一文搞懂反向传播算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文搞懂反向传播算法相关的知识,希望对你有一定的参考价值。
参考技术A 这是一场以误差(Error)为主导的反向传播(Back Propagation)运动,旨在得到最优的全局参数矩阵,进而将多层神经网络应用到分类或者回归任务中去。前向传递输入信号直至输出产生误差,反向传播误差信息更新权重矩阵。这两句话很好的形容了信息的流动方向,权重得以在信息双向流动中得到优化,这让我想到了北京城的夜景,车辆川流不息,车水马龙,你来我往(* ॑꒳ ॑* )⋆*。
至于为什么会提出反向传播算法,我直接应用梯度下降(Gradient Descent)不行吗?想必大家肯定有过这样的疑问。答案肯定是不行的,纵然梯度下降神通广大,但却不是万能的。梯度下降可以应对带有明确求导函数的情况,或者说可以应对那些可以求出误差的情况,比如逻辑回归(Logistic Regression),我们可以把它看做没有隐层的网络;但对于多隐层的神经网络,输出层可以直接求出误差来更新参数,但其中隐层的误差是不存在的,因此不能对它直接应用梯度下降,而是先将误差反向传播至隐层,然后再应用梯度下降,其中将误差从末层往前传递的过程需要链式法则(Chain Rule)的帮助,因此反向传播算法可以说是梯度下降在链式法则中的应用。
为了帮助较好的理解反向传播概念,对它有一个直观的理解,接下来就拿猜数字游戏举个栗子。
这一过程类比没有隐层的神经网络,比如逻辑回归,其中小黄帽代表输出层节点,左侧接受输入信号,右侧产生输出结果,小蓝猫则代表了误差,指导参数往更优的方向调整。由于小蓝猫可以直接将误差反馈给小黄帽,同时只有一个参数矩阵和小黄帽直接相连,所以可以直接通过误差进行参数优化(实纵线),迭代几轮,误差会降低到最小。
这一过程类比带有一个隐层的三层神经网络,其中小女孩代表隐藏层节点,小黄帽依然代表输出层节点,小女孩左侧接受输入信号,经过隐层节点产生输出结果,小蓝猫代表了误差,指导参数往更优的方向调整。由于小蓝猫可以直接将误差反馈给小黄帽,所以与小黄帽直接相连的左侧参数矩阵可以直接通过误差进行参数优化(实纵线);而与小女孩直接相连的左侧参数矩阵由于不能得到小蓝猫的直接反馈而不能直接被优化(虚棕线)。但由于反向传播算法使得小蓝猫的反馈可以被传递到小女孩那进而产生间接误差,所以与小女孩直接相连的左侧权重矩阵可以通过间接误差得到权重更新,迭代几轮,误差会降低到最小。
上边的栗子从直观角度了解了反向传播,接下来就详细的介绍其中两个流程前向传播与反向传播,在介绍之前先统一一下标记。
如何将输入层的信号传输至隐藏层呢,以隐藏层节点c为例,站在节点c上往后看(输入层的方向),可以看到有两个箭头指向节点c,因此a,b节点的信息将传递给c,同时每个箭头有一定的权重,因此对于c节点来说,输入信号为:
同理,节点d的输入信号为:
由于计算机善于做带有循环的任务,因此我们可以用矩阵相乘来表示:
所以,隐藏层节点经过非线性变换后的输出表示如下:
同理,输出层的输入信号表示为权重矩阵乘以上一层的输出:
同样,输出层节点经过非线性映射后的最终输出表示为:
输入信号在权重矩阵们的帮助下,得到每一层的输出,最终到达输出层。可见,权重矩阵在前向传播信号的过程中扮演着运输兵的作用,起到承上启下的功能。
