Kubernetes中Pod的实现原理
Posted JavaEdge.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kubernetes中Pod的实现原理相关的知识,希望对你有一定的参考价值。
在Kubernetes里部署一个应用的过程。Pod,是Kubernetes项目中最小的API对象。更专业说法,是Kubernetes项目的原子调度单位。
Docker容器本质不过“Namespace做隔离,Cgroups做限制,rootfs做文件系统”,为何Kubernetes又搞个Pod?
1 容器的本质是什么?
是进程!就是未来云计算系统中的进程;容器镜像就是这个系统里的“.exe”安装包。
那Kubernetes呢?就是操作系统!
登录到一台Linux机器里,执行如下命令:
$ pstree -g
展示当前系统中正在运行的进程的树状结构。结果:
systemd(1)-+-accounts-daemon(1984)-+-gdbus(1984)
| `-gmain(1984)
|-acpid(2044)
...
|-lxcfs(1936)-+-lxcfs(1936)
| `-lxcfs(1936)
|-mdadm(2135)
|-ntpd(2358)
|-polkitd(2128)-+-gdbus(2128)
| `-gmain(2128)
|-rsyslogd(1632)-+-in:imklog(1632)
| |-in:imuxsock) S 1(1632)
| `-rs:main Q:Reg(1632)
|-snapd(1942)-+-snapd(1942)
| |-snapd(1942)
| |-snapd(1942)
| |-snapd(1942)
| |-snapd(1942)
在一个真正的os,进程并非“孤苦伶仃”独自运行,而是以进程组,“有原则的”组织在一起。该进程树状图中,每个进程后面括号里的数字,就是它的进程组ID(Process Group ID, PGID)。
如rsyslogd程序负责Linux日志处理。可见rsyslogd的主程序main,和它要用到的内核日志模块imklog等,同属1632进程组。这些进程相互协作,共同完成rsyslogd程序的职责。
对os,这样的进程组更方便管理。Linux操作系统只需将信号,如SIGKILL信号,发给一个进程组,该进程组中的所有进程就都会收到这个信号而终止运行。
而Kubernetes所做的,其实就是将“进程组”的概念映射到容器技术,并使其成为云计算“os”里的“一等公民”。
1.1 为何要这么做?
Borg项目的开发和实践中,Google发现,他们部署的应用,往往存在类似“进程和进程组”的关系。即这些应用之间有着密切协作关系,使得它们必须部署在同一台机器。
若事先没有“组”的概念,这种运维关系就很难处理。
以rsyslogd为例。已知rsyslogd由三个进程组成:
- 一个imklog模块
- 一个imuxsock模块
- 一个rsyslogd自己的main函数主进程
这三个进程要运行在同一机器,否则它们之间基于Socket的通信和文件交换,都会有问题。
现在,要把rsyslogd应用给容器化,但受限于容器的“单进程模型”,这三个模块须被分别制作成三个不同容器。而在这三个容器运行时,它们设置的内存配额都是1GB。
容器的“单进程模型”,并非指容器里只能运行“一个”进程,而是容器没有管理多个进程的能力。因为容器里PID=1的进程就是应用本身,其他进程都是这个PID=1进程的子进程。可用户编写的应用,并不能像正常os里的init进程或systemd那样拥有进程管理的功能。如你的应用是个Java Web程序(PID=1),然后你执行docker exec在后台启动了一个nginx进程(PID=3)。可当该Nginx进程异常退出时,你怎么知道?该进程退出后的GC工作,又由谁去做?
