弹性并行查询深度剖析
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了弹性并行查询深度剖析相关的知识,希望对你有一定的参考价值。

背景
并行查询(Parallel Query)是自PolarDB mysql诞生伊始就致力于研发的企业级查询加速功能,这与PolarDB的产品定位密切相关,基于云原生的计算存储分离使底层数据量远突破单机容量的限制,而针对更海量数据的复杂分析、报表类业务也成为用户自然而然的需求,同时由于PolarDB是服务于在线业务(OLTP)的关系数据库系统,用户会希望分析业务能具有"在线"的能力,即针对最新鲜的数据进行实时甚至交互的查询,这也是现在概念上很火热的HTAP数据库的主要能力。
对线上海量实例的日常监控和运维中,我们发现云上计算资源的利用率普遍是偏低的(e.g CPU...),而利用闲置的CPU资源来做计算加速就是并行查询实现的事情,通过更充分的资源利用降低查询响应时间、提升用户体验的同时也提升了性价比。
关于并行查询的功能、特性、技术原理等,"并行查询的前世今生"这篇已做过详细的解读,今天这篇文章则主要聚焦于并行查询全新发布的下一代形态:弹性多机并行(Elastic Parallel Query)。
概念
顾名思义,多机并行意味着利用更多计算节点的资源完成查询,PolarDB的计算层是一写多读的部署方式,已有的并行查询是指在单个RW/RO节点内的多线程并行,这对于较小的数据量(几百GB)是比较ok的,但很多用户随着自身业务发展,数据开始到达了TB级别,有的甚至单表就有20~30TB,这已经超过了单个节点的处理能力,而多机并行正是为了应对这种场景,通过突破单机的CPU/IO瓶颈将整个计算层的资源打通,实现资源的全局均衡与全局利用。
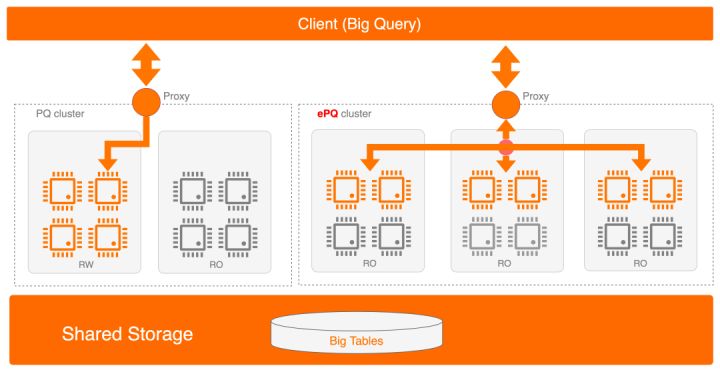
看起来这和传统的MPP架构有些相似,通过将查询的子任务分发到多个节点来以高并发完成计算。但两者有着本质的不同:
- 传统的MPP架构是计算与存储耦合的,查询的子任务要下发到数据所在的节点完成本地化计算,再通过后续分发,到上层节点中完成聚合计算
- PolarDB基于云上基础设施实现了计存分离,任何节点都可以看到全量数据,这使极致的弹性和灵活的调度成为可能,例如实例的规格可以根据负载的需求即时或定时升/降,而无需做任何数据迁移,同时无状态的计算任务理论上可以分发到任意节点执行
弹性多机并行除了具有前者利用多节点并行的加速能力外,更重要的是,它会实时监控集群内的拓扑变化和资源使用,从而实现随计算资源的变化动态适配并行策略,无论是单个节点的规格提升(scale up)、或是引入了新的RO节点(scale out),都可以自适应的做并行度调整和子任务分发,在避免单节点计算热点的同时、尽可能保证按照用户指定的并行度完成查询,从而达到更高的资源利用率。
优势
延续了并行查询的特性,弹性并行查询具有如下的一些优势:
- 100%兼容性
并行查询基于MySQL开发,具有100%的MySQL兼容性,包括语法、类型、行为的全方位兼容,除了查询时间更短外,用户是感觉不到查询是否开启了并行的。
- 极致性价比
性价比来源于四个方面:
- 数据:复用了底层同一套业务数据做in-place分析加速,而无需单独维护一套额外副本,没有附加的存储成本
- 计算:基于原生的执行引擎实现,购买实例后默认的读写集群即可开启多机并行功能,除非需要加入更多节点完成计算,否则并无额外计算成本。
- 调度:通过自适应调度来提高资源利用率,举个简单的例子:一个查询在单节点并行时需要4个线程完成,但当前节点只剩3个线程资源,而其他节点仍有空闲,则可以通过跨机调度分发一个计算任务,利用闲置资源保证加速效果。
