seq2seq问答摘要与推理<总结>
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了seq2seq问答摘要与推理<总结>相关的知识,希望对你有一定的参考价值。
参考技术A 使用汽车大师提供的11万条技师与用户的多轮对话与诊断建议报告数据建立模型,基于对话文本、用户问题、车型与车系,输出包含摘要与推断的报告文本,考验模型的归纳总结与推断能力。step_1:数据预处理
数据集含五个字段[QID,Brand,Model,Question,Dialogue,Report],训练集的自变量train_x只包含Question,Dialogue,QID,Brand,Model比较短且意义不大;训练集的因变量train_y为Report。
确定好train_x、train_y后,进行分词,停用词含special_character、少数高频率低意义的单词、去重的Brand。
step_2:生成词向量
用train_x、train_y生成所有中文词典,并且按频率由高到低排序,共计12万词。
用train_x、train_y合成后的文件,由Word2Vec方法训练词向量。
从中文词典中取出排名前2万单词,get其词向量,同时把单词索引换成评率排序的数字索引,从而生成以int为索引的词向量。之后,再向词向量中加入[PAD]、[UNK]、[START]、[STOP]。
step_3:建立模型
采用Neural Language Generation方法,搭建encoder-decoder模型,并且采用attention机制,解码单词时能够使模型能够探测上下文单词的重要程度。在encoder中采用双向GRU算法,目的一是GRU具有长短期记忆的处理能力,二是GRU相对于LSTM更快,三是双向更能够使GRU理解上下文之间的关系。在decoder中,使用单向的GRU,然后经历全连接层输出结果。
step_4:生成训练数据
将train_x、train_y转化成在词典中对应的id,按照batch_size可迭代的数据格式,同时对每一条样本做pad、截断。
step_5:训练模型
构建loss_function,调用模型,根据损失函数结果反向传播,打印损失函数的下降过程
step_6:测试数据
定义贪心算法,预测每一步概率最大的值,并id转化成中文单词,去除单词间的空格,最后形成dataframe格式输出
很多次尝试,并未每次都记录,突破性结果如下:
8000数据,循环了15个epochs,loss降到1.87;
10000数据,循环了24个epochs,loss降到1.84;
1、重复性词语偏多,两种形式:
"你好,根据你的描述, 没有问题没有问题没有问题没有问题 ......"
"这是因为发动机 未充分 燃烧 未充分 导致的"
导致的原因:
前者是loss函数未完全收敛,还有下降的空间,需要再调整参数;后者是存word_repetition,也就是decoder过程中,注意力总集中在某个词身上,导致它生成的概率偏大。
2、有比较多的[UNK]词
12万的词典,介于计算压力,只采取了2万词向量,很多词并未含盖导致不少[UNK]出现。
1、采用coverage方法,在attention计算中加入pre_coverage,并且在损失函数中加入coverage_loss,达到对已经decoder生成过的词加以惩罚,从而减少在此出现的概率。
2、采用PGN方法,每一个batch都生成一个oov词典,使每一步decoder出的概率分布都包含oov词,在保证词典维度不太扩张的情况下,从而减少[UNK]出现。
10000数据,循环了13个epochs,loss降到1.73,然后出现loss为nan;
在减小学习率后:
10000数据,循环了20个epochs,loss降到1.38;
增大训练集后:
80000数据,循环了17个epochs,loss降到2.20左右;
重复问题显著改善,但还是有少量存在;[UNK]显著减少,score能拿到30分出头
尝试:不做模型,根据训练数据的对话结构和规律,做一些规则清洗。从原对话提取比较重要的信息作为摘要,score也能达到27分左右,但这样缺乏推理。
心得:在此案例中,用encoder-decoder模型来生成摘要,结果还是不够理想,分数不够高,体现在语句不通畅,不够贴近自然语言。基于规则清洗的原文本也能接近模型所得分数!还可以尝试用抽取式或者更高级的模型尝试。
<学习一段时间的bert模型来尝试改进>
思路:用分类的方式来判断对话中的句子是否该成为摘要,如果是就分类为1,否则为0.
