分布式与并行计算大作业
Posted @阿证1024
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式与并行计算大作业相关的知识,希望对你有一定的参考价值。
一、项目
汽车销售数据分析
二、数据概况:
本数据为上牌汽车的销售数据,分为乘用车辆和商用车辆。数据包含销售相关数据与汽车具体参数。数据项包括:时间、销售地点、邮政编码、车辆类型、车辆型号、制造厂商名称、排量、油耗、功率、发动机型号、燃料种类、车外廓长宽高、轴距、前后车轮、轮胎规格、轮胎数、载客数、所有权、购买人相关信息等。
三、具体要求:
1.统计山西省2013年每个月的汽车销售数量的比例,结果例如:

2.统计不同品牌的车在每个月的销售量分布,结果例如:

四、代码实现
1. 统计山西省2013年每个月的汽车销售数量的比例
(1)核心代码
Mapper:
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class CarSalesMapper extends Mapper<LongWritable, Text, Text, LongWritable>
Text k = new Text();
LongWritable v = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
// 1. 获取一行数据
String line = value.toString();
// 2. 切分数据
String[] values = line.split("\\t");
// 过滤掉异常数据
if (values.length < 11)
return;
// 3. 获取月份
String month = values[1];
// 过滤掉异常数据
try
if(Integer.parseInt(month) < 1 || Integer.parseInt(month) > 12)
return;
catch (Exception e)
return;
// 4. 写出
k.set(month);
context.write(k, v);
Reducer:
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Map;
import java.util.TreeMap;
public class CarSalesReducer extends Reducer<Text, LongWritable, Text, DoubleWritable>
/**
* 统计总的汽车销售数量
*/
double totalNumber = 0;
/**
* 记录月份-->当月的汽车销售数量
*/
Map<String, Long> map = new TreeMap<>();
Text k = new Text();
DoubleWritable v = new DoubleWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException,
InterruptedException
// 记录某月的汽车销售数量
long monthNumber = 0L;
// 1. 统计某月的汽车销售数量
for (LongWritable elem : values)
monthNumber += elem.get();
// 2. 记录当月的汽车销售数量
map.put(key.toString(), monthNumber);
// 3. 统计此时总的汽车销售数量
totalNumber += monthNumber;
@Override
protected void cleanup(Context context) throws IOException, InterruptedException
// 统计每个月的汽车销售数量占汽车销售总数的比例
for (String key : map.keySet())
// 1. 获取当前月份
String month = key;
// 2. 计算比例值
double rate = map.get(key) / totalNumber;
// 3. 写出数据
k.set(month);
v.set(rate);
context.write(k, v);
Driver:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class CarSalesDriver
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException
args = new String[]"填写自己的路径",