- 弹性:随实例规格的弹性变化实时调整并行策略,在"降本"的同时仍然保证"增效"能力
- 极低运维成本
用户在现有或新建集群中,只需勾选是否开启跨机并行、并设置单节点并行度即可,保持了极简配置、开箱即用的状态,无需业务侧修改任何代码,降低使用和维护复杂度。
- 实时在线分析
相对于RDS传统的主从binlog同步,PolarDB基于innodb的物理复制实现,节点间同步延迟在ms级或更低,这样即使查询下发到RO节点,也可得到100%新鲜度的实时数据,同时结合更高并行度的计算在更短时间内得到查询结果,可以让业务在第一时间获取到insight,满足企业快速发展中随时可能变化的业务需求。
- 灵活的应用模式
很多企业用户有在一套数据上进行多种类分析的需求,不同种类可能来源于不同业务部门,查询的特性也各不相同,例如针对大量数据的批量报表、针对部分数据的实时交互等。PolarDB一写多读的架构本身就很适合这样的多样化场景,不同业务可以通过使用不同节点构成的子集群实现物理隔离,而不同子集群可以通过设置不同的并行策略来应对相应的分析场景。
适用场景
弹性并行查询(ePQ)是并行查询(PQ)的下一代演进,同时也保持了对PQ的完全兼容,因此并行查询本身适用的场景[1],弹性并行仍然适用。除此之外,ePQ能应对的场景更加灵活而广泛:
-海量数据分析场景
前面已经提到,在更大数据量的情况下,单机的CPU/Memory/IO都可能遇到瓶颈,如果打破这个瓶颈,查询响应时间就可以继续线性提升。这里可能有同学会问,能不能通过升级单个节点的规格(最高88core)来实现对更大数据量的处理?跨机一定是必须的吗?答案是肯定的,原因在两方面:
- 即使是最大88核的规格,处理能力仍是有上限的,而且如果数据量到达TB级别,这个规格应对分析查询仍是不够的,只有扩展出去才能利用更大的总体资源
- 即使单机资源没有遇到瓶颈(多核大内存),在数据库内核中会存在很多共享资源(page hash/readview/pages...),查询中的worker线程会并发访问这些资源,导致并发控制带来的消耗,查询性能无法很好的线性扩展。但如果worker线程分布到多个节点中,争抢会降低很多,仍然可以保证良好的加速比
- 资源负载不均衡场景
集群内的多个只读节点,借助数据库代理的负载均衡能力可以使每个节点的并发连接数大致相同。但由于不同查询的计算复杂度、资源使用方式各有差异,基于连接数的load balance无法完全避免节点间负载不均衡的问题。同所有分布式数据库一样,热点节点也会对PolarDB造成一定的负面影响:
- 如果RO节点过热使得查询执行过慢,可能造成主节点无法purge undo log导致磁盘空间膨胀。
- 如果RO节点过热导致redo apply过慢,会导致rw节点无法刷脏降低主节点的写吞吐性能。
为此我们更需要在内核中建立更为全面的负载均衡能力,弹性多机并行引入了全局资源视图机制,并基于该视图做自适应调度,依据各节点的资源利用率和数据亲和性反馈,将查询的部分甚至全部子任务调度到有空闲资源的节点上,在保证目标并行度的基础上均衡集群资源使用。

- 弹性计算场景
如前所述,弹性是作为云原生数据库的PolarDB的核心能力之一,自动扩/缩容功能提供了对短查询类业务非常友好的弹性能力,但之前并不适用于复杂分析类业务,因为对于大查询场景,单条查询仍无法通过增加节点实现提速。而现在开启弹性多机并行(ePQ)的集群,新扩展的节点会自动加入到集群分组中共享计算资源,弥补了之前弹性能力上的这一短板。
