系统学习NLP(二十三)--浅谈Attention机制的理解
Posted Eason.wxd
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了系统学习NLP(二十三)--浅谈Attention机制的理解相关的知识,希望对你有一定的参考价值。
转自:https://zhuanlan.zhihu.com/p/35571412
Attentin机制的发家史
Attention机制最早是应用于图像领域的,九几年就被提出来的思想。随着谷歌大佬的一波研究鼓捣,2014年google mind团队发表的这篇论文《Recurrent Models of Visual Attention》让其开始火了起来,他们在RNN模型上使用了attention机制来进行图像分类,然后取得了很好的性能。然后就开始一发不可收拾了。。。随后Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》中,使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,他们的工作算是第一个将attention机制应用到NLP领域中。接着attention机制就被广泛应用在基于RNN/CNN等神经网络模型的各种NLP任务中去了,效果看样子是真的好,仿佛谁不用谁就一点都不fashion一样。2017年,google机器翻译团队发表的《Attention is all you need》中大量使用了自注意力(self-attention)机制来学习文本表示。这篇论文引起了超大的反应,本身这篇paper写的也很赞,很是让人大开眼界。因而自注意力机制也自然而然的成为了大家近期的研究热点,并在各种NLP任务上进行探索,纷纷都取得了很好的性能。
Attention机制的本质
attention机制的本质是从人类视觉注意力机制中获得灵感(可以说很‘以人为本’了)。大致是我们视觉在感知东西的时候,一般不会是一个场景从到头看到尾每次全部都看,而往往是根据需求观察注意特定的一部分。而且当我们发现一个场景经常在某部分出现自己想观察的东西时,我们就会进行学习在将来再出现类似场景时把注意力放到该部分上。这可以说就是注意力机制的本质内容了。至于它本身包含的‘自上而下’和‘自下而上’方式就不在过多的讨论。
Attention机制的理解
Attention机制其实就是一系列注意力分配系数,也就是一系列权重参数罢了。
用encoder to decoder来做引子
我们可以用机器翻译来作为例子。当给出一句‘我爱你’(sorce)中文,要将它翻译成英文‘I love you’(target)时,利用现在深度学习最为流行的model--encoder to decoder,‘我爱你’被编码(这里指语义编码)成C,然后在经过非线性函数$g$来decoder得到目标Target中的每一个单词$y1$,$y2$,$y3$。计算如下:
$$C = f(x1,x2,x3)$$ $$y1 = g(C)$$ $$y2 = g(C,y1)$$ $$y3 = g(C,y1,y2)$$
这样的过程称之为一个分心模型。这是因为sorce中每一个元素对语义编码C的作用是相同的,也就是每一个元素的重要程度都是一样的。可实际上,‘我’这个元素对target中的'I'的结果是影响最大的,其他元素的影响可以说是微乎其微。但是在上述模型中,这个重要程度没有被体现出来,所以这是一个分心的模型。而与其对应的注意力模型就是要从序列中学习到每一个元素的重要程度,然后按重要程度将元素合并。这就表明了序列元素在编码的时候,所对应的语义编码C是不一样的。所以一个体现attention机制运行的图示如下:

所以$C$就不单单是$x1,x2,x3$简单的encoder,而是成为了各个元素按其重要度加权求和得到的。也即:
$$Ci = \\sumj=0^Lxaijf(xj)$$
其中i表示时刻,j表示序列中第j个元素,$Lx$表示序列的长度,$f()$表示元素$xj$的编码。
现在抛开encoder-decoder
