面试官:大量请求 Redis 不存在的数据,从而影响数据库,该如何解决?
Posted 朱小厮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试官:大量请求 Redis 不存在的数据,从而影响数据库,该如何解决?相关的知识,希望对你有一定的参考价值。
点击上方“朱小厮的博客”,选择“设为星标”
后台回复"书",获取
后台回复“k8s”,可领取k8s资料
大家都知道,在计算机中,IO一直是一个瓶颈,很多框架以及技术甚至硬件都是为了降低IO操作而生,今天聊一聊过滤器,先说一个场景:
我们业务后端涉及数据库,当请求消息查询某些信息时,可能先检查缓存中是否有相关信息,有的话返回,如果没有的话可能就要去数据库里面查询,这时候有一个问题,如果很多请求是在请求数据库根本不存在的数据,那么数据库就要频繁响应这种不必要的IO查询,如果再多一些,数据库大多数IO都在响应这种毫无意义的请求操作。
那么如何将这些请求阻挡在外呢?过滤器由此诞生!
布隆过滤器
布隆过滤器(Bloom Filter)大概的思路就是,当你请求的信息来的时候,先检查一下你查询的数据我这有没有,有的话将请求压给数据库,没有的话直接返回,是如何做到的呢?
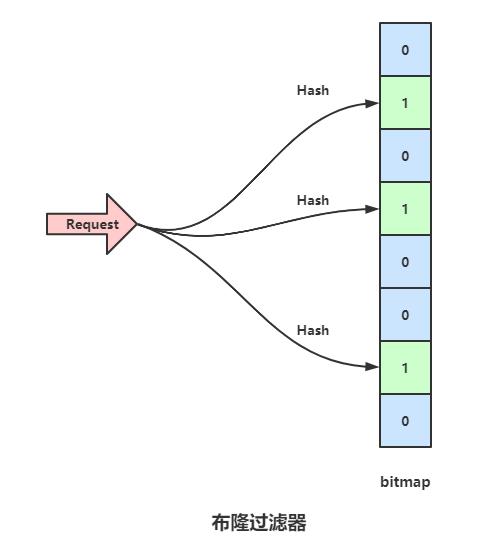
如图,一个bitmap用于记录,bitmap原始数值全都是0,当一个数据存进来的时候,用三个Hash函数分别计算三次Hash值,并且将bitmap对应的位置设置为1。
上图中,bitmap 的1,3,6位置被标记为1,这时候如果一个数据请求过来,依然用之前的三个Hash函数计算Hash值,如果是同一个数据的话,势必依旧是映射到1,3,6位,那么就可以判断这个数据之前存储过,如果新的数据映射的三个位置,有一个匹配不上,假如映射到1,3,7位,由于7位是0,也就是这个数据之前并没有加入进数据库,所以直接返回。
布隆过滤器的问题
上面这种方式,应该你已经发现了,布隆过滤器存在一些问题:
第一方面,布隆过滤器可能误判:
假如有这么一个情景,放入数据包1时,将bitmap的1,3,6位设置为了1,放入数据包2时将bitmap的3,6,7位设置为了1,此时一个并没有存过的数据包请求3,做三次哈希之后,对应的bitmap位点分别是1,6,7,这个数据之前并没有存进去过,但是由于数据包1和2存入时将对应的点设置为了1,所以请求3也会压倒数据库上,这种情况,会随着存入的数据增加而增加。