假设Kubernetes集群上有两个节点:
- node-1上有3 GB可用内存
- node-2有2.5 GB可用内存
假设我用Swarm运行该rsyslogd程序。为能够让这三容器都运行在同一机器,须在另外两个容器设置affinity=main(与main容器有亲密性)的约束,即:它们俩必须和main容器运行在同一机器。
然后,顺序执行:
- docker run main
- docker run imklog
- docker run imuxsock
创建这三个容器。这样,这三个容器都会进入Swarm待调度队列。然后,main容器和imklog容器都先后出队并被调度到node-2(这case完全有可能)。
可当imuxsock容器出队开始被调度时,Swarm就懵了:node-2上的可用资源只有0.5 GB了,并不足以运行imuxsock容器;可根据affinity=main的约束,imuxsock容器又只能运行在node-2。
这就是典型的成组调度(gang scheduling)没有被妥善处理的case。如Mesos就有个资源囤积(resource hoarding)机制,会在所有设置了Affinity约束的任务都达到时,才开始对它们统一调度。而在Google Omega论文提出使用乐观调度处理冲突的方法,即:先不管这些冲突,而是通过精心设计的回滚机制在出现冲突后解决问题。
可都谈不上完美。资源囤积带来不可避免的调度效率损失和死锁可能;而乐观调度的复杂程度,不是常规技术团队所能驾驭。
但到Kubernetes这问题迎刃而解:Pod是Kubernetes里的原子调度单位。即Kubernetes的调度器统一按Pod而非容器的资源需求进行计算。
所以,像imklog、imuxsock和main函数主进程这样的三个容器,正是典型的由三个容器组成的Pod。Kubernetes调度时,自然就会去选择可用内存3G的node-1节点进行绑定,而不会考虑node-2。
像这样容器间的紧密协作,可称为“超亲密关系”,有“超亲密关系”容器的典型特征包括但不限于:
- 互相之间会发生直接的文件交换
- 使用localhost或者Socket文件进行本地通信
- 会发生非常频繁的远程调用
- 需要共享某些Linux Namespace(如一个容器要加入另一个容器的Network Namespace)
即并非所有有“关系”的容器都属同一Pod。如php应用容器和mysql虽也发生访问关系,但并没有必要、也不该部署在同一机器,更适合做成两个Pod。
一般都是先学会用Docker这种单容器工具,才开始接触Pod。若Pod设计只是调度考虑,那Kubernetes似乎完全没必要非得把Pod作为“一等公民”?这不故意增加学习门槛?
若只处理“超亲密关系”调度问题,有Borg和Omega论文,Kubernetes项目肯定可以在调度器层解决。但Pod在Kubernetes还有更重要的意义:容器设计模式。
2 Pod实现原理
2.1 只是一个逻辑概念
即Kubernetes真正处理的,还是宿主机os上Linux容器的Namespace和Cgroups,而并不存在一个所谓的Pod的边界或隔离环境。
那Pod又怎么被“创建”的?其实是一组共享了某些资源的容器。Pod里的所有容器,共享的是同一Network Namespace,并且可声明共享同一个Volume。
这么看,一个有A、B两个容器的Pod,不就是等同于一个容器(容器A)共享另外一个容器(容器B)的网络和Volume?
这好像通过docker run --net --volumes-from就能实现,如:
$ docker run --net=B --volumes-from=B --name=A image-A ...
若真这么做,容器B就须比容器A先启动,这样一个Pod里的多个容器就不是对等关系,而是拓扑关系。
所以,在Kubernetes Pod的实现需要使用一个中间容器-Infra容器。在该Pod中,Infra容器永远都是第一个被创建的容器,而其他用户定义的容器,则通过Join Network Namespace,与Infra容器关联在一起。组织关系如下:
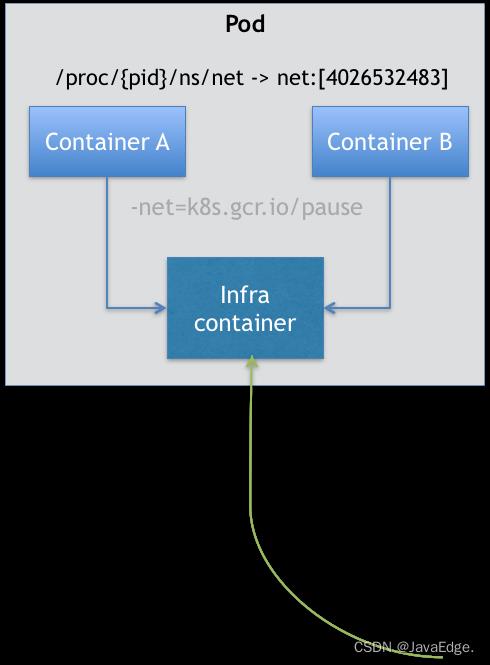
该Pod有两个用户容器A、B,还有个Infra容器。Kubernetes里的Infra容器一定要占用极少资源,所以它使用特殊镜像:k8s.gcr.io/pause。这是汇编语言编写的、永处于“暂停”状态的容器,解压后的大小也只有100~200KB。
在Infra容器“Hold住”Network Namespace后,用户容器就能加入Infra容器的Network Namespace。所以,若查看这些容器在宿主机上的Namespace文件(该Namespace文件的路径),它们指向的值一定完全一样。
即对Pod里的容器A、B:
- 它们能直接使用localhost进行通信
- 它们看到的网络设备跟Infra容器看到的完全一样
- 一个Pod只有一个IP地址,也就是这个Pod的Network Namespace对应的IP地址
- 其他所有网络资源,都是一个Pod一份,且被该Pod中的所有容器共享
- Pod的生命周期只跟Infra容器一致,与容器A、B无关
而对同一Pod里的所有用户容器,它们的进出流量,也可认为都是通过Infra容器完成。将来若你要为Kubernetes开发一个网络插件,应重点考虑如何配置这个Pod的Network Namespace,而非每个用户容器如何使用你的网络配置,这没意义。
即若你的网络插件需在容器里安装某些包或配置才能完成的话,是不可取的:Infra容器镜像的rootfs里几乎啥都没,没你随意发挥的空间。这也意味着你的网络插件完全不必关心用户容器的启动与否,而只需关注如何配置Pod,即Infra容器的Network Namespace。
有了该设计,共享Volume就简单了:Kubernetes只要把所有Volume的定义都设计在Pod层级。
这样,一个Volume对应的宿主机目录对Pod就只有一个,Pod里的容器只要声明挂载该Volume,就一定能共享这个Volume对应的宿主机目录。如下案例:
apiVersion: v1
kind: Pod
metadata:
name: two-containers
spec:
restartPolicy: Never
volumes:
- name: shared-data
hostPath:
path: /data
containers:
- name: nginx-container
image: nginx
volumeMounts:
- name: shared-data
mountPath: /usr/share/nginx/html
- name: debian-container
image: debian
volumeMounts:
- name: shared-data
mountPath: /pod-data
command: ["/bin/sh"]
args: ["-c", "echo Hello from the debian container > /pod-data/index.html"]
debian-container和nginx-container都声明挂载了shared-data这个Volume。而shared-data是hostPath类型。所以,它对应在宿主机上的目录就是:/data。该目录就被同时绑定挂载进上述两个容器。
这就是为何nginx-container可从它的/usr/share/nginx/html目录中,读取到debian-container生成的index.html文件。
3 容器设计模式
Pod这种“超亲密关系”容器的设计思想,就是希望,当用户想在一个容器里跑多个功能不相关的应用时,应优先考虑它们是不是更应被描述成一个Pod里的多个容器。
为掌握这种思考方式,应尽量尝试使用它来描述一些用单容器难解决的问题。
3.1 WAR包与Web服务器
现有一Java Web应用的WAR包,需放在Tomcat的webapps目录下运行起来。假如现在只能用Docker,如何处理该组合关系?
- 把WAR包直接放在Tomcat镜像的webapps目录,做成一个新镜像运行。可这时,若你要更新WAR包内容或升级Tomcat镜像,就要重新制作一个新的发布镜像,麻烦!