步骤:(1)制定训练数据集,因为原始的文本不是分好类的,所以通过对Report文本分词,来计算Dialogue中的句子所占Report词语的频率,选出频率高的作为摘要原始句子
(2)将文本转换成bert所需的数据格式:tokens\segment_id\mask_id
(3)download bert预训练模型,加载到我的模型中
(4)在bert模型后面,加一个简单的全连接层,进行预测输出
训练过程:由于GPU资源有限,就在本地训练了不到1000多条数据,还不到一个epoch就stop了,损失函数下降正常
测试结果:bert的效果确实好很多,在几乎不用怎么训练的情况下,分数都能够提升6分左右,如果能到服务器上面再跑跑,应该提升近10分
心得:用bert做多轮对话的摘要,虽然效果提升了很多,还是有点的缺陷。一是基于分类来做的,缺乏推理的能力;二是对话的文本很随意,在拆分成句子的时候拆的太短太长都不好,很难把控。但是如果在正规的长篇 文章中,bert表现应该更好。
Textual Entailment(自然语言推理-文本蕴含) - AllenNLP
自然语言推理是NLP高级别的任务之一,不过自然语言推理包含的内容比较多,机器阅读,问答系统和对话等本质上都属于自然语言推理。最近在看AllenNLP包的时候,里面有个模块:文本蕴含任务(text entailment),它的任务形式是:
给定一个前提文本(premise),根据这个前提去推断假说文本(hypothesis)与premise的关系,一般分为蕴含关系(entailment)和矛盾关系(contradiction),蕴含关系(entailment)表示从premise中可以推断出hypothesis;矛盾关系(contradiction)即hypothesis与premise矛盾。文本蕴含的结果就是这几个概率值。
Textual Entailment
Textual Entailment (TE) models take a pair of sentences and predict whether the facts in the first necessarily imply the facts in the second one. The AllenNLP TE model is a re-implementation of the decomposable attention model (Parikh et al, 2017), a widely used TE baseline that was state-of-the-art onthe SNLI dataset in late 2016. The AllenNLP TE model achieves an accuracy of 86.4% on the SNLI 1.0 test dataset, a 2% improvement on most publicly available implementations and a similar score as the original paper. Rather than pre-trained Glove vectors, this model uses ELMo embeddings, which are completely character based and account for the 2% improvement.
AllenNLP集成了EMNLP2016中谷歌作者们撰写的一篇文章:A Decomposable Attention Model for Natural Language Inference
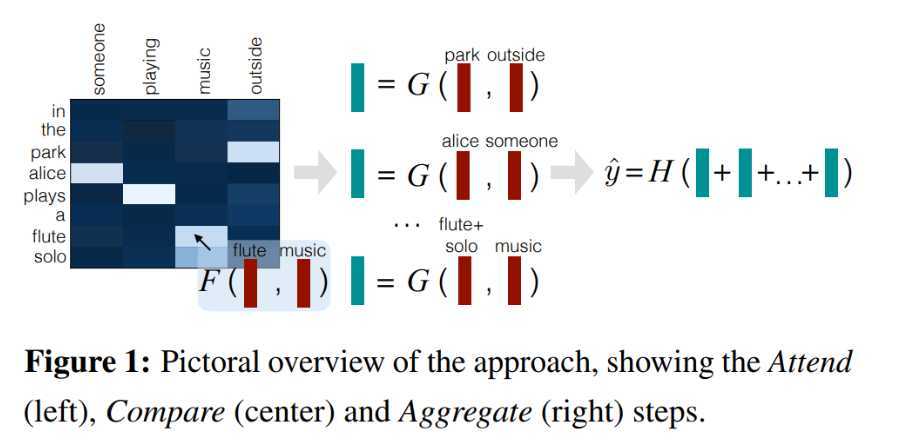
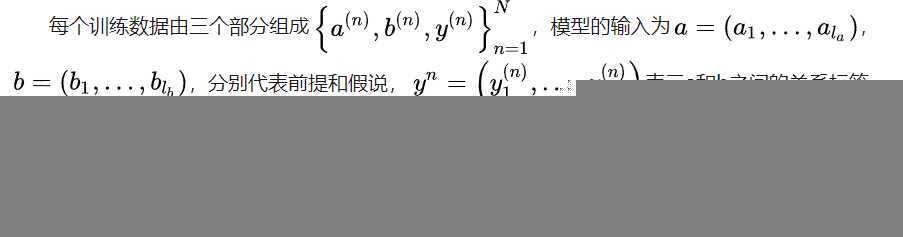


论文实践
(1)测试例子一:
前提:Two women are wandering along the shore drinking iced tea.