既然梯度下降需要每一层都有明确的误差才能更新参数,所以接下来的重点是如何将输出层的误差反向传播给隐藏层。
其中输出层、隐藏层节点的误差如图所示,输出层误差已知,接下来对隐藏层第一个节点c作误差分析。还是站在节点c上,不同的是这次是往前看(输出层的方向),可以看到指向c节点的两个蓝色粗箭头是从节点e和节点f开始的,因此对于节点c的误差肯定是和输出层的节点e和f有关。
不难发现,输出层的节点e有箭头分别指向了隐藏层的节点c和d,因此对于隐藏节点e的误差不能被隐藏节点c霸为己有,而是要服从按劳分配的原则(按权重分配),同理节点f的误差也需服从这样的原则,因此对于隐藏层节点c的误差为:
同理,对于隐藏层节点d的误差为:
为了减少工作量,我们还是乐意写成矩阵相乘的形式:
你会发现这个矩阵比较繁琐,如果能够简化到前向传播那样的形式就更好了。实际上我们可以这么来做,只要不破坏它们的比例就好,因此我们可以忽略掉分母部分,所以重新成矩阵形式为:
仔细观察,你会发现这个权重矩阵,其实是前向传播时权重矩阵w的转置,因此简写形式如下:
不难发现,输出层误差在转置权重矩阵的帮助下,传递到了隐藏层,这样我们就可以利用间接误差来更新与隐藏层相连的权重矩阵。可见,权重矩阵在反向传播的过程中同样扮演着运输兵的作用,只不过这次是搬运的输出误差,而不是输入信号(我们不生产误差,只是误差的搬运工(っ̯ -。))。
第三部分大致介绍了输入信息的前向传播与输出误差的后向传播,接下来就根据求得的误差来更新参数。
首先对隐藏层的w11进行参数更新,更新之前让我们从后往前推导,直到预见w11为止:
因此误差对w11求偏导如下:
求导得如下公式(所有值已知):
同理,误差对于w12的偏导如下:
同样,求导得w12的求值公式:
同理,误差对于偏置求偏导如下:
带入上述公式为:
接着对输入层的w11进行参数更新,更新之前我们依然从后往前推导,直到预见第一层的w11为止(只不过这次需要往前推的更久一些):
因此误差对输入层的w11求偏导如下:
同理,输入层的其他三个参数按照同样的方法即可求出各自的偏导,在这不再赘述。
在每个参数偏导数明确的情况下,带入梯度下降公式即可(不在重点介绍):
至此,利用链式法则来对每层参数进行更新的任务已经完成。
利用链式法则来更新权重你会发现其实这个方法简单,但过于冗长。由于更新的过程可以看做是从网络的输入层到输出层从前往后更新,每次更新的时候都需要重新计算节点的误差,因此会存在一些不必要的重复计算。其实对于已经计算完毕的节点我们完全可以直接拿来用,因此我们可以重新看待这个问题,从后往前更新。先更新后边的权重,之后再在此基础上利用更新后边的权重产生的中间值来更新较靠前的参数。这个中间变量就是下文要介绍的delta变量,一来简化公式,二来减少计算量,有点动态规划的赶脚。
接下来用事实说话,大家仔细观察一下在第四部分链式求导部分误差对于输出层的w11以及隐藏层的w11求偏导以及偏置的求偏导的过程,你会发现,三个公式存在相同的部分,同时隐藏层参数求偏导的过程会用到输出层参数求偏导的部分公式,这正是引入了中间变量delta的原因(其实红框的公式就是delta的定义)。
大家看一下经典书籍《神经网络与深度学习》中对于delta的描述为在第l层第j个神经元上的误差,定义为误差对于当前带权输入求偏导,数学公式如下:
因此输出层的误差可以表示为(上图红色框公式):
隐藏层的误差可以表示为(上图蓝色框公式):
同时对于权重更新的表示为(上图绿色框公式):
