Apache Druid的SQL查询使用手册
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Druid的SQL查询使用手册相关的知识,希望对你有一定的参考价值。
参考技术A [1] 书写使用说明[2] 支持查询
[3] 使用说明
[1] 聚合函数
[2] 数值函数
[3] 字符串函数
[4] 时间函数
[5] IP地址函数
[6] 比较运算符
[7] 多值的字符串函数
[8] HLL草图运算符
[9] Theta草图运算符
[10] 分位数草图运算符
[11] 其他功能
[12] 不支持的功能
[1] 没有聚合的查询将使用Druid的Scan本机查询类型。
[2] 近似算法
[1] 通过Http发送json
[2] JDBC
[1] 信息模式
[2] 系统模式
使用Druid SQL Parser解析SQL
文章目录
使用Druid SQL Parser解析SQL
在以前的博文《使用Spring Boot JPA Specification实现使用JSON数据来查询实体数据》中讲到了目前业务上的需求就是以前老系统是通过配置SQL去抽取一些业务数据的,但现在新系统想通过页面的一些配置化实现跟配置SQL一样去抽取数据。所以在之前的博文讲到了如何利用JPA Specification和构造的JSON数据去抽取数据。但是老系统很多历史数据都是用SQL去配置的,这些配置当然需要迁移到新系统,但是我们不可能手工一条条去把这些SQL转成当前的JSON结构,这样太浪费时间了。所以我的思路是解析这个SQL,然后去构造出需要的JSON结构。
当然如果你需要解析的SQL很复杂那其实就很麻烦了,但是因为我们的业务配置的SQL其实不算很复杂,而且只有单表的操作,而且SQL里面最多也就是有=,<>,>,<,>=,<=,like这种简单的操作,跟之前博文目前实现的操作是一样的。
所以基于这个前提,我们便需要有方法去解析SQL了。首先SQL本质上是一种数据处理的描述语言,是一种描述语言的规范。 如果我们用简单字符串处理,使用字符串查找或者正则表达式来提取SQL中的字段,对于简单的SQL可以这样实现,但SQL规范还有复杂的开闭括号以及嵌套查询,复杂SQL几乎不可能通过字符串匹配来实现。所以我们考虑使用已有的开源SQL解释器。
最终我选用的是Druid内置的SQL Parser, SQL Parser是Druid的一个重要组成部分,Druid内置使用SQL Parser来实现防御SQL注入(WallFilter)、合并统计没有参数化的SQL(StatFilter的mergeSql)、SQL格式化、分库分表。 而且官方强调:和Antlr生成的SQL有很大不同的是,Druid SQL Parser性能非常好,可以用于生产环境直接对SQL进行分析处理。
Druid SQL Parser的代码结构
Druid SQL Parser分三个模块:Parser,AST,Visitor
Parser
parser是将输入文本转换为ast(抽象语法树),parser有包括两个部分,Parser和Lexer,其中Lexer实现词法分析,Parser实现语法分析。
AST
AST是abstract syntax tree的缩写,也就是抽象语法树。和所有的Parser一样,Druid Parser会生成一个抽象语法树。
在Druid Parser中可以通过如下方式生成AST
final String dbType = JdbcConstants.MYSQL; // 可以是ORACLE、POSTGRESQL、SQLSERVER、ODPS等
String sql = "select * from t";
// SQLStatement就是AST
List<SQLStatement> stmtList = SQLUtils.parseStatements(sql, dbType);
当然在使用之前不要忘记了加入依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.6</version>
<scope>test</scope>
</dependency>
在Druid SQL Parser中有哪些AST节点类型?
在Druid中,AST节点类型主要包括SQLObject、SQLExpr、SQLStatement三种抽象类型。
package com.alibaba.druid.sql.ast;
interface SQLObject
interface SQLExpr extends SQLObject // 条件表达式相关的抽象,例如 ID = 3 这里的ID是一个SQLIdentifierExpr
interface SQLStatement extends SQLObject //最常用的Statement当然是SELECT/UPDATE/DELETE/INSERT,他们分别是SQLSelectStatement ,SQLUpdateStatement ,SQLDeleteStatement ,SQLInsertStatement
interface SQLTableSource extends SQLObject //常见的SQLTableSource包括SQLExprTableSource、SQLJoinTableSource、SQLSubqueryTableSource、SQLWithSubqueryClause.Entry
class SQLSelect extends SQLObject
class SQLSelectQueryBlock extends SQLObject //SQLSelectStatement包含一个SQLSelect,SQLSelect包含一个SQLSelectQuery,都是组成的关系。SQLSelectQuery有主要的两个派生类,分别是SQLSelectQueryBlock和SQLUnionQuery。
具体的类型和作用可以参考:在Druid SQL Parser中有哪些AST节点类型?
我这里不会介绍太多AST节点类型,我这里主要关注在SQLExpr, 因为这个跟条件表达式相关的解析,比如我们条件中的ID = 3,但我们需要解析这个条件表达式的时候会用到SQLExpr
常用的SQLExpr有哪些?
我们这里直接看官网的例子:
package com.alibaba.druid.sql.ast.expr;
// SQLName是一种的SQLExpr的Expr,包括SQLIdentifierExpr、SQLPropertyExpr等
public interface SQLName extends SQLExpr
// 例如 ID = 3 这里的ID是一个SQLIdentifierExpr
class SQLIdentifierExpr implements SQLExpr, SQLName
String name;
// 例如 A.ID = 3 这里的A.ID是一个SQLPropertyExpr
class SQLPropertyExpr implements SQLExpr, SQLName
SQLExpr owner;
String name;
// 例如 ID = 3 这是一个SQLBinaryOpExpr
// left是ID (SQLIdentifierExpr)
// right是3 (SQLIntegerExpr)
class SQLBinaryOpExpr implements SQLExpr
SQLExpr left;
SQLExpr right;
SQLBinaryOperator operator;
// 例如 select * from where id = ?,这里的?是一个SQLVariantRefExpr,name是'?'
class SQLVariantRefExpr extends SQLExprImpl
String name;
// 例如 ID = 3 这里的3是一个SQLIntegerExpr
public class SQLIntegerExpr extends SQLNumericLiteralExpr implements SQLValuableExpr
Number number;
// 所有实现了SQLValuableExpr接口的SQLExpr都可以直接调用这个方法求值
@Override
public Object getValue()
return this.number;
// 例如 NAME = 'jobs' 这里的'jobs'是一个SQLCharExpr
public class SQLCharExpr extends SQLTextLiteralExpr implements SQLValuableExpr
String text;
我们来写一个具体的例子看看
String sql = "select * from t where id = 1";
List<SQLStatement> sqlStatements = SQLUtils.parseStatements(sql, JdbcConstants.MYSQL);
最后我们debugger看最后的结果

