Hadoop大数据平台
Posted S4061222
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop大数据平台相关的知识,希望对你有一定的参考价值。
目录
操作参考手册:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
一. Hadoop简介
1 hadoop的演变
Hadoop起源于Google的三大论文:
- GFS:Google的分布式文件系统Google File System
- MapReduce:Google的MapReduce开源分布式并行计算框架
- BigTable:一个大型的分布式数据库
演变关系:
GFS—->HDFS
Google MapReduce—->Hadoop MapReduce
BigTable—->HBase
Hadoop名字不是一个缩写,是Hadoop之父Doug Cutting儿子毛绒玩具象命名的
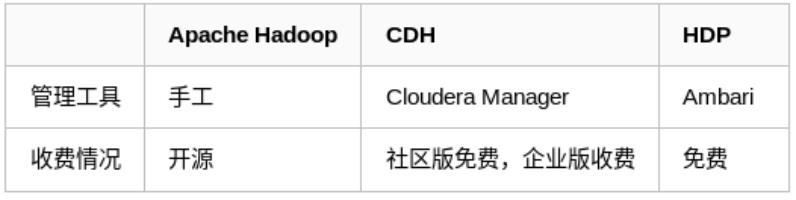
hadoop主流版本:
- Apache基金会hadoop
- Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称“CDH”)
- Hortonworks版本(Hortonworks Data Platform,简称“HDP”)
Hadoop的框架最核心的设计就是:HDFS和MapReduce。
- HDFS为海量的数据提供了存储。
- MapReduce为海量的数据提供了计算。
Hadoop框架包括以下四个模块:
Hadoop Common: 这些是其他Hadoop模块所需的Java库和实用程序。这些库提供文件系统和操作系统级抽象,并包含启动Hadoop所需的Java文件和脚本。Hadoop YARN: 这是一个用于作业调度和集群资源管理的框架。Hadoop Distributed File System (HDFS): 分布式文件系统,提供对应用程序数据的高吞吐量访问。Hadoop MapReduce:这是基于YARN的用于并行处理大数据集的系统。
hadoop应用场景:
- 在线旅游
- 移动数据
- 电子商务
- 能源开采与节能
- 基础架构管理
- 图像处理
- 诈骗检测
- IT安全
- 医疗保健
2 hadoop的简介
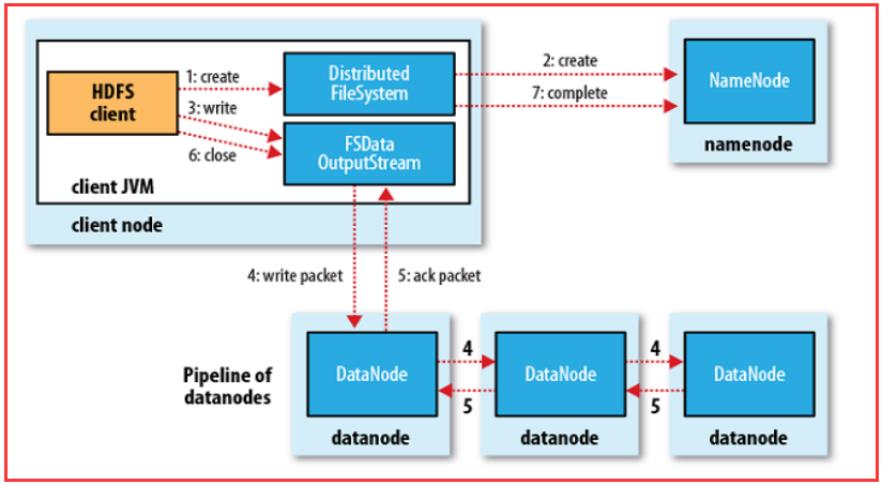
-
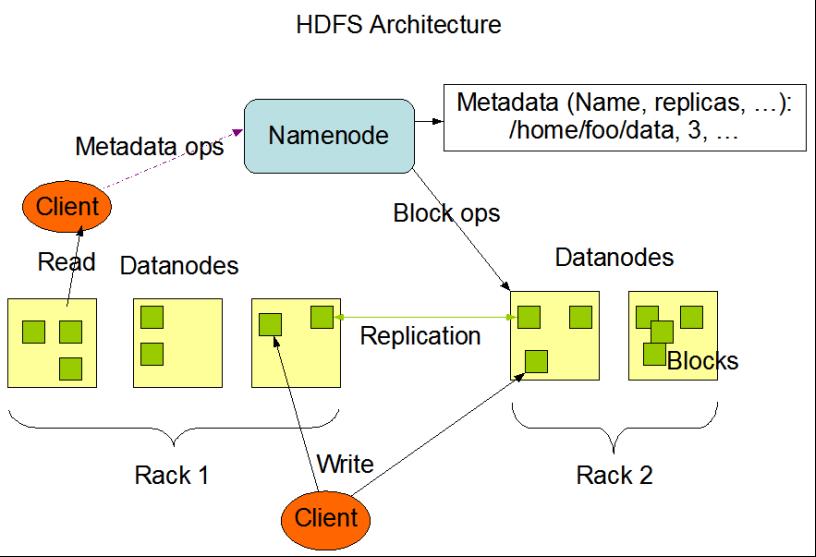
HDFS属于
Master与Slave结构。一个集群中只有一个NameNode,可以有多个DataNode。 -
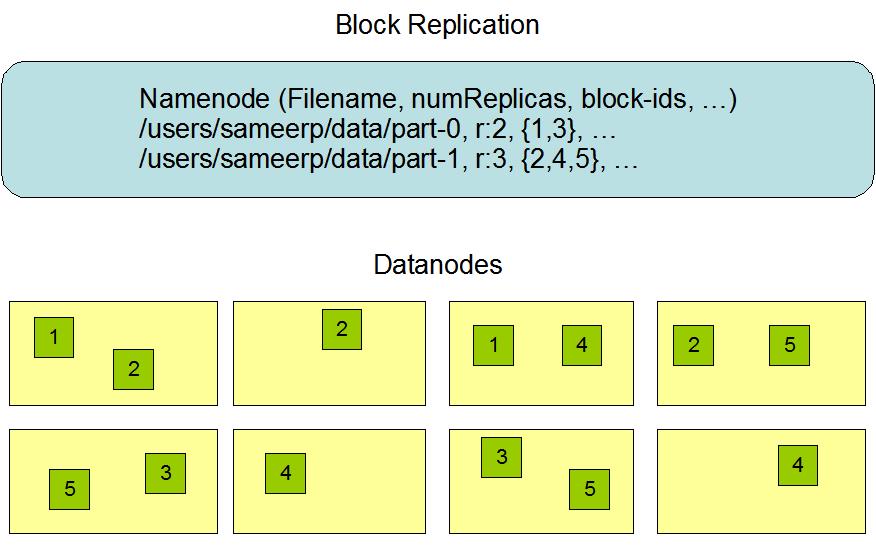
HDFS存储机制保存了多个副本,当写入1T文件时,我们需要3T的存储,3T的网络流量带宽;系统提供容错机制,副本丢失或宕机可自动恢复,保证系统高可用性。
-
HDFS默认会将文件分割成block。然后将block按键值对存储在HDFS上,并将键值对的映射存到内存中。如果小文件太多,会导致内存的负担很重。 -
HDFS采用的是
一次写入多次读取的文件访问模型。一个文件经过创建、写入和关闭之后就不需要改变。这一假设简化了数据一致性问题,并且使高吞吐量的数据访问成为可能。 -
HDFS
存储理念是以最少的钱买最烂的机器并实现最安全、难度高的分布式文件系统(高容错性低成本),HDFS认为机器故障是种常态,所以在设计时充分考虑到单个机器故障,单个磁盘故障,单个文件丢失等情况。 -
HDFS
容错机制:
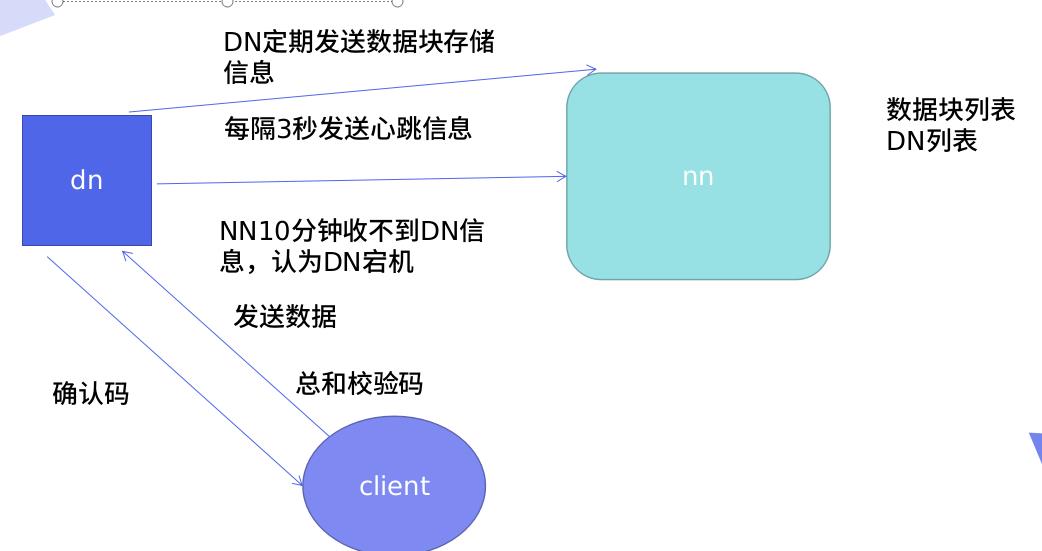
节点失败监测机制:DN每隔3秒向NN发送心跳信号,10分钟收不到,认为DN宕机。
通信故障监测机制:只要发送了数据,接收方就会返回确认码。
数据错误监测机制:在传输数据时,同时会发送总和校验码。
3 工作原理
Nn和Dn
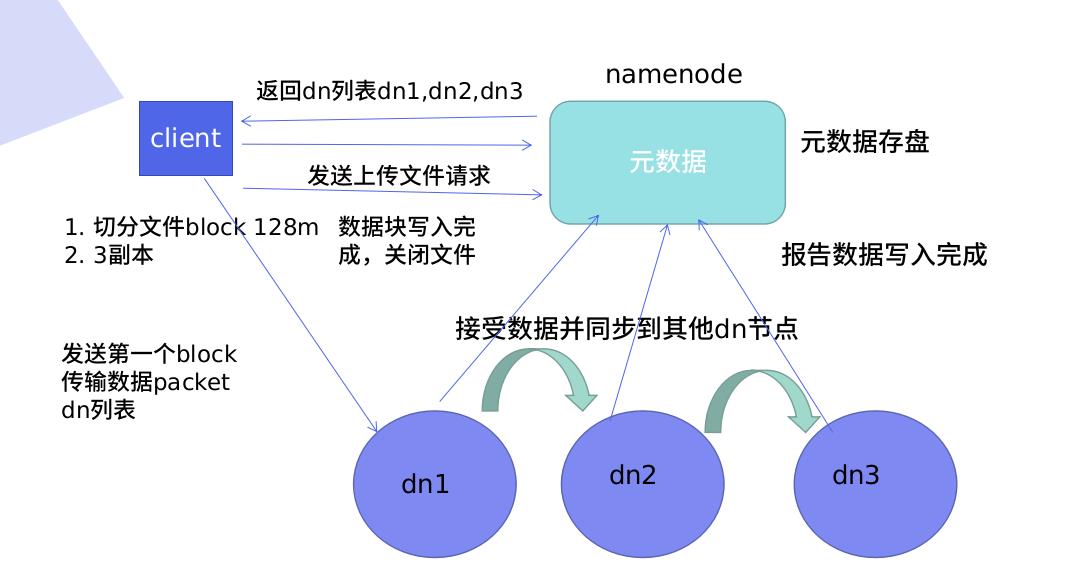
工作原理:
Cliet向Namenode请求,Nn向cl返回Dn列表(Dn列表有顺序,校验数据的距离,根据距离排序),Nn知道所有节点的状态,Cl知道会以多大的block切分,设定副本数,Cl连接dn列表,(发送第一个block传输数据packet和dn列表),Nn接收block并保存dn列表数据,同步其他Dn节点(边接收边同步),Dn报告Block存储完成。
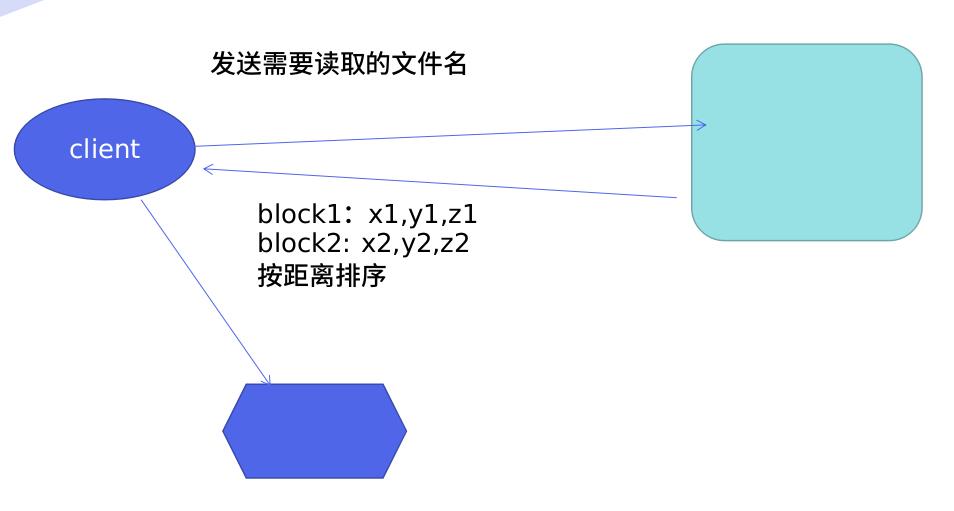
返回Dn列表顺序
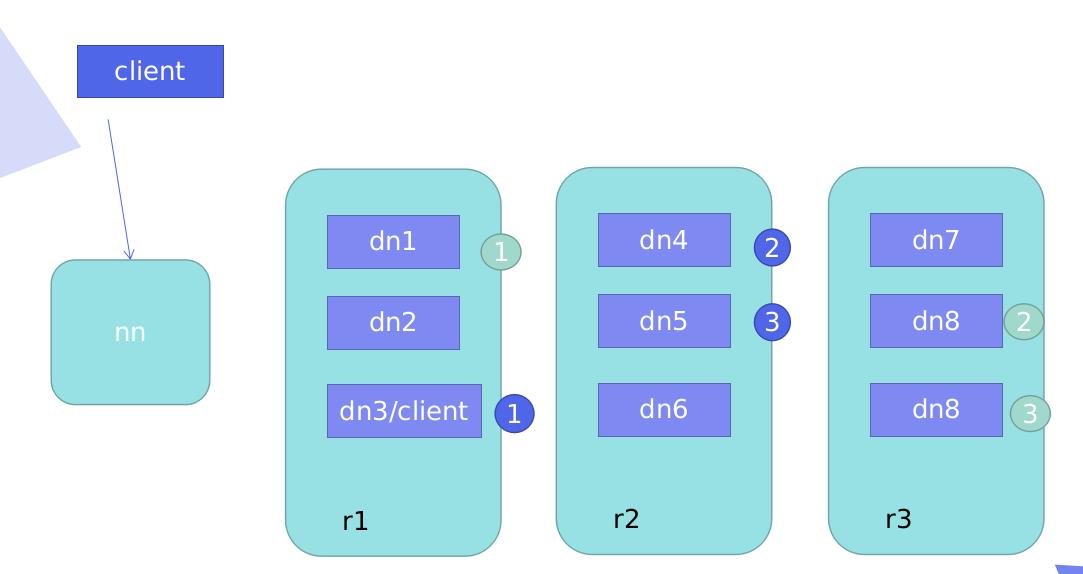