其实对于偏置的更新表示为(上图红色框):
上述4个公式其实就是《神经网络与深度学习》书中传说的反向传播4大公式(详细推导证明可移步此书):
仔细观察,你会发现BP1与BP2相结合就能发挥出最大功效,可以计算出任意层的误差,只要首先利用BP1公式计算出输出层误差,然后利用BP2层层传递,就无敌了,这也正是误差反向传播算法的缘由吧。同时对于权重w以及偏置b我们就可以通过BP3和BP4公式来计算了。
至此,我们介绍了反向传播的相关知识,一开始看反向传播资料的时候总觉得相对独立,这个教材这么讲,另一篇博客又换一个讲法,始终不能很好的理解其中的含义,到目前为止,思路相对清晰。我们先从大致流程上介绍了反向传播的来龙去脉,接着用链式求导法则来计算权重以及偏置的偏导,进而我们推出了跟经典著作一样样儿的结论,因此本人觉得较为详细,应该对初学者有一定的借鉴意义,希望对大家有所帮助。
Nielsen M A. Neural networks and deep learning[M]. 2015.
Rashid T. Make your own neural network[M]. CreateSpace IndependentPublishing Platform, 2016.
一文弄懂神经网络中的反向传播法——BackPropagation
最近在看深度学习的东西,一开始看的吴恩达的UFLDL教程,有中文版就直接看了,后来发现有些地方总是不是很明确,又去看英文版,然后又找了些资料看,才发现,中文版的译者在翻译的时候会对省略的公式推导过程进行补充,但是补充的又是错的,难怪觉得有问题。反向传播法其实是神经网络的基础了,但是很多人在学的时候总是会遇到一些问题,或者看到大篇的公式觉得好像很难就退缩了,其实不难,就是一个链式求导法则反复用。如果不想看公式,可以直接把数值带进去,实际的计算一下,体会一下这个过程之后再来推导公式,这样就会觉得很容易了。
说到神经网络,大家看到这个图应该不陌生:
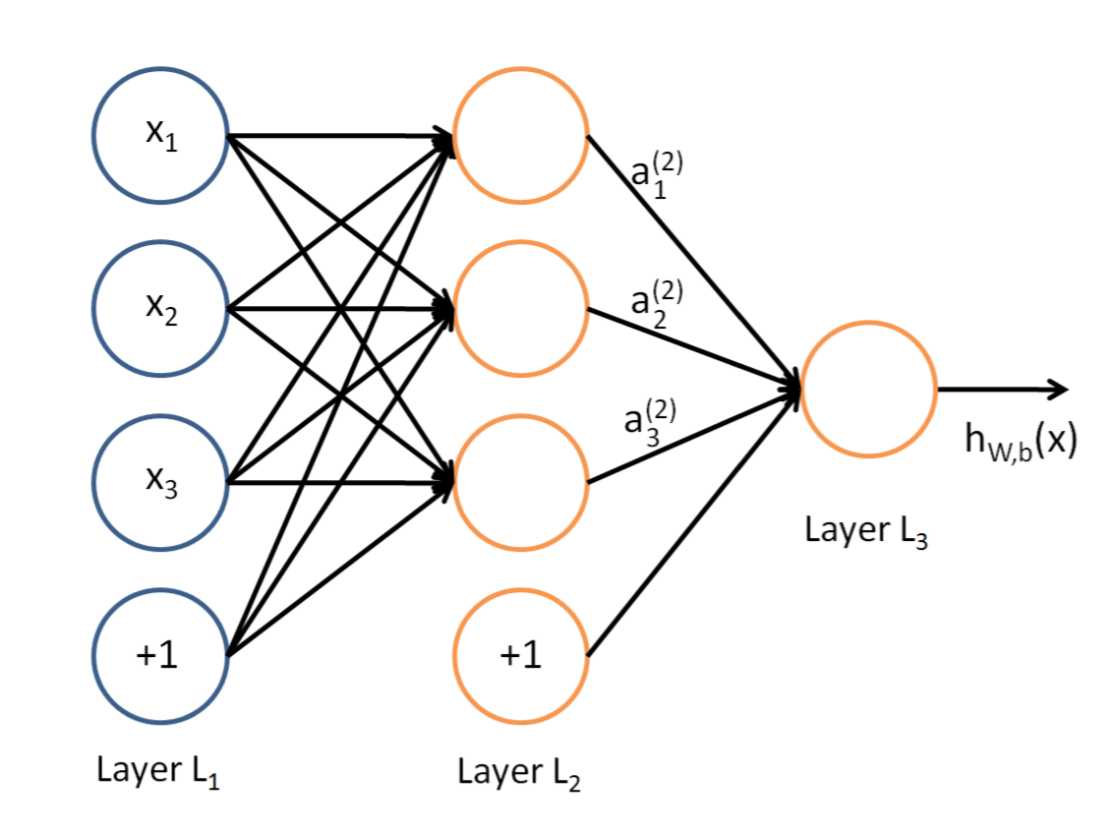
这是典型的三层神经网络的基本构成,Layer L1是输入层,Layer L2是隐含层,Layer L3是隐含层,我们现在手里有一堆数据{x1,x2,x3,...,xn},输出也是一堆数据{y1,y2,y3,...,yn},现在要他们在隐含层做某种变换,让你把数据灌进去后得到你期望的输出。如果你希望你的输出和原始输入一样,那么就是最常见的自编码模型(Auto-Encoder)。可能有人会问,为什么要输入输出都一样呢?有什么用啊?其实应用挺广的,在图像识别,文本分类等等都会用到,我会专门再写一篇Auto-Encoder的文章来说明,包括一些变种之类的。如果你的输出和原始输入不一样,那么就是很常见的人工神经网络了,相当于让原始数据通过一个映射来得到我们想要的输出数据,也就是我们今天要讲的话题。
本文直接举一个例子,带入数值演示反向传播法的过程,公式的推导等到下次写Auto-Encoder的时候再写,其实也很简单,感兴趣的同学可以自己推导下试试:)(注:本文假设你已经懂得基本的神经网络构成,如果完全不懂,可以参考Poll写的笔记:[Mechine Learning & Algorithm] 神经网络基础)
假设,你有这样一个网络层:
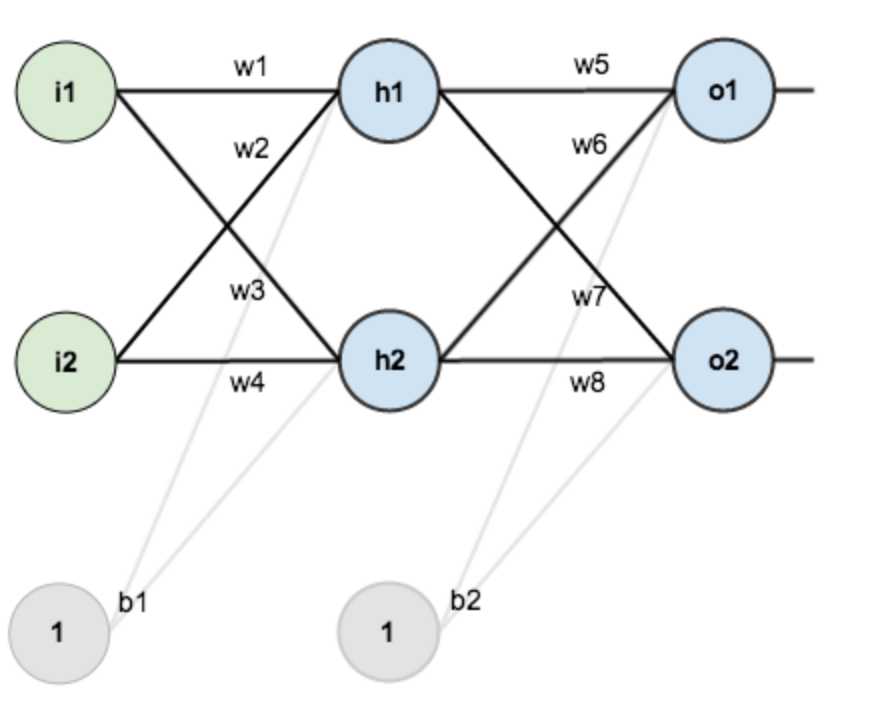