看到这个结果的AST,是不是对上面AST节点类型有一定的了解了。
当然上面的写法也可以写成下面这种:
String sql = "select * from t where id = 1";
SQLStatementParser parser = new MySqlStatementParser(sql);
SQLStatement sqlStatement = parser.parseStatement();
同时我们还可以通过SQLUtils产生SQLExpr,看下面的示例:
SQLExpr sqlExpr = SQLUtils.toSQLExpr("id=1", JdbcConstants.MYSQL);

甚至可以写更加复杂的表达式
SQLExpr sqlExpr = SQLUtils.toSQLExpr("(id=1 or name='test' and age=14)", JdbcConstants.MYSQL);

从最终的结果可以看出来,其实就是一个二叉树,父结点就是一个操作符,然后左右孩子结点就是表达式的左右两边的字段名和对应的值。
而且还可以通过SQLUtils.toSQLString打印节点
String sql = "select * from t where id = 1";
List<SQLStatement> sqlStatements = SQLUtils.parseStatements(sql, JdbcConstants.MYSQL);
System.out.println(SQLUtils.toSQLString(sqlStatements, JdbcConstants.MYSQL));
//SELECT *
//FROM t
//WHERE id = 1
String sql = "select * from t where id = 1";
SQLStatementParser parser = new MySqlStatementParser(sql);
SQLStatement sqlStatement = parser.parseStatement();
System.out.println(SQLUtils.toSQLString(sqlStatement, JdbcConstants.MYSQL));
//SELECT *
//FROM t
//WHERE id = 1
SQLExpr sqlExpr = SQLUtils.toSQLExpr("(id=1 or name='test' and age=14)", JdbcConstants.MYSQL);
System.out.println(SQLUtils.toSQLString(sqlExpr, JdbcConstants.MYSQL));
//id = 1
//OR name = 'test'
//AND age = 14
看到这里我们是不是有一点点思路了,因为我们构造出来的json是不关心表名的,其实我们关心的就只有表达式还有操作符,然后组合起来一个整体的JSON。
举个例子可能更加清晰一点,比如有一个表达式(id=1 and (name='test' or age=14)),我们预期最后出来的Condition对象的json结构应该是如下的:
"conditions": [