-
Cl和Dn节点在同一台机器,存储副本(默认3个),Nn返回的Dn列表顺序:本机–不同机架的不同Dn上----同机架的不同Dn上(down后,找本机架其他的Dn)其他的随机,只是控制前3 -
Cl和Dn节点不在同一台机器:第一个副本随机,2,3副本一样
hdfs中文漫画:https://blog.csdn.net/lsziri/article/details/102503486
节点故障/网络故障/数据块损坏
RM:resourcemanager
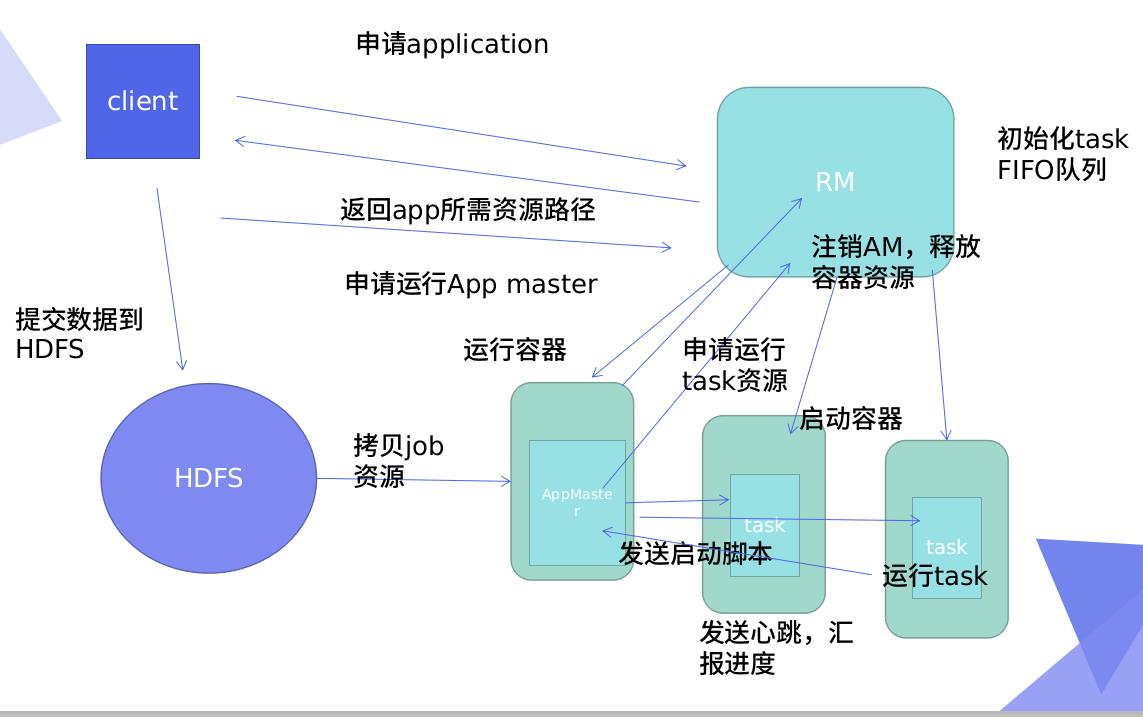
v1: jobTrack,不能过2000节点
v2:过2000节点
工作原理:
Cl向RM申请,任务队列,RM返回app所需资源路径,Cl需要的资源数据存储到HDFS,Cl申请运行App master,RM运行容器(分配资源)AM,AM拷贝HDFS中的job资源,AM向RM申请运行资源,RM会分配到下面的多个task中,实时汇总AM,AM持续监控job
完成任务后,申请释放资源,RM注销AM,释放容器资源
二. hadoop工作模式
1 伪分布式
实验环境:
| 主机名 | ip |
|---|---|
| vm1 | 172.25.28.11(2G) |
Nn和Dn不分离:
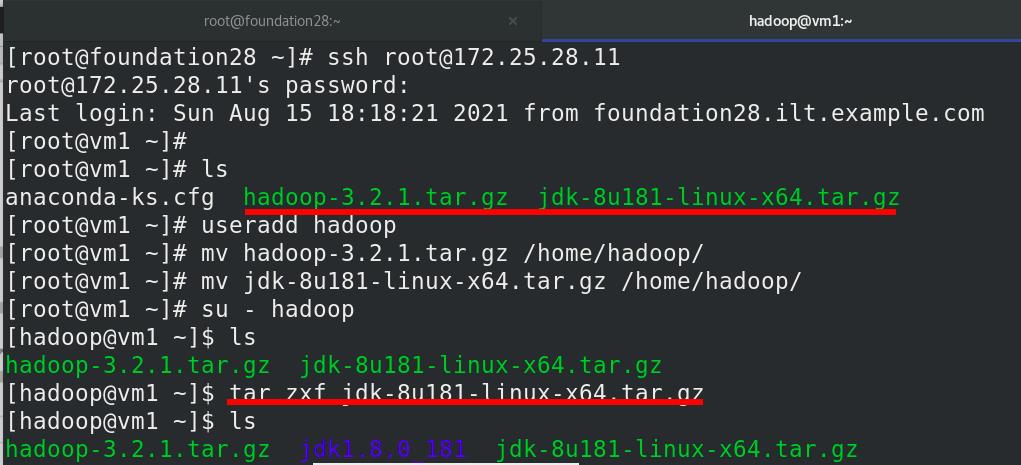
hadoop安装有jdk要求,不用rpm包,使用源码tar.gz,
建立hadoop用户,解压缩jdk包,普通用户hadoop运行
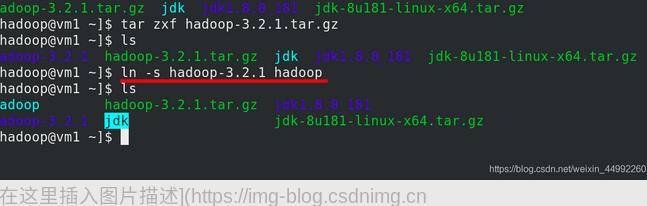
hadoop和java作软链接,方便更新版本

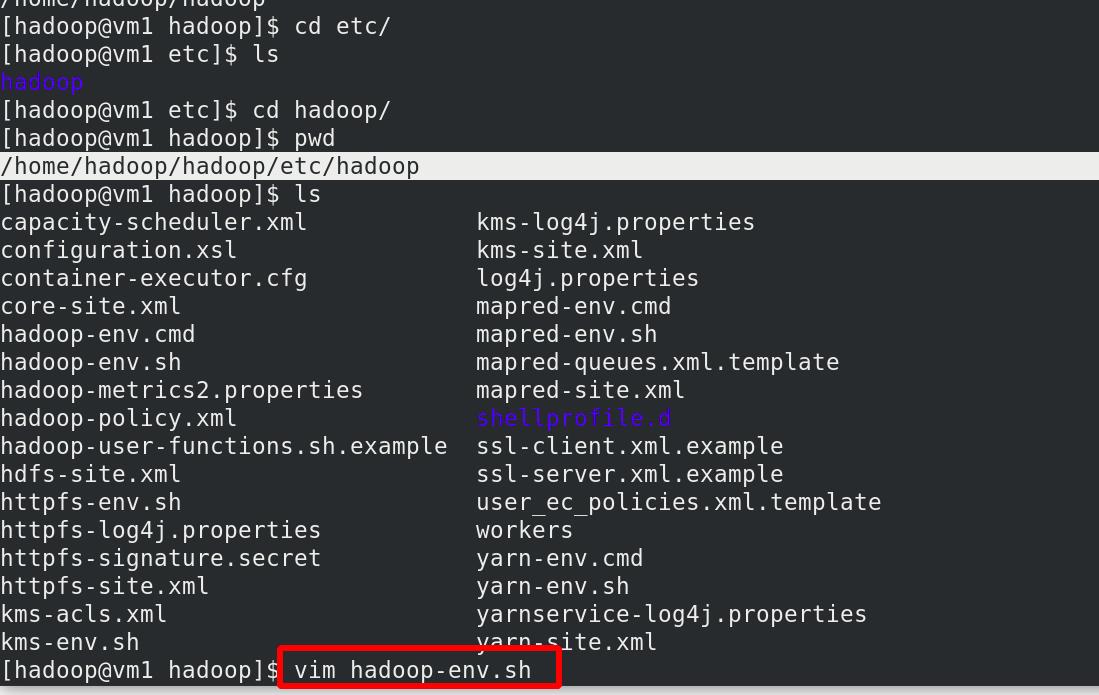
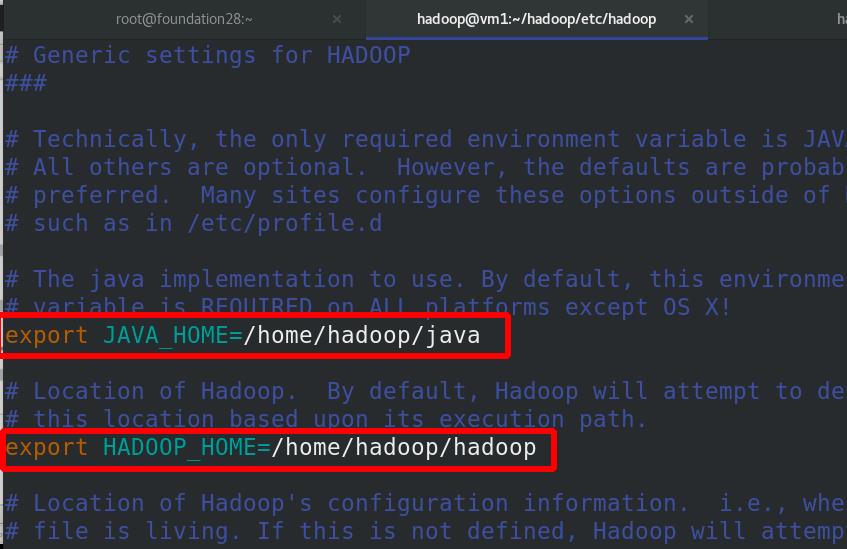
编辑文件,修改java和hadoop的环境变量
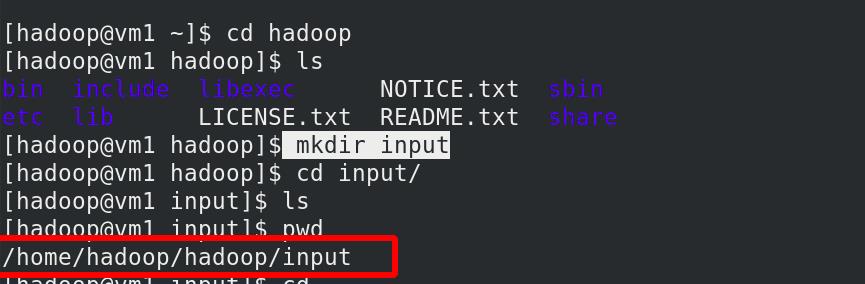
新建input目录
将etc/hadoop中.xml 文件复制到input目录
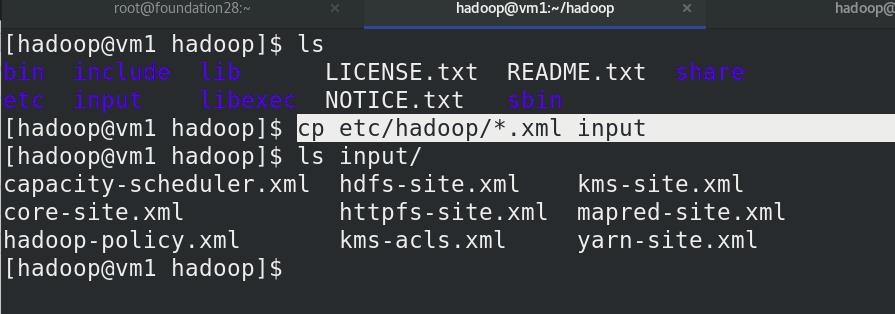
Hadoop 配置为在非分布式模式下作为单个 Java 进程运行,查找并显示给定正则表达式的每个匹配项。 输出写入给定的输出目录 output,outpot不用创建,过滤dfs的关键字。
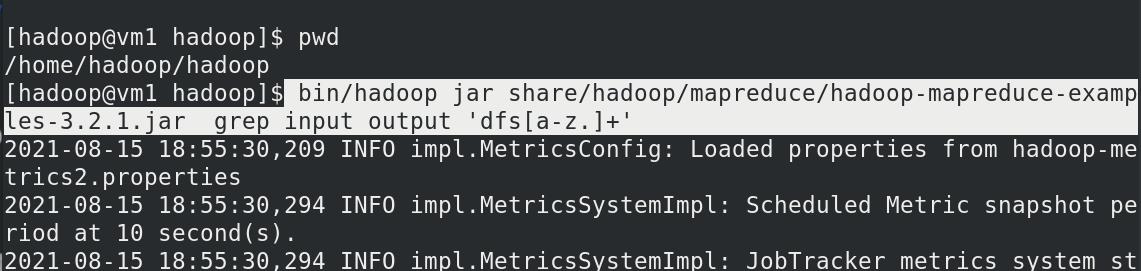
查看output目录中的内容
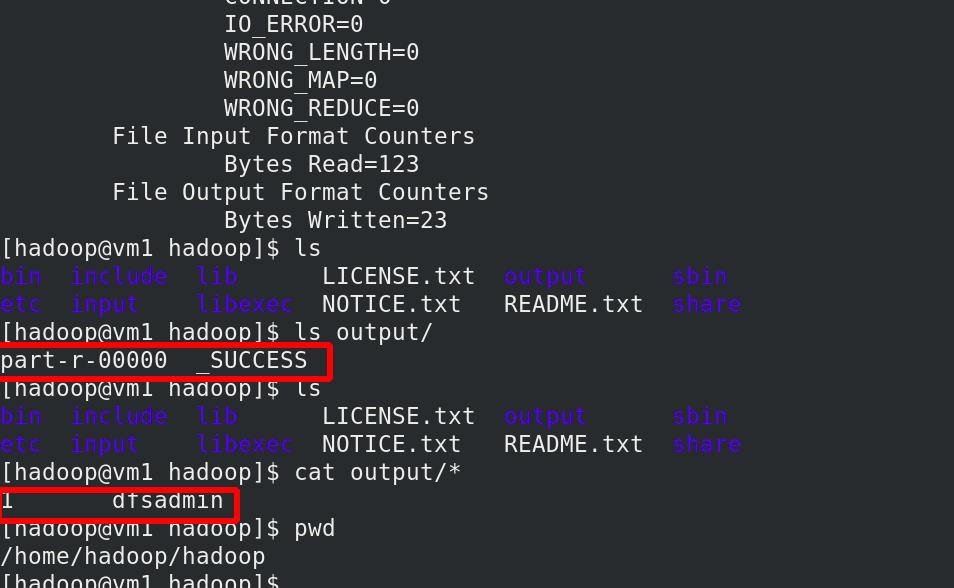
Hadoop 也可以以伪分布式模式在单节点上运行,其中每个 Hadoop 守护进程在单独的 Java 进程中运行。
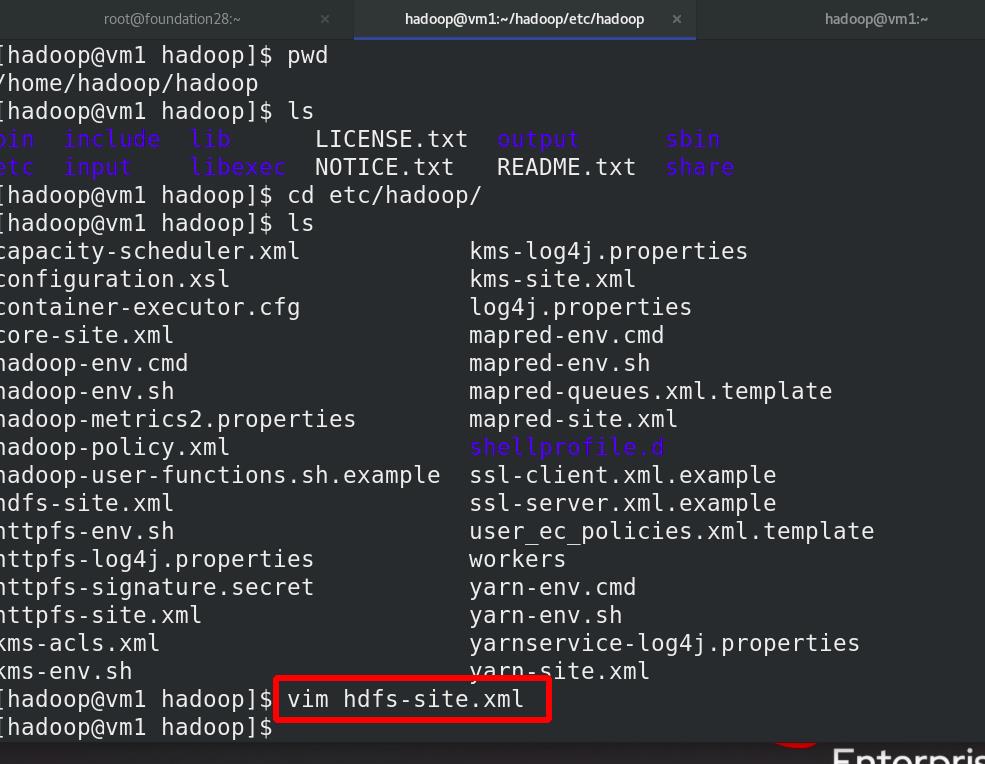
编辑 etc/hadoop/hdfs-site.xml 文件,副本数为1
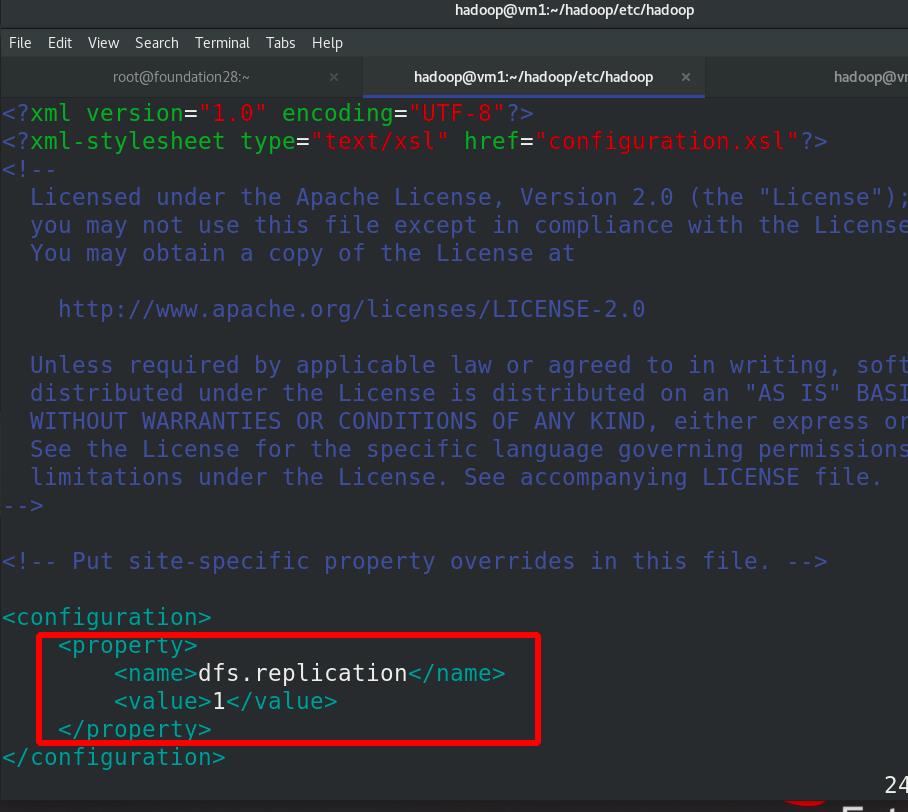
编辑etc/hadoop/core-site.xml 文件,分布式文件系统的master,主从都是自己
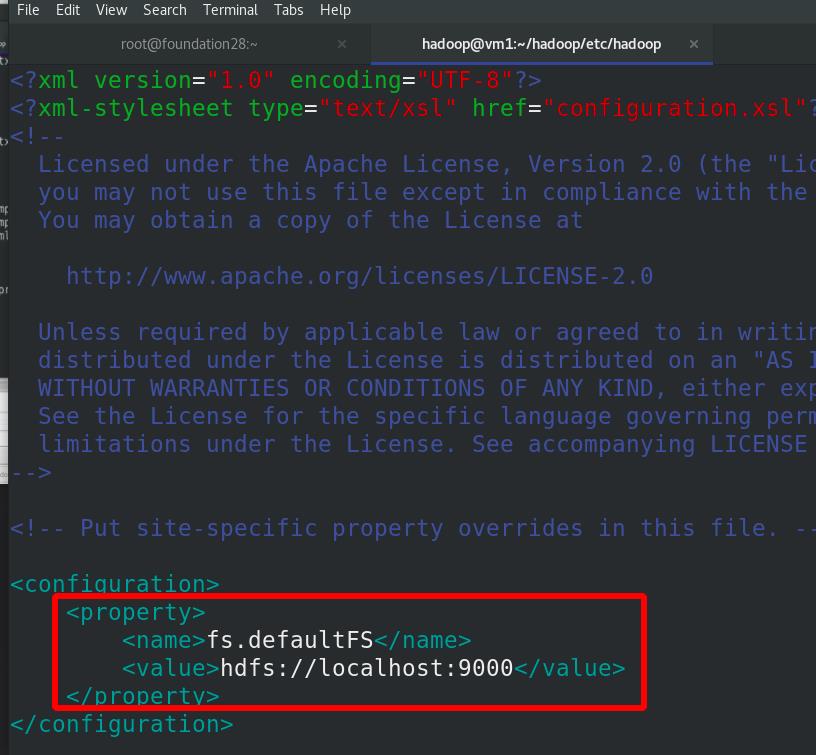
master和worker都是自己!!!
与localhost进行ssh免密
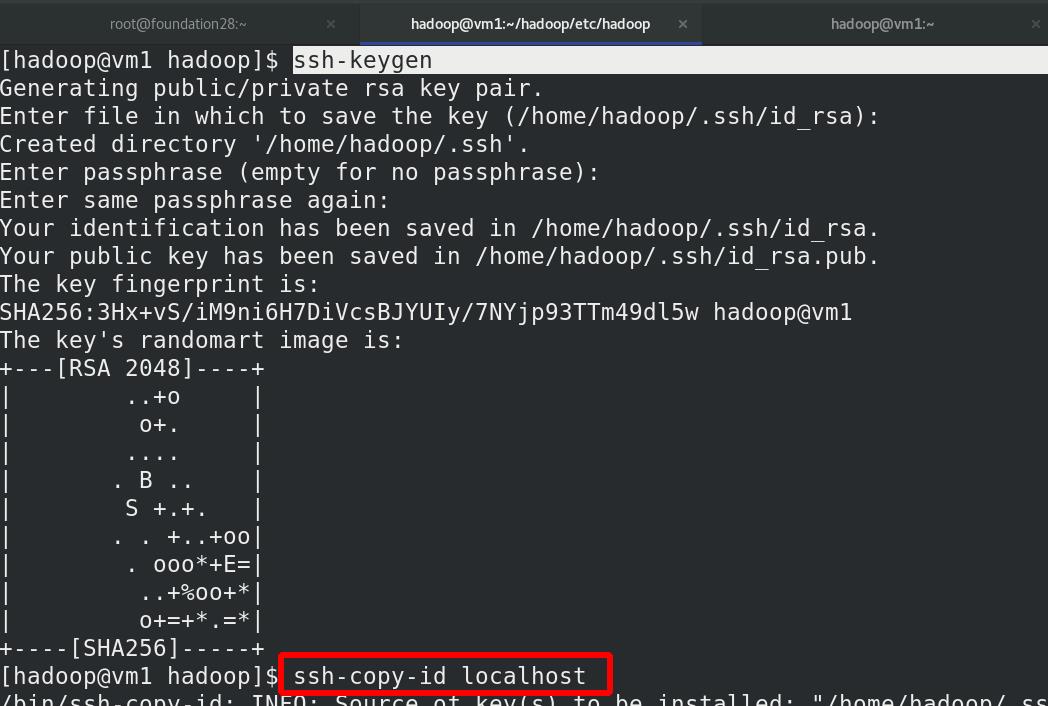
与localhost免密测试
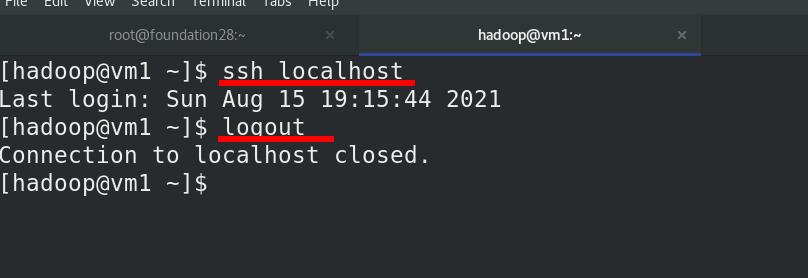
查看生成的公钥和私钥
本地运行 MapReduce 作业
初始化文件系统
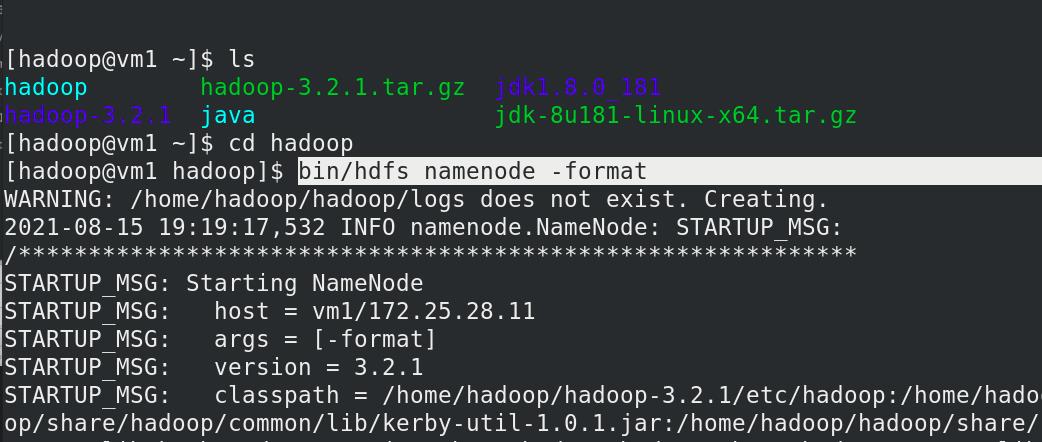
启动 NameNode 守护进程和 DataNode 守护进程
namenode启动master,datanode启动worker
当前master和worker都是本机vm1 !!!
数据存储位置:/tmp
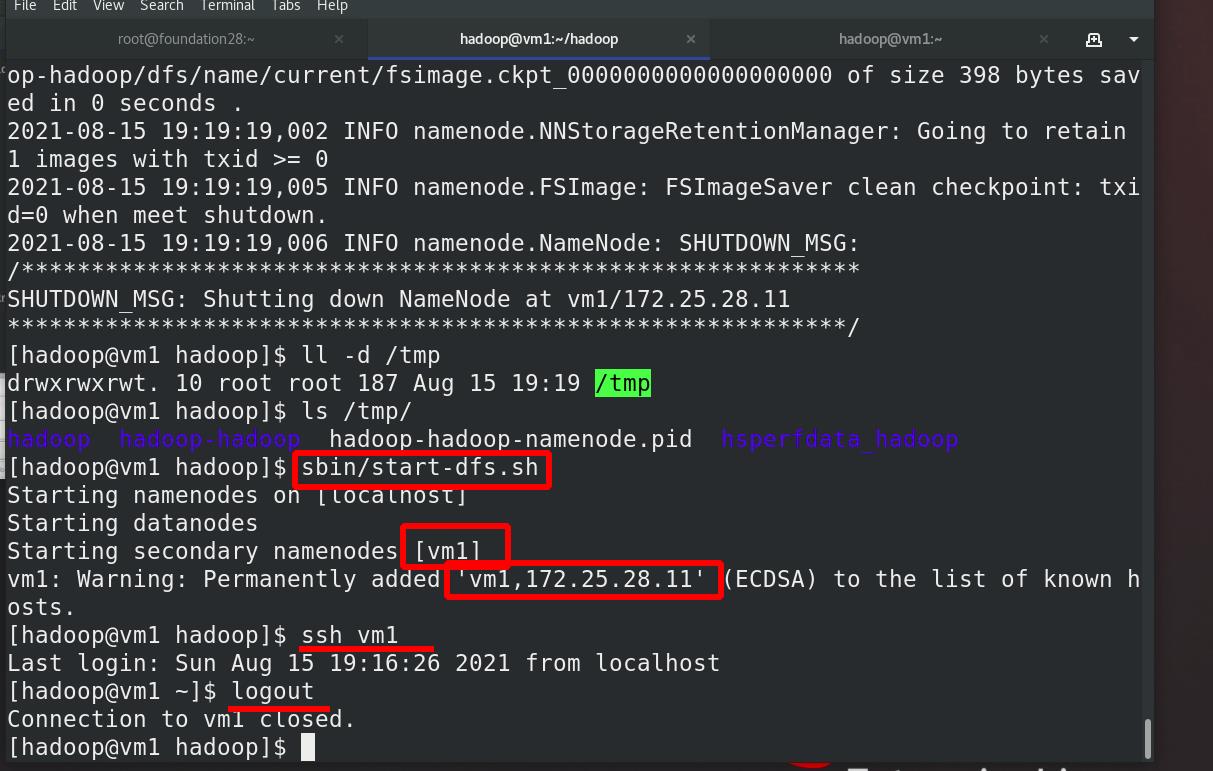
jps:java进程查看,代替ps ax
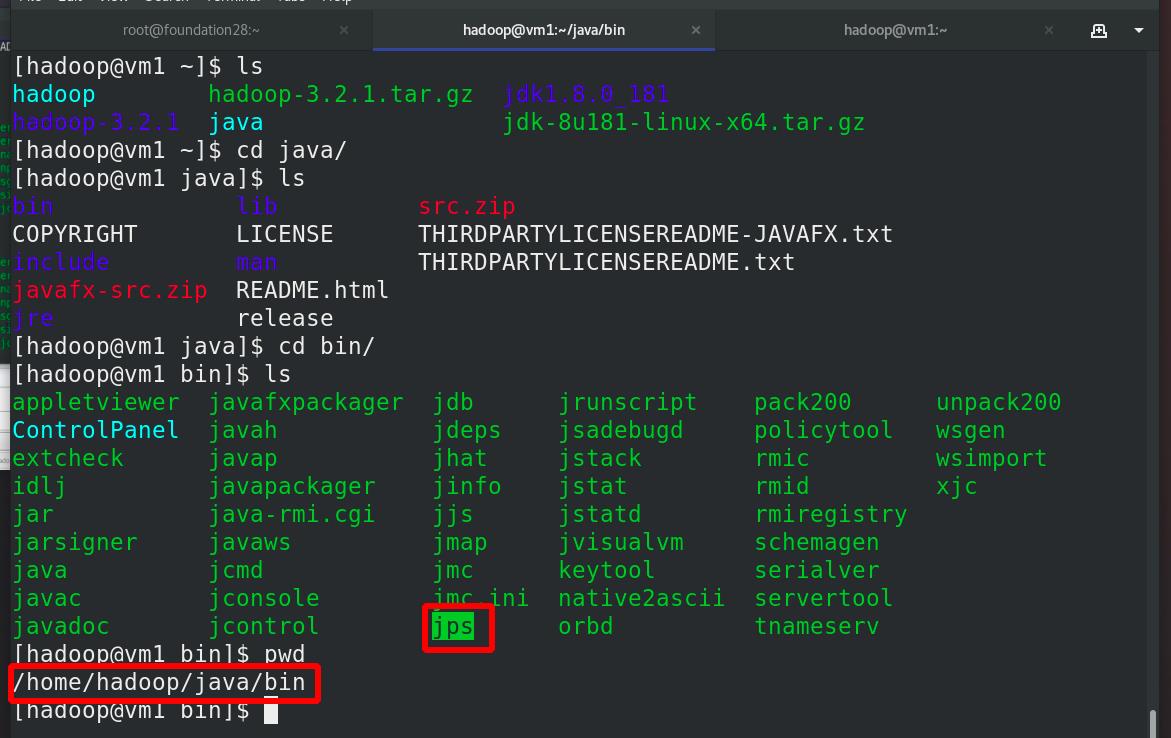
编辑java的环境变量
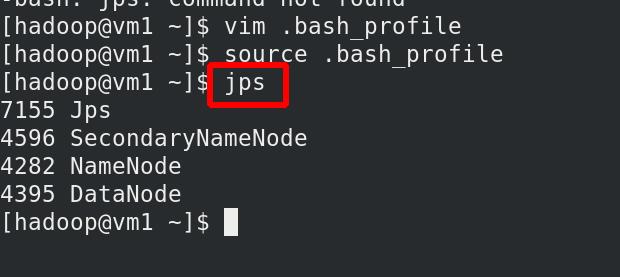
jps查看进程,其中secondnode表示当master的namenode down掉后,接管
由于hadoop的master和worker都是vm1,所以同时出现Namenode和DataNode !!!