第一层是输入层,包含两个神经元i1,i2,和截距项b1;第二层是隐含层,包含两个神经元h1,h2和截距项b2,第三层是输出o1,o2,每条线上标的wi是层与层之间连接的权重,激活函数我们默认为sigmoid函数。
现在对他们赋上初值,如下图:
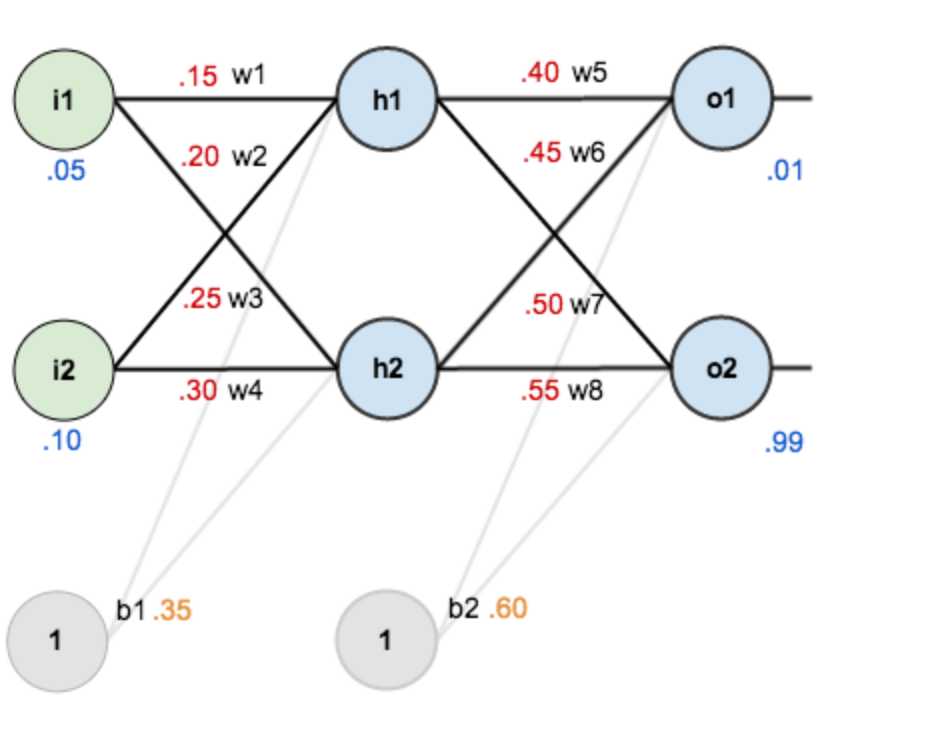
其中,输入数据 i1=0.05,i2=0.10;
输出数据 o1=0.01,o2=0.99;
初始权重 w1=0.15,w2=0.20,w3=0.25,w4=0.30;
w5=0.40,w6=0.45,w7=0.50,w8=0.55
目标:给出输入数据i1,i2(0.05和0.10),使输出尽可能与原始输出o1,o2(0.01和0.99)接近。
Step 1 前向传播
1.输入层---->隐含层:
计算神经元h1的输入加权和:
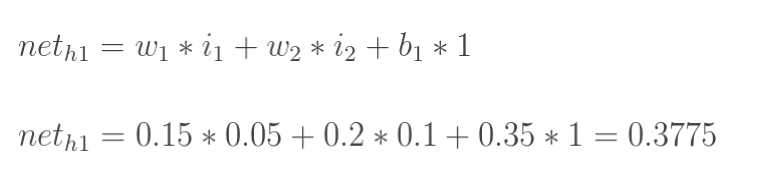
神经元h1的输出o1:(此处用到激活函数为sigmoid函数):
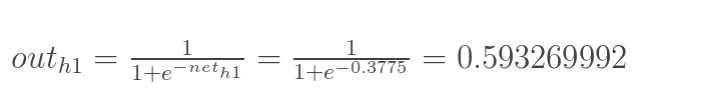
同理,可计算出神经元h2的输出o2:
![]()
2.隐含层---->输出层:
计算输出层神经元o1和o2的值:
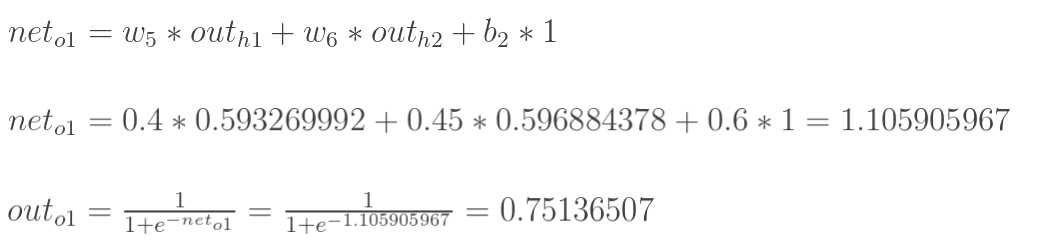
![]()
这样前向传播的过程就结束了,我们得到输出值为[0.75136079 , 0.772928465],与实际值[0.01 , 0.99]相差还很远,现在我们对误差进行反向传播,更新权值,重新计算输出。
Step 2 反向传播
1.计算总误差
总误差:(square error)

但是有两个输出,所以分别计算o1和o2的误差,总误差为两者之和:
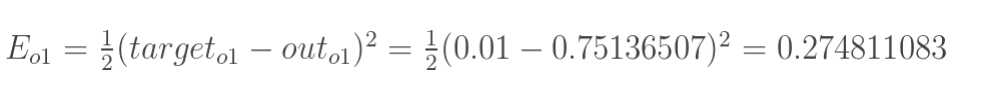

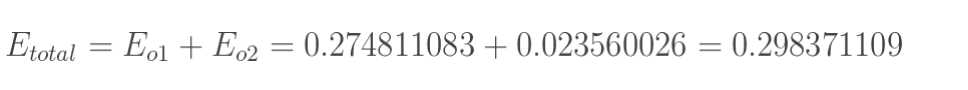
2.隐含层---->输出层的权值更新:
以权重参数w5为例,如果我们想知道w5对整体误差产生了多少影响,可以用整体误差对w5求偏导求出:(链式法则)
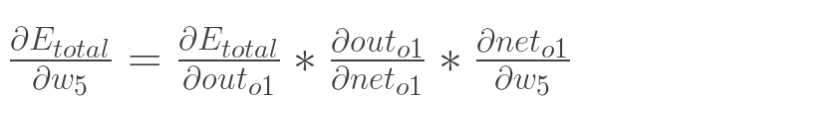
下面的图可以更直观的看清楚误差是怎样反向传播的:
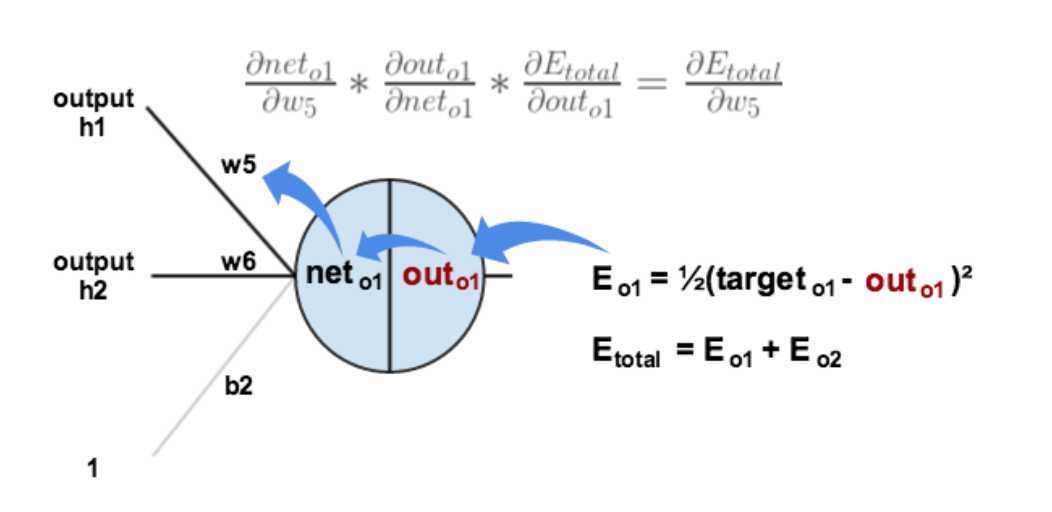
现在我们来分别计算每个式子的值:
计算![]() :
:
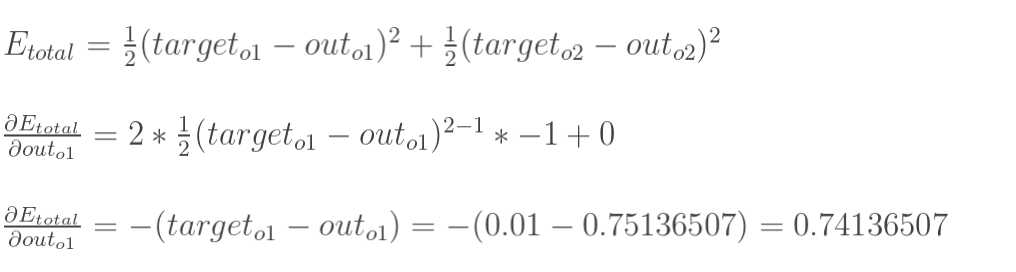
计算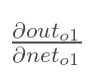 :
:

(这一步实际上就是对sigmoid函数求导,比较简单,可以自己推导一下)
计算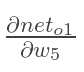 :
:
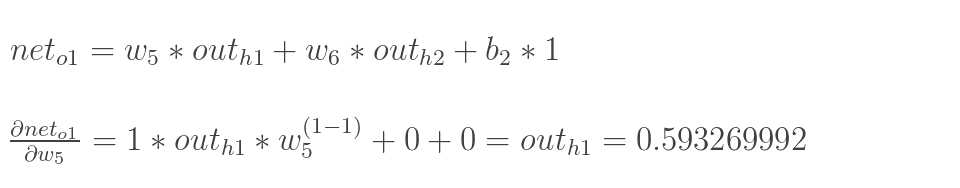
最后三者相乘:

这样我们就计算出整体误差E(total)对w5的偏导值。
回过头来再看看上面的公式,我们发现:
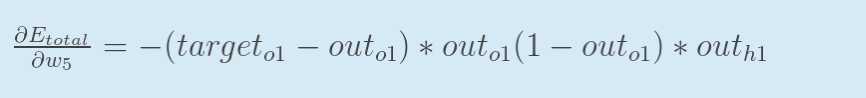
为了表达方便,用![]() 来表示输出层的误差:
来表示输出层的误差:
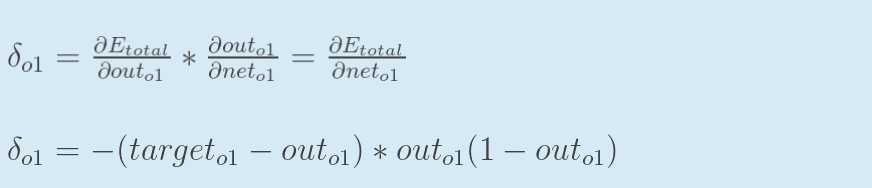