"conditions": [
"conditions": [],
"operation": null,
"conditionExpression":
"type": "STRING",
"column": "name",
"operateExpression": "=",
"not": false,
"operateValue": ["test"]
,
"conditions": [],
"operation": null,
"conditionExpression":
"type": "NUMBER",
"column": "age",
"operateExpression": "=",
"not": false,
"operateValue": ["14"],
"dateformat": null,
"dateFormatFunction": null
],
"operation": "OR"
,
"conditions": [],
"operation": null,
"conditionExpression":
"type": "NUMBER",
"column": "id",
"operateExpression": "=",
"not": false,
"operateValue": ["1"]
],
"operation": "AND",
"conditionExpression": null

通过这样的一个自身嵌套构造出来的json在我们之前的博客文章里就实现了实体的查询逻辑。
所以我们现在要做的是通过表达式转成一个json数据。然后就可以通过这个json数据去查询数据了。所以我们就可以把历史数据的SQL配置,转成json数据在我们新系统中进行查询了。
前面我们说SQLUtils产生SQLExpr本质上就是一个二叉树,所以我们可以通过遍历二叉树的方式去获取每个结点,判断结点的类型,然后在把它转成一个我们JSON的一个对象。
那要遍历二叉树,很显然我们这里需要用后序遍历的方式,因为我想从最下往上去遍历,最后遍历根结点,才能把左右两棵树通过操作符合并起来。

在JAVA中后序遍历二叉树,可以使用栈来遍历,具体的代码我这里就不会提供了,但是我这里可以讲一下大致的思路,至于怎么用栈来遍历,以及栈中元素的结构怎么设计这里就不过多介绍了,因为我相信讲完后面的思路,其实也大概能搞出来了。
我们可以想看看这个表达式(id=1 and (name='test' or age=14))展现出来的结构是如何的

然后我们可以简单的把这个树画出来
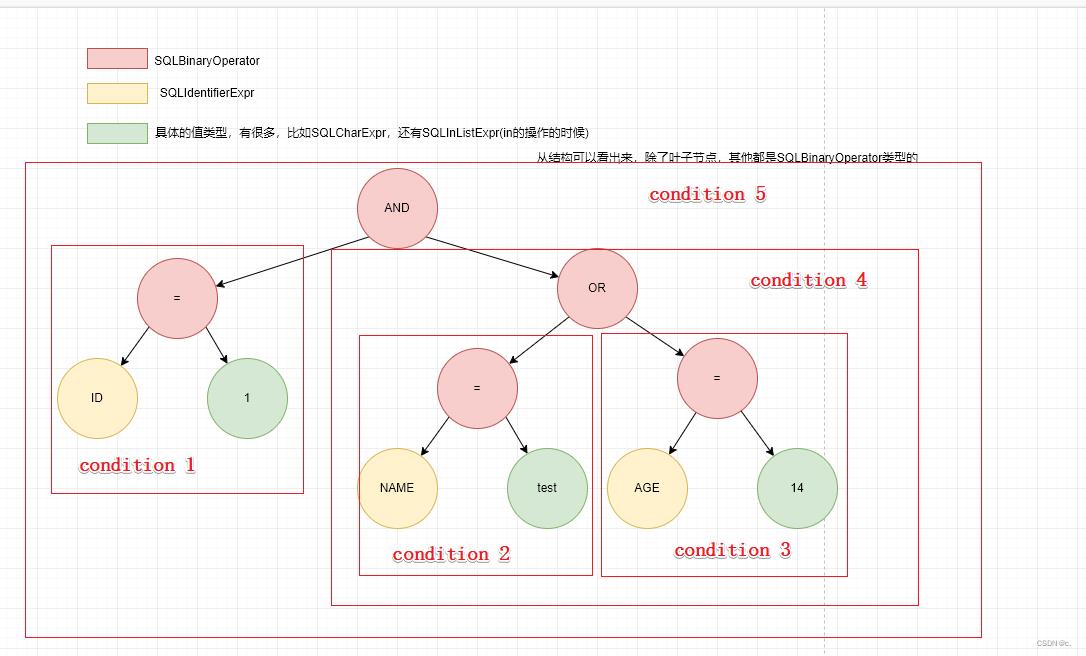
从图上看出来我们遍历左子树,在遍历condition 1这部分的子树的时候,先遍历ID和1,然后再遍历到父节点的=,叶子节点我们可以不看,我们只要判断到节点是SQLBinaryOperator,我们就可以把他们的左右节点拿出来构成出一个condition 1对象,一样的我们会遍历右子树,遍历出condition 2和condition 3两个对象,然后我们在遍历他们的父节点OR,这个时候我们只需要把它左右子树的两个condition 2 和condition 3放到list中,然后在给他加上一个operator 为OR即可变成一个新的condition 4,就变成如下:

然后最后遍历到根结点,就把condition 1 和 condition 4通过AND连接变成一个condition 5,而这个condition 5就是我们最终的JSON结构了。
如果用栈的方式去遍历的话,大概的思路就是每遇到一个结点先把它压入栈中,再去周游其左子树,周游完他的左子树左子树后,应继续周游该结点的右子树;周游完它的右子树之后,才从栈顶弹出该结点并访问它,在访问这个父结点的时候把它的左右子结点的数据拿出来,然后构造出来一个condition对象,大概的思路就是这样。
Visitor
Visitor是遍历AST的手段,是处理AST最方便的模式,Visitor是一个接口,有缺省什么都没做的实现VistorAdapter。
Druid内置提供了如下Visitor:
- OutputVisitor用来把AST输出为字符串
- WallVisitor 来分析SQL语意来防御SQL注入攻击
- ParameterizedOutputVisitor用来合并未参数化的SQL进行统计
- EvalVisitor 用来对SQL表达式求值
- ExportParameterVisitor用来提取SQL中的变量参数
- SchemaStatVisitor 用来统计SQL中使用的表、字段、过滤条件、排序表达式、分组表达式
- SQL格式化 Druid内置了基于语义的SQL格式化功能
Druid提供了多种默认实现的Visitor,可以满足基本需求,如果默认提供的不满足需求,可自行实现自定义Visitor。
比如我们要统计下一条SQL中涉及了哪些表 select name ,id ,select money from user from acct where id =10,如果我们不用visitor,自行遍历AST,能实现,但是很繁琐。
但是我们用默认自带的Visitor就可以很轻松的实现
SQLStatementParser parser = new MySqlStatementParser("select name ,id ,select money from user from acct where id =10");
SQLStatement sqlStatement = parser.parseStatement();
MySqlSchemaStatVisitor visitor = new MySqlSchemaStatVisitor();
sqlStatement.accept(visitor);
System.out.println(visitor.getColumns()); //[acct.name, acct.id, user.money]
System.out.println(visitor.getTables()); //acct=Select, user=Select
System.out.println(visitor.getConditions()); //[acct.id = 10]
System.out.println(visitor.getDbType());//mysql
更多关于Visitor的使用可以参考官网或者参考:Druid SQL解析原理以及使用(二)
参考
Java解析SQL中的表名:使用Druid解析SQL中的表名,使用Alibaba Druid解析SQL中的数据库类型、字段、表名、条件、聚合类型、排序类型。
Java 使用druid包解析sql语句 之 获取查询字段集合
druid 解析select查询sql获取表名,字段名,where条件
以上是关于Apache Druid的SQL查询使用手册的主要内容,如果未能解决你的问题,请参考以下文章
在 Apache Druid 中使用 SQL 将聚合函数应用于某些列
如何将 Spark SQL 批处理作业结果写入 Apache Druid?