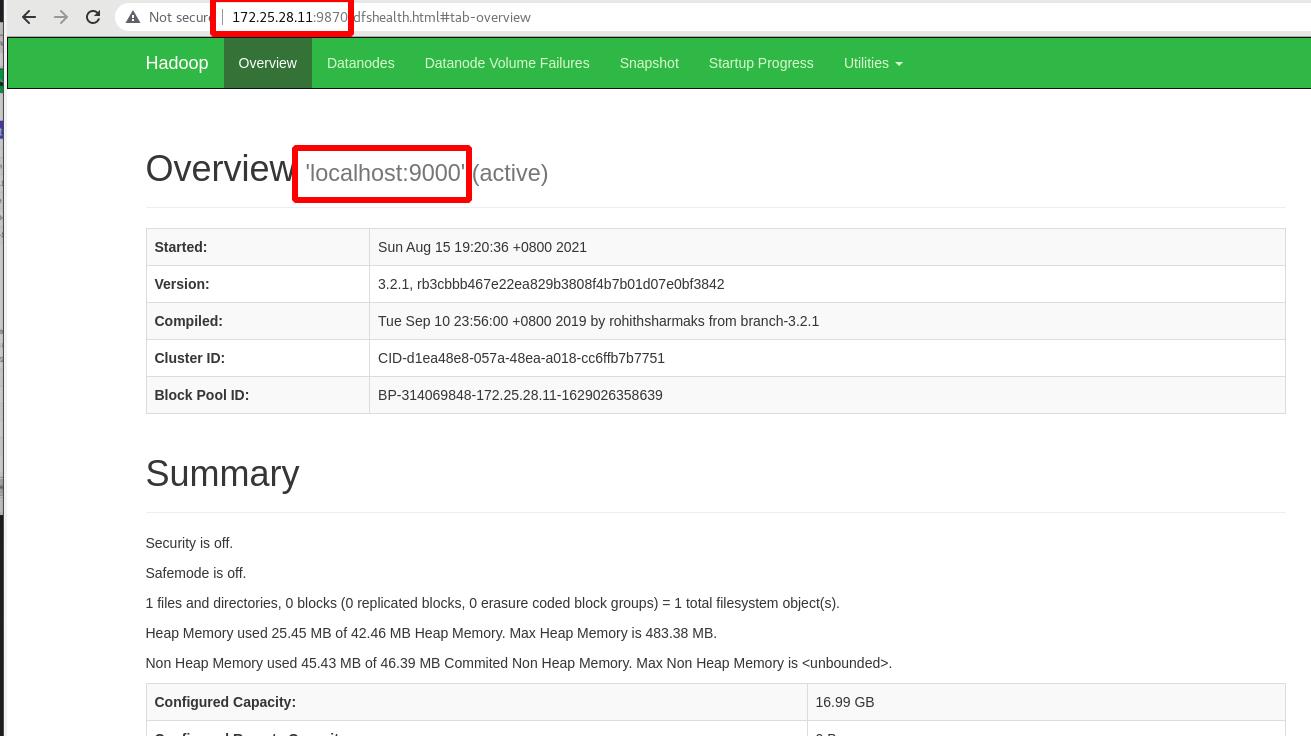
外部访问:
172.25.28.11:9870
9870:hadoop默认的监听端口
9000:Namenode和Datanode的连接端口
查看日志:
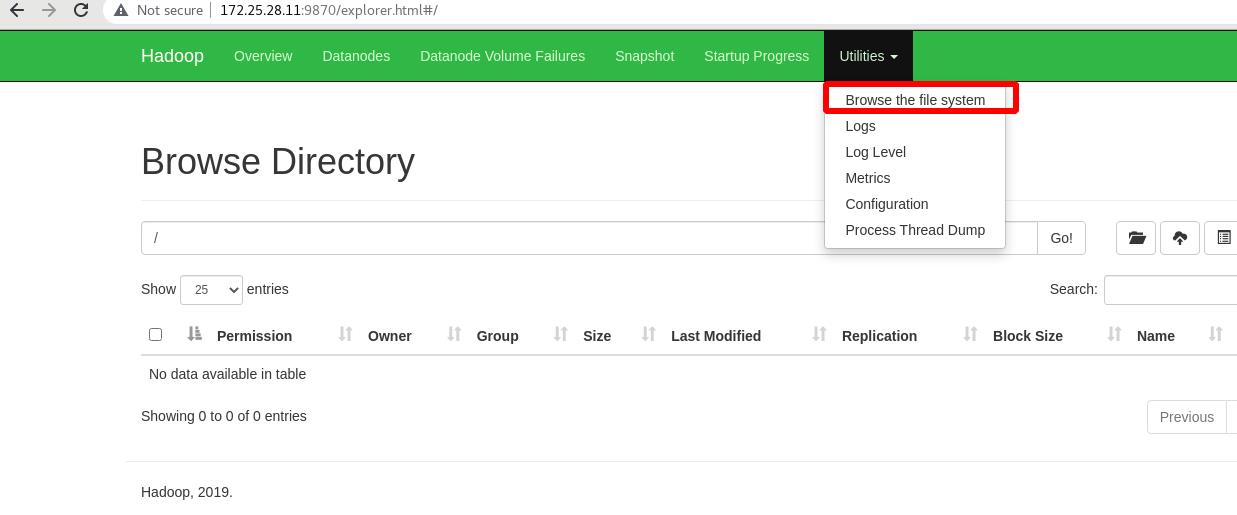
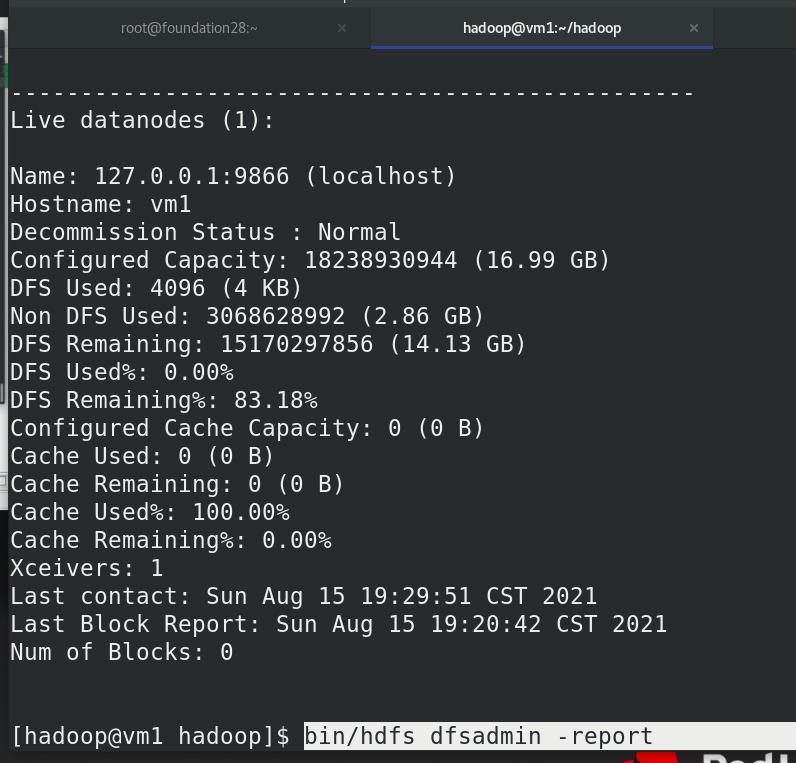
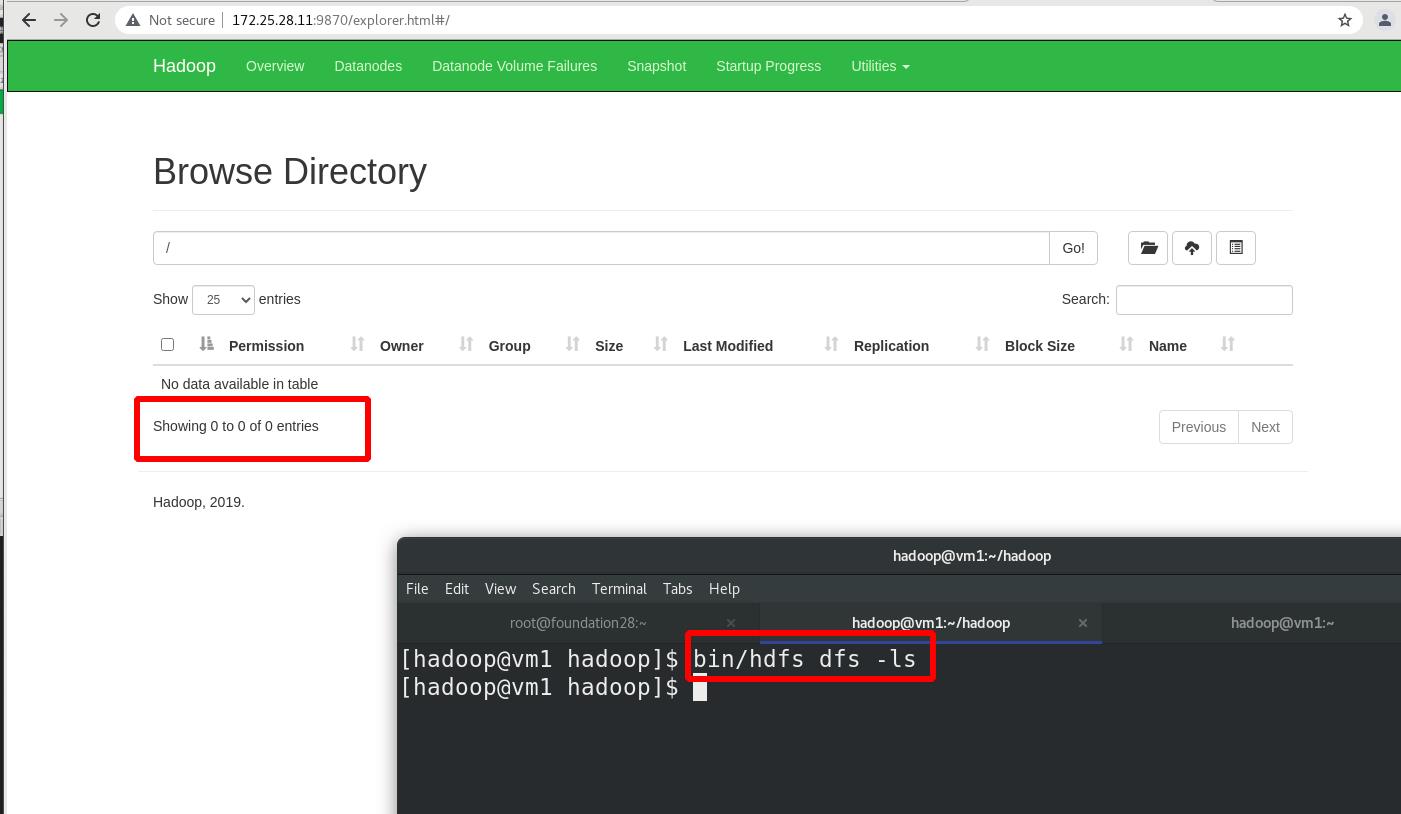
查看文件系统,此时没有内容:
两种方式:命令行和图形化
创建执行 MapReduce 作业所需的 HDFS 目录: 用户与当前id保持一致

ls 默认查看的是这个目录/user/haddop
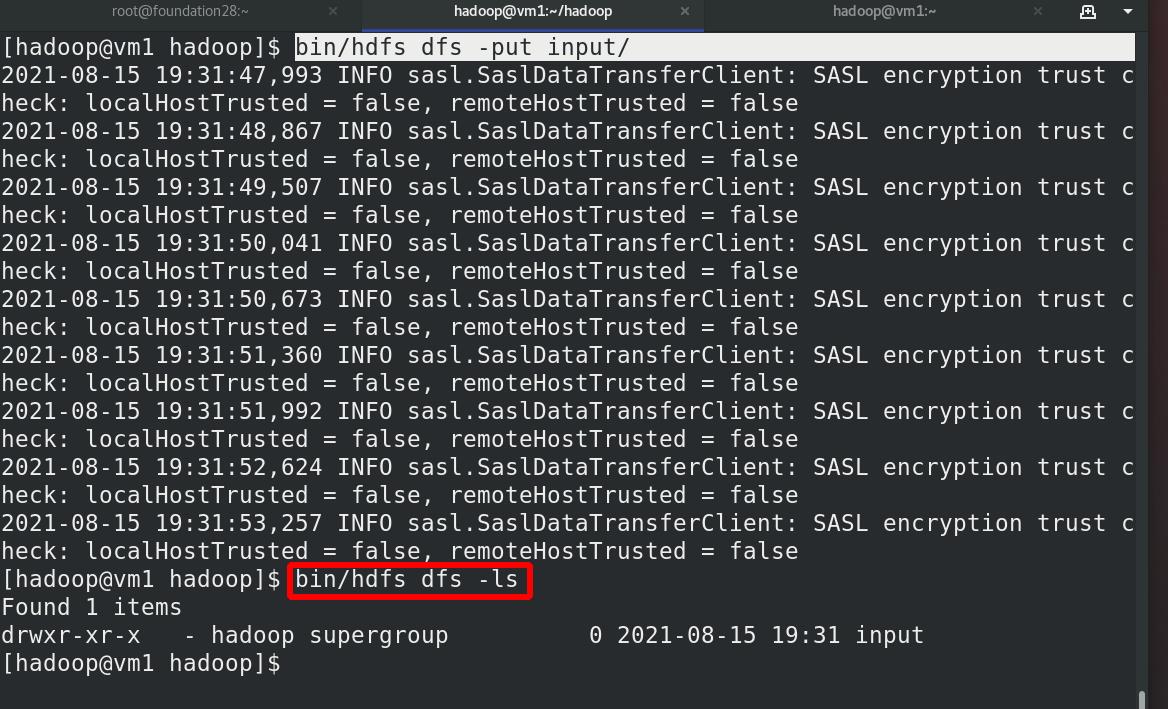
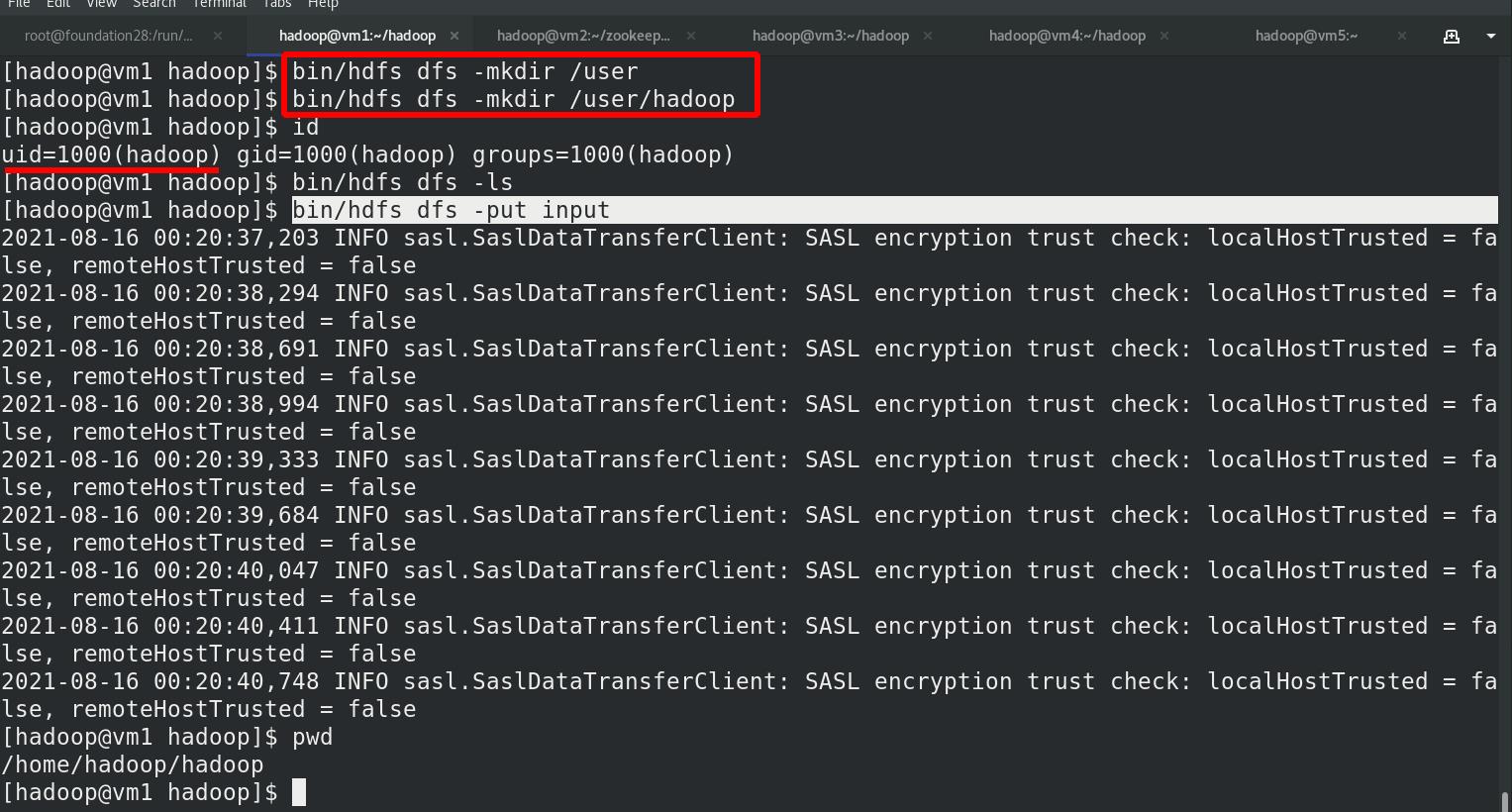
将输入文件复制到分布式文件系统中
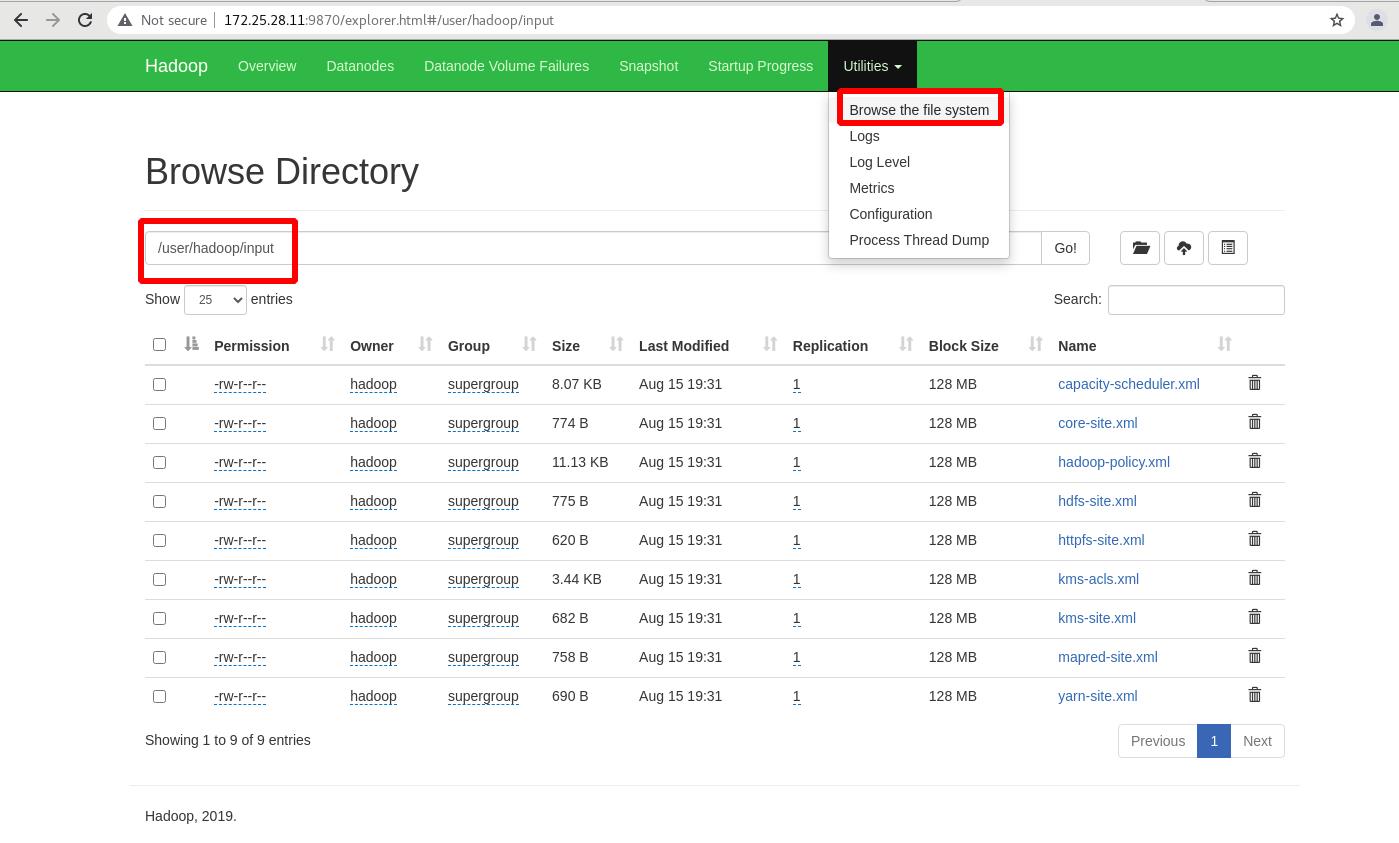
外部查看,存在(图形化)
本地查看(命令行)

单词数,
input,output :和本地无关,分布式中的输入输出目录
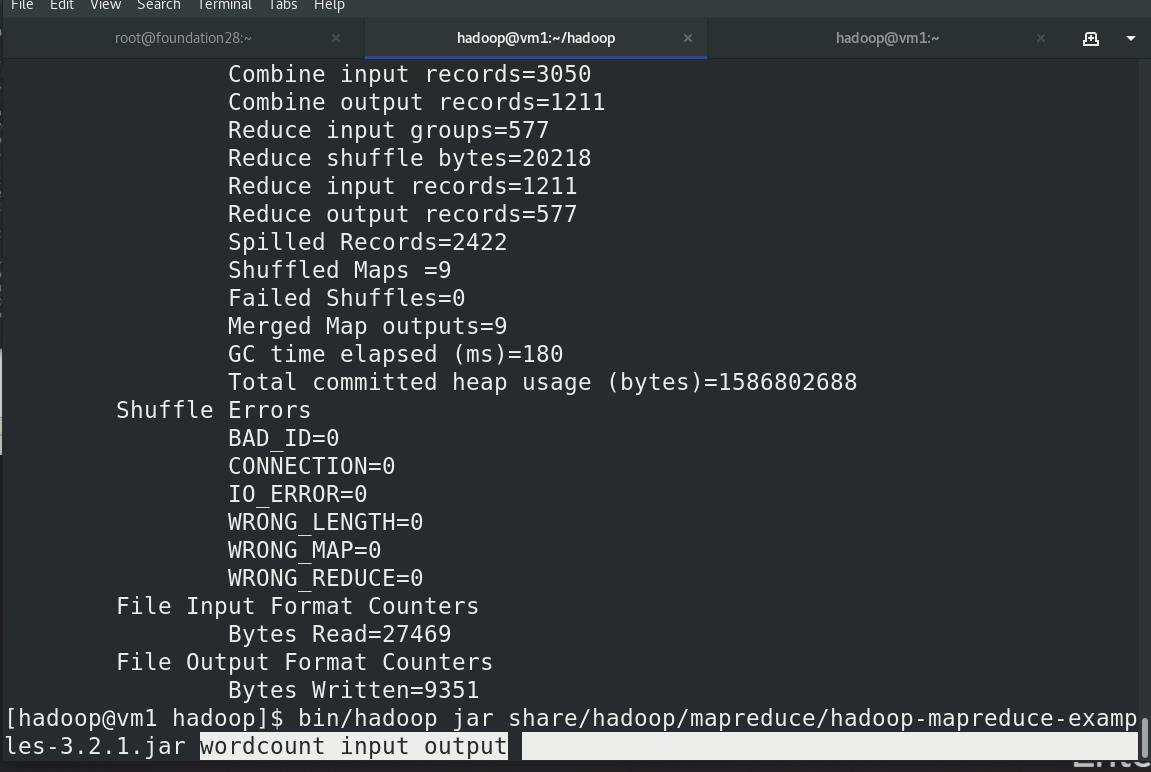
本地查看
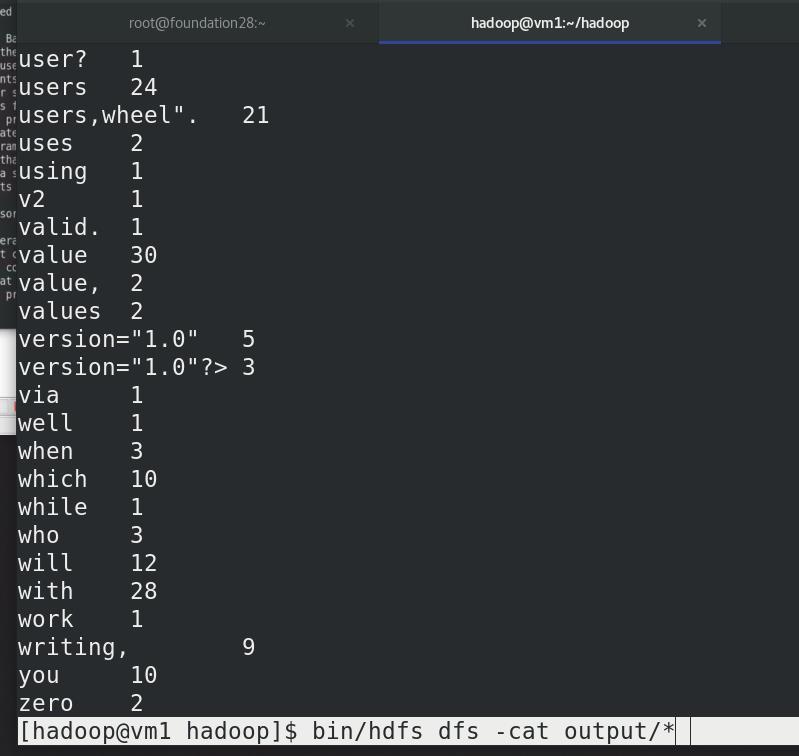
本地删除

此时查看,是分布式中的输入输出目录
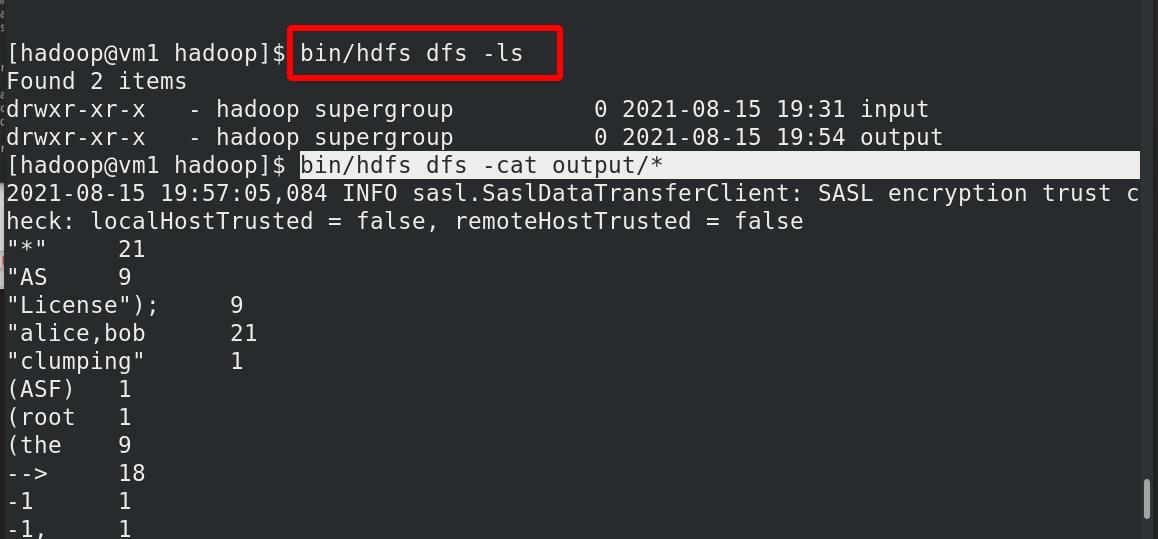
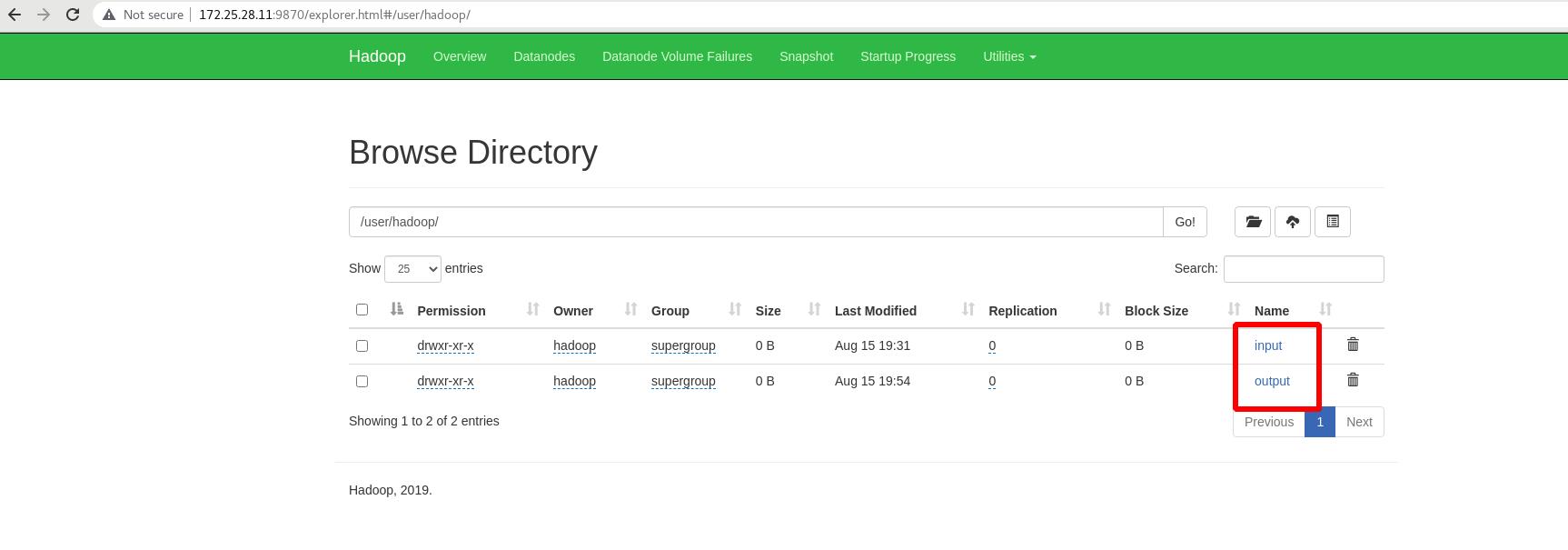
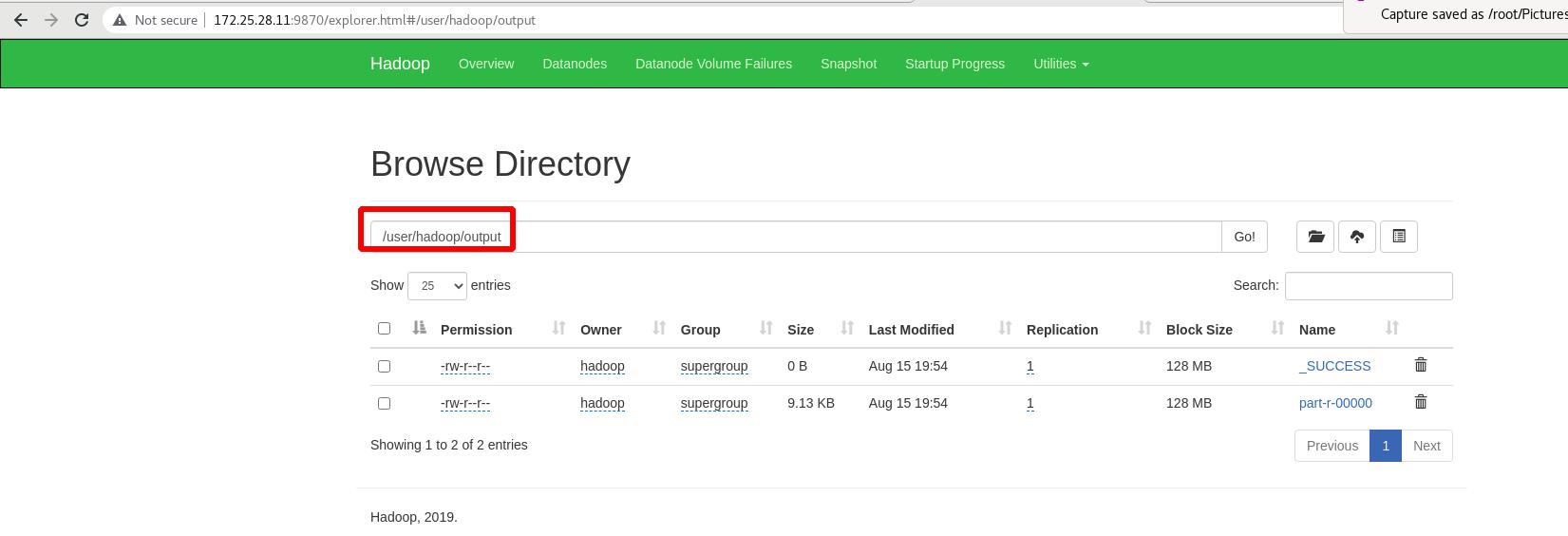
重新获取分布式中的输出目录
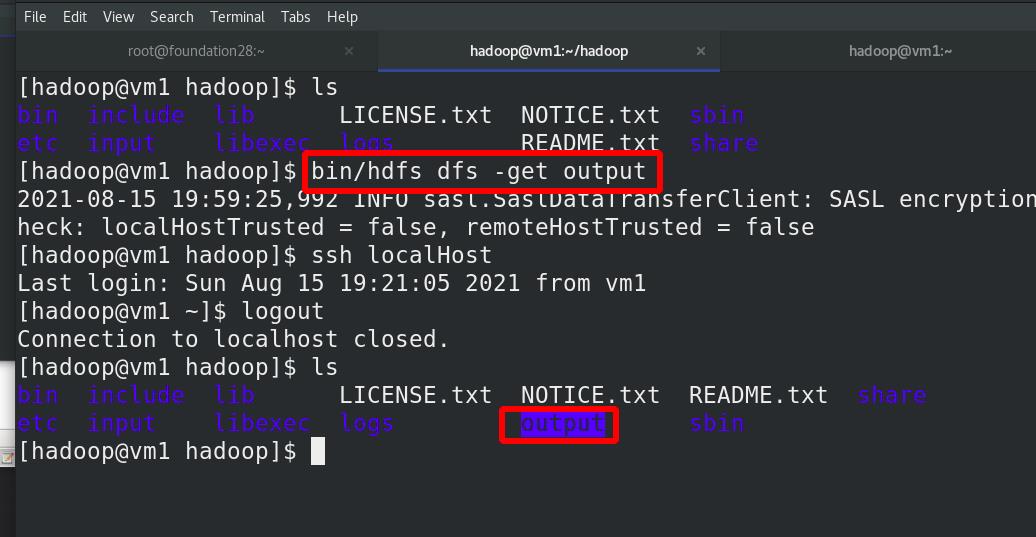
本地查看成功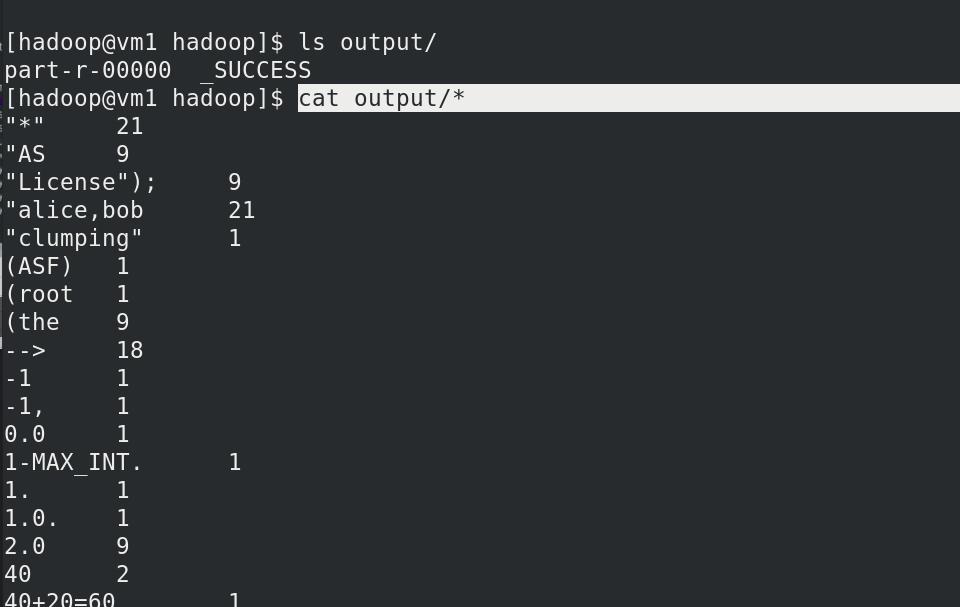