因此,整体误差E(total)对w5的偏导公式可以写成:

如果输出层误差计为负的话,也可以写成:

最后我们来更新w5的值:
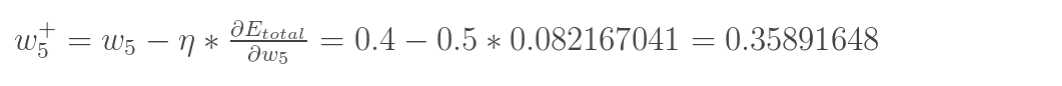
(其中,![]() 是学习速率,这里我们取0.5)
是学习速率,这里我们取0.5)
同理,可更新w6,w7,w8:

3.隐含层---->隐含层的权值更新:
方法其实与上面说的差不多,但是有个地方需要变一下,在上文计算总误差对w5的偏导时,是从out(o1)---->net(o1)---->w5,但是在隐含层之间的权值更新时,是out(h1)---->net(h1)---->w1,而out(h1)会接受E(o1)和E(o2)两个地方传来的误差,所以这个地方两个都要计算。
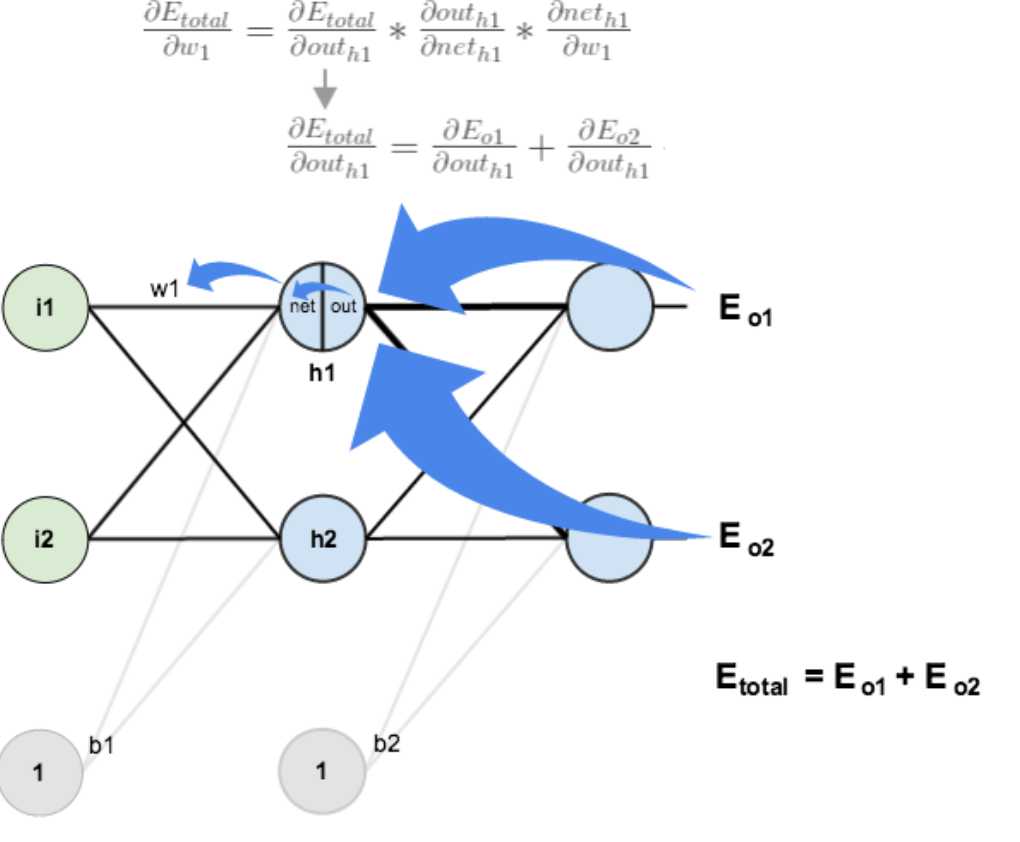
计算![]() :
:

先计算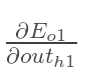 :
:
![]()
![]()
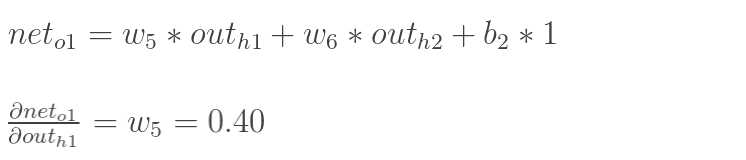
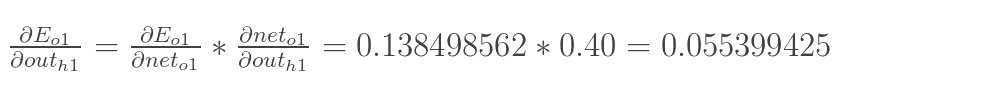
同理,计算出:
![]()
两者相加得到总值:
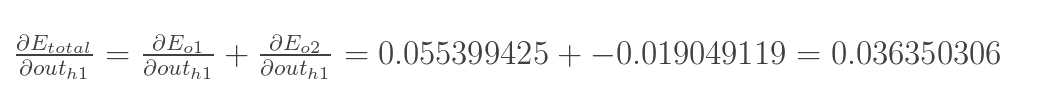
再计算![]() :
:

再计算![]() :
:
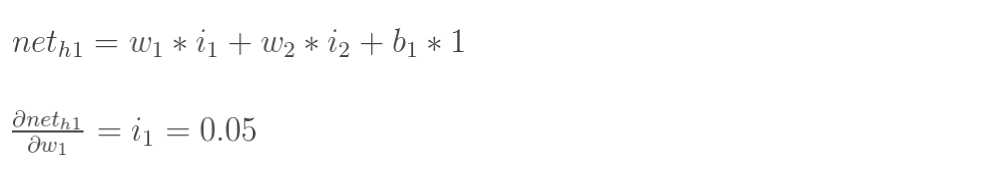
最后,三者相乘:
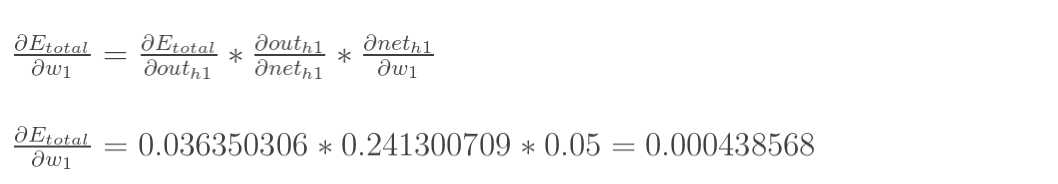
为了简化公式,用sigma(h1)表示隐含层单元h1的误差:
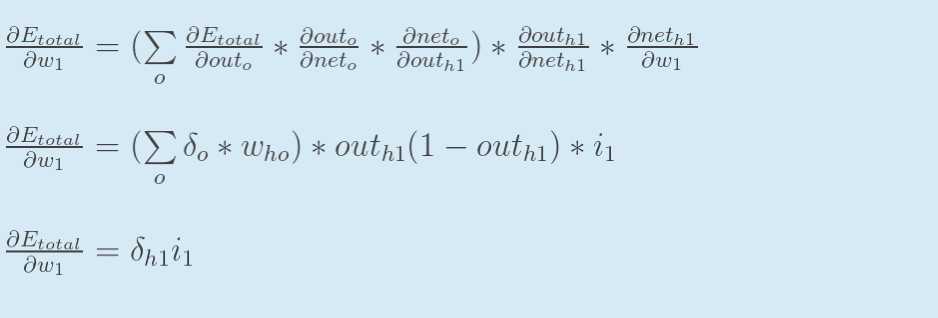
最后,更新w1的权值:
![]()
同理,额可更新w2,w3,w4的权值:

这样误差反向传播法就完成了,最后我们再把更新的权值重新计算,不停地迭代,在这个例子中第一次迭代之后,总误差E(total)由0.298371109下降至0.291027924。迭代10000次后,总误差为0.000035085,输出为[0.015912196,0.984065734](原输入为[0.01,0.99]),证明效果还是不错的。
代码(Python):

1 #coding:utf-8
2 import random
3 import math
4
5 #
6 # 参数解释:
7 # "pd_" :偏导的前缀
8 # "d_" :导数的前缀
9 # "w_ho" :隐含层到输出层的权重系数索引
10 # "w_ih" :输入层到隐含层的权重系数的索引
11
12 class NeuralNetwork:
13 LEARNING_RATE = 0.5
14
15 def __init__(self, num_inputs, num_hidden, num_outputs, hidden_layer_weights = None, hidden_layer_bias = None, output_layer_weights = None, output_layer_bias = None):
16 self.num_inputs = num_inputs
17