- 不管WAR包,永远只发布一个Tomcat容器。但该容器的webapps目录,须声明一个hostPath类型的Volume,从而把宿主机上的WAR包挂载进Tomcat容器当中运行起来。但这样就须解决:如何让每台宿主机,都预先准备好这个存储有WAR包的目录?看来,你只能独立维护一套分布式存储系统。
有Pod之后,这样的问题很容易解决。把WAR包和Tomcat分别做成镜像,然后把它们作为一个Pod里的两个容器“组合”。该Pod的配置文件:
apiVersion: v1
kind: Pod
metadata:
name: javaweb-2
spec:
initContainers:
- image: javaedge/sample:v2
name: war
command: ["cp", "/sample.war", "/app"]
volumeMounts:
- mountPath: /app
name: app-volume
containers:
- image: javaedge/tomcat:7.0
name: tomcat
command: ["sh","-c","/root/apache-tomcat-7.0.42-v2/bin/start.sh"]
volumeMounts:
- mountPath: /root/apache-tomcat-7.0.42-v2/webapps
name: app-volume
ports:
- containerPort: 8080
hostPort: 8001
volumes:
- name: app-volume
emptyDir:
该Pod定义两个容器,第一个容器使用的镜像是javaedge/sample:v2,这个镜像里只有一个WAR包(sample.war)放在根目录下。而第二个容器则使用的是一个标准的Tomcat镜像。
WAR包容器的类型不再是个普通容器,而是个Init Container类型。
Pod中所有Init Container定义的容器,都会比spec.containers定义的用户容器先启动。且Init Container容器会按序逐一启动,直到它们都启动并且退出,用户容器才启动。
所以,该Init Container类型的WAR包容器启动后,执行"cp /sample.war /app",把应用的WAR包拷贝到/app目录,然后退出。
而后该/app目录,就挂载了一个名叫app-volume的Volume。
Tomcat容器同样声明了挂载app-volume到自己的webapps目录下。所以,等Tomcat容器启动,其webapps目录下就一定会存在sample.war文件:这文件正是WAR包容器启动时拷贝到这Volume里的,而这个Volume被这两个容器共享。
像这就用“组合”,解决了WAR包与Tomcat容器的耦合问题。这所谓的“组合”操作,正是容器设计模式里最常用的一种模式:sidecar。即可以在一个Pod中,启动一个辅助容器,来完成一些独立于主进程(主容器)之外的工作。
如在我们的这个应用Pod中,Tomcat容器是主容器,而WAR包容器的存在,只是给它提供一个WAR包。所以,用Init Container的方式优先运行WAR包容器,扮演sidecar角色。
3.2 容器的日志收集
现有一应用,需不断将日志文件输出到容器的/var/log目录。就能把一个Pod里的Volume挂载到应用容器的/var/log目录。
然后,在该Pod里同时运行一个sidecar容器,它也声明挂载同一个Volume到自己的/var/log目录。
接下来,sidecar容器就只需不断从自己的/var/log目录读取日志文件,转发到MongoDB或ES中存储起来。这样,一个最基本的日志收集工作完成了。
该例中的sidecar的主要也是使用共享的Volume完成对文件的操作。
Pod另一重要特性:它的所有容器都共享同一Network Namespace。这使得很多与Pod网络相关的配置和管理,也都能交给sidecar,而完全无须干涉用户容器。最典型的莫过Istio。
Kubernetes社区把“容器设计模式”理论理成的论文。
3 总结
仍很多人把容器跟虚拟机相比,把容器当做性能更好的VM,讨论如何把应用从VM无缝迁移到容器。
但无论是从实现原理还是使用方法、特性、功能等方面,容器与VM几乎无任何相似。也不存在一种普遍的方法,能够把虚拟机里的应用无缝迁移到容器中。因为,容器的性能优势,必伴随缺陷,即它不能像VM,完全模拟本地物理机环境中的部署方法。所以,“上云”最终还是要深入理解容器本质,即进程。
一个运行在VM里的应用,都被管理在systemd或supervisord下的一组进程,而非一个进程。这跟本地物理机上应用的运行方式一样。这也是为何,从物理机到虚拟机之间的应用迁移不难。
可一个容器永远只能管理一个进程,一个容器就是一个进程。所以,将一个原运行在虚拟机的应用,“无缝迁移”到容器,和容器的本质相悖。
所以Swarm无法成长:一旦到生产环境,Swarm这种单容器工作方式,难以描述真实世界的应用架构。所以,你可理解Pod本质:扮演传统基础设施里“VM”的角色;而容器,则是该VM里运行的用户程序。
所以下一次,当你需要把一个运行在VM的应用迁移到Docker容器,仔细分析到底有哪些进程(组件)运行在这VM里。
然后,你就能把整个VM想象成为一个Pod,把这些进程分别做成容器镜像,把有顺序关系的容器,定义为Init Container。这才是更合理的、松耦合的容器编排,也是从传统应用架构,到“微服务架构”最自然的过渡。
Pod提供的是一种编排思想,而非具体技术方案。若愿意,完全可使用VM作为Pod实现,然后把用户容器都运行在该VM。如Mirantis公司的virtlet项目。甚至,你能实现一个带Init进程的容器项目,模拟传统应用的运行方式。
相反的,若强行把整个应用塞到一个容器,甚至不惜使用Docker In Docker,则后患无穷。
以上是关于Kubernetes中Pod的实现原理的主要内容,如果未能解决你的问题,请参考以下文章