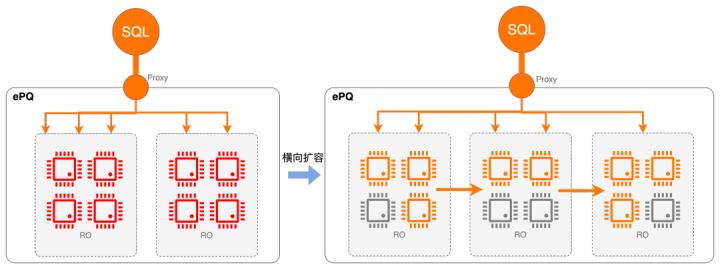
- 在离线业务混合场景
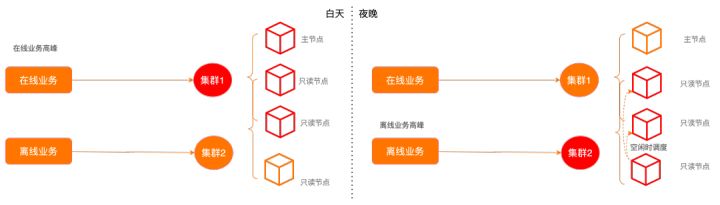
前面提到了多个子集群的物理资源隔离能力,最彻底的隔离方式是将在线交易业务和离线分析业务划定为不同节点集合,但如果用户在意成本,这种模式会显得有些浪费,因为很多情况下,在、离线业务会有不同的高、低峰特性,更经济的方式是通过错峰使用,让不同业务共享部分集群资源,但使用不同的集群地址承接业务。通过开启弹性并行,让离线业务重叠使用在线业务低峰期的空闲资源,进一步降本增效。
技术实现
关于并行查询的技术细节,在之前的"PolarDB并行查询的前世今生"中已有详细说明。本文将主要介绍为实现弹性的多机并行,我们额外做了哪些工作,如果大家感兴趣,可以连同前一篇一起对照看下,会有个更整体的概念。
内核架构
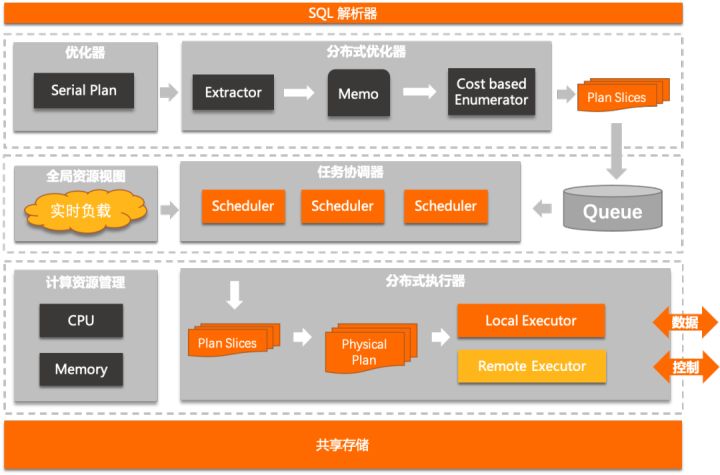
和之前相比,弹性跨机并行在优化器/执行器/调度/一致性等方面都做了进一步优化或分布式改造,逐一介绍如下
分布式优化器
多阶段的分布式优化器已经实现了对各种形态并行计划的穷尽式枚举,因此后续的改造主要集中在根据全局资源视图以及调度策略,选择合适的全局并行度,例如:
- 如果全局资源均不充足,禁止使用并行
- 如果查询代价或表扫描行数超过阈值,等比例扩展单机并行度到多机,更充分利用多核资源加速计算
- 否则保持现有并行度不变,并在枚举计划空间中,考虑跨节点的数据分发代价
此外,由于实现了更多的并行执行策略,在优化器层面也要支持更复杂计划形态的枚举,详见下节。
并行执行策略
在单节点PQ2.0中,已经实现了全算子的并行执行支持,但少量算子仍不够完善,例如对于Semijoin Materialize这种执行方式,原有的并行策略是全量下推到worker中,这意味着每个worker都需要执行全部的semijoin物化操作,这明显不是最高效的。
新的并行执行策略包括:
- semijoin-materialization并行物化
sjm是MySQL对semijoin的一种物理执行算法,通过将子查询的join结果物化为临时表,参与到外层表的join中,并行查询中对其原有的支持如下:
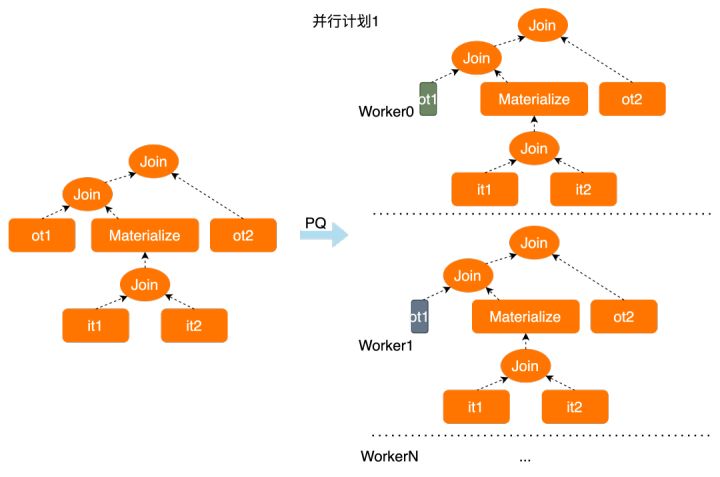
可以看到,每个worker都完成了it1和it2表的全量join和物化操作,这个重复的动作有可能代价很大,且没有必要,更有效的方法可能是这样:
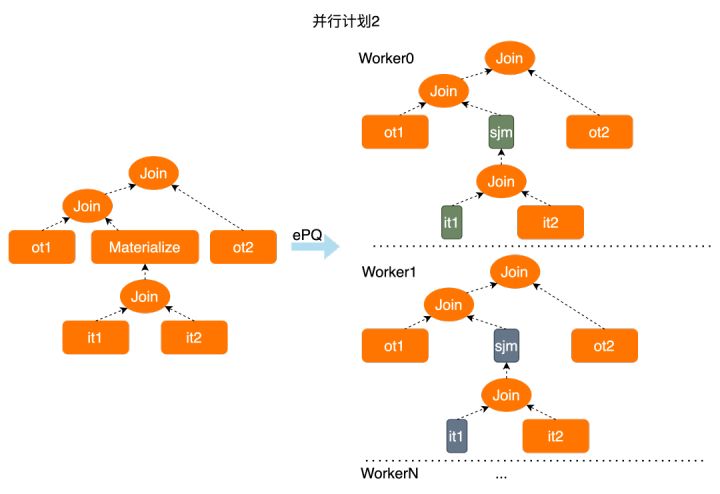
这样的计划形态,可以使每个worker都完成更小的计算量,当然这只是一个极简例子,实际情况可能复杂的多。
当然如果物化本身涉及的计算量已经很小,计划形态1也许更优,这要通过分布式优化器的枚举框架,基于统计信息+代价来选择,确保找到最优解。
有了sjm并行物化的支持,TPC-H 100G Q20,在32并行度下提速5.8倍。
- derived table/cte并行物化
类似于semijoin,MySQL对于无法merge到外层的derived table/view也会先物化下来并参与到外层join中,这个过程同样可以分片完成,由于示意图与上面非常相似,因此不再给出,不过熟悉MySQL源码的同学应该知道,semijoin-materialize和derived table materialize有着完全不同的优化路径和执行机制,因此PolarDB内部的并行实现逻辑是完全不同的。
有了derived table并行支持,TPC-H 100G Q13,在32并行度下提速2.2倍。
