余弦相似度
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了余弦相似度相关的知识,希望对你有一定的参考价值。
参考技术A 简介:余弦相似度,即两物体之间的cos$值,值越大,表示两物体的相似度越大。1、向量空间余弦相似度:即向量空间中两夹角的余弦值。其值在0-1之间,两向量越接近,其夹角越小,余弦值越接近于1。
2、n维空间的余弦公式:
3、python中的工具:
numpy中提供了范数的计算工具: linalg.norm(),假定X、Y均为列向量,
则: num = float(X.T * Y)#若为行向量则 X * Y.T
denom = linalg.norm(X) * linalg.norm(Y)
cos = num / denom#余弦值
sim =0.5+0.5* cos#归一化
dist = linalg.norm(X - Y)
sim =1.0/ (1.0+ dist)#归一化
4、例子:
***文本相似度****
sim =1.0/ (1.0+ dist)#归一化
句子A:这只皮靴号码大了。那只号码合适
句子B:这只皮靴号码不小,那只更合适
怎样计算上面两句话的相似程度?
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
第一步,分词 。
句子A:这只/皮靴/号码/大了。那只/号码/合适。
句子B:这只/皮靴/号码/不/小,那只/更/合适。
第二步,列出所有的词。
这只,皮靴,号码,大了。那只,合适,不,小,很
第三步,计算词频。
句子A:这只1,皮靴1,号码2,大了1。那只1,合适1,不0,小0,更0
句子B:这只1,皮靴1,号码1,大了0。那只1,合适1,不1,小1,更1
第四步,写出词频向量。
句子A:(1,1,2,1,1,1,0,0,0)
句子B:(1,1,1,0,1,1,1,1,1)
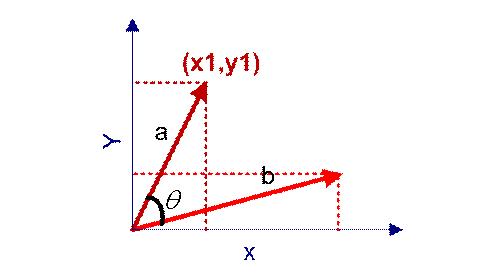
到这里,问题就变成了如何计算这两个向量的相似程度。我们可以把它们想象成空间中的两条线段,都是从原点([0, 0, ...])出发,指向不同的方向。两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合,这是表示两个向量代表的文本完全相等;如果夹角为90度,意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向正好相反。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
使用上面的公式(4)
计算两个句子向量
句子A:(1,1,2,1,1,1,0,0,0)
和句子B:(1,1,1,0,1,1,1,1,1)的向量余弦值来确定两个句子的相似度。
计算过程如下:
计算结果中夹角的余弦值为0.81非常接近于1,所以,上面的句子A和句子B是基本相似的
由此,我们就得到了文本相似度计算的处理流程是:
(1)找出两篇文章的关键词;
(2)每篇文章各取出若干个关键词,合并成一个集合,计算每篇文章对于这个集合中的词的词频
(3)生成两篇文章各自的词频向量;
(4)计算两个向量的余弦相似度,值越大就表示越相似。
Java根据余弦定理计算文本相似度
项目中需要算2个字符串的相似度,是根据余弦相似性算的,下面具体介绍一下:
余弦相似度计算
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。
我们知道,对于两个向量,如果他们之间的夹角越小,那么我们认为这两个向量是越相似的。余弦相似性就是利用了这个理论思想。它通过计算两个向量的夹角的余弦值来衡量向量之间的相似度值。余弦相似性推导公式如下:
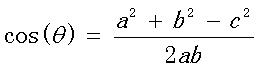
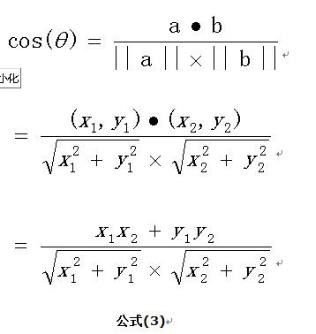
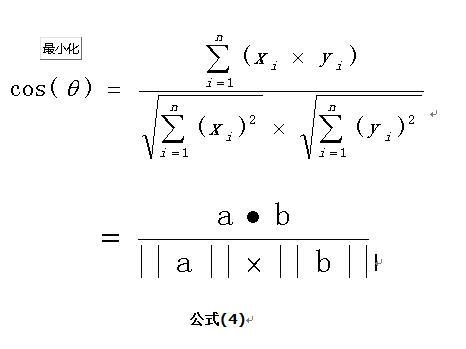
public class Cosine { public static double getSimilarity(String doc1, String doc2) { if (doc1 != null && doc1.trim().length() > 0 && doc2 != null&& doc2.trim().length() > 0) { Map<Integer, int[]> AlgorithmMap = new HashMap<Integer, int[]>(); //将两个字符串中的中文字符以及出现的总数封装到,AlgorithmMap中 for (int i = 0; i < doc1.length(); i++) { char d1 = doc1.charAt(i); if(isHanZi(d1)){//标点和数字不处理 int charIndex = getGB2312Id(d1);//保存字符对应的GB2312编码 if(charIndex != -1){ int[] fq = AlgorithmMap.get(charIndex); if(fq != null && fq.length == 2){ fq[0]++;//已有该字符,加1 }else { fq = new int[2]; fq[0] = 1; fq[1] = 0; AlgorithmMap.put(charIndex, fq);//新增字符入map } } } } for (int i = 0; i < doc2.length(); i++) { char d2 = doc2.charAt(i); if(isHanZi(d2)){ int charIndex = getGB2312Id(d2); if(charIndex != -1){ int[] fq = AlgorithmMap.get(charIndex); if(fq != null && fq.length == 2){ fq[1]++; }else { fq = new int[2]; fq[0] = 0; fq[1] = 1; AlgorithmMap.put(charIndex, fq); } } } } Iterator<Integer> iterator = AlgorithmMap.keySet().iterator(); double sqdoc1 = 0; double sqdoc2 = 0; double denominator = 0; while(iterator.hasNext()){ int[] c = AlgorithmMap.get(iterator.next()); denominator += c[0]*c[1]; sqdoc1 += c[0]*c[0]; sqdoc2 += c[1]*c[1]; } return denominator / Math.sqrt(sqdoc1*sqdoc2);//余弦计算 } else { throw new NullPointerException(" the Document is null or have not cahrs!!"); } } public static boolean isHanZi(char ch) { // 判断是否汉字 return (ch >= 0x4E00 && ch <= 0x9FA5); /*if (ch >= 0x4E00 && ch <= 0x9FA5) {//汉字 return true; }else{ String str = "" + ch; boolean isNum = str.matches("[0-9]+"); return isNum; }*/ /*if(Character.isLetterOrDigit(ch)){ String str = "" + ch; if (str.matches("[0-9a-zA-Z\\\\u4e00-\\\\u9fa5]+")){//非乱码 return true; }else return false; }else return false;*/ } /** * 根据输入的Unicode字符,获取它的GB2312编码或者ascii编码, * * @param ch 输入的GB2312中文字符或者ASCII字符(128个) * @return ch在GB2312中的位置,-1表示该字符不认识 */ public static short getGB2312Id(char ch) { try { byte[] buffer = Character.toString(ch).getBytes("GB2312"); if (buffer.length != 2) { // 正常情况下buffer应该是两个字节,否则说明ch不属于GB2312编码,故返回\'?\',此时说明不认识该字符 return -1; } int b0 = (int) (buffer[0] & 0x0FF) - 161; // 编码从A1开始,因此减去0xA1=161 int b1 = (int) (buffer[1] & 0x0FF) - 161; return (short) (b0 * 94 + b1);// 第一个字符和最后一个字符没有汉字,因此每个区只收16*6-2=94个汉字 } catch (UnsupportedEncodingException e) { e.printStackTrace(); } return -1; } public static void main(String[] args) { String str1="担保人姓名"; String str2="个人法定名称"; long start=System.currentTimeMillis(); double Similarity=Cosine.getSimilarity(str1, str2); System.out.println("用时:"+(System.currentTimeMillis()-start)); System.out.println(Similarity); } }
以上是关于余弦相似度的主要内容,如果未能解决你的问题,请参考以下文章