我们现在抛开encoder-decoder来说attention机制。既然attention是一组注意力分配系数的,那么它是怎样实现的?这里要提出一个函数叫做attention函数,它是用来得到attention value的。比较主流的attention框架如下:

上图其实可以描述出attention value的本质:它其实就是一个查询(query)到一系列键值(key-value)对的映射。
这个也就是attention函数的工作实质,如下图所示:
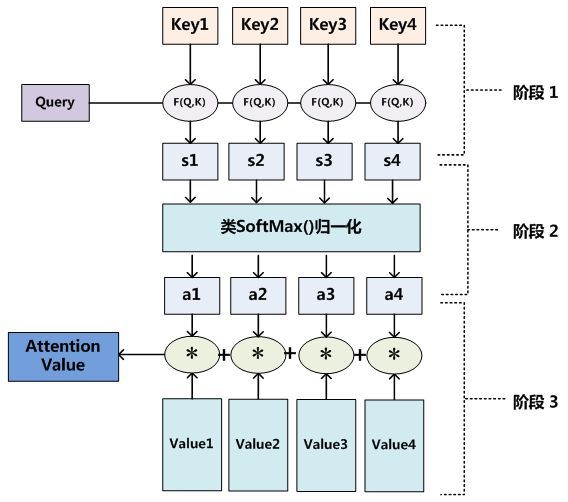
Attention函数工作机制
attention函数共有三步完成得到attention value。
- Q与K进行相似度计算得到权值
- 对上部权值归一化
- 用归一化的权值与V加权求和
此时加权求和的结果就为注意力值。公式如下:$$Attention Value = similarity(QK^T)V$$
在自然语言任务中,往往K和V是相同的。这时计算出的attention value是一个向量,代表序列元素$xj$的编码向量。此向量中包含了元素$xj$的上下文关系,即包含全局联系也拥有局部联系。全局联系是因为在求相似度的时候,序列中元素与其他所有元素的相似度计算,然后加权得到了编码向量。局部联系可以这么解释,因为它所计算出的attention value是属于当前输入的$x_j$的。这也就是attention的强大优势之一,它可以灵活的捕捉长期和local依赖,而且是一步到位的。
换一个角度理解Attention机制
说到这里,大家应该也明白attention机制具体是个啥吧。其实也不是很玄乎,就是把序列中各个元素分配一个权重系数。上面从attention函数得到了attention机制工作过程。现在换一个角度来理解,我们将attention机制看做软寻址。就是说序列中每一个元素都由key(地址)和value(元素)数据对存储在存储器里,当有query=key的查询时,需要取出元素的value值(也即query查询的attention值),与传统的寻址不一样,它不是按照地址取出值的,它是通过计算key与query的相似度来完成寻址。这就是所谓的软寻址,它可能会把所有地址(key)的值(value)取出来,上步计算出的相似度决定了取出来值的重要程度,然后按重要程度合并value值得到attention值,此处的合并指的是加权求和。
谈谈Attention机制的优劣
优点:
- 一步到位的全局联系捕捉
上文说了一些,attention机制可以灵活的捕捉全局和局部的联系,而且是一步到位的。另一方面从attention函数就可以看出来,它先是进行序列的每一个元素与其他元素的对比,在这个过程中每一个元素间的距离都是一,因此它比时间序列RNNs的一步步递推得到长期依赖关系好的多,越长的序列RNNs捕捉长期依赖关系就越弱。 - 并行计算减少模型训练时间
Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。但是CNN也只是每次捕捉局部信息,通过层叠来获取全局的联系增强视野。 - 模型复杂度小,参数少
模型复杂度是与CNN和RNN同条件下相比较的。
缺点:
缺点很明显,attention机制不是一个"distance-aware"的,它不能捕捉语序顺序(这里是语序哦,就是元素的顺序)。这在NLP中是比较糟糕的,自然语言的语序是包含太多的信息。如果确实了这方面的信息,结果往往会是打折扣的。说到底,attention机制就是一个精致的"词袋"模型。所以有时候我就在想,在NLP任务中,我把分词向量化后计算一波TF-IDF是不是会和这种attention机制取得一样的效果呢? 当然这个缺点也好搞定,我在添加位置信息就好了。所以就有了 position-embedding(位置向量)的概念了,这里就不细说了。
结语
Attention机制说大了就一句话,分配权重系数。当然里面还有很深的数学道理和理论知识,我还是没搞懂滴。所以这点浅显的理解就当茶语饭后的笑谈吧。
以上是关于系统学习NLP(二十三)--浅谈Attention机制的理解的主要内容,如果未能解决你的问题,请参考以下文章
系统学习NLP(二十四)--详解Transformer (Attention Is All You Need)