节点间交互
为实现跨机,节点间要建立高效的控制+数据通道,同时两者间要有必要的协调控制来确保正确的early-stop,错误处理等机制。
- 控制通道
我们扩展了MySQL的命令协议来完成下发计划、执行控制、回收状态等功能,最naive的做法是1: worker数的方式,即对每个worker都建立一个命令通道,但这不仅意味着连接的增加,也会造成同一节点内的很多工作重复执行(e.g 计划模板反序列化,执行环境重建...),因此我们设计了如下控制通道拓扑:
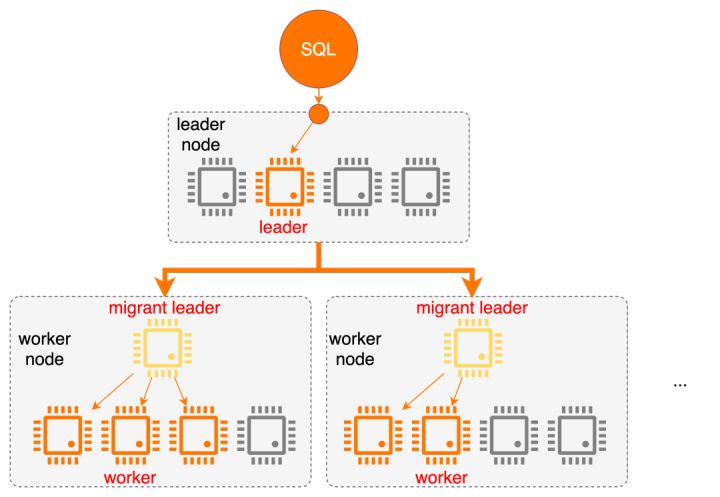
在每个下发的子节点上建立一个migrant leader角色,该线程是节点上的代理,负责与leader的控制信令交互、生成计划模板和执行上下文等共享信息,同时也要负责创建worker、管理worker执行状态等,这个角色的计算量很小基本不占什么资源。通过这种方式,控制通道优化为1:node数。
- 数据通道
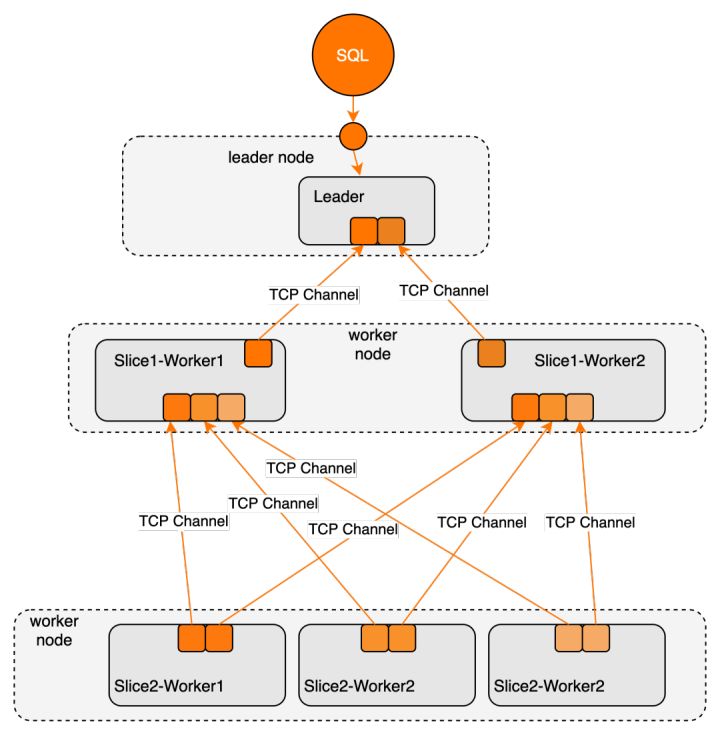
目前实现了基于TCP的数据交互协议,在leader构建执行上下文时会检查不同子计划的worker间,是否位于同一节点,如存在跨机则使用网络通道,并将相关信息(e.g IP/Port...)随计划片段序列化到远程节点的migrant leader上,并传递给对应worker用来建立非阻塞的数据通道,数据通道拓扑如下:
高效的数据传输是查询性能的关键因素之一,为此我们做了一系列针对性优化
- 端口复用
每个worker可能需要建立多个数据通道,并且可能同时是数据发送方和接收方(上图slice1),如果每个连接都使用独立端口,可能会导致节点端口用尽。为避免这一问题,我们优化为在同一节点内的所有worker共用同一端口接收下层worker的中间结果数据,并使用全局的Exchange manager线程管理连接并映射到目标收端worker。
- 缓冲队列
由于流水线的执行模式,如果每从iterator吐出一条数据就向网络发送,必然带来频繁系统调用的开销,为此在收发端均引入了循环缓冲队列,实现了流控和batching+pipeling,提升传输性能。
- 异步设计
为了降低网络传输不稳定以及worker负载不均衡的影响,数据通道使用了全异步化设计,对于各个通道的读/写均是非阻塞的,如果某个通道暂时无法收发,则切换到下一个通道继续操作,这显著提升了整体的cpu利用率和传输效率。
但仍存在一些问题:
在高并发度的shuffle中,数据通道会产生经典的连接爆炸问题( N * N的连接数),这对于集群的网络开销还是比较高的,为此我们后续有两方面的规划:
- 实现proxy模式的数据交互协议,多路数据复用同一连接,以应对更大规模的并行(e.g 参考Deepgreen)
- 使用RDMA实现数据传输协议,彻底bypass网络协议栈和kernel的处理开销,进一步提升性能
执行计划序列化
分布式执行计划的计划片段如何传递到远程节点并转换为准确的物理执行计划,是分布式计算引擎必须要解决的问题。Microsoft Synapse和Oracle PX通过将计划片段转换为SQL语句,下发到集群中各子节点,并在节点本地重新解析生成执行计划来实现子计划的分发。还有一些系统(e.g Greenplum)会分发物理计划的逻辑描述,并在子节点上基于抽象描述重新构建物理计划。但PolarDB考虑到MySQL实现的特点并兼顾计划生成的高效性,选择了序列化计划模板的方式,具体如下:
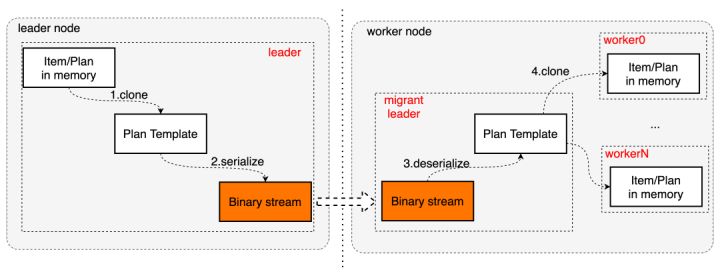