18 self.hidden_layer = NeuronLayer(num_hidden, hidden_layer_bias)
19 self.output_layer = NeuronLayer(num_outputs, output_layer_bias)
20
21 self.init_weights_from_inputs_to_hidden_layer_neurons(hidden_layer_weights)
22 self.init_weights_from_hidden_layer_neurons_to_output_layer_neurons(output_layer_weights)
23
24 def init_weights_from_inputs_to_hidden_layer_neurons(self, hidden_layer_weights):
25 weight_num = 0
26 for h in range(len(self.hidden_layer.neurons)):
27 for i in range(self.num_inputs):
28 if not hidden_layer_weights:
29 self.hidden_layer.neurons[h].weights.append(random.random())
30 else:
31 self.hidden_layer.neurons[h].weights.append(hidden_layer_weights[weight_num])
32 weight_num += 1
33
34 def init_weights_from_hidden_layer_neurons_to_output_layer_neurons(self, output_layer_weights):
35 weight_num = 0
36 for o in range(len(self.output_layer.neurons)):
37 for h in range(len(self.hidden_layer.neurons)):
38 if not output_layer_weights:
39 self.output_layer.neurons[o].weights.append(random.random())
40 else:
41 self.output_layer.neurons[o].weights.append(output_layer_weights[weight_num])
42 weight_num += 1
43
44 def inspect(self):
45 print(‘------‘)
46 print(‘* Inputs: {}‘.format(self.num_inputs))
47 print(‘------‘)
48 print(‘Hidden Layer‘)
49 self.hidden_layer.inspect()
50 print(‘------‘)
51 print(‘* Output Layer‘)
52 self.output_layer.inspect()
53 print(‘------‘)
54
55 def feed_forward(self, inputs):
56 hidden_layer_outputs = self.hidden_layer.feed_forward(inputs)