2 完全分布式
3台虚拟机
实验环境:
| 主机名 | ip | 功能 |
|---|---|---|
| vm1 | 172.25.28.11(2G) | master |
| vm2 | 172.25.28.12 | worker |
| vm3 | 172.25.28.13 | worker |
| vm4 | 172.25.28.14 | worker |
Nn和Dn分离
编辑 etc/hadoop/core-site.xml 文件,修改master为vm1的ip
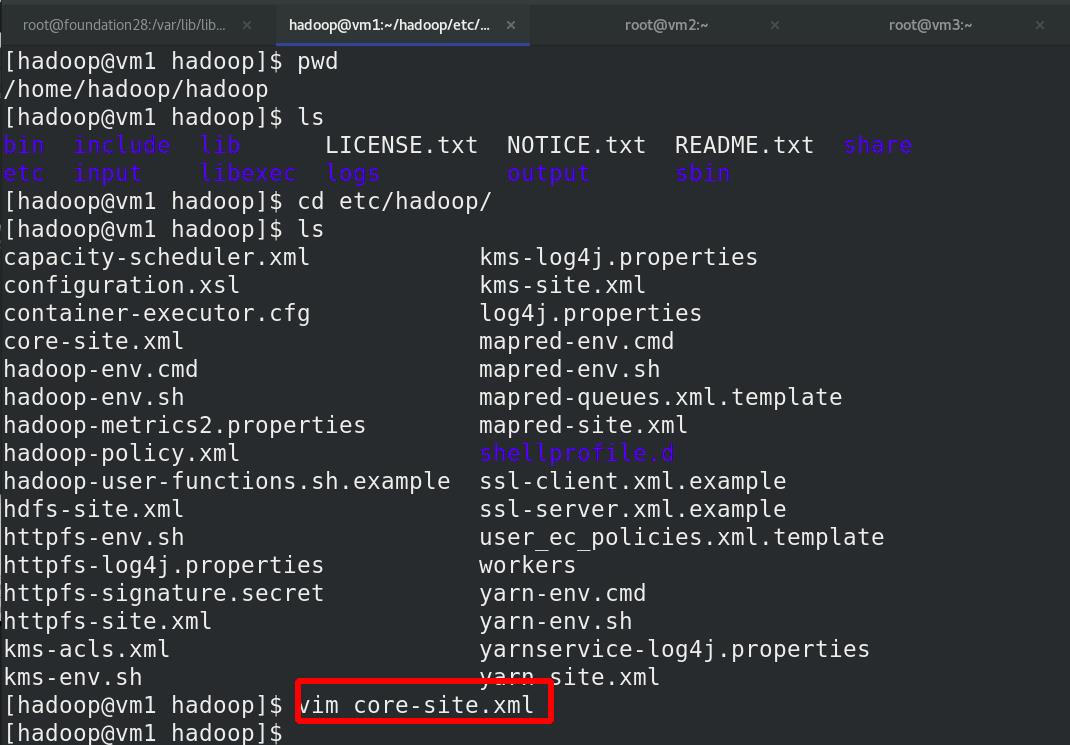
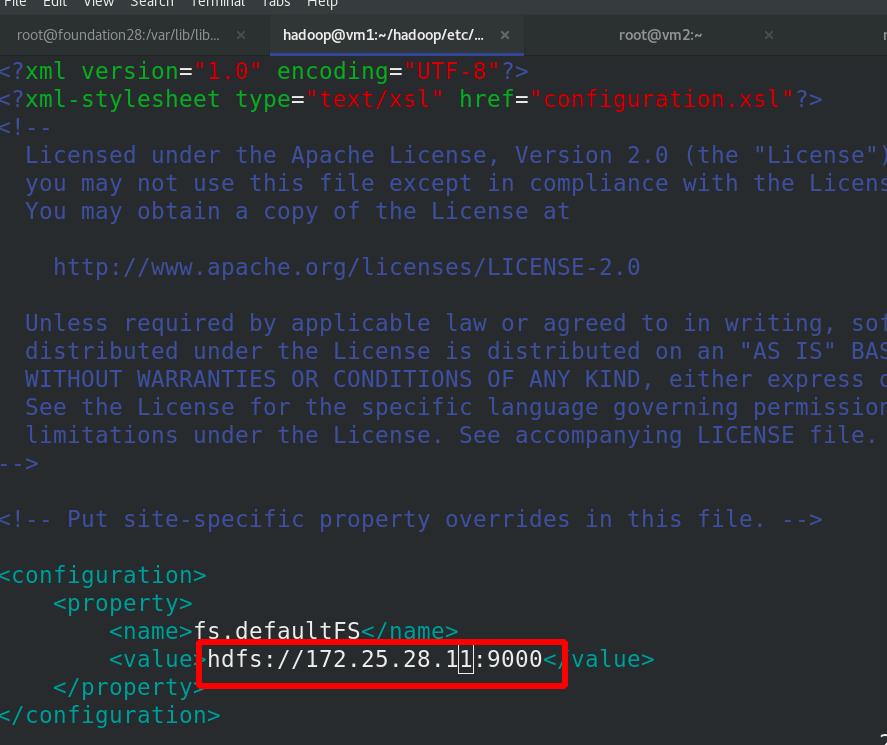
编辑 etc/hadoop/hdfs-site.xml 文件,副本数为2
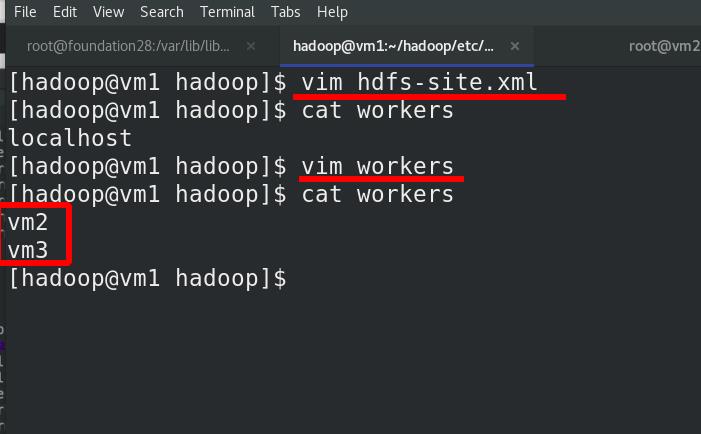
修改worker为vm2和vm3
vm1安装nfs文件系统,
修改文件,启动nfs服务

vm2新建hadoop用户,安装nfs文件系统
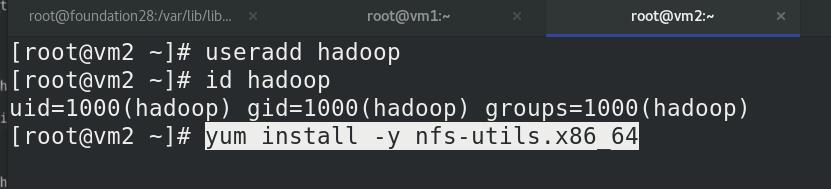
vm3新建hadoop用户,安装nfs文件系统

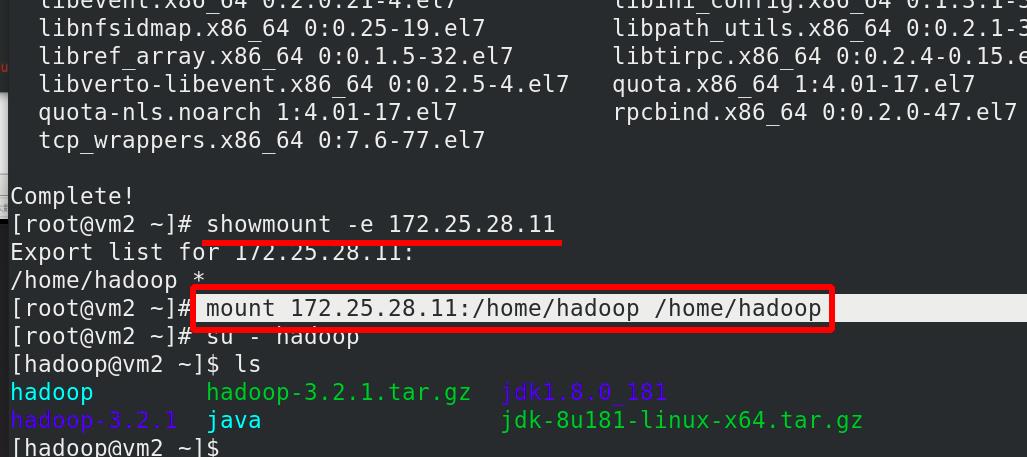
挂载nfs到vm2中的/home/hadoop
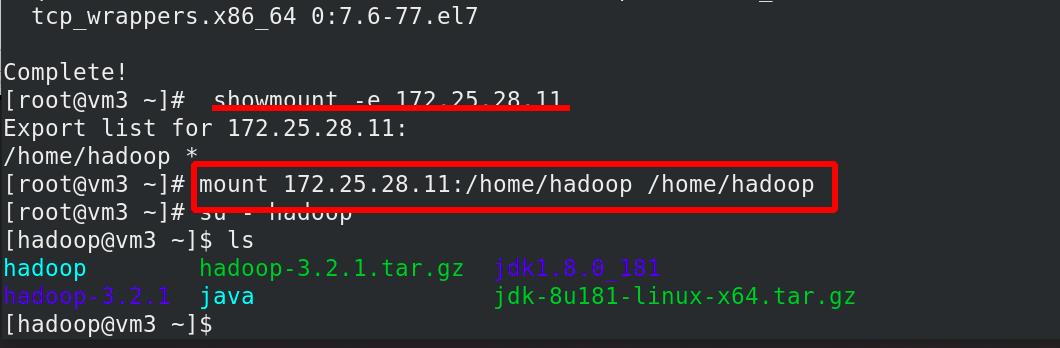
挂载nfs到vm3中的/home/hadoop
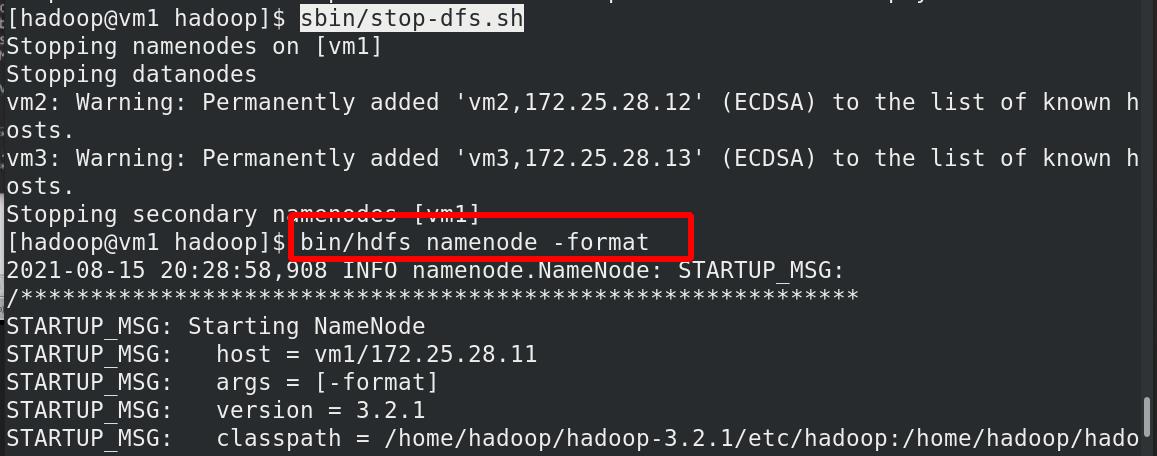
重新初始化文件系统,先stop
测试免密连接
外部访问:
172.25.28.11:9870
9870:hadoop默认的监听端口
此时vm2和vm3已成功加入
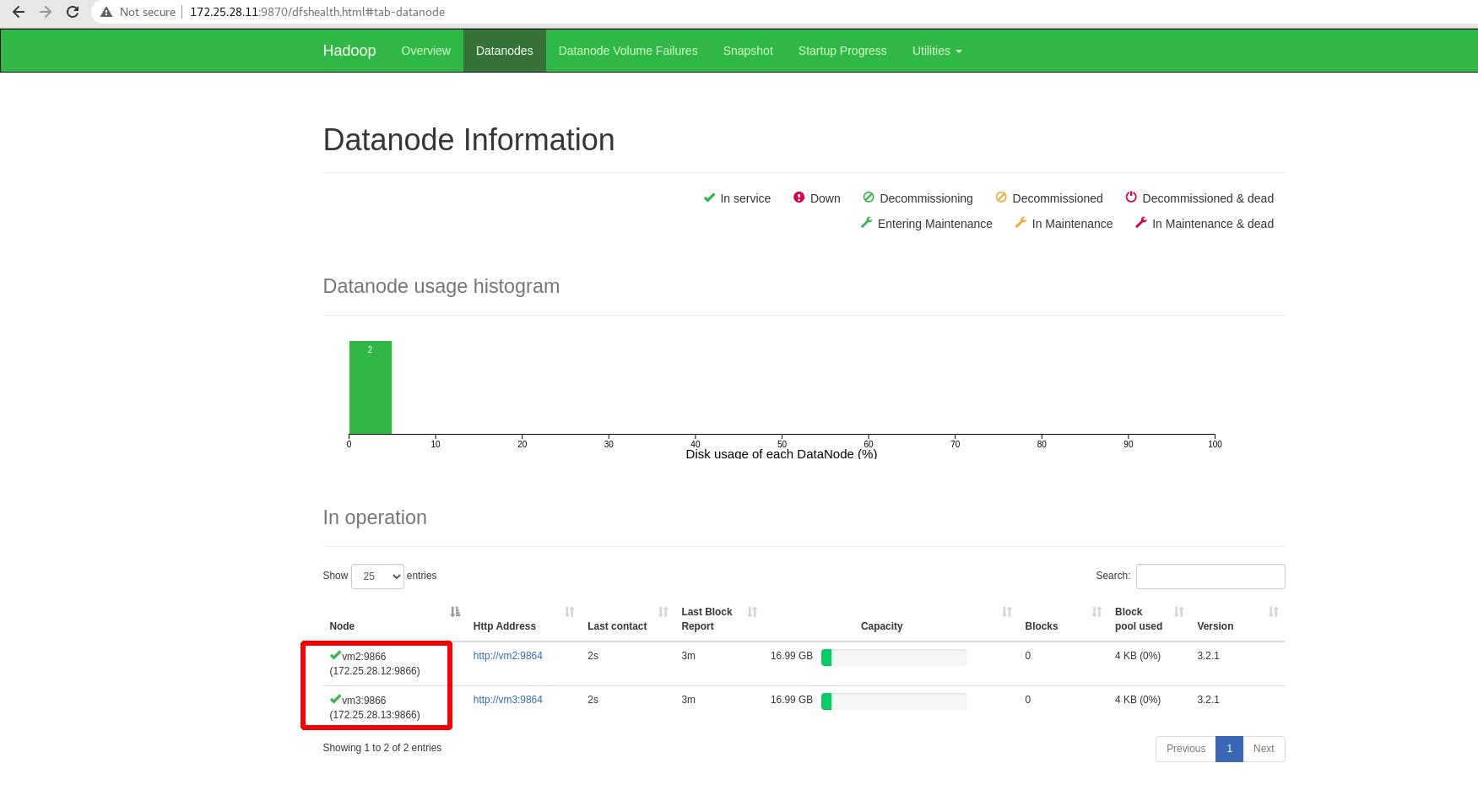
vm2和vm3上,jps查看进程,都有DataNode!!!
