系统学习NLP(二十八)--GPT
Posted Eason.wxd
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了系统学习NLP(二十八)--GPT相关的知识,希望对你有一定的参考价值。
论文:Improving Language Understandingby Generative Pre-Training
1. 前言
本文对2018年OpenAi提出的论文《Improving Language Understandingby Generative Pre-Training》做一个解析。
一个对文本有效的抽象方法可以减轻NLP对监督学习的依赖。大多数深度学习方法大量的人工标注信息,这限制了在很多领域的应用。在这些情况下,可以利用来未标记数据的语言信息的模型来产生更多的注释,这可能既耗时又昂贵。此外,即使在可获得相当大的监督的情况下,以无人监督的方式学习良好的表示也可以提供显着的性能提升。到目前为止,最引人注目的证据是广泛使用预训练词嵌入来提高一系列NLP任务的性能。
2. OpenAI GPT原理
本文提出一种半监督的方式来处理语言理解的任务。使用非监督的预训练和监督方式的微调。我们的目标是学习一个通用的语言标示,可以经过很小的调整就应用在各种任务中。这个模型的设置不需要目标任务和非标注的数据集在同一个领域。模型有两个过程。
- 使用语言模型学习一个深度模型
- 随后,使用相应的监督目标将这些参数调整到目标任务
3. OpenAI GPT模型结构
3.1 非监督预训练
处理非监督文本(𝑥1,𝑥2,...,𝑥𝑚)的普通方法是用语言模型去最大化语言模型的极大似然。
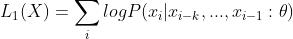
文章中使用的是多层Transformer的decoder的语言模型,还是多个训练单词预测序列中的下一个单词。这个多层的结构应用multi-headed self-attention在处理输入的文本加上位置信息的前馈网络,输出是词的概念分布。


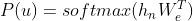
3.2 监督微调fine-tuning
这个阶段要对前一个阶段模型的参数,根据监督任务进行调整。我们假设有标签数据集𝐶,里面的结构是(𝑥1,𝑥2,...,𝑥𝑚,𝑦)。输入(𝑥1,𝑥2,...,𝑥𝑚)经过我们预训练的模型获得输出向量ℎ𝑚𝑙,然后经过线性层和softmax来预测标签。

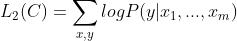
我们增加了语言模型去辅助微调,提高了监督模型的结果。最后的损失函数可以标示为
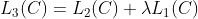
模型结构如下:
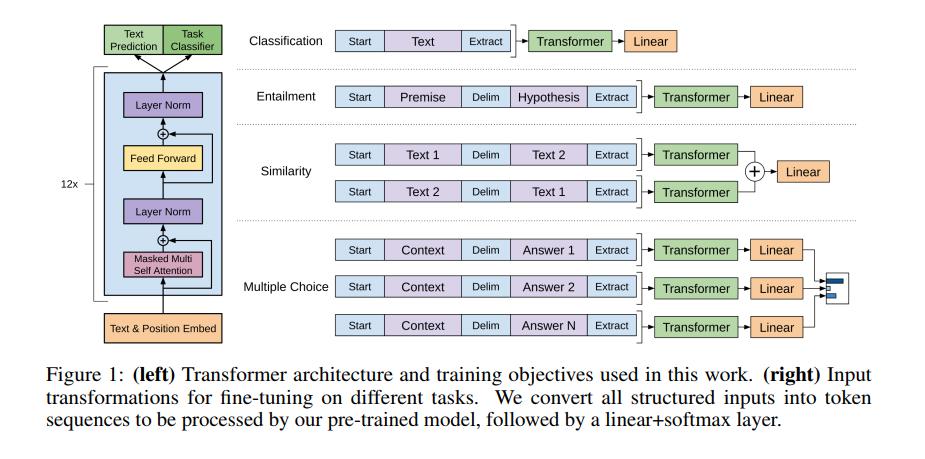
3.3 特殊任务的输入变换
对于有些任务,像文本分类,我们能够直接用上文的模型进行微调。另外的任务,问答系统,需要构造输入的句子对,或者三个文档。由于我们的预训练模型需要连续的文本序列,我们需要改变这种多句文本的输入。
- 文本含义:用$链接前后两个文本
- 相似度:对于相似度的问题,由于没有文本内部的先后顺序。我们可以有两个输入𝑇𝑒𝑥𝑡1$𝑇𝑒𝑥𝑡2和𝑇𝑒𝑥𝑡2$𝑇𝑒𝑥𝑡1,输出的表示向量在加起来。
- 问答系统:有𝐶𝑜𝑛𝑡𝑒𝑥𝑡和𝐴𝑛𝑠𝑤𝑒𝑟1,...,𝐴𝑛𝑠𝑤𝑒𝑟𝑁,我们可以组合成𝑁个𝐶𝑜𝑛𝑡𝑒𝑥𝑡$𝐴𝑛𝑠𝑤𝑒𝑟𝑖输入,获得N个输出,在通过linear后softmax出概率分布。
4. 总结
论文中介绍了一通过预训练学习和有针对性的微调的个强有力的框架。通过预训练是不同的长文本连续的数据集,模型能够有能力去处理长而广的依赖关系,这个是解决问答系统、语义相似度、文本分类中的关键点。
以上是关于系统学习NLP(二十八)--GPT的主要内容,如果未能解决你的问题,请参考以下文章