- leader在完成分布式优化后生成物理计划片段的模板(类似MySQL的物理计划),然后序列化该模板
- 二进制的计划模板分发到各子节点的migrant leader上
- migrant leader反序列化后,还原出本地计划模板和执行上下文信息(e.g variables/readview...)
- 各worker线程从本地模板中clone出自己的物理执行计划,实际执行
跨节点parallel scan
PolarDB的并行查询能力与innodb btree的逻辑分片+并行访问密不可分,由于不是share nothing的架构,为了保证对共享表的并行读取,在innodb层对leaf page按照页粒度做了逻辑切分,而对于切分后的各个granules,各worker有两种不同的访问模式:
- round-robin
每个worker轮流获取1个granule并完成后续算子的计算任务,然后读取下一个granule,各个worker间通过一个全局偏移计数器协同对granule的读取。这个做法可以尽可能的保证各worker的负载均衡,由于granule的切分数量远大于worker数,因此执行快的worker可以抢到更多granule去执行,保证各个worker间执行时间比较均衡,避免skew问题。
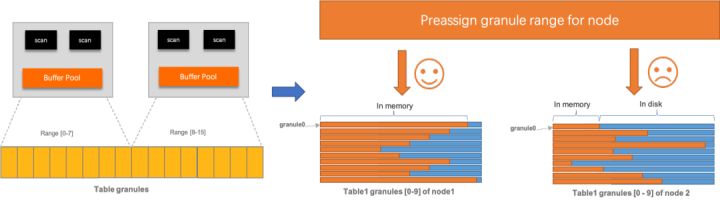
- pre-assign
对所有切分出的granules,在worker间预先分配,每个worker访问指定的分片集合,这种方式是静态的,初始各个worker分配到的数据量是差不多的,但由于后续执行的过滤等操作,worker之间的计算量可能会各有不同,导致skew问题。
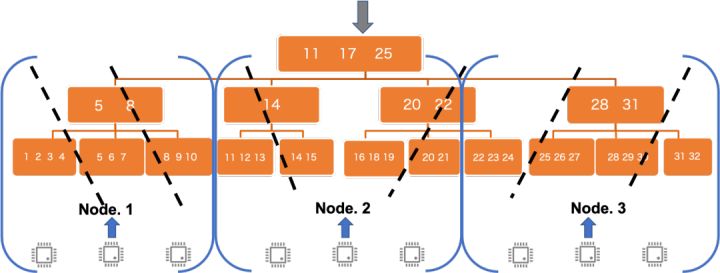
显然我们希望在跨机时仍然能使用第一种方案,但很遗憾这个全局的偏移计数是无法跨机共享的,Oracle PX的实现方式是由leader作为协调者,通过网络通信来协调对granule的获取,但这样也引入了额外的通信成本,因此PolarDB的跨机parallel scan目前采用了一种折衷方案:
节点内做round-robin,节点间pre-assign。
对于切分出的所有granules,预先按照参与查询的节点数分配为若干range区间,各个range内的granule连续排列。在实际执行中,每个节点内的所有worker线程利用所属migrant leader的共享计数器,争抢所分配range内的granules集合。
查询内事务一致性
在单节点并行查询中,各worker线程通过共享leader的readview,来保证在innodb层使用统一的读视图读到符合事务一致性的表数据。但在跨机的情况下这个机制就出现了问题:不同节点间的读视图如何保持与leader一致?为了做到这一点,需要三方面的工作:
- 读写事务信息同步
为了保证集群级别的事务一致性,RO节点必须能够感知到RW上发生的读写事务,并根据这些信息构建本地的活跃事务信息,来同步RW的事务系统状态,为此innodb层会将读写事务的相关信息写入redo log复制到RO,RO解析redo后重新构建活跃事务链表。
- 全局一致位点的同步
只是有了活跃事务链表并不足够,因为RO上的信息总是落后于RW的,如果一个查询的worker任务到达RO时,该查询在leader的活跃事务信息还没有在RO上apply出来,worker是不能开始读取的,需要等待全局事务信息恢复到leader创建时的状态,为此需要有个等待同步点的过程。