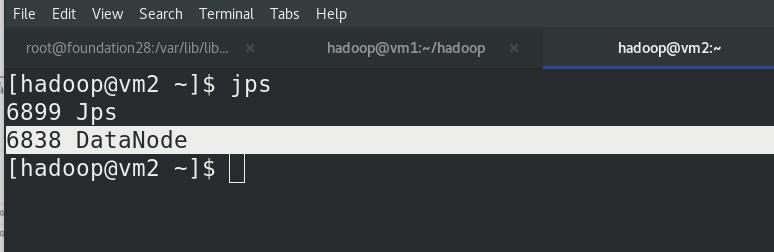
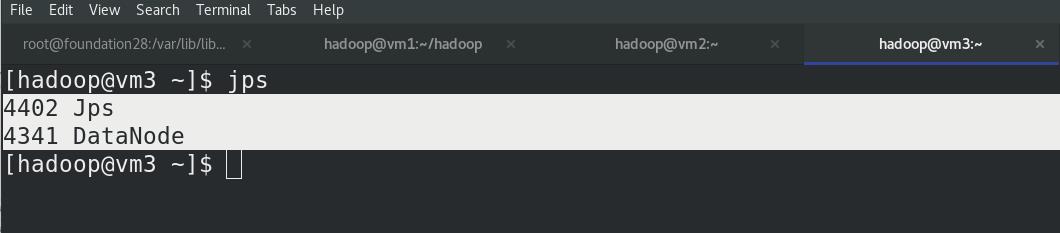
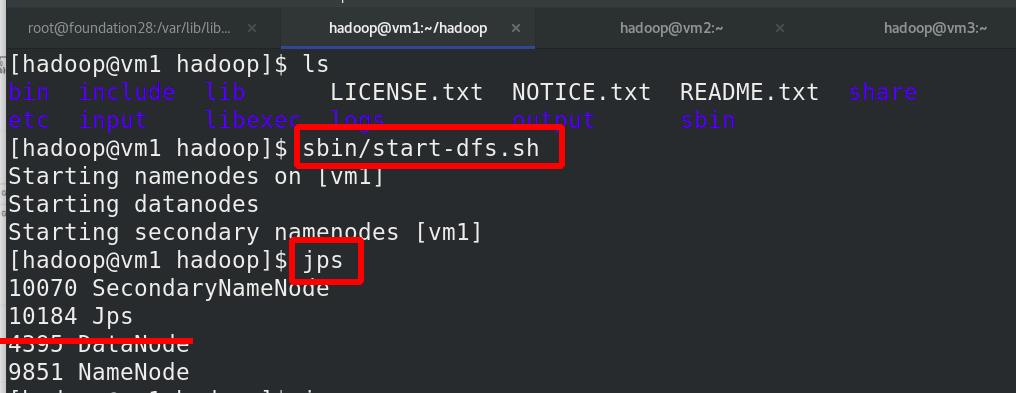
vm1上启动 NameNode 守护进程,此时vm1是没有Datanode,只有Namenode,此处由于版本问题,vm1作为master,Nn是只保留原始数据,不存储数据
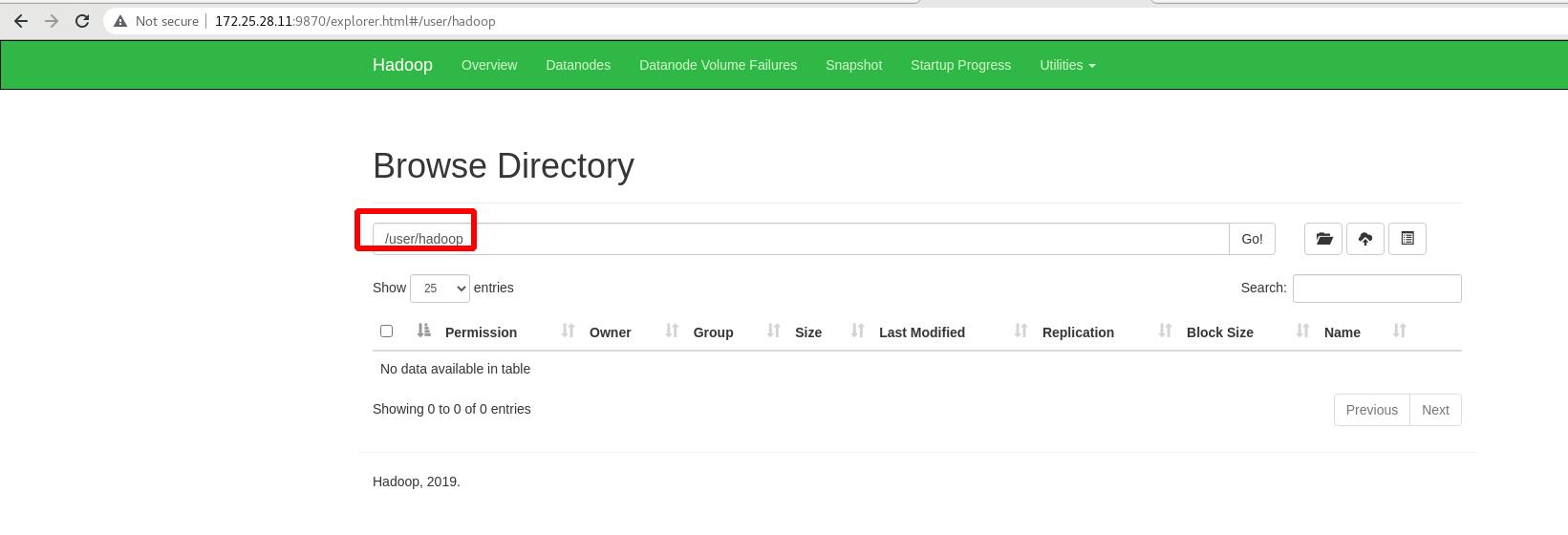
外部访问,查看文件系统
上传input目录至分布式文件系统中
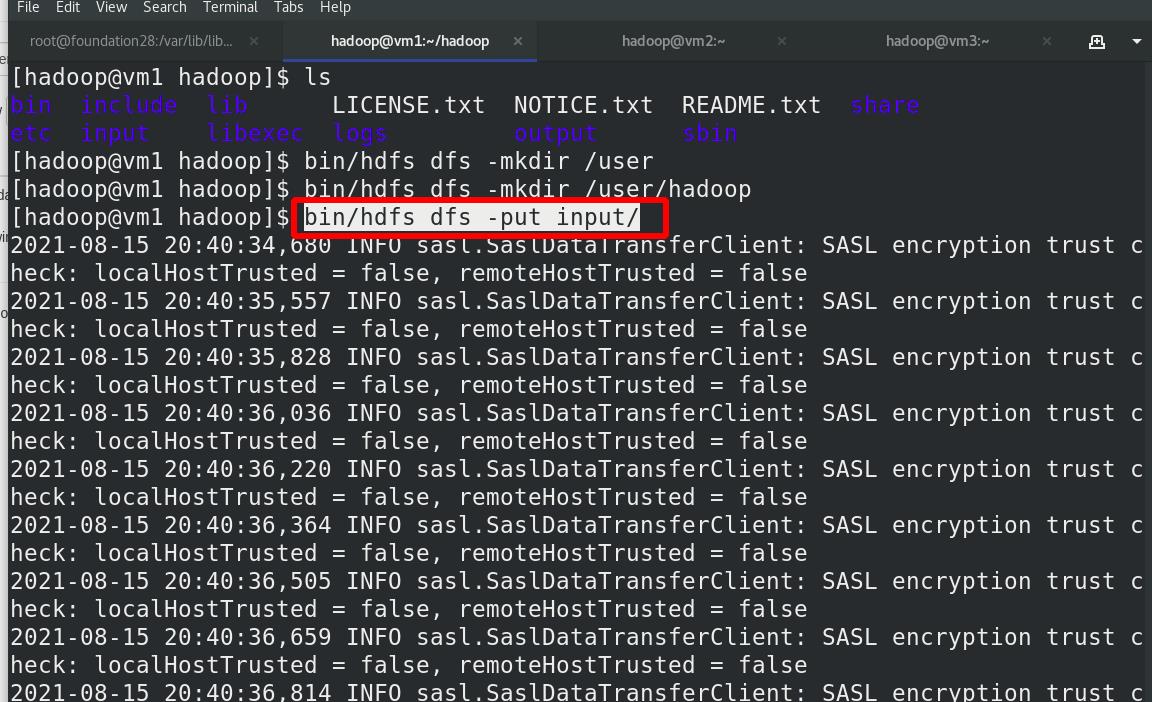
外部再次查看
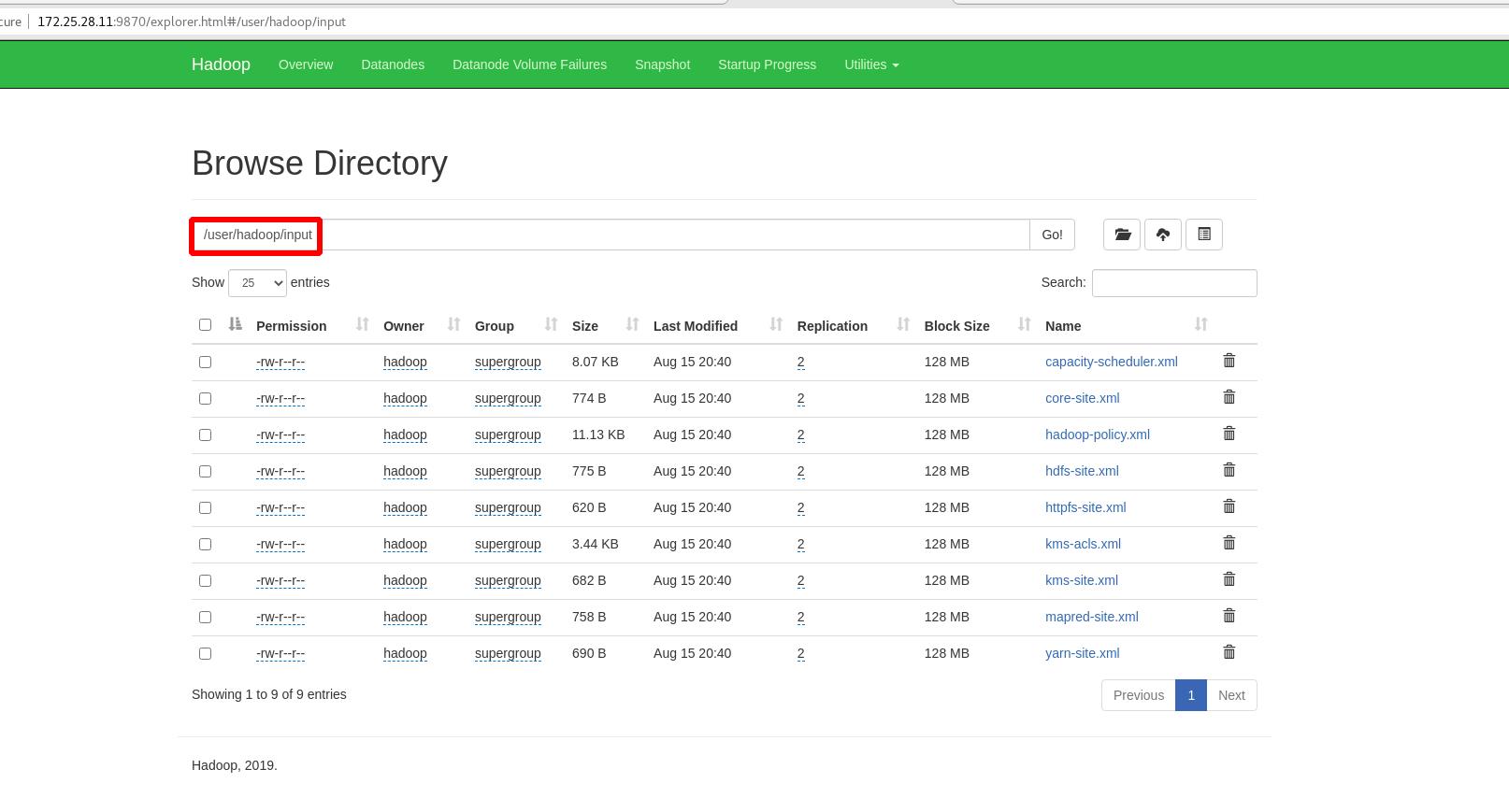
单词数,
input,output :和本地无关,分布式中的输入输出目录
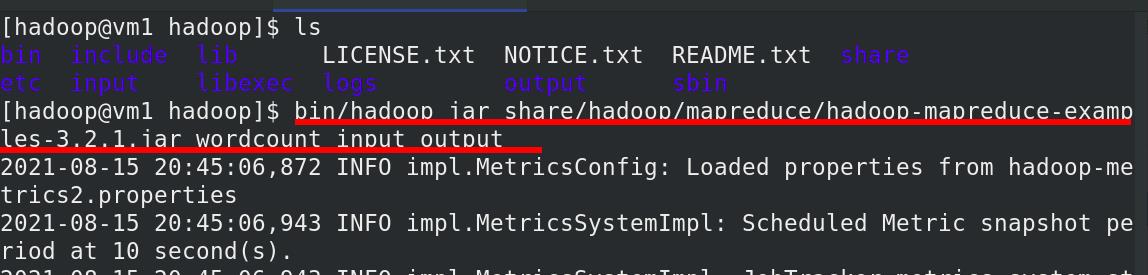
外部查看:分布式中的输出目录
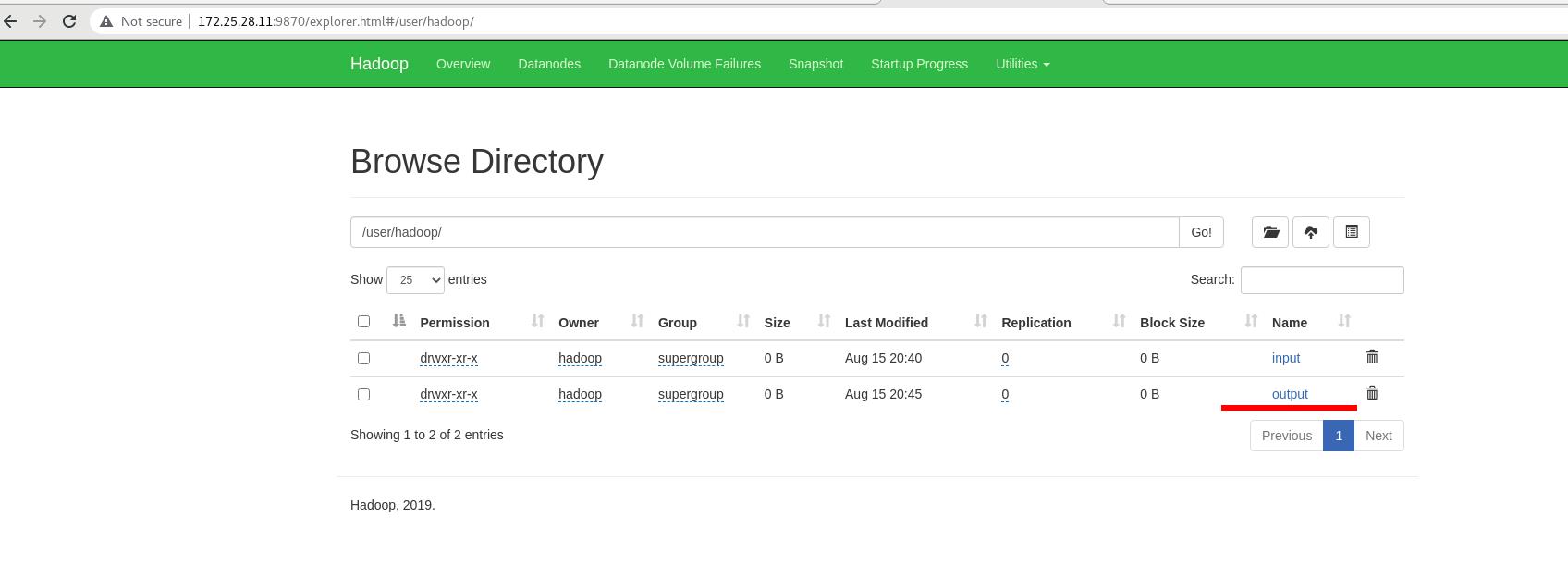
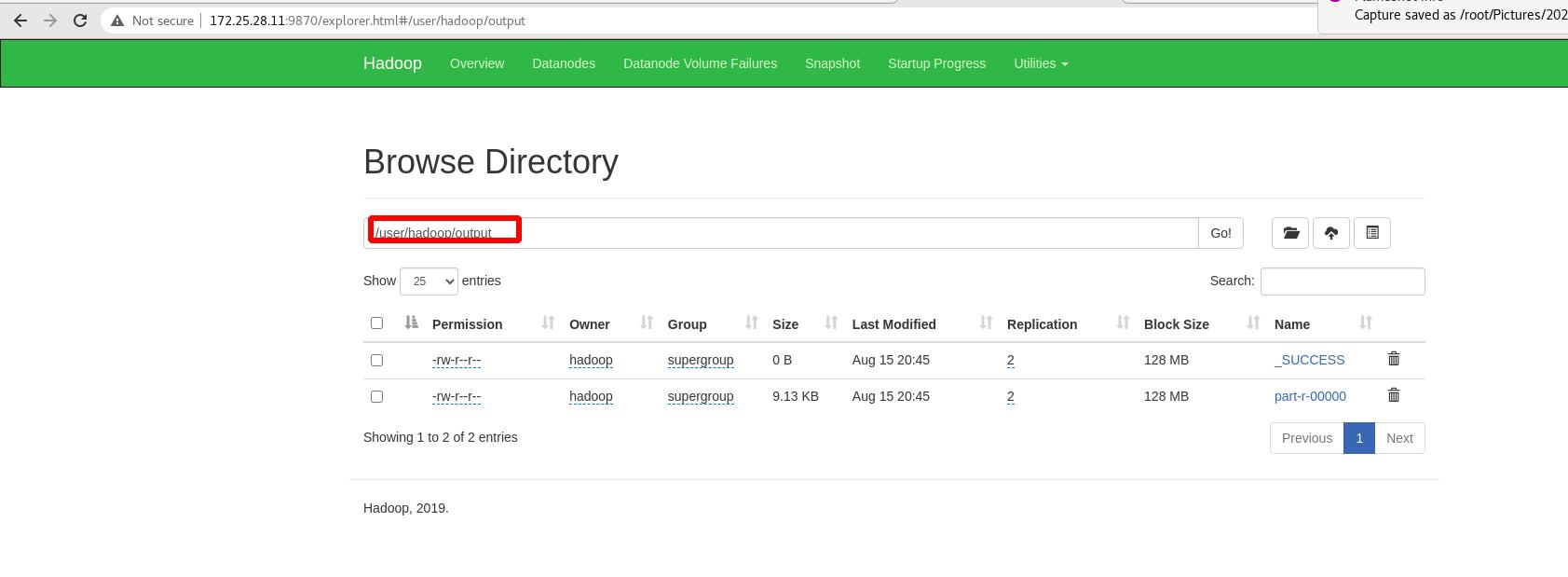
将vm1加入此分布式中:
安装nfs,挂载,编辑worker文件
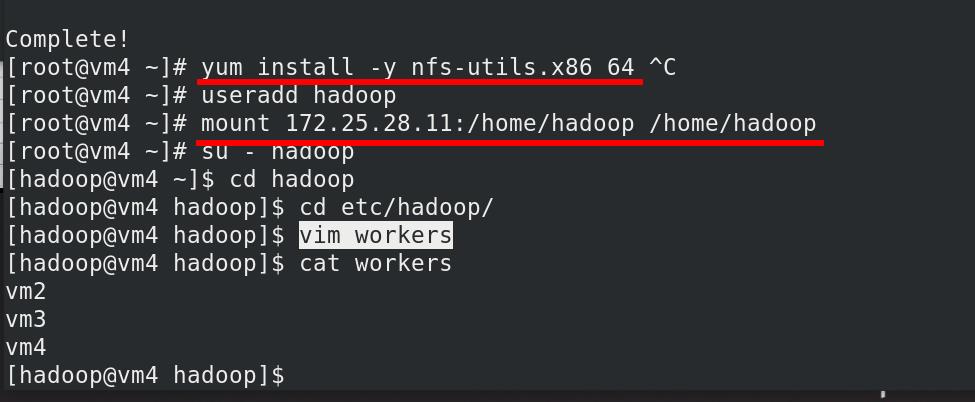
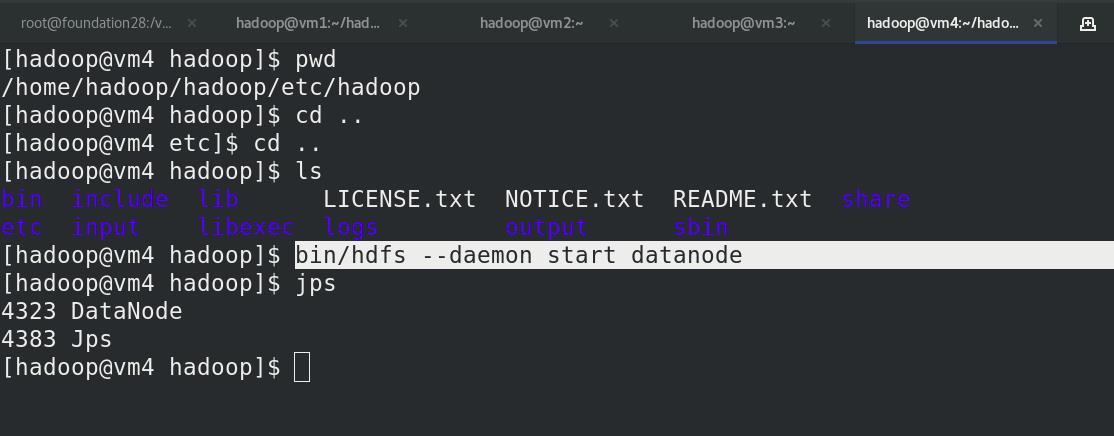
vm4启动namenode,jps查看java进程,已经出现Datanode
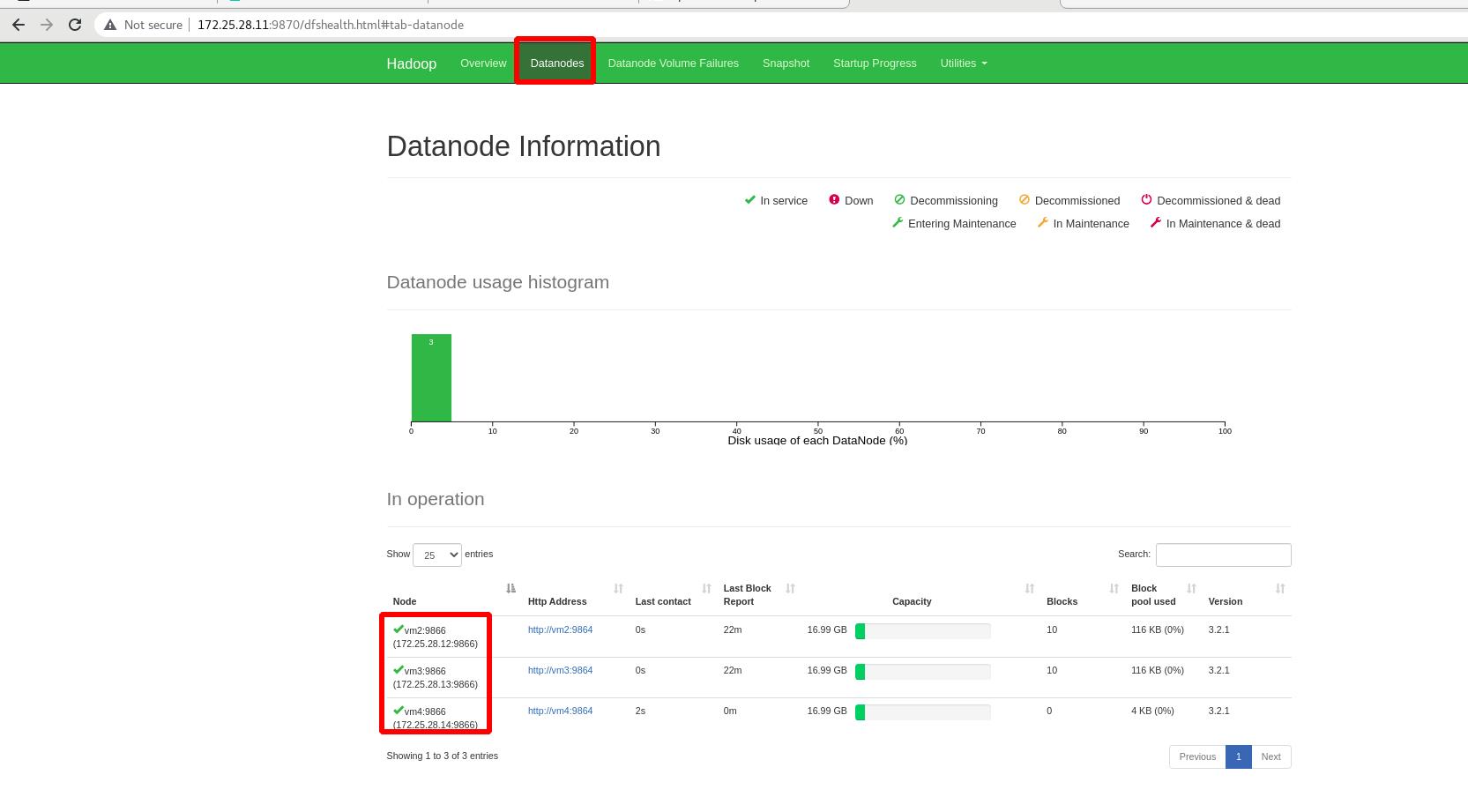
外部查看:vm4已经成功加入此分布式!!!
