linux用户进程分析
Posted yiye_01
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux用户进程分析相关的知识,希望对你有一定的参考价值。
经过实验3的介绍,我们需要来点实在的,所以将我们理解的流程 用于 linux 系统的 分析 。 换句话说,通过类比的方式去进行描述与理解linux相关的部分。本节的内容很详实,而且也分析了很久,所以长话短说,静静的去感受与理解linux内核代码的实现。当然,我们实验的系统代码很简单而且直接,但是linux内核经过20多年的发展,更有成千上万的开发者共同维护,所以对于代码的书写会更加精练,对于基础相对薄弱的程序员去理解有一些障碍,但是反过来说,更有利于我们语言知识的提高。如下的介绍方法是对应于实验中的3个部分进行分别说明,而对于这3个部分主要以分析代码的结构与流程来介绍,而对于细节的实现还需要去认真查看代码。本文只对核心的部分进行介绍,引导读者从基本的部分去学习与理解linux内核的部分代码。
一)进程管理:
在浩如烟海的代码中,如何寻找,太麻烦了。所以我们需要使用其他人的分析结果(参考了《深入理解Linux内核第3版》的部分章节),然后根据相关介绍去有针对性的查看代码。但是我们分析的对象是kernel4.0.2.跟原文中有些出入。当然对于去理解linux内核的程序员,当然这本书是不可多得的参考资料,但是实际使用的linux内核却是发展的,所以还是需要我们触类旁通的理解之。
根据实验3的内容我们首先需要找到对进程的抽象描述,即核心数据结构,由于其结构很是复杂,就不在博客中列出,而是放在附件的源码中。内核的核心数据结构为task_struct——include/linux/sched.h(1286)。当我们打开该数据结构时,第1感觉肯定是定义太复杂了,从什么地方入手呢?我们可以从两个方面入手去理解:其一为从经典的操作系统教程中找寻进程的描述,然后以之为切入点对应分析(可以参考的教程为《操作系统精髓与设计原理第6版》),其二为从简单的操作系统模型去把握核心的部分去分析,然后以此为基础去逐步扩展着分析。当然,我们介绍的是第2种方法,因为我们已经知道了一个简单的操作系统模型。
根据实验3的进程属性分析我们可以将进程属性分为如下几部分:
-
进程标识符(pid,stack)
内核有两种方式识别进程:其一为unix标准的id号(见结构体元素:pid_t pid);其二通过进程的描述符地址,每个进程都会分配唯一的一个进程描述符。对于进程id号,需要被循环使用,它被结构体pid_namespace(pid_namespace.h)中的pidmap所指向的page进行管理,用该页帧的每个bit位来表示已经使用的pid号。
对于进程描述符地址,因为进程描述符与每个进程是一一对应的,当内核需要对进程进行操作时,首先需要得到进程描述符地址,然后对其数据进行操作;对于此linux内核用了一种 巧妙的方式来进行操作,这种方式是基于每个进程在内核状态都有自己唯一的堆栈,将进程执行的必要状态(线程相关状态)放在栈顶与堆栈共享内存空间详情见下图:
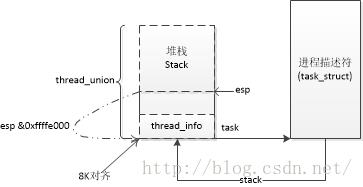
由上图可以知道,内核可以通过简单的检查堆栈指针esp获得进程描述符地址。这样的结构可以在sched.h中获得,当然初始化我们可以参考init_task(init_task.c)的默认初始化。
2.进程状态(state,exit_state)

进程切换如上图所示:我们可以简单的理解,linux进程主要分为4种状态——运行,阻塞(分两种),退出(分两种),特殊(分两种)。迁移路线见图中标识,其中虚线为猜测的退出路线。如上只是一个大概的描述图,更细节的需要针对不同的事件去查看进程状态。
3.进程关系——层次关系(real_parent,parent,children,sibling),静态链接关系(tasks),运行链接关系,协作关系(进程组与会话)