57 return self.output_layer.feed_forward(hidden_layer_outputs)
58
59 def train(self, training_inputs, training_outputs):
60 self.feed_forward(training_inputs)
61
62 # 1. 输出神经元的值
63 pd_errors_wrt_output_neuron_total_net_input = [0] * len(self.output_layer.neurons)
64 for o in range(len(self.output_layer.neurons)):
65
66 # ∂E/∂z?
67 pd_errors_wrt_output_neuron_total_net_input[o] = self.output_layer.neurons[o].calculate_pd_error_wrt_total_net_input(training_outputs[o])
68
69 # 2. 隐含层神经元的值
70 pd_errors_wrt_hidden_neuron_total_net_input = [0] * len(self.hidden_layer.neurons)
71 for h in range(len(self.hidden_layer.neurons)):
72
73 # dE/dy? = Σ ∂E/∂z? * ∂z/∂y? = Σ ∂E/∂z? * w??
74 d_error_wrt_hidden_neuron_output = 0
75 for o in range(len(self.output_layer.neurons)):
76 d_error_wrt_hidden_neuron_output += pd_errors_wrt_output_neuron_total_net_input[o] * self.output_layer.neurons[o].weights[h]
77
78 # ∂E/∂z? = dE/dy? * ∂z?/∂
79 pd_errors_wrt_hidden_neuron_total_net_input[h] = d_error_wrt_hidden_neuron_output * self.hidden_layer.neurons[h].calculate_pd_total_net_input_wrt_input()
80
81 # 3. 更新输出层权重系数
82 for o in range(len(self.output_layer.neurons)):
83 for w_ho in range(len(self.output_layer.neurons[o].weights)):
84
85 # ∂E?/∂w?? = ∂E/∂z? * ∂z?/∂w??
86 pd_error_wrt_weight = pd_errors_wrt_output_neuron_total_net_input[o] * self.output_layer.neurons[o].calculate_pd_total_net_input_wrt_weight(w_ho)
87
88 # Δw = α * ∂E?/∂w?