三. yarn 调度
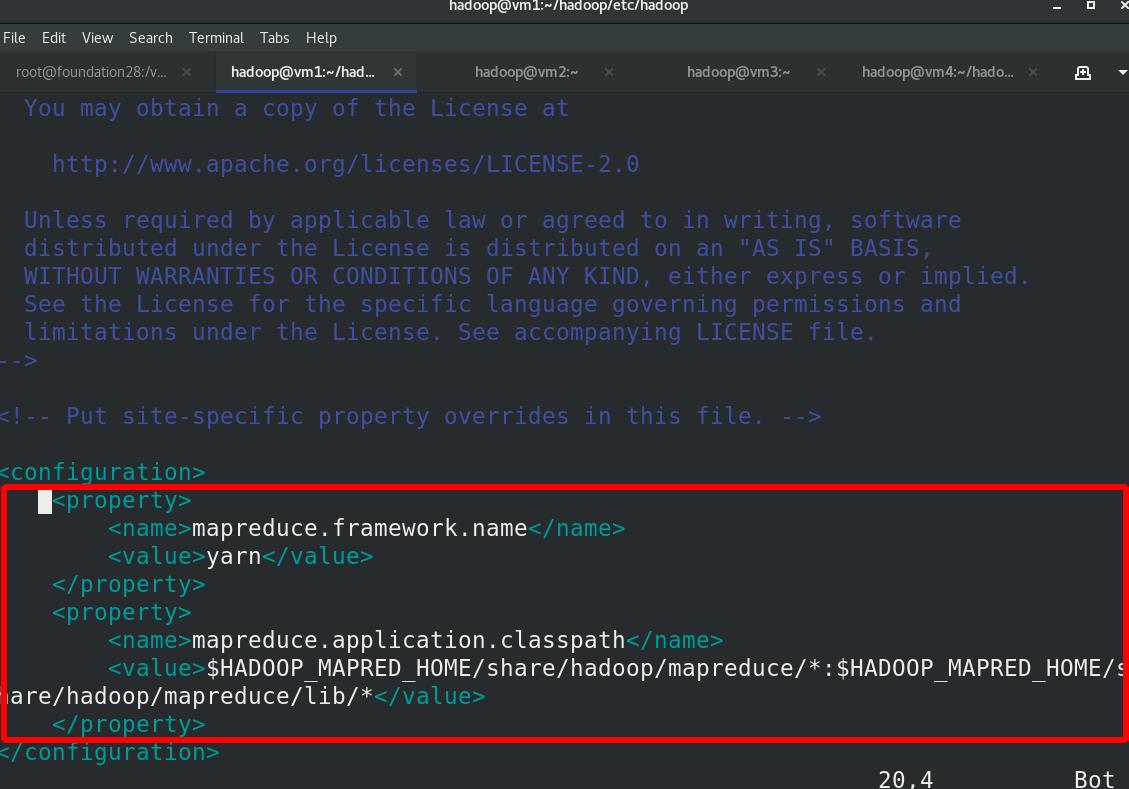
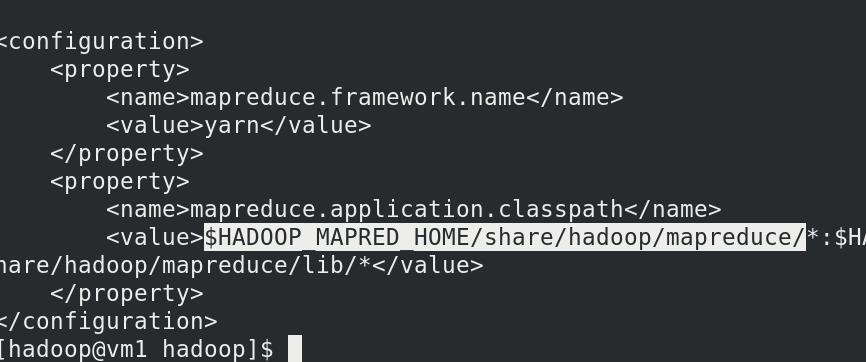
编辑etc/hadoop/mapred-site.xml:文件
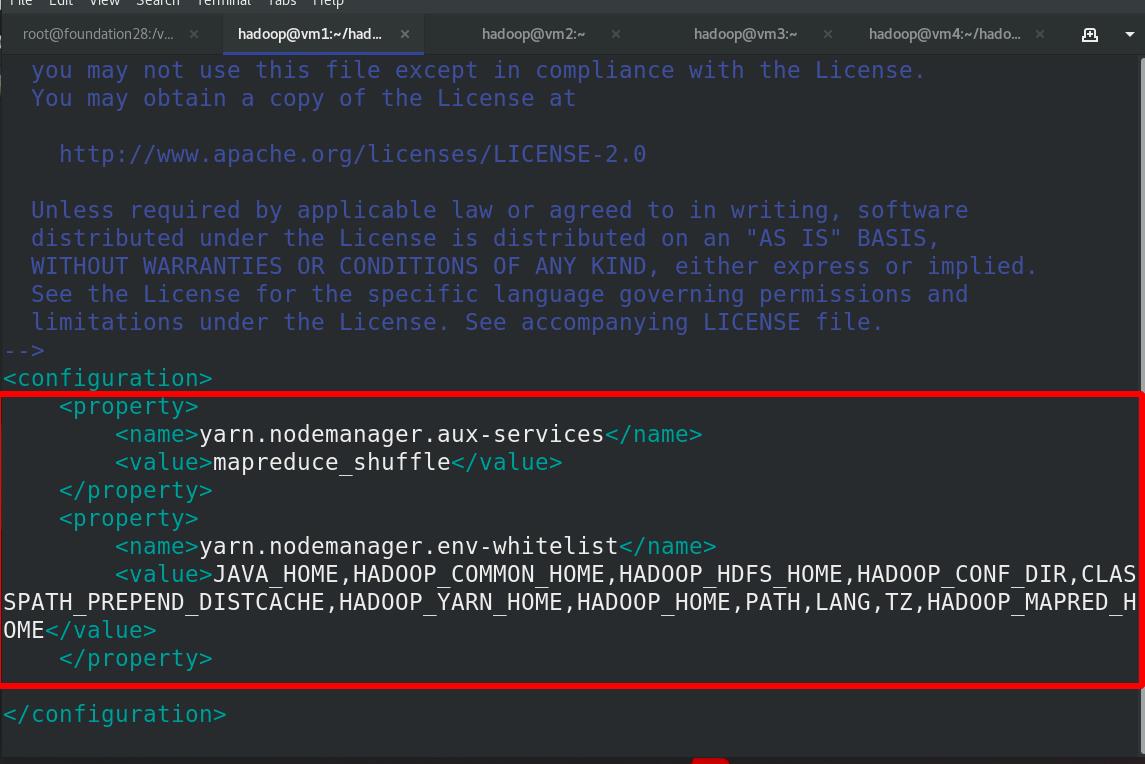
编辑etc/hadoop/yarn-site.xml文件
编辑环境变量,加入$HADOOP_HOME

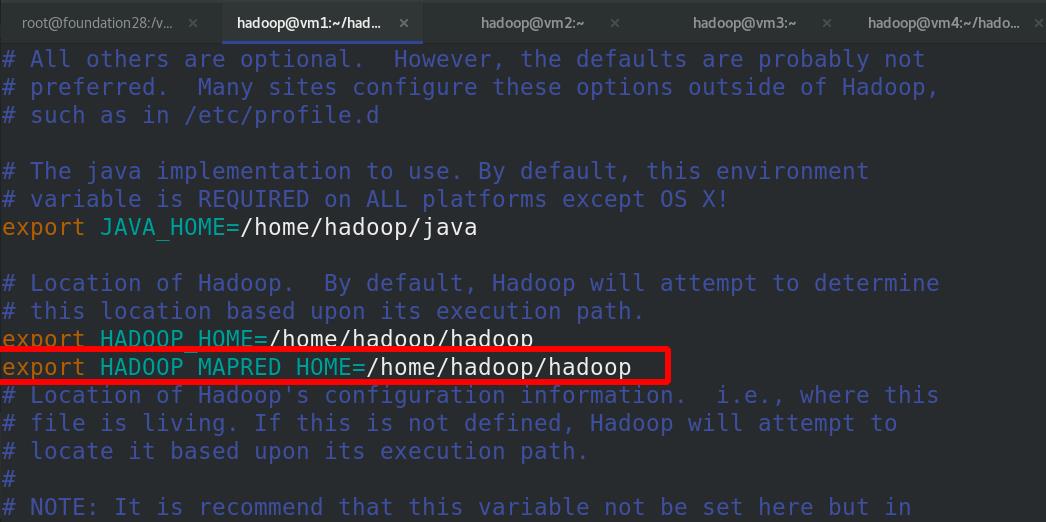
$HADOOP_HOME 就是 /home/hadoop/hadoop/share/hadoop/mapreduce
启动 ResourceManager 进程和 NodeManager 进程
vm1上有ResourceManager 进程
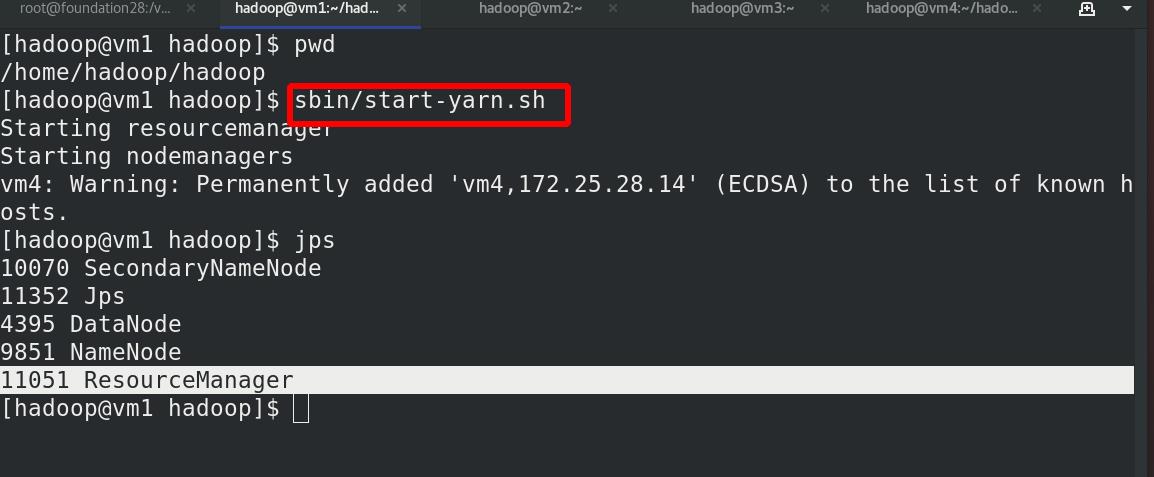
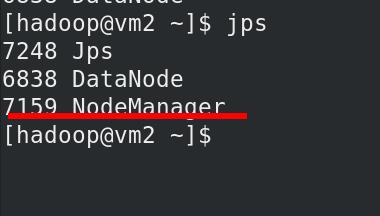
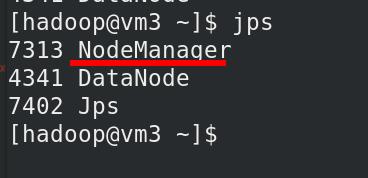
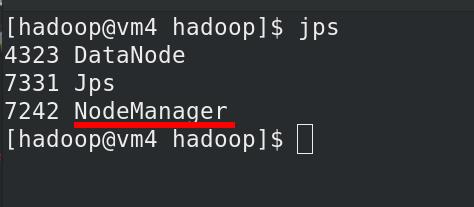
vm 2,3,4 有 NodeManager 进程
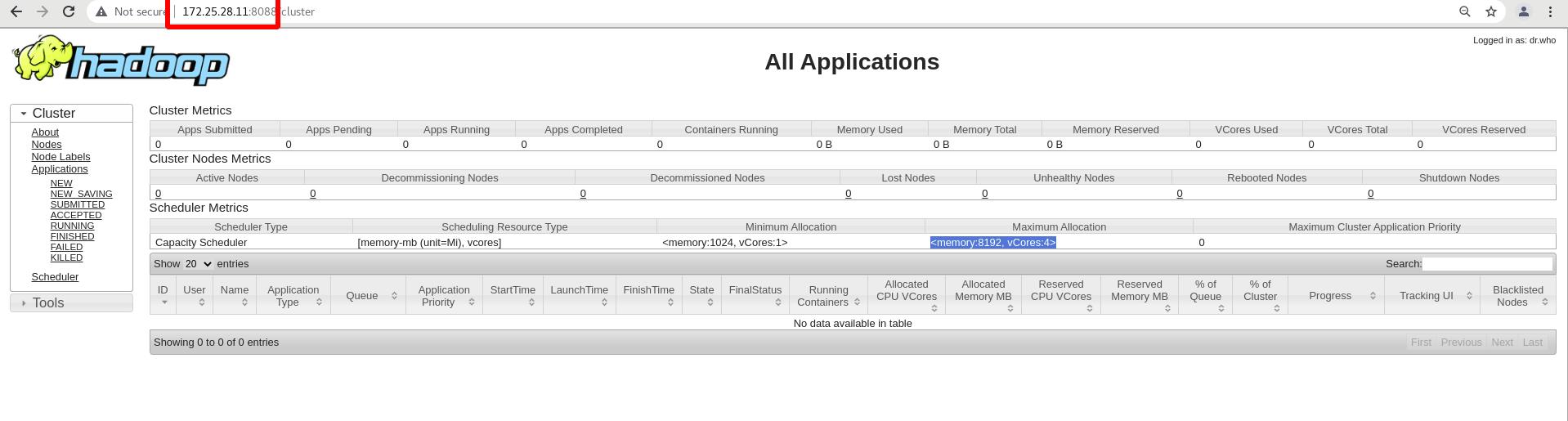
外部访问:
172.25.28.11:8088
调度内存消耗较大
四. hadoop高可用
参考pdf:/pub/docs/hadoop
实验环境:
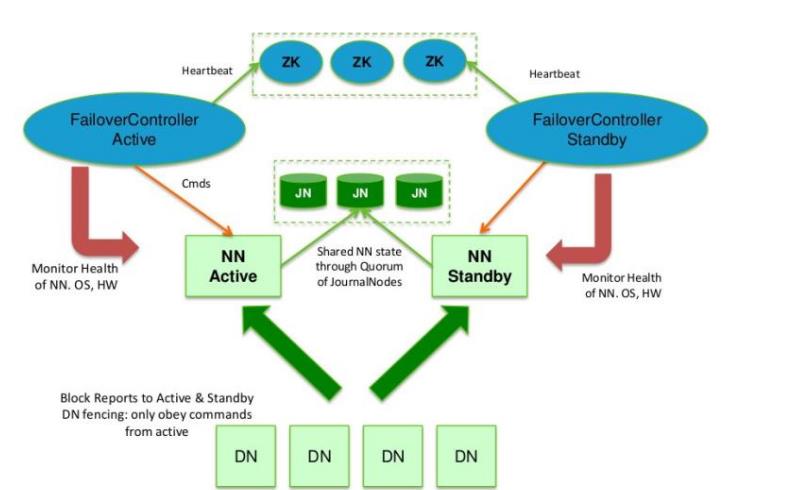
ZK(3); JN(3); 双机热备;(NN主备模式2); DN(4)
在典型的 HA 高可用集群中,通常有两台不同的机器充当 NN。在任何时间,只有一台机器处于Active 状态;另一台机器是处于 Standby 状态。Active NN 负责集群中所有客户端的操作;而 Standby NN 主要用于备用,它主要维持足够的状态,如果必要,可以提供快速的故障恢
复。
| 主机名 | ip | 功能 |
|---|---|---|
| vm1 | 172.25.28.11(2G) | (Namenode)master,双机热备的主Active |
| vm2 | 172.25.28.12 | (Datanode)worker, zookeeper,JN |
| vm3 | 172.25.28.13 | (Datanode)worker, zookeeper,JN |
| vm4 | 172.25.28.14 | (Datanode)worker, zookeeper,JN |
| vm5 | 172.25.28.15 | (Namenode)master,双机热备的备Standby |
为了让 Standby NN 的状态和 Active NN 保持同步,即元数据保持一致,它们都将会和JournalNodes 守护进程通信。
1 zookeeper集群
所有主机停止

/tmp数据全部删除
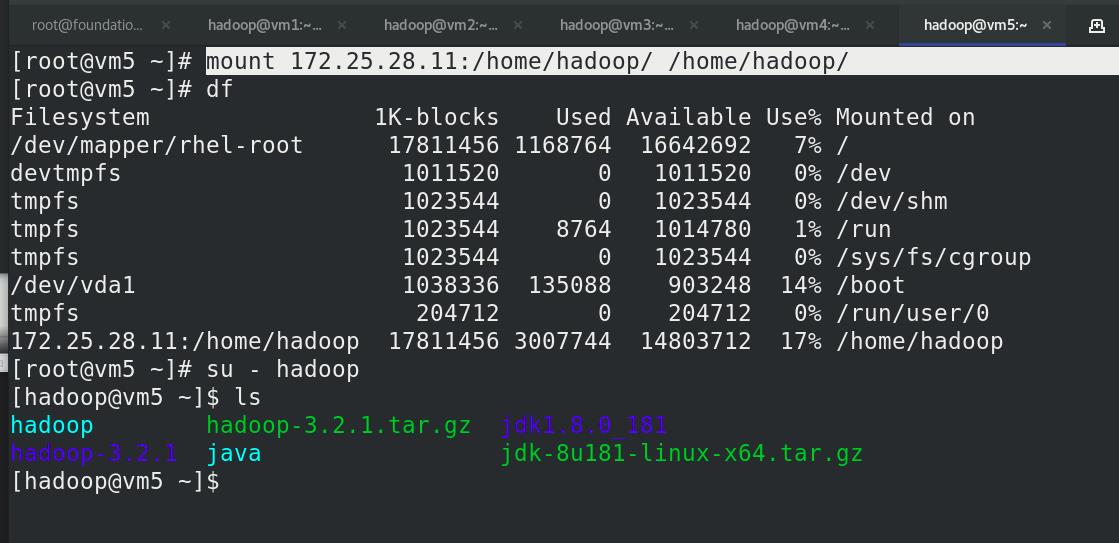
vm5 安装nfs,挂载,新建hadoop用户

 安装 JDK
安装 JDK
安装 zookeeper
解压缩zookeeper包
编辑 zoo.cfg 文件,各节点配置文件相同,(已经挂载)
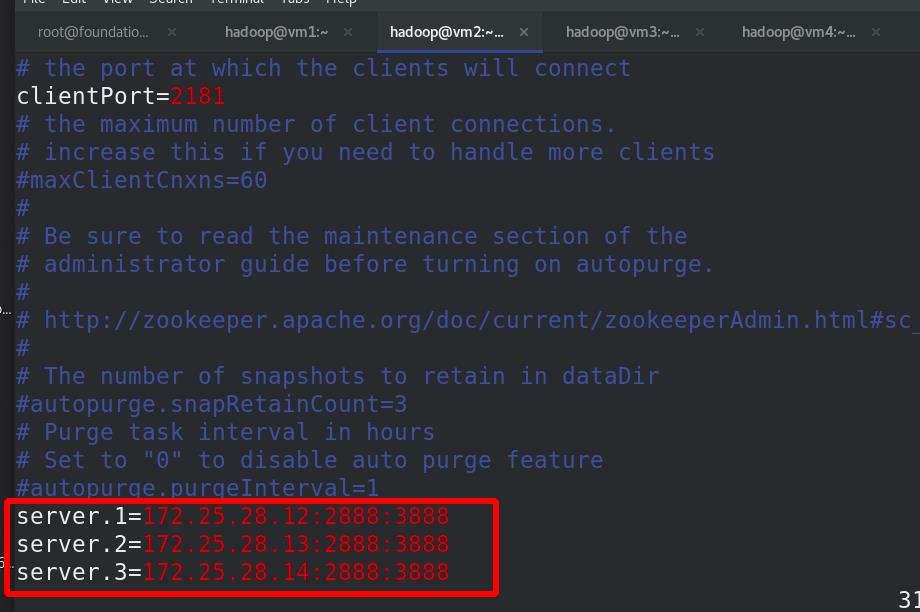
2888(数据同步)和38888(选举的)通信端口
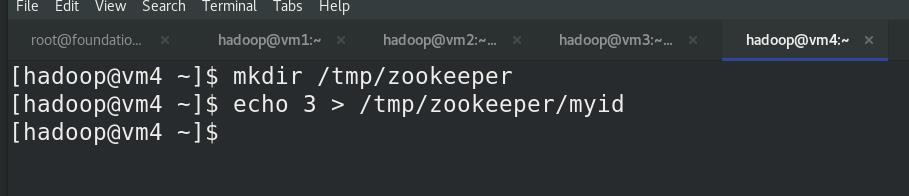
需要在/tmp/zookeeper 目录中创建 myid 文件,
写入 一个唯一的数字,取值范围在 1-255
比如:172.25.28.12 节点的 myid 文件写入数
字“1”,此数字与配置文件中的定义保持一致,(server.1=172.25.28.12:2888:3888)其它节点依次类推。


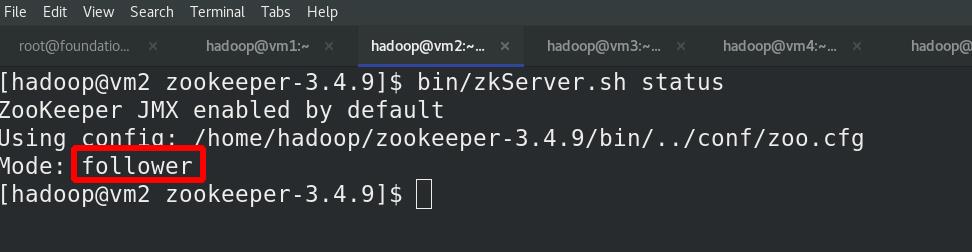
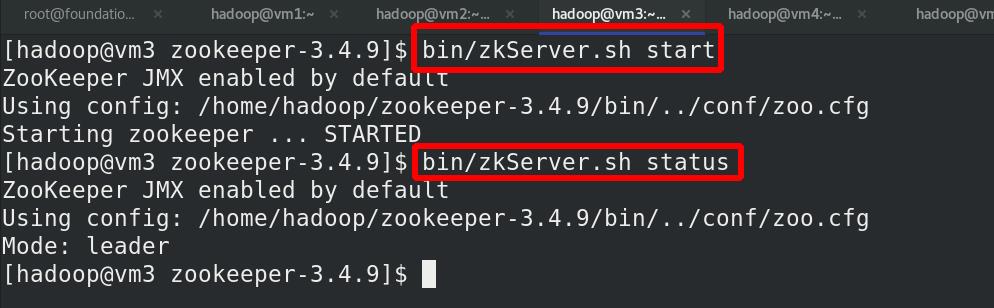
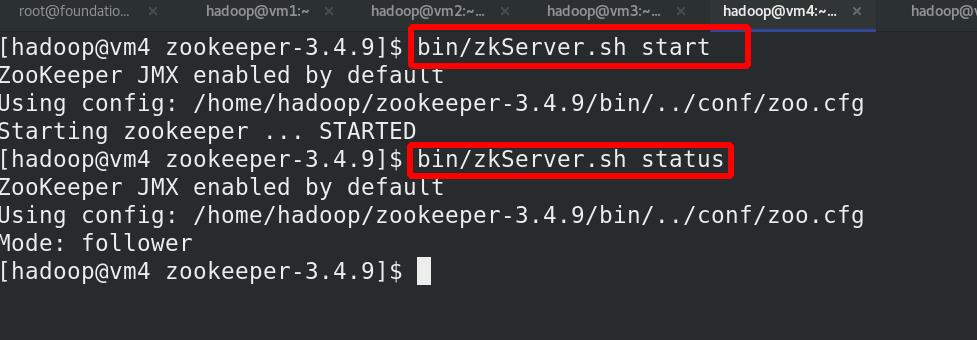
在各节点(vm2,vm3,vm4)启动服务,vm3为leader,随机

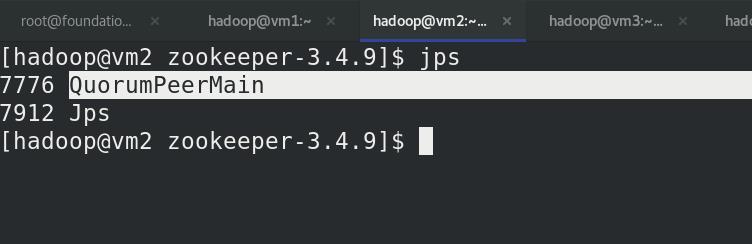
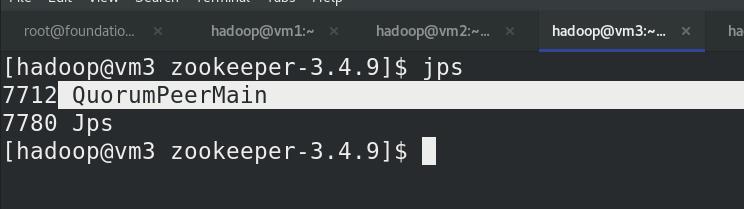
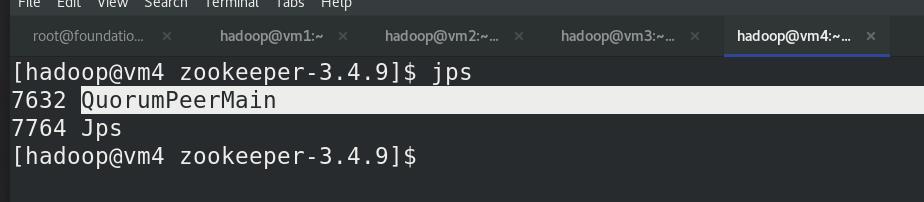
(vm2,vm3,vm4)jps查看进程
连接 zookeeper
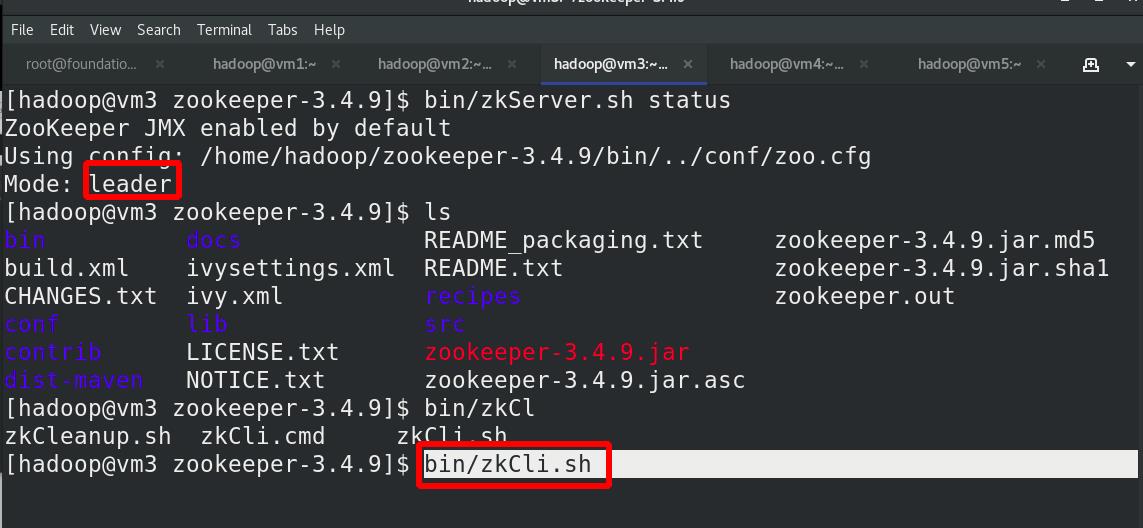
查看
2 hdfs高可用
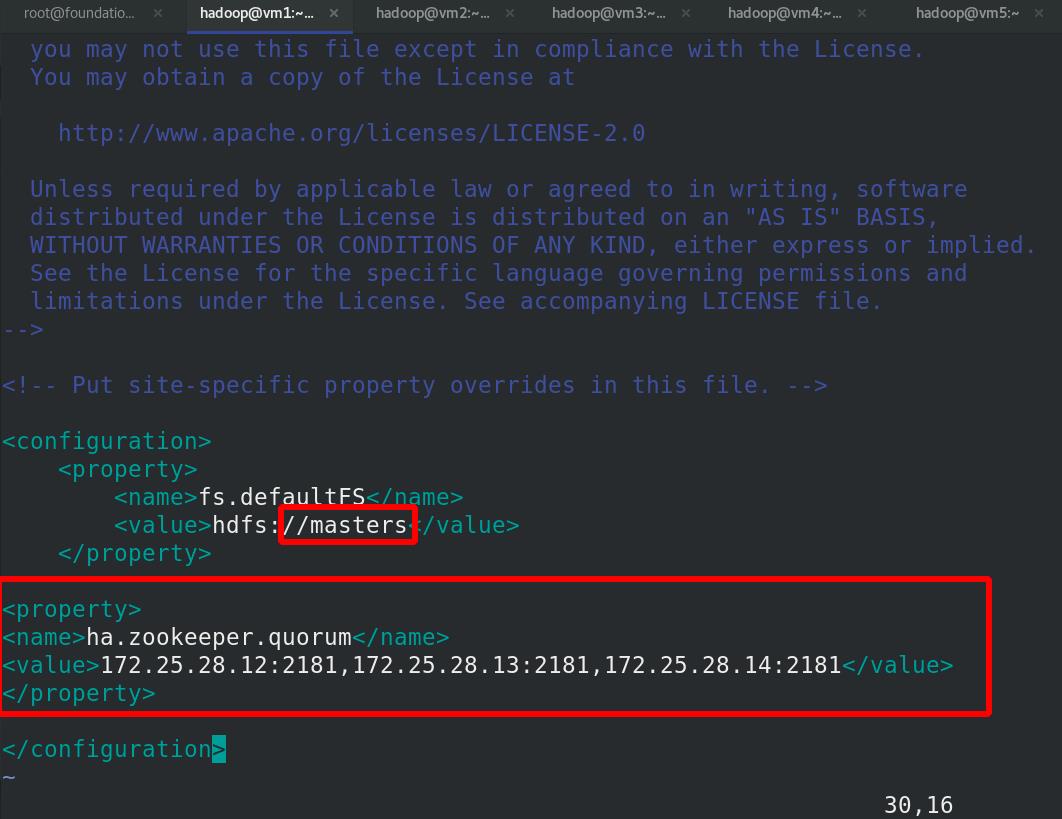
编辑etc/hadoop/core-site.xml文件
<configuration>
<!-- 指定 hdfs 的 namenode 为 masters (名称可自定义)-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://masters</value>
</property>
<!-- 指定 zookeeper 集群主机地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>172.25.28.12:2181;172.25.28.13:2181;172.25.28.14:2181</value>
</property>
</configuration>
