数据挖掘核心算法之一--回归
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘核心算法之一--回归相关的知识,希望对你有一定的参考价值。
数据挖掘核心算法之一--回归回归,是一个广义的概念,包含的基本概念是用一群变量预测另一个变量的方法,白话就是根据几件事情的相关程度,
参考技术A 数据挖掘核心算法之一--回归回归,是一个广义的概念,包含的基本概念是用一群变量预测另一个变量的方法,白话就是根据几件事情的相关程度,用其中几件来预测另一件事情发生的概率,最简单的即线性二变量问题(即简单线性),例如下午我老婆要买个包,我没买,那结果就是我肯定没有晚饭吃;复杂一点就是多变量(即多元线性,这里有一点要注意的,因为我最早以前犯过这个错误,就是认为预测变量越多越好,做模型的时候总希望选取几十个指标来预测,但是要知道,一方面,每增加一个变量,就相当于在这个变量上增加了误差,变相的扩大了整体误差,尤其当自变量选择不当的时候,影响更大,另一个方面,当选择的俩个自变量本身就是高度相关而不独立的时候,俩个指标相当于对结果造成了双倍的影响),还是上面那个例子,如果我丈母娘来了,那我老婆就有很大概率做饭;如果在加一个事件,如果我老丈人也来了,那我老婆肯定会做饭;为什么会有这些判断,因为这些都是以前多次发生的,所以我可以根据这几件事情来预测我老婆会不会做晚饭。
大数据时代的问题当然不能让你用肉眼看出来,不然要海量计算有啥用,所以除了上面那俩种回归,我们经常用的还有多项式回归,即模型的关系是n阶多项式;逻辑回归(类似方法包括决策树),即结果是分类变量的预测;泊松回归,即结果变量代表了频数;非线性回归、时间序列回归、自回归等等,太多了,这里主要讲几种常用的,好解释的(所有的模型我们都要注意一个问题,就是要好解释,不管是参数选择还是变量选择还是结果,因为模型建好了最终用的是业务人员,看结果的是老板,你要给他们解释,如果你说结果就是这样,我也不知道问什么,那升职加薪基本无望了),例如你发现日照时间和某地葡萄销量有正比关系,那你可能还要解释为什么有正比关系,进一步统计发现日照时间和葡萄的含糖量是相关的,即日照时间长葡萄好吃,另外日照时间和产量有关,日照时间长,产量大,价格自然低,结果是又便宜又好吃的葡萄销量肯定大。再举一个例子,某石油产地的咖啡销量增大,国际油价的就会下跌,这俩者有关系,你除了要告诉领导这俩者有关系,你还要去寻找为什么有关系,咖啡是提升工人精力的主要饮料,咖啡销量变大,跟踪发现工人的工作强度变大,石油运输出口增多,油价下跌和咖啡销量的关系就出来了(单纯的例子,不要多想,参考了一个根据遥感信息获取船舶信息来预测粮食价格的真实案例,感觉不够典型,就换一个,实际油价是人为操控地)。
回归利器--最小二乘法,牛逼数学家高斯用的(另一个法国数学家说自己先创立的,不过没办法,谁让高斯出名呢),这个方法主要就是根据样本数据,找到样本和预测的关系,使得预测和真实值之间的误差和最小;和我上面举的老婆做晚饭的例子类似,不过我那个例子在不确定的方面只说了大概率,但是到底多大概率,就是用最小二乘法把这个关系式写出来的,这里不讲最小二乘法和公式了,使用工具就可以了,基本所有的数据分析工具都提供了这个方法的函数,主要给大家讲一下之前的一个误区,最小二乘法在任何情况下都可以算出来一个等式,因为这个方法只是使误差和最小,所以哪怕是天大的误差,他只要是误差和里面最小的,就是该方法的结果,写到这里大家应该知道我要说什么了,就算自变量和因变量完全没有关系,该方法都会算出来一个结果,所以主要给大家讲一下最小二乘法对数据集的要求:
1、正态性:对于固定的自变量,因变量呈正态性,意思是对于同一个答案,大部分原因是集中的;做回归模型,用的就是大量的Y~X映射样本来回归,如果引起Y的样本很凌乱,那就无法回归
2、独立性:每个样本的Y都是相互独立的,这个很好理解,答案和答案之间不能有联系,就像掷硬币一样,如果第一次是反面,让你预测抛两次有反面的概率,那结果就没必要预测了
3、线性:就是X和Y是相关的,其实世间万物都是相关的,蝴蝶和龙卷风(还是海啸来着)都是有关的嘛,只是直接相关还是间接相关的关系,这里的相关是指自变量和因变量直接相关
4、同方差性:因变量的方差不随自变量的水平不同而变化。方差我在描述性统计量分析里面写过,表示的数据集的变异性,所以这里的要求就是结果的变异性是不变的,举例,脑袋轴了,想不出例子,画个图来说明。(我们希望每一个自变量对应的结果都是在一个尽量小的范围)
我们用回归方法建模,要尽量消除上述几点的影响,下面具体讲一下简单回归的流程(其他的其实都类似,能把这个讲清楚了,其他的也差不多):