初始时我们采用了基于lsn位点的等待:leader在构建readview时记住所在的lsn位点lsn3,并传递到worker,worker在RO等待知道apply位点到达目标值lsn3后,再构建出和leader一样的readview,做数据读取
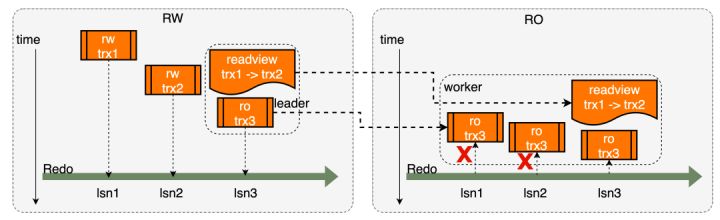
可以看到,基于lsn机制的同步粒度是较粗的,理论上,在RO恢复lsn2之后,worker就可以构建同样的readview信息了,因此在新方案中我们进行了优化,利用innodb层提供的SCC全局强一致能力来更及时的同步RW/RO之间的事务状态,并基于这个信息作为同步位点,进一步降低query内延迟。关于SCC功能可以参考官方文档[2]。
- 读视图的复制
有了以上两点的保证,这里就非常简单了,只需要将leader获取到的readview同步给所有worker即可,具体就是通过对readview相关结构(e.g 上图的trx1/trx2...)完成序列化+反序列化。
基于资源的自适应调度
弹性多机并行支持以下3种调度策略
- LOCAL
节点内并行,相当于关闭了ePQ引擎
- MULTI_NODES
全局并行度随节点数线性增加,适用于海量数据的复杂查询
- AUTO(default)
自适应并行,会根据集群内节点的实时负载信息做调度,本地节点资源不足时,尝试选择有空闲资源的节点调度执行,同时如果查询代价/扫描行数超过阈值则切换到"MULTI_NODES"模式
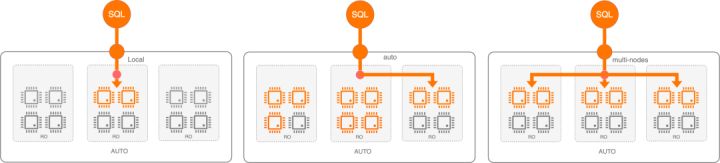
例如:
用户设置并行度为2,当开启AUTO模式时,如本地节点资源充足则选择本地执行 (上图左),否则会将worker协调到其它有空闲资源的节点(上图中)。当查询代价/扫描行数超过特定阈值且集群内有足够空闲资源,DoP弹性调整为2*3=6,使用集群内所有节点进行加速(上图右)
这种AUTO模式下的自适应调度能力通过分布式任务调度器完成,调度机制整体框图如下:
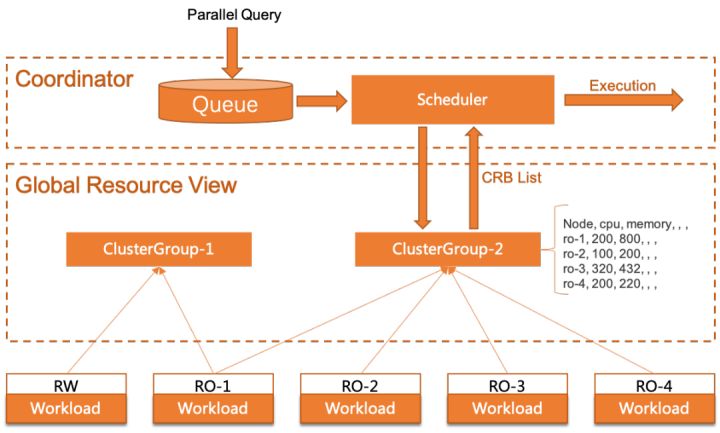
- 分布式任务调度器
任务调度器为无中心架构,每个计算节点均可接受查询并通过本地Coordinator完成查询调度。首先优化器生成的分布式执行计划会进入FIFO队列,Scheduler从队首获取任务,通过全局资源视图(见下)为计算任务申请计算资源池(CRB List)。如资源不足则继续等待,直到有空闲资源或超时回退串行。
- 全局资源视图
该模块负责收集和维护各节点的资源负载信息(e.g CPU/Memory/Concurrency...),每个节点定时采集自身负载信息并以UDF报文广播到集群中,这样每个节点都会维护一份全局资源信息的快照。
- 计算资源预算
计算资源预算(Compute Resource Bugdet. CRB)是对节点负载资源的一个评估值,代表该节点剩余的计算能力。由于资源信息广播是异步的,无法完全避免由于stall导致的不准确调度,为避免资源分配过载/不足,在计算单个节点的有效预算时我们引入了一个自适应因子,该因子会按如下策略调整:
- 连续N次负载信息无明显波动,factor上调10%;
- 连续N/2次负载信息有明显上升,factor下调20%;
- 目标节点并行资源耗尽,factor直接下调为0,禁止分配
- worker分配CRB
当获取到资源池后,池中的列表会涉及多个节点,那如何将workers集合分配到这些节点中呢?这里会考虑基于两个因素
1、cache亲和度:针对最下层leaf workers生效,前面已提到,在为表切分granules时,会以pre-assign方式将各granules集合绑定到各节点上,每个worker会根据自己所属的granule range映射到目标节点,如果该节点有资源预算供该worker执行,则执行分发(复用节点中可能缓存的pages),否则只能调度到其他节点执行