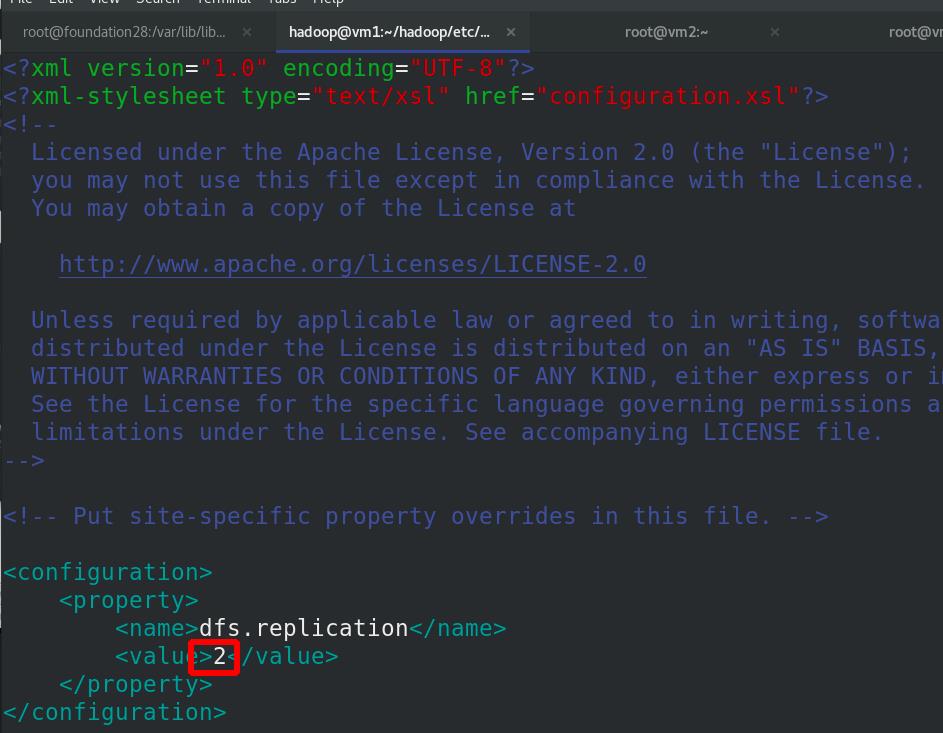
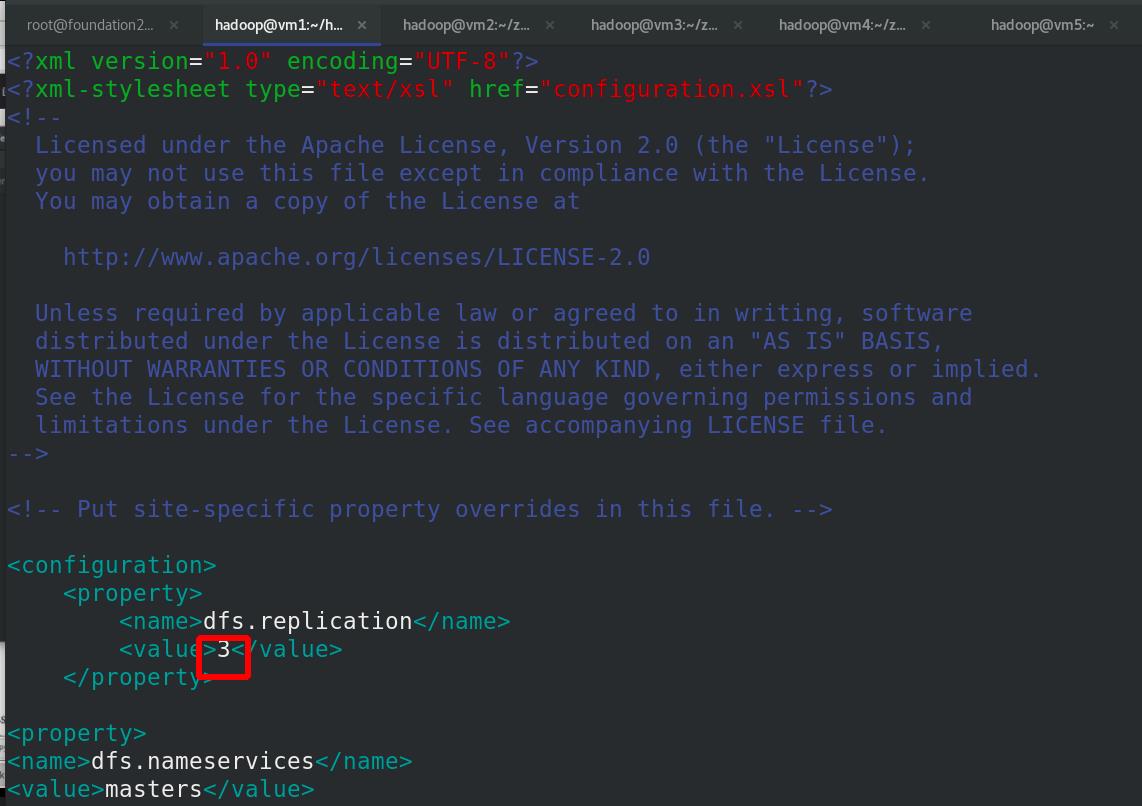
编辑 etc/hadoop/hdfs-site.xml 文件,副本数为3(vm2,3,4)
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<!-- 指定 hdfs 的 nameservices 为 masters,和 core-site.xml 文件中的设置保持一致 -->
<name>dfs.nameservices</name>
<value>masters</value>
</property>
<property>
<!-- masters 下面有两个 namenode 节点,分别是 h1 和 h2 (名称可自定义)
-->
<name>dfs.ha.namenodes.masters</name>
<value>h1,h2</value>
</property>
<property>
<!-- 指定 h1 节点的 rpc 通信地址 -->
<name>dfs.namenode.rpc-address.masters.h1</name>
<value>172.25.28.11:9000</value>
</property>
<property>
<!-- 指定 h1 节点的 http 通信地址 -->
<name>dfs.namenode.http-address.masters.h1</name>
<value>172.25.28.11:9870</value>
</property>
<property>
<!-- 指定 h2 节点的 rpc 通信地址 -->
<name>dfs.namenode.rpc-address.masters.h2</name>
<value>172.25.28.15:9000</value>
</property>
<property>
<!-- 指定 h2 节点的 http 通信地址 -->
<name>dfs.namenode.http-address.masters.h2</name>
<value>172.25.28.15:9870</value>
</property>
<property>
<!-- 指定 NameNode 元数据在 JournalNode 上的存放位置 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://172.25.28.12:8485;172.25.28.13:8485;172.25.28.14:8485/masters</value>
</property>
<property>
<!-- 指定 JournalNode 在本地磁盘存放数据的位置 -->
<name>dfs.journalnode.edits.dir</name>
<value>/tmp/journaldata</value>
</property>
<property>
<!-- 开启 NameNode 失败自动切换 -->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<!-- 配置失败自动切换实现方式 -->
<name>dfs.client.failover.proxy.provider.masters</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- 配置隔离机制方法,每个机制占用一行-->
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<!-- 使用 sshfence 隔离机制时需要 ssh 免密码 -->
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<!-- 配置 sshfence 隔离机制超时时间 -->
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
启动 hdfs 集群(按顺序启动)
在三个 DN 上依次启动 zookeeper 集群
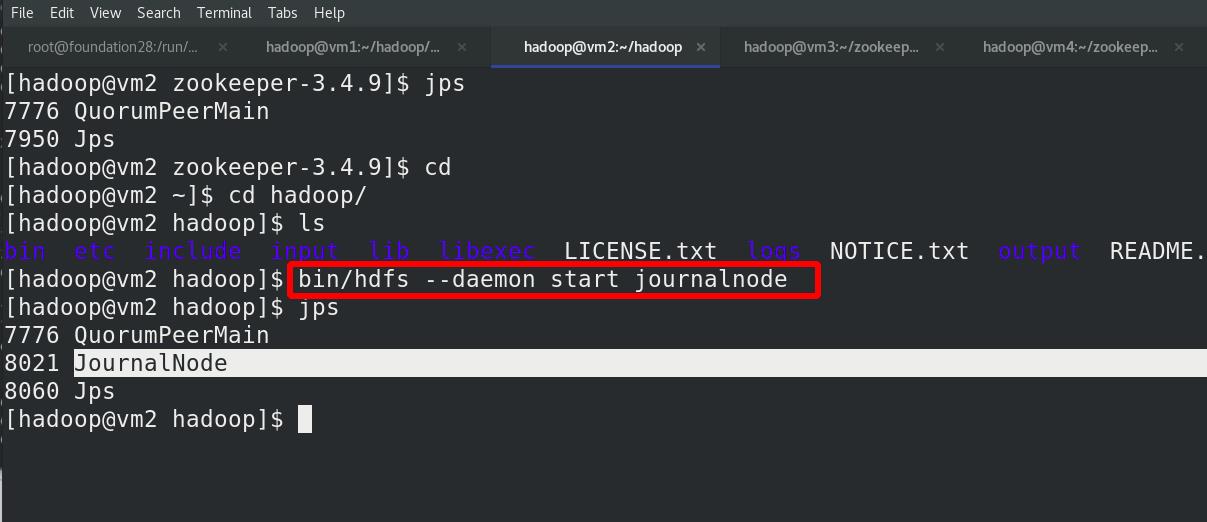
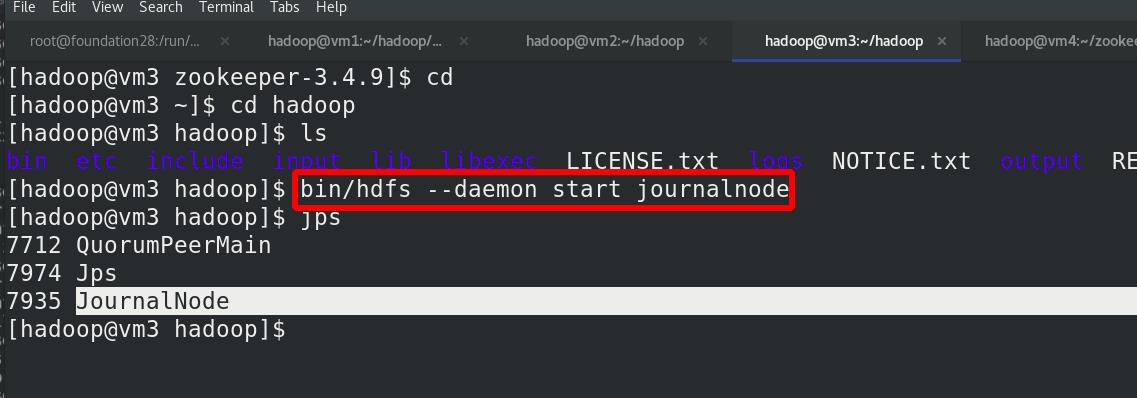
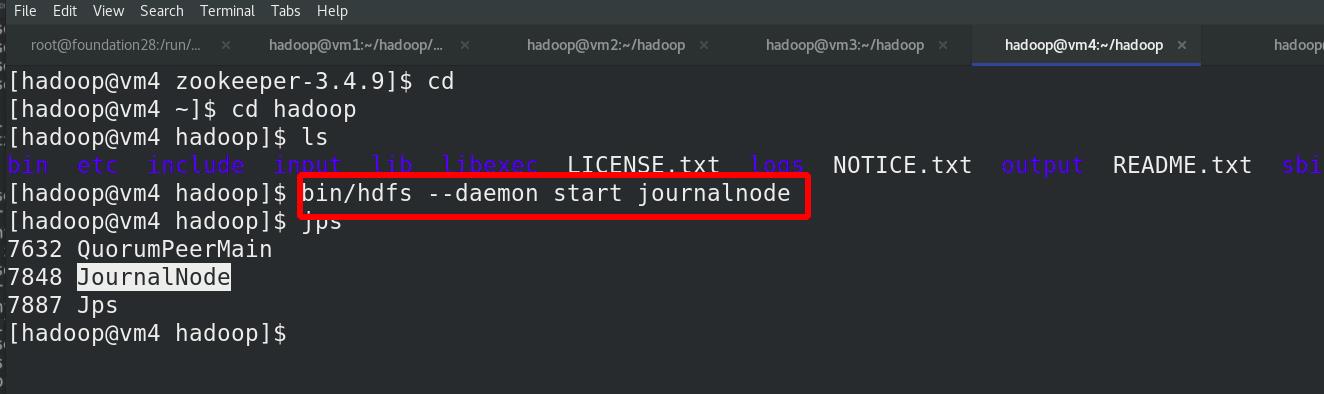 在三个 DN 上依次启动 journalnode(之前已经都启动!!!)
在三个 DN 上依次启动 journalnode(之前已经都启动!!!)
格式化 HDFS 集群
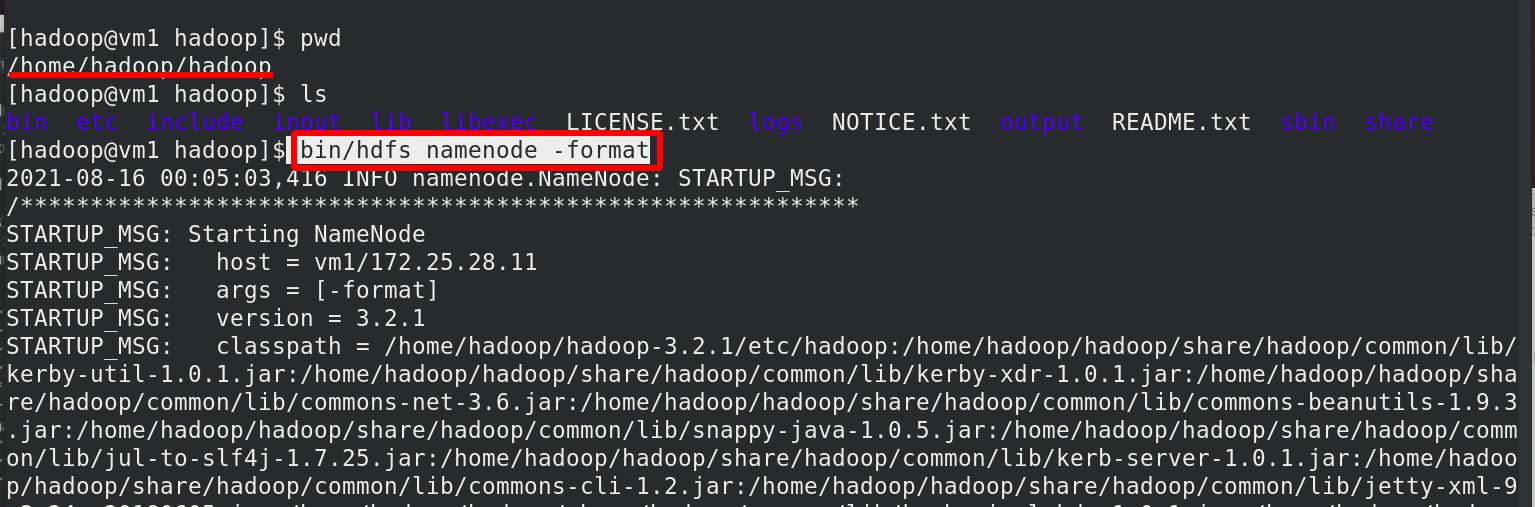 Namenode 数据默认存放在/tmp,需要把数据拷贝到 h2(vm5)
Namenode 数据默认存放在/tmp,需要把数据拷贝到 h2(vm5)
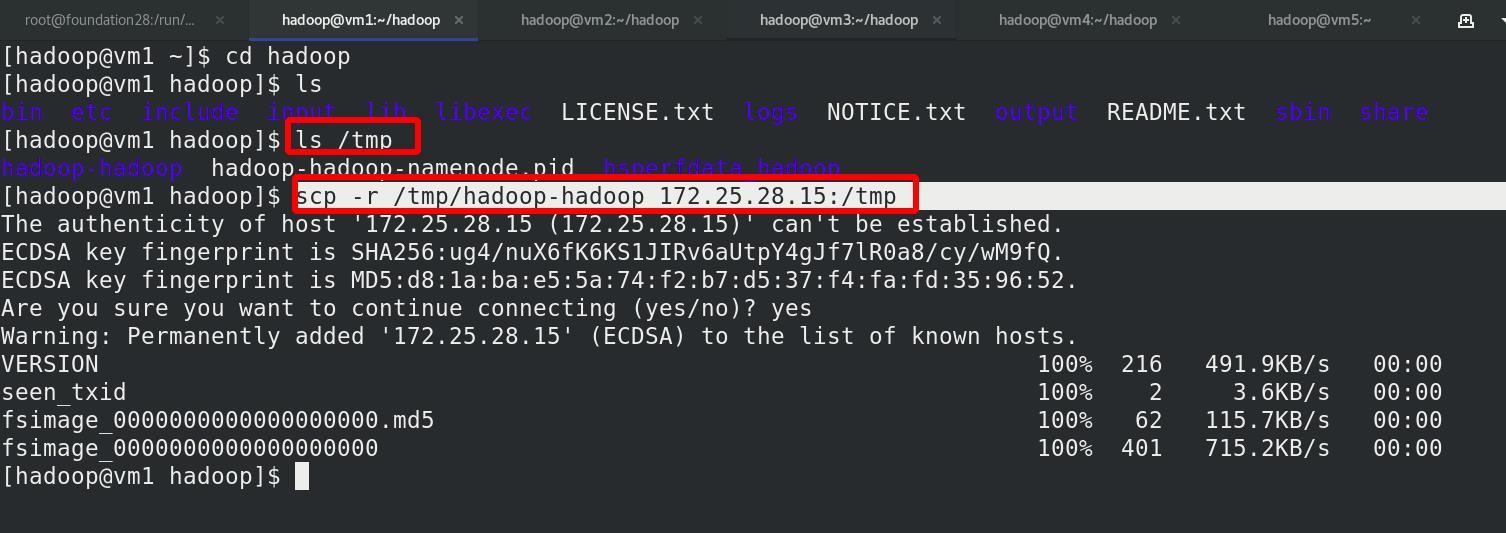 格式化 zookeeper (只需在 h1 上执行即可)
格式化 zookeeper (只需在 h1 上执行即可)
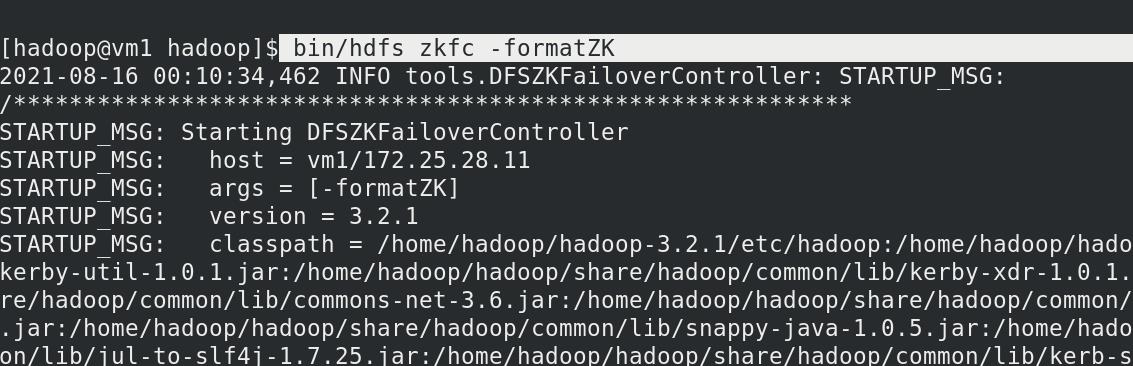 连接zookeeper
连接zookeeper

查看有zookeeper
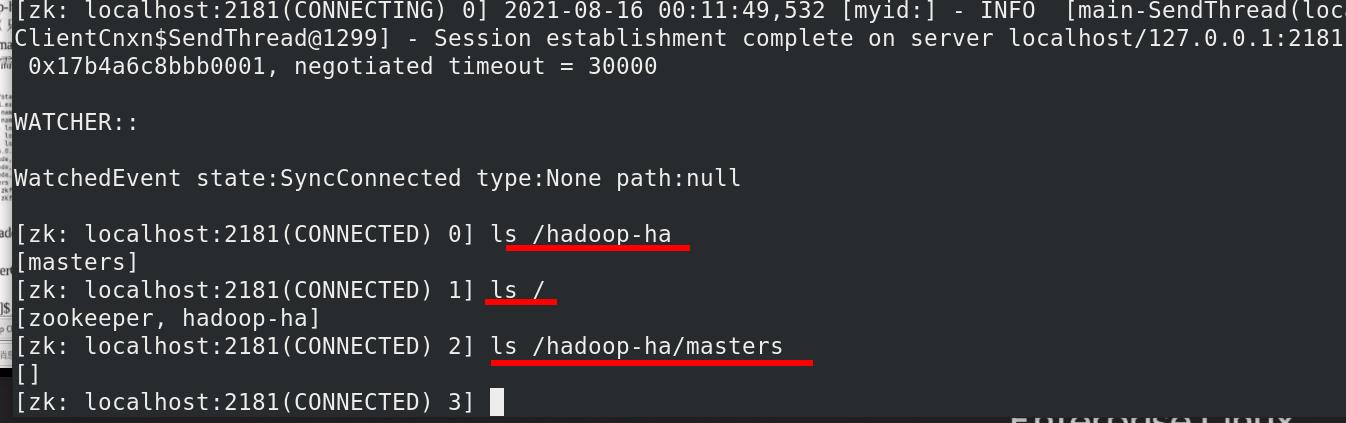
启动 hdfs 集群(只需在 h1 上执行即可)
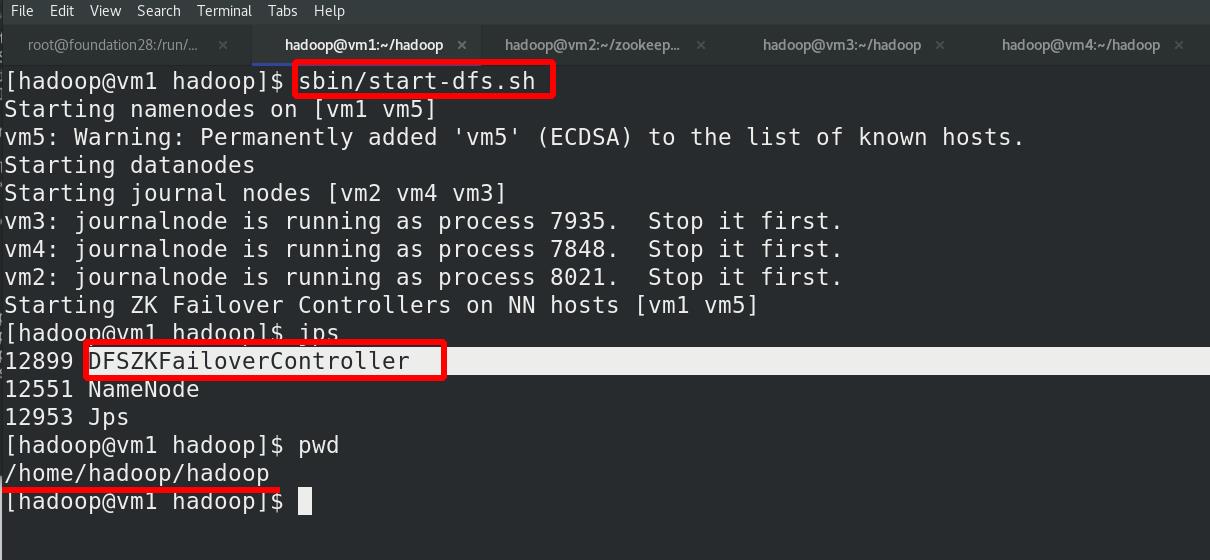 vm5查看进程状态,主备(vm1和vm5)保持一致!!!
vm5查看进程状态,主备(vm1和vm5)保持一致!!!