"填写自己的路径";
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(CarSalesDriver.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
job.setMapperClass(CarSalesMapper.class);
job.setReducerClass(CarSalesReducer.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
(2)运行结果
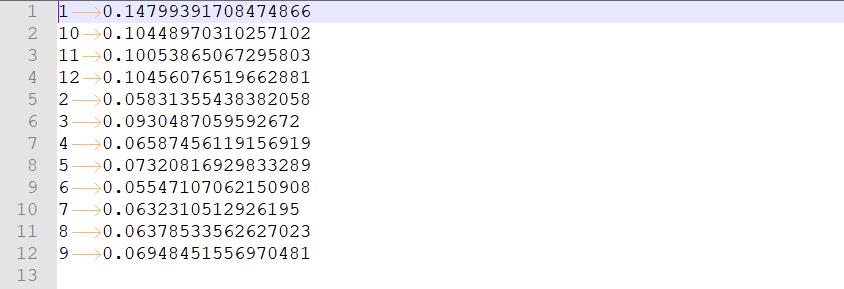
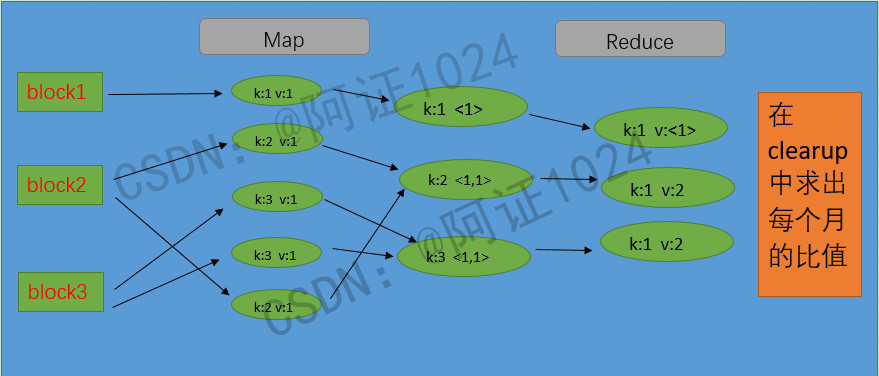
(3)MRJob运行流程图
2. 统计不同品牌的车在每个月的销售量分布
(1)核心代码
Mapper:
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class CarBrandSalesMapper extends Mapper<LongWritable, Text, Text, LongWritable>
Text k = new Text();
LongWritable v = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
// 1. 获取一行数据
String line = value.toString();
// 2. 切分数据
String[] values = line.split("\\t");
// 过滤掉异常数据
if (values.length < 11)
return;
String monthStr = values[1];
// 过滤掉异常数据
try
int month = Integer.parseInt(monthStr);
if(month < 1 || month > 12)
return;
catch (Exception e)
return;
// 3. 设置k, v
k.set(monthStr + "\\t" + values[7]);
// 4. 写出
context.write(k, v);
Reducer:
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class CarBrandSalesReducer extends Reducer<Text, LongWritable, Text, LongWritable>
Text k = new Text();
LongWritable v = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException
// 记录销量总和
long carSales = 0;
// 1. 统计销量
for(LongWritable elem : values)
carSales += elem.get();
// 2. 设置k, v
k.set(key);
v.set(carSales);
// 3. 写出
context.write(k, v);
Driver:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class CarBrandSalesDirver
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException
args = new String[]"填写自己的路径",
"填写自己的路径";
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(CarSalesDriver.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setMapperClass(CarBrandSalesMapper.class);
job.setReducerClass(CarBrandSalesReducer.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
(2)运行结果
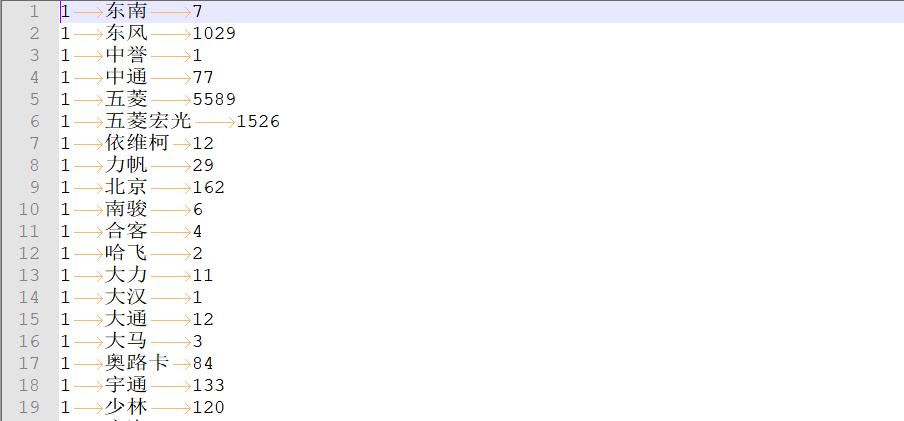
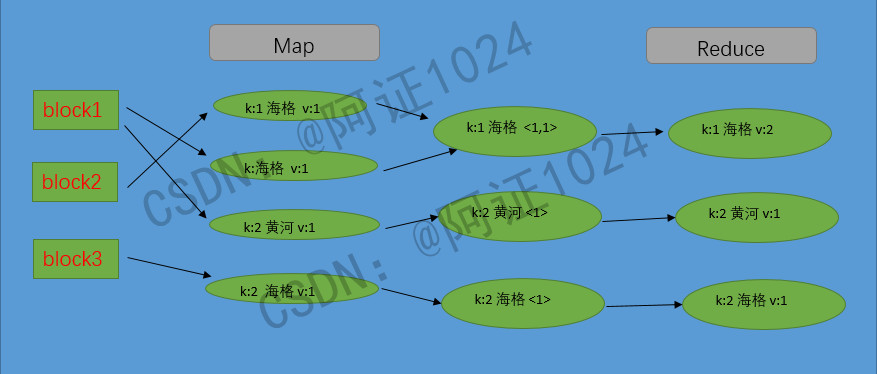
(3)MRJob运行流程图
到此大作业完成,有什么问题私信我,关注可领取电子版报告书及相关数据集。
以上是关于分布式与并行计算大作业的主要内容,如果未能解决你的问题,请参考以下文章