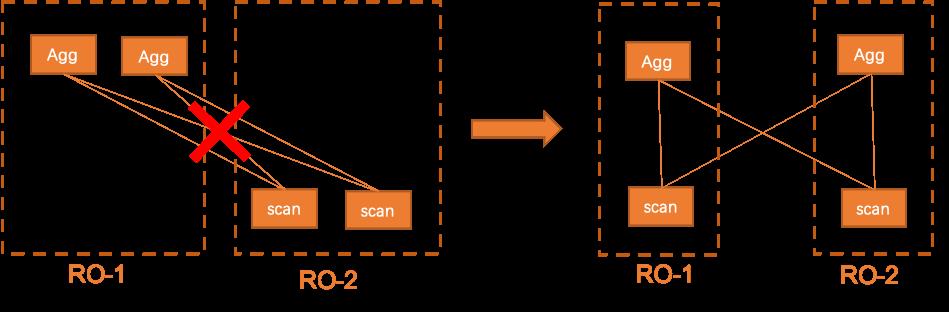
2、最小化跨机数据传输:针对非leaf workers生效,上层worker在分配时要参考下层worker尽量做"竖向"切分,减少跨机数据交互,例如下图左侧的数据分发总量会少于右侧
性能评估
性能的表现方式可以有很多种,这里我们既会关注一般产品都会测试的TPC-H查询性能,也会针对前面提到的几个特定场景来逐一做下评估,确定弹性多机并行的行为是否符合设计预期。
注:
本测试是通过购买PolarDB 8.0.2版本线上实例,关闭了2个属于实验状态的优化器参数。
set optimizer_switch="hash_join_cost_based=off";
set cbqt_enabled=off;然后在集群配置页面上开启多节点并行并设置单节点并行度即可,无需其他操作和调优,基本属于开箱即测。
测试使用标准的 TPC-H [3]数据(主外键)和语句。
单机 v.s 多机
前面我们提到的一个问题,就是相同总体并行度的情况下,大规格单机会比小规格多机更好吗?为了验证我们使用如下测试方法:
1node 32c的polar.mysql.x8.4xlarge v.s 2node 16c的polar.mysql.x8.2xlarge,两者CPU/MEM资源持平,对用户来说成本也相同
- CPU bound
TPC-H 100G,22条查询每条执行3次取第3次结果,此时数据完全cache在实例内存中无IO,对比如下:
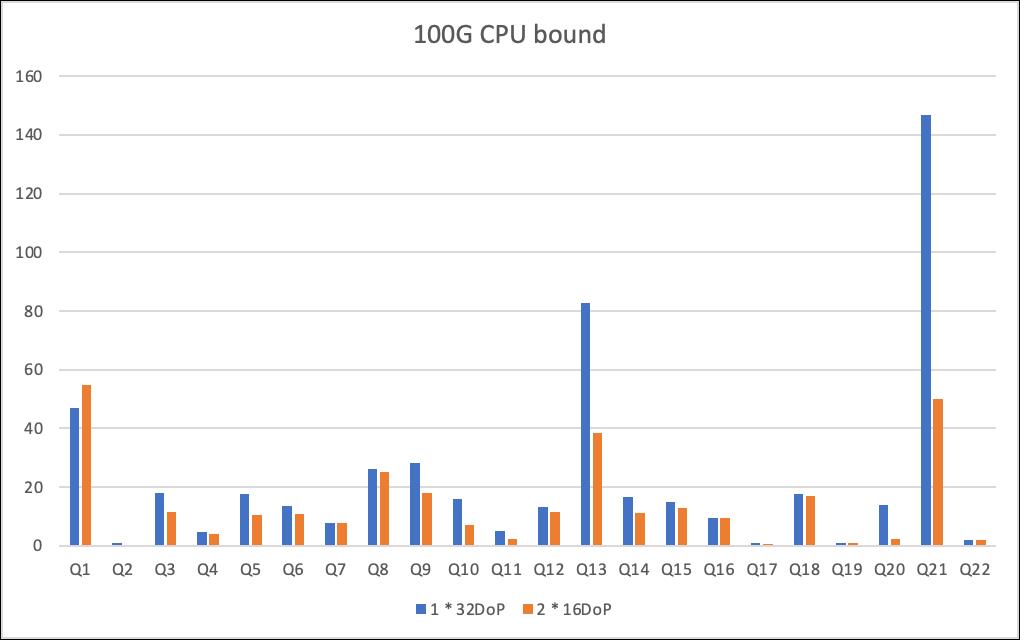
可以看到基本所有查询都变得更快了,这也符合我们对并发资源争抢消减的预期
- IO bound
使用TPC-H 1T做power run,由于内存严重不足,因此一定会产生大量读IO,结果对比如下:
注:power run指重启实例所有节点的docker实例后,顺序执行22条查询SQL
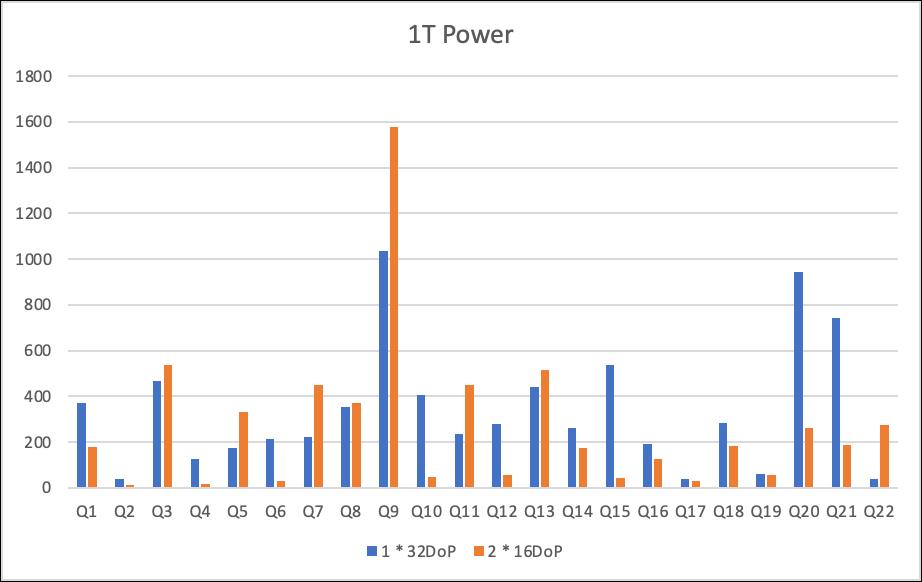
可以看到由于有了两个节点,总体的IO带宽也扩大了一倍,能够更好的利用底层共享存储的大吞吐,多数查询有了提升,但部分查询会变慢,观察发现这些查询主要都存在多个大表join的情况,这是由于在做多表join时,基于主外键的nested loop join会带来一定的二级索引随机回表,在单节点时,同一个主键索引page在被淘汰之前很可能被某些worker线程复用而加速了那些worker的执行,但分散到多节点后这种复用率降低了,产生了更多的page thrashing。但总体执行时间仍然多节点是更快的,提升了21%。
横向扩容
这里我们来看下随着集群的横向扩容(scale out),查询的扩展性如何,仍然考虑CPU bound/IO bound两种场景
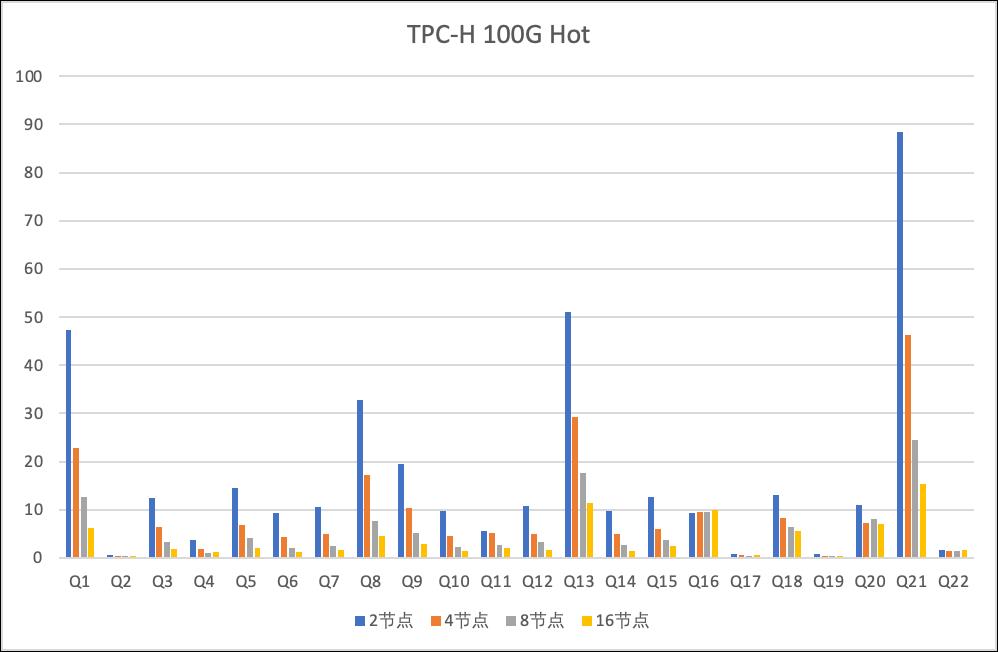
- CPU bound
同样使用TPC-H 100G,22条查询每条跑3次取第3次结果,使用16c的polar.mysql.x8.2xlarge规格的节点,从2节点开始依次翻倍节点数
- IO bound
仍然使用TPC-H 1T做power run,也是从2节点开始依次翻倍
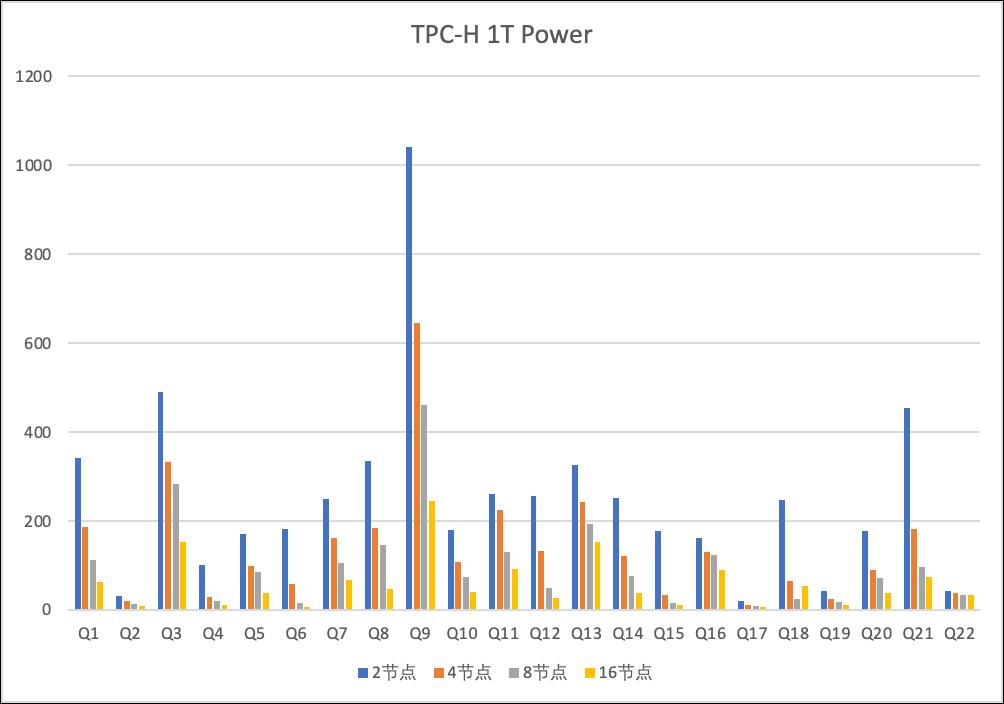
可以看到从16DoP到256DoP,冷热查询的性能均得到了线性提升。
在离线混合