假设:Two women are sitting on a blanket near some rocks talking about politics.
其测试结果如下:
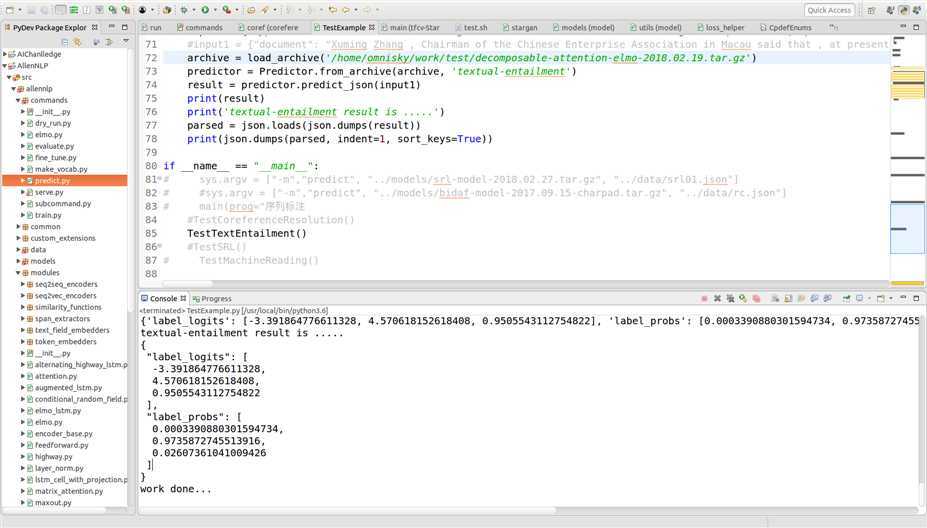
可视化呈现结果如下:

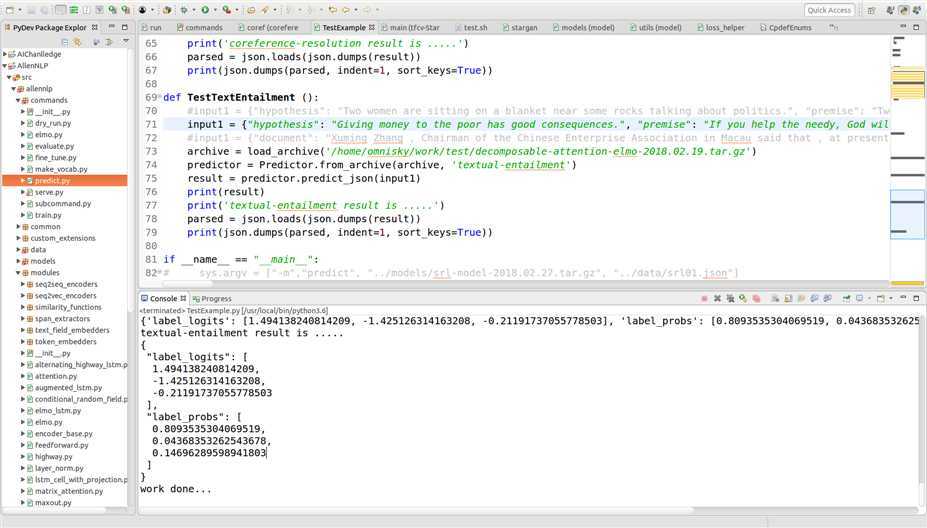
测试例子二:
前提:If you help the needy, God will reward you.
假设:Giving money to the poor has good consequences.
测试结果如下:
以上是关于seq2seq问答摘要与推理<总结>的主要内容,如果未能解决你的问题,请参考以下文章
DL4NLP —— seq2seq+attention机制的应用:文档自动摘要(Automatic Text Summarization)