(A)层次关系:进程总是被其他进程所创建(当然0,1进程默认被内核创建,考虑除外),所以所有进程的创建过程决定了其层次关系(父子)如下图(P0创建P1,P2,P3;P3创建P4):
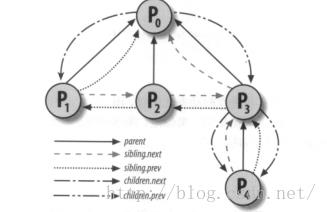
(B)静态链接关系:所有进程都链接到由内存编译时创建的以init_task.task为表头的链表中。
(C)协作关系:当进程在一起协同工作时,可能需要被组织成组,进而形成会话(这种机制,可以参考《UNIX高级编程》的第9章)。为了描述如上关系,需要将进程的pid进行分类——pid,gpid,sid。而在用户空间进程一般操作都是通过pid来进行处理的,所以我们需要能够从pid到task_struct地址的转换。详细描述见下图表示:实现代码详情见pid.h,pid_namespace.h等代码实现。
(D)运行链接关系:主要用于进程被调度时,被分配到不同的队列中。目前主要描述静态的结构,而动态的关系在下一章描述。
4.处理器状态——thread(线程)与task(堆栈)
线程是进程的执行单元,而执行的状态主要用堆栈保存。进程的堆栈如前介绍,而进程的线程主要包含了处理器的寄存器状态。
5.内存映像信息——mm_struct
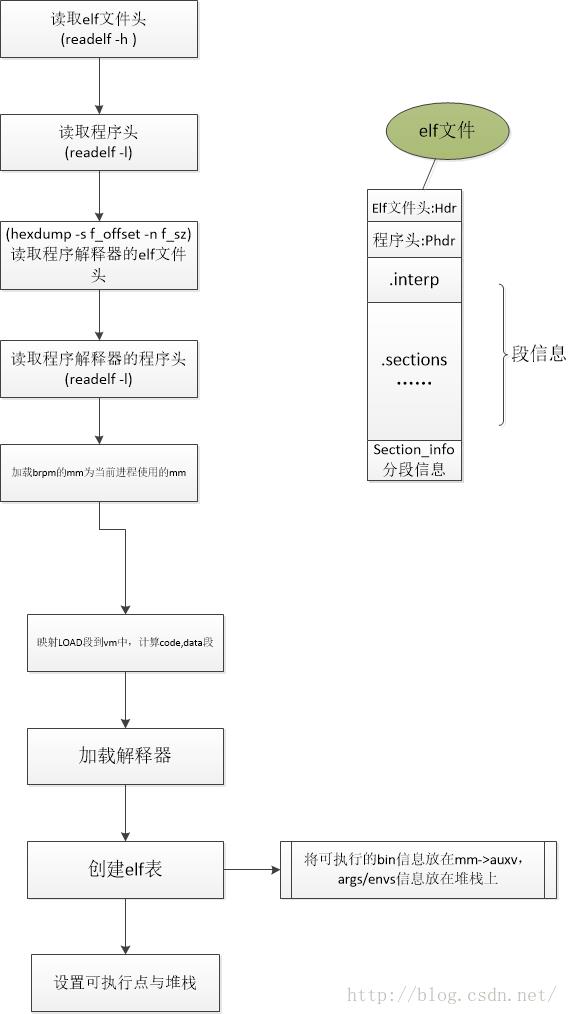
每个用户进程都需要被加载到内存中才能运行,而每个用户进程都是加载磁盘中的可执行文件(以elf文件为例),所以从这个意义上来说,内存映像就是将elf文件加载到内存之后,内存的运行状态。为此我们需要首先了解elf文件的构成,然后根据此去理解mm_struct的相关域。同时,我们也需要参考实验3中进程对进程内存的引用。
(A)elf文件具体结构可以用如下图描述:可以通过readelf去读取其基本信息,同时也可以用hexdump去读取每个部分的详细内容。
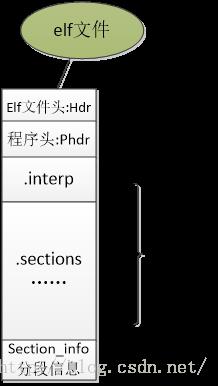
又上图可以看到出elf文件是有不同的段组成。段的基本信息由elf文件头描述(readelf -h),elf文件被加载到内存的情况由程序头(readelf -l)描述,然后就是每个elf段的详细信息(可以用hexdump -s xxx -n yyy来查看,而需要被加载的内存的段组合成了程序头中的段),最后是elf段的信息表(readelf -S),通过它可以查看每个elf段的详细信息。
当了解了elf文件之后我们还要知道进程对执行文件的内存描述:代码段,数据段,堆栈段等信息,当然还有程序运行时的命令行与环境变量等信息(这些信息被放在堆栈段的栈底)。这些信息保存在mm_struct如下域中:
unsigned long start_code, end_code, start_data, end_data;//代码段与数据段
unsigned long start_brk, brk, start_stack;//堆栈信息
unsigned long arg_start, arg_end, env_start, env_end;//命令行参数与环境变量
mm_struct也包含它所有映射的elf文件的一些信息:
unsigned long saved_auxv[AT_VECTOR_SIZE]; //elf表,包含了一些elf文件的信息(在binfmt_elf.c:create_elf_tables()中查看其详细内容)
struct linux_binfmt *binfmt;//加载elf文件时使用的接口
struct file *exe_file;//对应的elf文件
(B)进程的内存分配,通过实验3可以知道每个进程都必需有自己的页目录与页表,所以有如下的如下域:pgd_t * pgd;