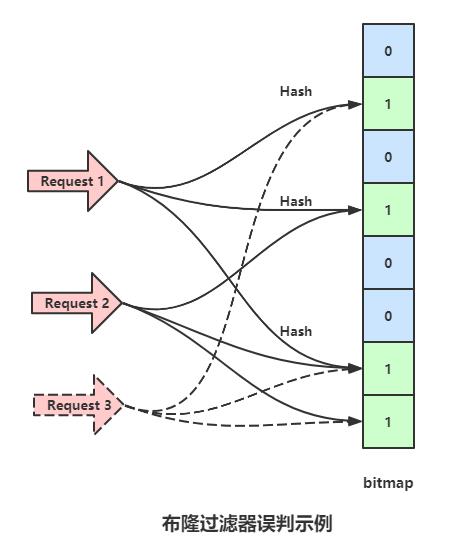
第二方面,布隆过滤器没法删除数据,删除数据存在以下两种困境:
一是,由于有误判的可能,并不确定数据是否存在数据库里,例如数据包3。
二是,当你删除某一个数据包对应位图上的标志后,可能影响其他的数据包,例如上面例子中,如果删除数据包1,也就意味着会将bitmap1,3,6位设置为0,此时数据包2来请求时,会显示不存在,因为3,6两位已经被设置为0。
布隆过滤器增强版
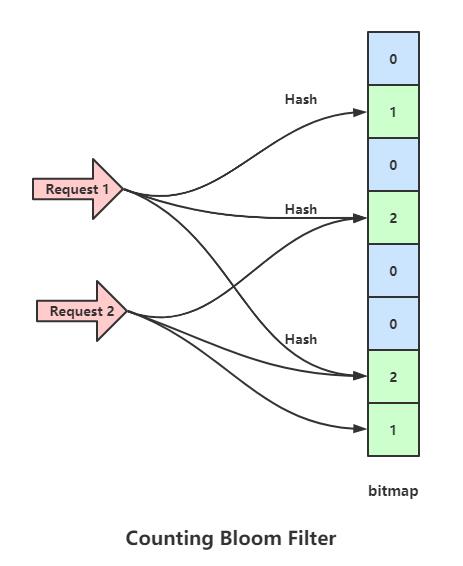
为了解决上面布隆过滤器的问题,出现了一个增强版的布隆过滤器(Counting Bloom Filter),这个过滤器的思路是将布隆过滤器的bitmap更换成数组,当数组某位置被映射一次时就+1,当删除时就-1,这样就避免了普通布隆过滤器删除数据后需要重新计算其余数据包Hash的问题,但是依旧没法避免误判。
布谷鸟过滤器
为了解决布隆过滤器不能删除元素的问题, 论文《Cuckoo Filter:Better Than Bloom》作者提出了布谷鸟过滤器。相比布谷鸟过滤器,布隆过滤器有以下不足:查询性能弱、空间利用效率低、不支持反向操作(删除)以及不支持计数。
查询性能弱是因为布隆过滤器需要使用多个 hash 函数探测位图中多个不同的位点,这些位点在内存上跨度很大,会导致 CPU 缓存行命中率低。
空间效率低是因为在相同的误判率下,布谷鸟过滤器的空间利用率要明显高于布隆,空间上大概能节省 40% 多。不过布隆过滤器并没有要求位图的长度必须是 2 的指数,而布谷鸟过滤器必须有这个要求。从这一点出发,似乎布隆过滤器的空间伸缩性更强一些。
不支持反向删除操作这个问题着实是击中了布隆过滤器的软肋。在一个动态的系统里面元素总是不断的来也是不断的走。布隆过滤器就好比是印迹,来过来就会有痕迹,就算走了也无法清理干净。比如你的系统里本来只留下 1kw 个元素,但是整体上来过了上亿的流水元素,布隆过滤器很无奈,它会将这些流失的元素的印迹也会永远存放在那里。随着时间的流失,这个过滤器会越来越拥挤,直到有一天你发现它的误判率太高了,不得不进行重建。
布谷鸟过滤器在论文里声称自己解决了这个问题,它可以有效支持反向删除操作。而且将它作为一个重要的卖点,诱惑你们放弃布隆过滤器改用布谷鸟过滤器。
为啥要取名布谷鸟呢?