为评估之前提到的在离线混合场景的效果,我们建立了一个1rw+3ro的实例,并创建oltp、olap两个集群分别模拟在线事务(rw1+ro1+ro2)和离线分析(ro1+ro2+ro3)负载。

使用2个client:
Client-1连接oltp cluster,使用sysbench做短事务读写压测。
Client-2连接olap cluster,使用tpch数据改造后的sysbench,但为看出效果,这里也没有使用很大的长查询,仅为了使其足够使用多机资源。
测试流程:
- Client-1 暂停,模拟oltp业务空闲。
- Client-2 开始直接连接ro3节点,观察qps。
- Client-1恢复,将oltp cluster资源占满,此时观察Client-2的qps变化。
- 再次暂停Client-1的压力,观察Client-2的qps变化
下图给出Client-2的sysbench截图
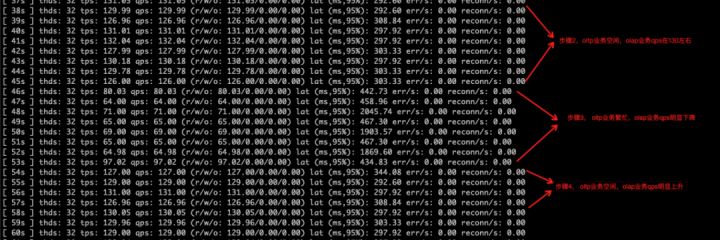
可以看到
- 在oltp cluster有压力时,Client-2的查询只在ro3节点内并行,吞吐也较低。
- 当tp业务空闲时,ap查询的负载分发到ro1/ro2节点,吞吐量立刻上升。
- 当tp业务再次繁忙时,ap的查询能力重新回落到单节点水平
对负载变化的响应延迟在1-2秒左右。
TPCH
针对绝对性能我们在各种[节点数 并行度]的组合下进行了大量测试,这里仅给出 16 16 = 256并行度 的数据
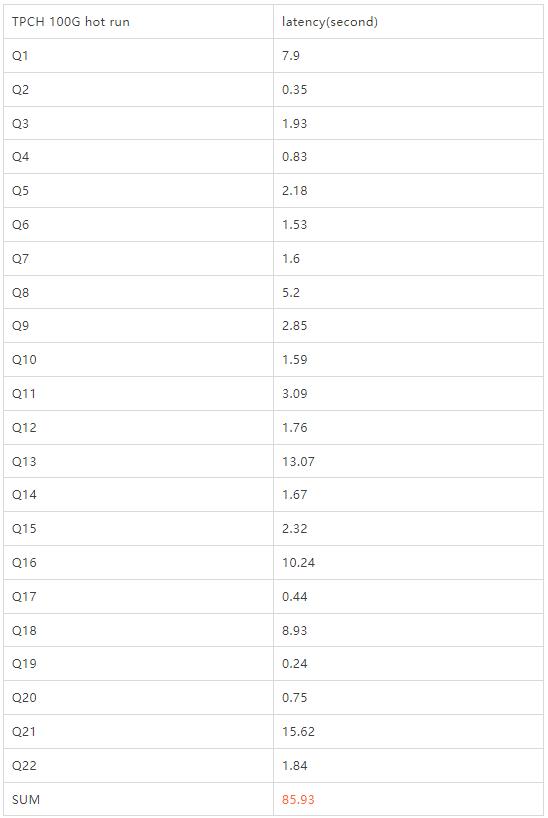
100G hot
1T hot
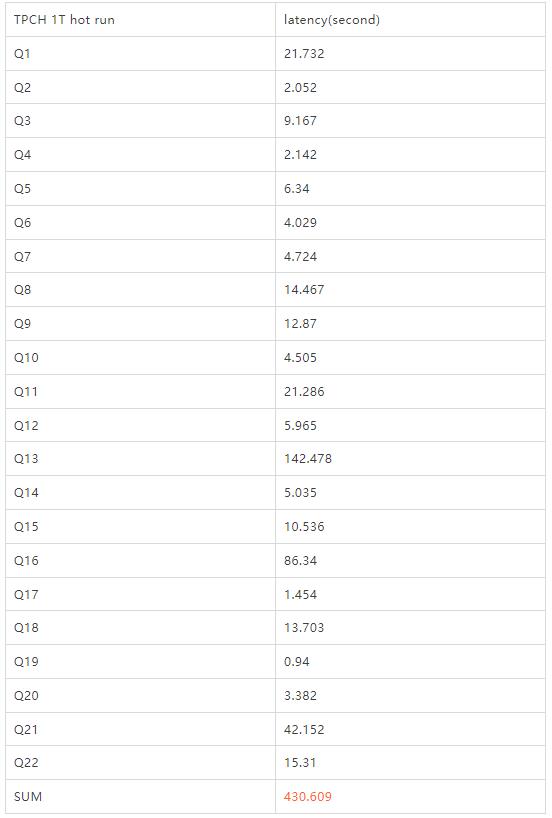
可以看到,无论是100G还是1T的数据量,多机并行都得到了非常不错的性能数据,作为一款主要面向高并发TP负载的事务型数据库,这已经体现出了PolarDB MySQL不俗的实时分析能力。
总结与展望
PolarDB MySQL的弹性多机并行(ePQ)为面向大数据量的复杂分析查询提供了更强大的实时加速能力,但其作用不止于此,作为PolarDB云原生特性的一部分,它更重要的能力是横向打通集群的计算资源,将集群中的各节点作为一个整体来考虑,或是对大表查询进行加速,或是对查询进行动态调度,从而保证分析的实时性和资源的充分均衡利用。此外与弹性能力的结合让并行能够应用到更广泛的场景中,为客户提供更极致的性价比。
多机并行的工作远没有结束,后续还有很多的优化和应用场景等待我们挖掘:
- 增强MySQL原生优化器,给出更优的join tree形态(bushy join/hash join),解决大量nested loop index lookup产生的IO thrashing问题
- 进一步增强MySQL的统计信息能力,提升最优串行/分布式计划的准确性
- 使用RDMA作为数据通道底层协议
- 支持partition-wise join/cluster-aware partition-wise join
- 支持对导出到对象存储(oss)的冷数据做分布式查询
- 支持对各类外表的联邦查询
- 在分布式执行中引入自适应机制,提升执行效率
- 。。。
敬请期待
参考资料:
[1]https://help.aliyun.com/document_detail/128615.htm
[2]https://help.aliyun.com/document_detail/422032.html
作者 | 梁辰(遥凌)
本文为阿里云原创内容,未经允许不得转载
以上是关于弹性并行查询深度剖析的主要内容,如果未能解决你的问题,请参考以下文章