(C)线性区管理:如前面所诉,所有elf文件都会被以程序段的信息加载到内存中,当加载到内存中时,分配的虚拟地址都是连续的(可以用cat /proc/$pid/maps查看)。这些线性区是是由结构体vm_area_struct所描述。对于一个进程可能有很多的线性区,而且对它的操作也很频繁,所以需要有快速查找相关线性区的方式——内核使用了红黑树的方式。
struct rb_root mm_rb;//线性区的红黑树根。
对应的vm_area_struct的相关属性如下:
unsigned long vm_start;//线性区的开始地址
unsigned long vm_end;//结束地址
pgprot_t vm_page_prot;//访问权限
unsigned long vm_flags;//标志
struct file * vm_file;//指向的文件
struct rb_node vm_rb;//线性区的红黑树节点
struct mm_struct *vm_mm;//线性区所属的mm_struct.
所有线性区都被链接到mm_struct上:
struct vm_area_struct *mmap;/* list of VMAs */
(D)初始化与设置进程mm的流程如下,可以参考一下,更容易理解mm_struct与mm_area_struct的结构体。

6.统计信息——暂无
7.调度管理——暂无
二)中断管理与glibc:
-
中断基本处理
对于中断的基本处理,我们也用类似实验3的流程图开始介绍之:
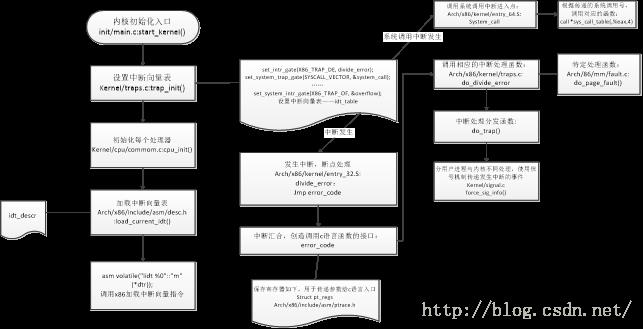
如上图所示,中断的基本处理流程跟实验3的没有多少区别,只是调用方式的区别,当然,我们也可以说是对x86处理器中断处理的封装不一样。
2.系统调用:
对于系统调用,可以参考《深入理解linux内核》第10章——系统调用的部分,如下只是引用另外一张图来说明一下:

如上图所示,给出我们使用系统调用的框图,而直接面向系统调用编程的软件是libc标准库,比如:glibc,bionic等,当然我们也可以直接调用系统调用。对于由系统调用进入system_call的方式由中断基本处理流程介绍了。所有的系统调用都被定义在sys_call_table的数组中。
三)用户启动代码:
我们所认识的C程序都是从main函数开始执行的,但是从实验3,我们发现在执行main函数前需要执行一些引导代码,为执行main函数做一些必要的铺垫,所以我们就对基于glibc的代码在linux平台上的启动做一些介绍。为什么需要理解这些细节呢,不仅仅是为了完善课程,更重要的是为了我们去实现一个操作系统接口,不仅仅是标准c接口,更重要是如何为操作系统的系统调用进行封装,而且方便其他用户使用。glibc实现这样的功能,而是一个很好的例子值得我们学习。当我们在学习软件技术时,很好的模仿是一个入门技巧,更要感谢这么技术的一个本质属性——能够被极简单的复制,然后被不断地演化,改进,用于满足实际需求。
以手动链接“hello world”为例,解析程序默认链接的实现,以及glibc的引导代码的简单流程:
-
编辑“void main()printf(“hello world.\\n”);”到文件hello.c
-
编译hello.c为hello.o(gcc -c hello.c)
-
链接hello.o为hello.out
直接链接:ld -hello.o -o hello.out出现一个错误(不能找到puts)一个警告(不能找到_start)。出现错误的原因是引用了printf,它是基于标准c实现的,所以需要引用c库(-lc);出现警告是因为所有程序的链接过程都是由链接脚本控制,而默认的链接动作是以_start为入口——这就是所有用户进程的实际入口(readelf -h可以查看之),它的实现在glibc编译时生成的crt1.o中定义。将libc与crt1.o链接时又碰到了其他标识没有被定义,所以我们将链接的默认参数dump出来:
/usr/lib/gcc/x86_64-redhat-linux/5.3.1/../../../../lib64/crt1.o /usr/lib/gcc/x86_64-redhat-linux/5.3.1/../../../../lib64/crti.o /usr/lib/gcc/x86_64-redhat-linux/5.3.1/crtbegin.o -L/usr/lib/gcc/x86_64-redhat-linux/5.3.1 -L/usr/lib/gcc/x86_64-redhat-linux/5.3.1/../../../../lib64 -L/lib/../lib64 -L/usr/lib/../lib64 -L/usr/lib/gcc/x86_64-redhat-linux/5.3.1/../../.. -lgcc --as-needed -lgcc_s --no-as-needed -lc -lgcc --as-needed -lgcc_s --no-as-needed /usr/lib/gcc/x86_64-redhat-linux/5.3.1/crtend.o /usr/lib/gcc/x86_64-redhat-linux/5.3.1/../../../../lib64/crtn.o
由此我们知道每个c程序被执行前与结束需要链接的代码为crt1.o,crti.o,crtbegin.o,crtend.o,crtn.o。
对于每一个它们的引用与使用情况,我们可以用readelf -s读取它们定义的标识符了解一下,当然也需要将每个单独链接之后,然后运行,针对出错,进行反复尝试。
当链接完成之后我们运行我们的代码,又报错了,程序解析器不对:
./hello.o.out: /lib/ld64.so.1: bad ELF interpreter: 没有那个文件或目录
默认链接器会使用如上的链接器,而实际机器使用的为glibc编译出来的/lib64/ld-linux-x86-64.so.2,所以我们使用命令——--dynamic-linker /lib64/ld-linux-x86-64.so.2解决。当我们在linux内核中分析程序加载(exec系统调用)的过程中时会发现内核不仅仅会建立应用程序的虚拟段,同时也会建立解析器的虚拟段,同时会创建进程的执行环境——命令行与环境变量,拷贝它们到进程的堆栈空间的顶端(我们可以通过dump进程的堆栈来查看——附件process_stack.c可以参考)。
一叶说,终于又开始接着写了,但是发现一个问题,linux的进程描述与管理太复杂了。而我写的大部分内容也是参考了《深入理解linux内核》的部分内容,同时针对linux 4.0源码进行分析与理解。所以此文只起了一个抛砖引玉的作用,从原始模型类比的方式去理解linux内核,同时也可以了解linux在unix的基础上演变了很多。当然如果需要对内核有深入的理解,参考《深入理解linux内核》是一种很好的途径,但是也要认识到linux内核是一个不断演化,改进的过程,所以现在的理解只是针对目前的状态有效,后续的一些理解应该跟着最新的代码走。当我们在看linux代码时也会发现很多有效的技术在内核中很快得到使用,比如slab分配管理,RCU机制等,然后经过几个版本的更新就稳定下来了,然后被反复的使用。所以对于我们理解内核的代码,需要对这些技术有深入的理解。我们可以将其作为基本模块来理解,首先理解这些技术的原理——可以通过查看这些技术的论文,同时参考最先引入的内核版本进行理解,然后在跟进代码的演化实现到稳定的代码实现,最后看最新的代码实现。后续有机会再好好分析与整理linux内核的部分实现,目前是想把这个简单内核的课程完成,而对操作系统的模型内核有一个完整的认识。
以上是关于linux用户进程分析的主要内容,如果未能解决你的问题,请参考以下文章