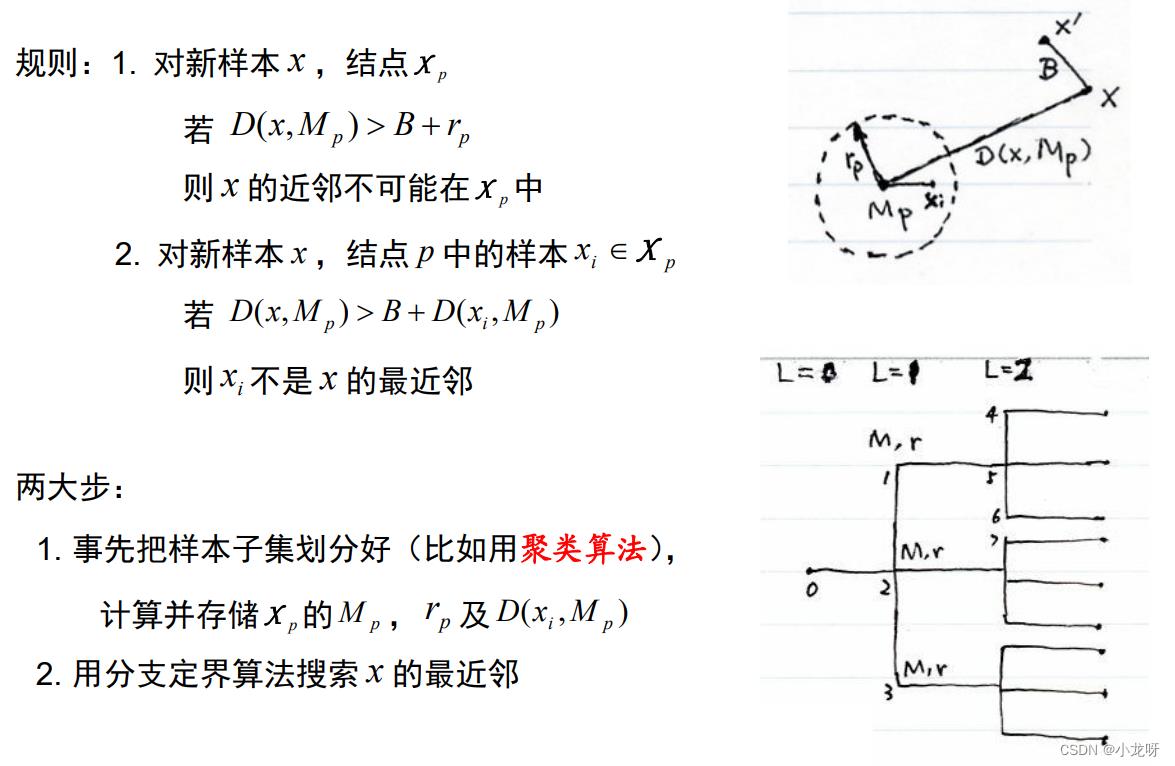



4.剪辑近邻法
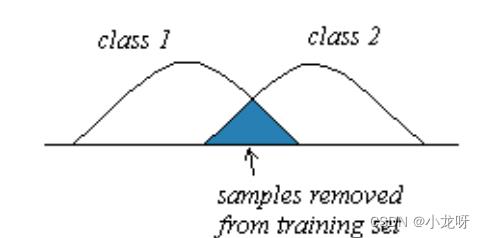
- 算法思想
如果训练样本处在两类分布重合的区域,其中部分样本就会落在最优分类面错误一侧,在进行近邻法分类时,这样的训练样本会误导决策从而使分类错误。
如果设法把图中阴影部分的已知样本去掉,决策时就不会受到那些错分样本的影响,可以使近邻法的决策面更接近最优分类面。 - 算法步骤
①划分
将样本集划分为考试集 X N T X_NT XNT和训练集 X N R X_NR XNR两部分。
②剪辑
用训练集 X N R X_NR XNR中的样本对考试集 X N T X_NT XNT中的样本进行近邻法分类,从 X N T X_NT XNT中除去被错误分类的样本,剩余样本构成剪辑样本集 X N T E X_NTE XNTE。
③分类
用 X N T E X_NTE XNTE对未来样本进行近邻法分类。 - 多重剪辑方法(MULTIEDIT)
①划分
把样本集随机划分为s个子集, X 1 , X 2 , . . . , X s , s ≥ 3 X_1,X_2,...,X_s,\\quad s\\ge3 X1,X2,...,Xs,s≥3。
②分类
用 X ( i + 1 ) m o d ( s ) X_(i+1)mod(s) X(i+1)mod(s)对 X i X_i Xi中的样本分类, i = 1 , 2 , . . . , s i=1,2,...,s i=1,2,...,s。比如,如果s=3,则用 X 2 X_2 X2对 X 1 X_1 X1分类,用 X 3 X_3 X3对 X 2 X_2 X2分类,用 X 1 X_1 X1对 X 3 X_3 X3分类。
③剪辑
从各个子集中去掉在②中被分错的样本。
④混合
把剩下的样本合在一起,形成新的样本集 X N E X_NE XNE。
⑤迭代
用新的样本集 X N E X_NE XNE替代原样本集,转①。如果在最近的m次迭代中都没有样本被剪掉,则终止迭代,用最后的 X N E X_NE XNE作为剪辑后的样本集。
5.压缩近邻法
- 算法思想
根据近邻法的分类原理,可以发现,那些远离分类边界的样本对于最后的分类决策没有贡献。
只要能够设法找出各类样本中最有利于用来区分其它类的代表性样本,就可以把很多训练样本去掉,简化决策的计算。 - 算法步骤
①将样本集 X N X_N XN分为两个活动的子集 X S X_S XS和 X G X_G XG,前者称作储存集Storage,后者称作备选集GrabBag。
②算法开始时, X S X_S XS只有一个样本,其余样本都在 X G X_G XG中。
对 X G X_G XG中的每一个样本 x x x,如果用 X S X_S XS中的样本可以对它正确分类,则该样本保留在 X G X_G XG中;否则移到 X S X_S XS。
以此类推,直到没有样本再搬移为止。
③ X S X_S XS中的样本作为代表样本,对未来样本进行近邻法分类。
6.错误率分析


本文内容参考:张学工教授的《模式识别》
如有错误或者不足之处,欢迎大家留言指正!
以上是关于近邻法总结的主要内容,如果未能解决你的问题,请参考以下文章