查看各节点状态,有QuorumPeerMain进程!!!
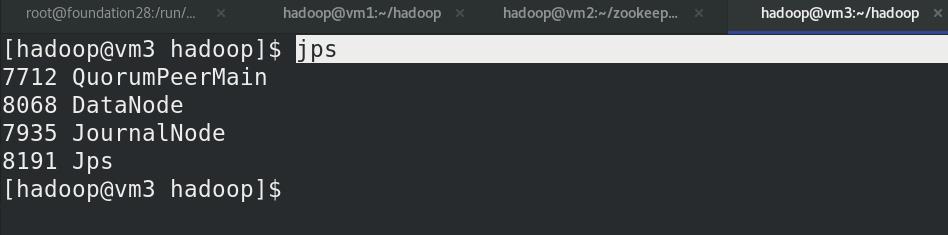
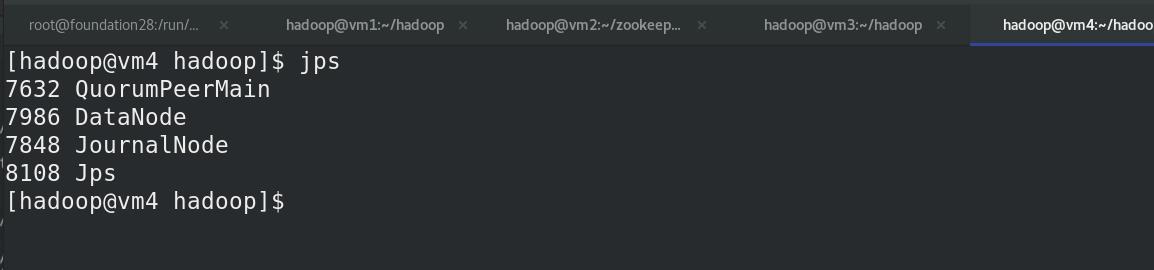
vm2查看NN主备,此时vm1为NN的主
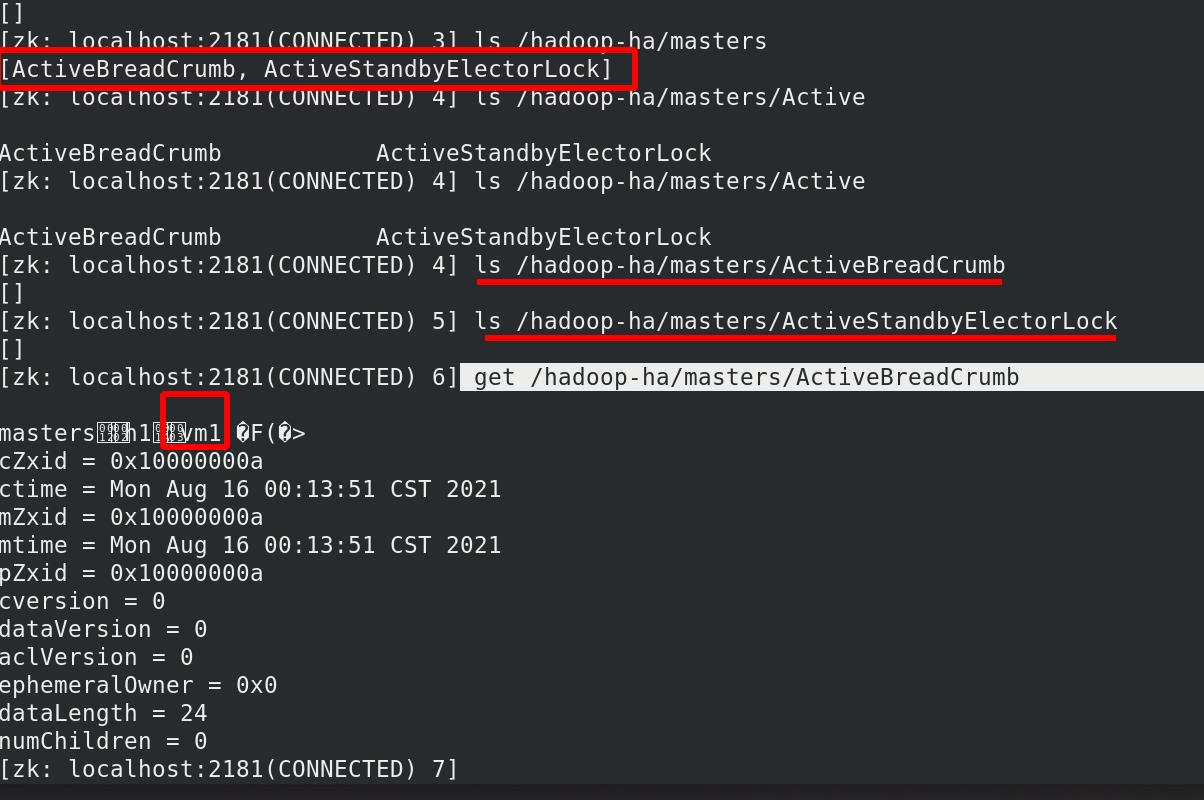 外部访问查看,
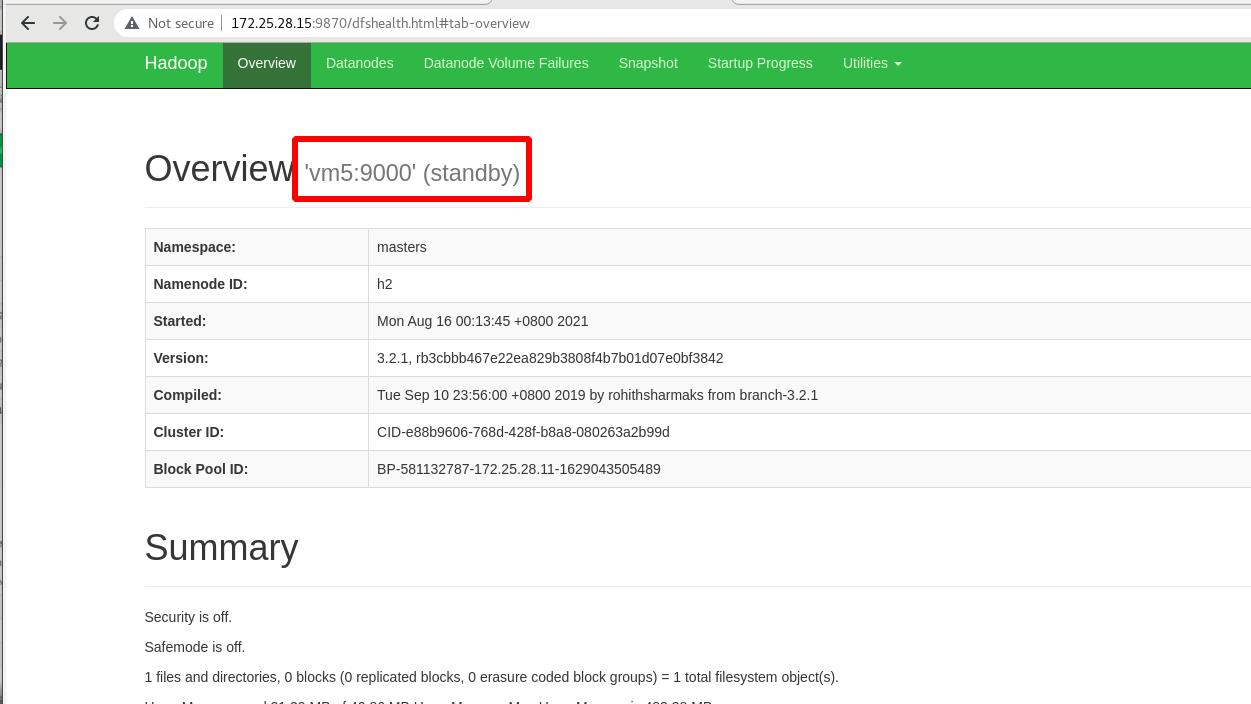
外部访问查看,主为vm1!!!备为vm5!!!
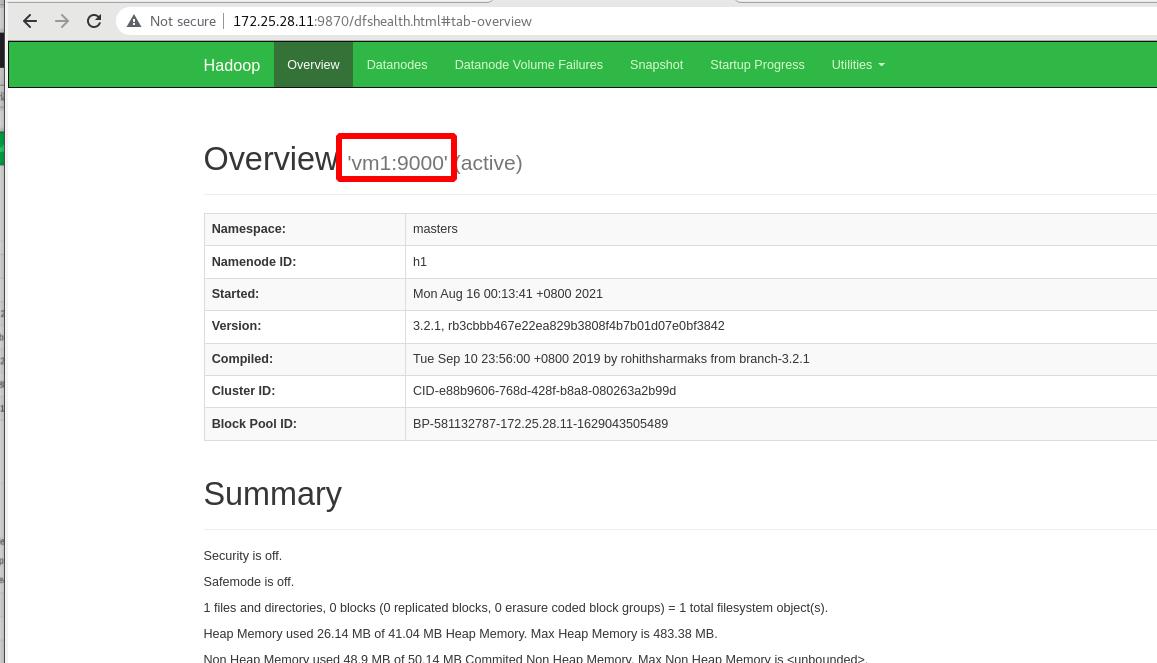
上传input目录到分布式文件系统中
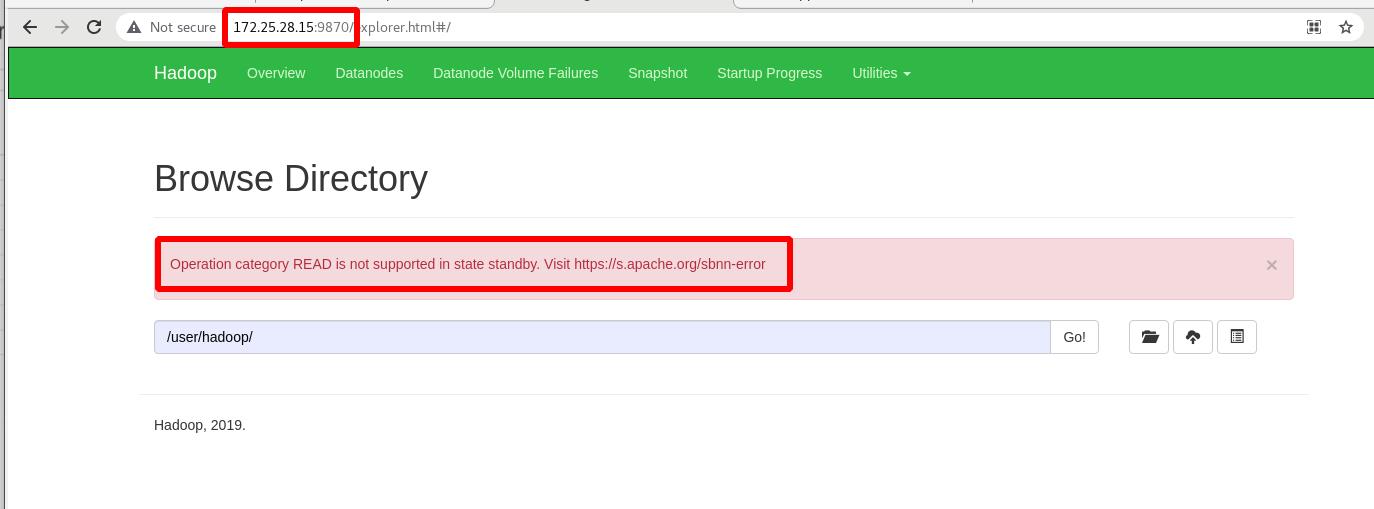
备机vm5无法查看
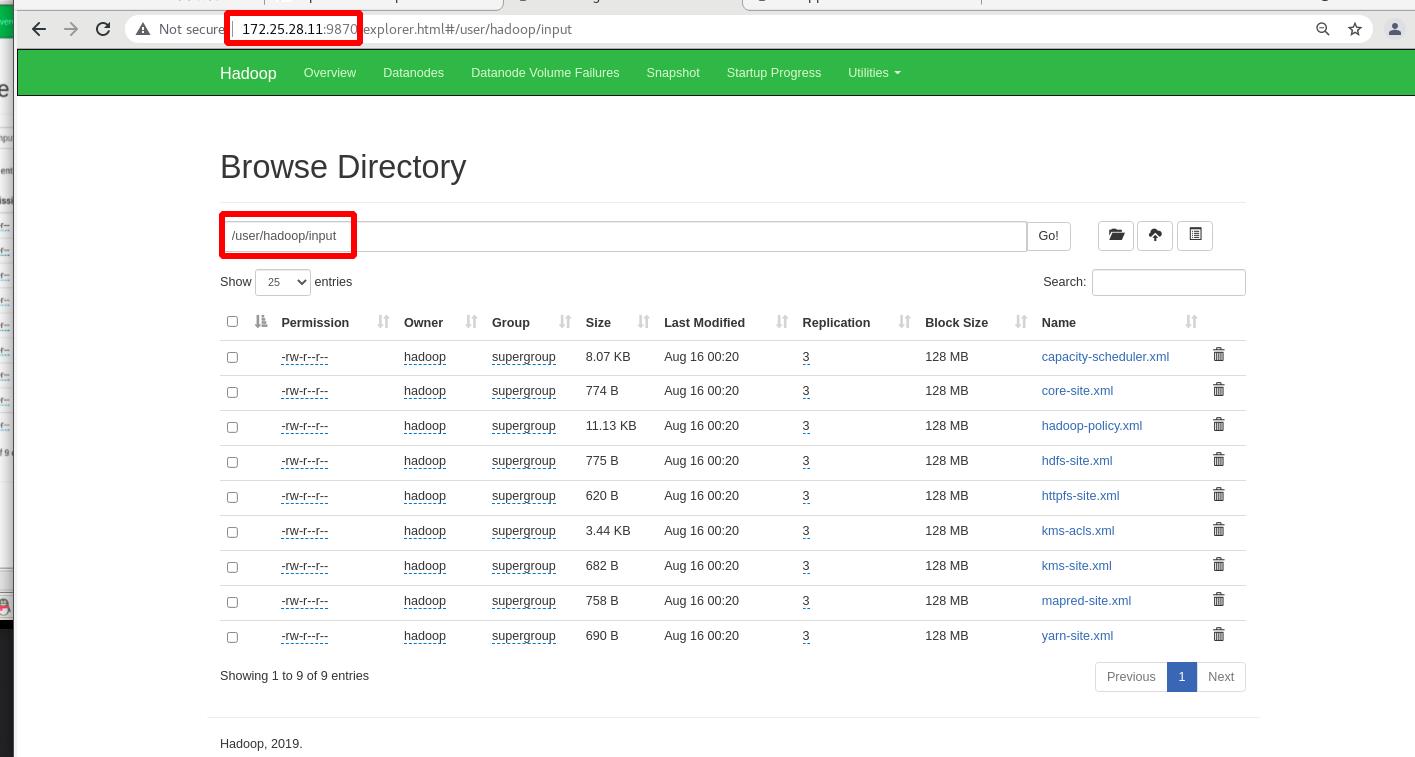
主机vm5无法查看
vm2,vm3,vm4 为hadoop集群
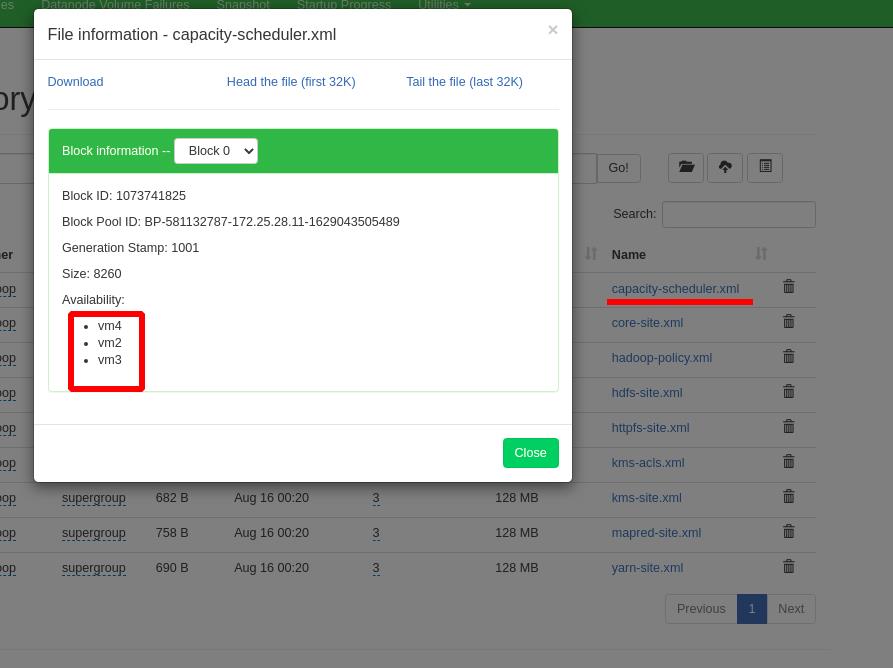 命令行方式查看分布式文件系统中的内容
命令行方式查看分布式文件系统中的内容
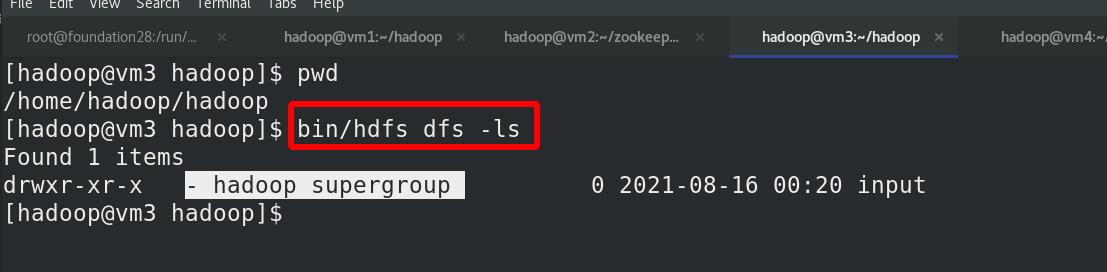
测试故障自动切换
杀死vm1的NameNode进程
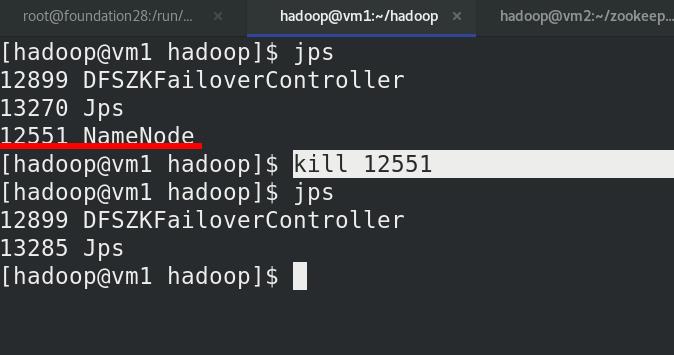
此时此时 h2 (vm5)转为 active 状态接管 namenode
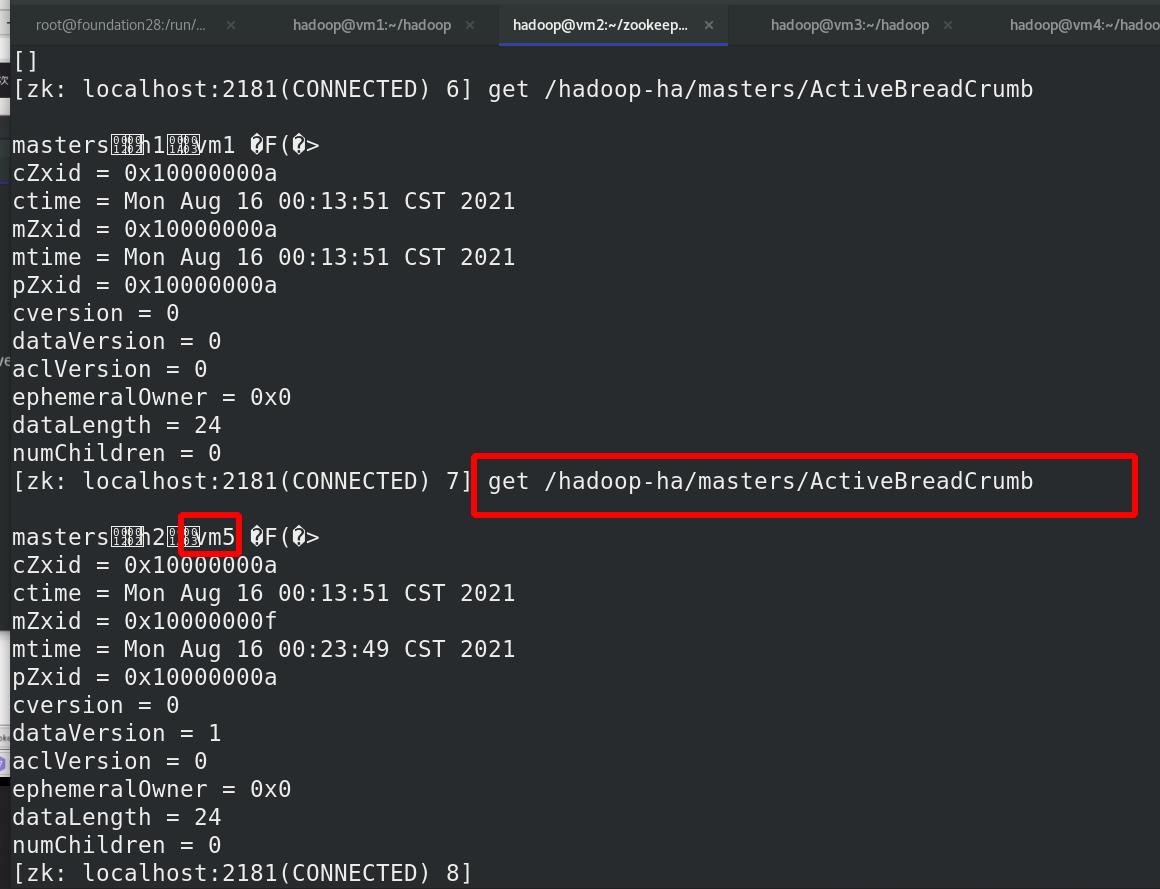 外部访问查看
外部访问查看