first,找指标,找你要预测变量的相关指标(第一步应该是找你要预测什么变量,这个话题有点大,涉及你的业务目标,老板的目的,达到该目的最关键的业务指标等等,我们后续的话题在聊,这里先把方法讲清楚),找相关指标,标准做法是业务专家出一些指标,我们在测试这些指标哪些相关性高,但是我经历的大部分公司业务人员在建模初期是不靠谱的(真的不靠谱,没思路,没想法,没意见),所以我的做法是将该业务目的所有相关的指标都拿到(有时候上百个),然后跑一个相关性分析,在来个主成分分析,就过滤的差不多了,然后给业务专家看,这时候他们就有思路了(先要有东西激活他们),会给一些你想不到的指标。预测变量是最重要的,直接关系到你的结果和产出,所以这是一个多轮优化的过程。
第二,找数据,这个就不多说了,要么按照时间轴找(我认为比较好的方式,大部分是有规律的),要么按照横切面的方式,这个就意味横切面的不同点可能波动较大,要小心一点;同时对数据的基本处理要有,包括对极值的处理以及空值的处理。
第三, 建立回归模型,这步是最简单的,所有的挖掘工具都提供了各种回归方法,你的任务就是把前面准备的东西告诉计算机就可以了。
第四,检验和修改,我们用工具计算好的模型,都有各种假设检验的系数,你可以马上看到你这个模型的好坏,同时去修改和优化,这里主要就是涉及到一个查准率,表示预测的部分里面,真正正确的所占比例;另一个是查全率,表示了全部真正正确的例子,被预测到的概率;查准率和查全率一般情况下成反比,所以我们要找一个平衡点。
第五,解释,使用,这个就是见证奇迹的时刻了,见证前一般有很久时间,这个时间就是你给老板或者客户解释的时间了,解释为啥有这些变量,解释为啥我们选择这个平衡点(是因为业务力量不足还是其他的),为啥做了这么久出的东西这么差(这个就尴尬了)等等。
回归就先和大家聊这么多,下一轮给大家聊聊主成分分析和相关性分析的研究,然后在聊聊数据挖掘另一个利器--聚类。
Apriori算法详解之一相关概念和核心步骤
本文转载自,感谢原作者的辛苦分享
http://blog.csdn.net/lizhengnanhua/article/details/9061755
一、Apriori算法简介: Apriori算法是一种挖掘关联规则的频繁项集算法,其核心思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集。 Apriori(先验的,推测的)算法应用广泛,可用于消费市场价格分析,猜测顾客的消费习惯;网络安全领域中的入侵检测技术;可用在用于高校管理中,根据挖掘规则可以有效地辅助学校管理部门有针对性的开展贫困助学工作;也可用在移动通信领域中,指导运营商的业务运营和辅助业务提供商的决策制定。
二、挖掘步骤:
1.依据支持度找出所有频繁项集(频度)
2.依据置信度产生关联规则(强度)
三、基本概念
对于A->B
①支持度:P(A ∩ B),既有A又有B的概率
②置信度:
P(B|A),在A发生的事件中同时发生B的概率 p(AB)/P(A) 例如购物篮分析:牛奶 ⇒ 面包
例子:[支持度:3%,置信度:40%]
支持度3%:意味着3%顾客同时购买牛奶和面包
置信度40%:意味着购买牛奶的顾客40%也购买面包
③如果事件A中包含k个元素,那么称这个事件A为k项集事件A满足最小支持度阈值的事件称为频繁k项集。
④同时满足最小支持度阈值和最小置信度阈值的规则称为强规则
四、实现步骤
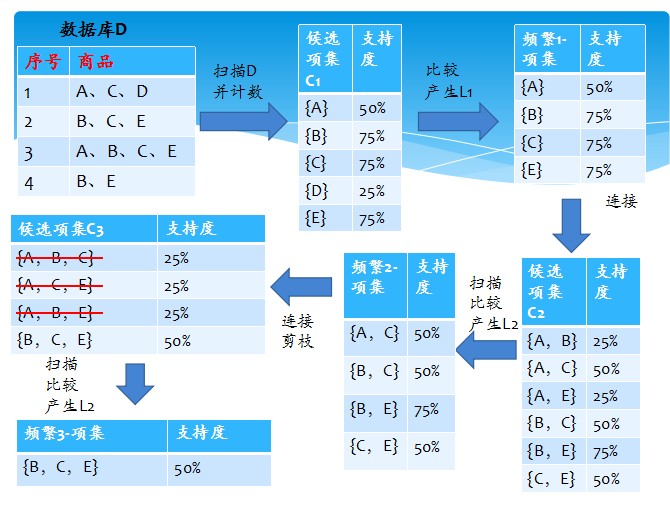
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法Apriori使用一种称作逐层搜索的迭代方法,“K-1项集”用于搜索“K项集”。
首先,找出频繁“1项集”的集合,该集合记作L1。L1用于找频繁“2项集”的集合L2,而L2用于找L3。如此下去,直到不能找到“K项集”。找每个Lk都需要一次数据库扫描。
核心思想是:连接步和剪枝步。连接步是自连接,原则是保证前k-2项相同,并按照字典顺序连接。剪枝步,是使任一频繁项集的所有非空子集也必须是频繁的。反之,如果某
个候选的非空子集不是频繁的,那么该候选肯定不是频繁的,从而可以将其从CK中删除。
简单的讲,1、发现频繁项集,过程为(1)扫描(2)计数(3)比较(4)产生频繁项集(5)连接、剪枝,产生候选项集 重复步骤(1)~(5)直到不能发现更大的频集
2、产生关联规则,过程为:根据前面提到的置信度的定义,关联规则的产生如下:
(1)对于每个频繁项集L,产生L的所有非空子集;
(2)对于L的每个非空子集S,如果
P(L)/P(S)≧min_conf
则输出规则“SàL-S”
注:L-S表示在项集L中除去S子集的项集
以上是关于数据挖掘核心算法之一--回归的主要内容,如果未能解决你的问题,请参考以下文章