89 self.output_layer.neurons[o].weights[w_ho] -= self.LEARNING_RATE * pd_error_wrt_weight
90
91 # 4. 更新隐含层的权重系数
92 for h in range(len(self.hidden_layer.neurons)):
93 for w_ih in range(len(self.hidden_layer.neurons[h].weights)):
94
95 # ∂E?/∂w? = ∂E/∂z? * ∂z?/∂w?
96 pd_error_wrt_weight = pd_errors_wrt_hidden_neuron_total_net_input[h] * self.hidden_layer.neurons[h].calculate_pd_total_net_input_wrt_weight(w_ih)
97
98 # Δw = α * ∂E?/∂w?
99 self.hidden_layer.neurons[h].weights[w_ih] -= self.LEARNING_RATE * pd_error_wrt_weight
100
101 def calculate_total_error(self, training_sets):
102 total_error = 0
103 for t in range(len(training_sets)):
104 training_inputs, training_outputs = training_sets[t]
105 self.feed_forward(training_inputs)
106 for o in range(len(training_outputs)):
107 total_error += self.output_layer.neurons[o].calculate_error(training_outputs[o])
108 return total_error
109
110 class NeuronLayer:
111 def __init__(self, num_neurons, bias):
112
113 # 同一层的神经元共享一个截距项b
114 self.bias = bias if bias else random.random()
115
116 self.neurons = []
117 for i in range(num_neurons):
118 self.neurons.append(Neuron(self.bias))
119
120 def inspect(self):
121 print(‘Neurons:‘, len(self.neurons))
122 for n in range(len(self.neurons)):
123 print(‘ Neuron‘, n)
124 for w in range(len(self.neurons[n].weights)):
125 print(‘ Weight:‘, self.neurons[n].weights[w])
126 print(‘ Bias:‘, self.bias)
127
128 def feed_forward(self, inputs):
129 outputs = []
130 for neuron in self.neurons:
131 outputs.append(neuron.calculate_output(inputs))
132 return outputs
133
134 def get_outputs(self):
135 outputs = []
136 for neuron in self.neurons:
137 outputs.append(neuron.output)
138 return outputs
139
140 class Neuron:
141 def __init__(self, bias):
142 self.bias = bias
143 self.weights = []
144
145 def calculate_output(self, inputs):
146 self.inputs = inputs
147 self.output = self.squash(self.calculate_total_net_input())
148 return self.output
149
150 def calculate_total_net_input(self):
151 total = 0
152 for i in range(len(self.inputs)):
153 total += self.inputs[i] * self.weights[i]
154 return total + self.bias
155
156 # 激活函数sigmoid
157 def squash(self, total_net_input):
158 return 1 / (1 + math.exp(-total_net_input))
159
160
161 def calculate_pd_error_wrt_total_net_input(self, target_output):
162 return self.calculate_pd_error_wrt_output(target_output) * self.calculate_pd_total_net_input_wrt_input();
163
164 # 每一个神经元的误差是由平方差公式计算的
165 def calculate_error(self, target_output):
166 return 0.5 * (target_output - self.output) ** 2
167
168
169 def calculate_pd_error_wrt_output(self, target_output):
170 return -(target_output - self.output)
171
172
173 def calculate_pd_total_net_input_wrt_input(self):
174 return self.output * (1 - self.output)
175
176
177 def calculate_pd_total_net_input_wrt_weight(self, index):
178 return self.inputs[index]
179
180
181 # 文中的例子:
182
183 nn = NeuralNetwork(2, 2, 2, hidden_layer_weights=[0.15, 0.2, 0.25, 0.3], hidden_layer_bias=0.35, output_layer_weights=[0.4, 0.45, 0.5, 0.55], output_layer_bias=0.6)
184 for i in range(10000):
185 nn.train([0.05, 0.1], [0.01, 0.09])
186 print(i, round(nn.calculate_total_error([[[0.05, 0.1], [0.01, 0.09]]]), 9))
187
188
189 #另外一个例子,可以把上面的例子注释掉再运行一下:
190
191 # training_sets = [
192 # [[0, 0], [0]],
193 # [[0, 1], [1]],
194 # [[1, 0], [1]],
195 # [[1, 1], [0]]
196 # ]
197
198 # nn = NeuralNetwork(len(training_sets[0][0]), 5, len(training_sets[0][1]))
199 # for i in range(10000):
200 # training_inputs, training_outputs = random.choice(training_sets)
201 # nn.train(training_inputs, training_outputs)
202 # print(i, nn.calculate_total_error(training_sets))
最后写到这里就结束了,现在还不会用latex编辑数学公式,本来都直接想写在草稿纸上然后扫描了传上来,但是觉得太影响阅读体验了。以后会用公式编辑器后再重把公式重新编辑一遍。稳重使用的是sigmoid激活函数,实际还有几种不同的激活函数可以选择,具体的可以参考文献[3],最后推荐一个在线演示神经网络变化的网址:http://www.emergentmind.com/neural-network,可以自己填输入输出,然后观看每一次迭代权值的变化,很好玩~如果有错误的或者不懂的欢迎留言:)
参考文献:
1.Poll的笔记:[Mechine Learning & Algorithm] 神经网络基础(http://www.cnblogs.com/maybe2030/p/5597716.html#3457159 )
2.Rachel_Zhang:http://blog.csdn.net/abcjennifer/article/details/7758797
3.http://www.cedar.buffalo.edu/%7Esrihari/CSE574/Chap5/Chap5.3-BackProp.pdf
4.https://mattmazur.com/2015/03/17/a-step-by-step-backpropagation-example/
以上是关于一文搞懂反向传播算法的主要内容,如果未能解决你的问题,请参考以下文章