有个成语,「鸠占鹊巢」,布谷鸟也是,布谷鸟从来不自己筑巢。它将自己的蛋产在别人的巢里,让别人来帮忙孵化。待小布谷鸟破壳而出之后,因为布谷鸟的体型相对较大,它又将养母的其它孩子(还是蛋)从巢里挤走 —— 从高空摔下夭折了。
布谷鸟哈希
最简单的布谷鸟哈希结构是一维数组结构,会有两个 hash 算法将新来的元素映射到数组的两个位置。如果两个位置中有一个位置为空,那么就可以将元素直接放进去。
但是如果这两个位置都满了,它就不得不「鸠占鹊巢」,随机踢走一个,然后自己霸占了这个位置。
p1 = hash1(x) % l
p2 = hash2(x) % l不同于布谷鸟的是,布谷鸟哈希算法会帮这些受害者(被挤走的蛋)寻找其它的窝。因为每一个元素都可以放在两个位置,只要任意一个有空位置,就可以塞进去。
所以这个伤心的被挤走的蛋会看看自己的另一个位置有没有空,如果空了,自己挪过去也就皆大欢喜了。但是如果这个位置也被别人占了呢?好,那么它会再来一次「鸠占鹊巢」,将受害者的角色转嫁给别人。然后这个新的受害者还会重复这个过程直到所有的蛋都找到了自己的巢为止。
布谷鸟哈希的问题
但是会遇到一个问题,那就是如果数组太拥挤了,连续踢来踢去几百次还没有停下来,这时候会严重影响插入效率。这时候布谷鸟哈希会设置一个阈值,当连续占巢行为超出了某个阈值,就认为这个数组已经几乎满了。这时候就需要对它进行扩容,重新放置所有元素。
还会有另一个问题,那就是可能会存在挤兑循环。比如两个不同的元素,hash 之后的两个位置正好相同,这时候它们一人一个位置没有问题。但是这时候来了第三个元素,它 hash 之后的位置也和它们一样,很明显,这时候会出现挤兑的循环。不过让三个不同的元素经过两次 hash 后位置还一样,这样的概率并不是很高,除非你的 hash 算法太挫了。
布谷鸟哈希算法对待这种挤兑循环的态度就是认为数组太拥挤了,需要扩容(实际上并不是这样)。
优化
上面的布谷鸟哈希算法的平均空间利用率并不高,大概只有 50%。到了这个百分比,就会很快出现连续挤兑次数超出阈值。这样的哈希算法价值并不明显,所以需要对它进行改良。
改良的方案之一是增加 hash 函数,让每个元素不止有两个巢,而是三个巢、四个巢。这样可以大大降低碰撞的概率,将空间利用率提高到 95%左右。
另一个改良方案是在数组的每个位置上挂上多个座位,这样即使两个元素被 hash 在了同一个位置,也不必立即「鸠占鹊巢」,因为这里有多个座位,你可以随意坐一个。除非这多个座位都被占了,才需要进行挤兑。
很明显这也会显著降低挤兑次数。这种方案的空间利用率只有 85%左右,但是查询效率会很高,同一个位置上的多个座位在内存空间上是连续的,可以有效利用 CPU 高速缓存。
所以更加高效的方案是将上面的两个改良方案融合起来,比如使用 4 个 hash 函数,每个位置上放 2 个座位。这样既可以得到时间效率,又可以得到空间效率。这样的组合甚至可以将空间利用率提到高 99%,这是非常了不起的空间效率。
布谷鸟过滤器
布谷鸟过滤器和布谷鸟哈希结构一样,它也是一维数组,但是不同于布谷鸟哈希的是,布谷鸟哈希会存储整个元素,而布谷鸟过滤器中只会存储元素的指纹信息(几个bit,类似于布隆过滤器)。这里过滤器牺牲了数据的精确性换取了空间效率。正是因为存储的是元素的指纹信息,所以会存在误判率,这点和布隆过滤器如出一辙。
首先布谷鸟过滤器还是只会选用两个 hash 函数,但是每个位置可以放置多个座位。这两个 hash 函数选择的比较特殊,因为过滤器中只能存储指纹信息。当这个位置上的指纹被挤兑之后,它需要计算出另一个对偶位置。而计算这个对偶位置是需要元素本身的,我们来回忆一下前面的哈希位置计算公式。
fp = fingerprint(x)
p1 = hash1(x) % l
p2 = hash2(x) % l我们知道了 p1 和 x 的指纹,是没办法直接计算出 p2 的。
特殊的 hash 函数
布谷鸟过滤器巧妙的地方就在于设计了一个独特的 hash 函数,使得可以根据 p1 和 元素指纹 直接计算出 p2,而不需要完整的 x 元素。
fp = fingerprint(x)
p1 = hash(x)
p2 = p1 ^ hash(fp) // 异或从上面的公式中可以看出,当我们知道 fp 和 p1,就可以直接算出 p2。同样如果我们知道 p2 和 fp,也可以直接算出 p1 —— 对偶性。
p1 = p2 ^ hash(fp)所以我们根本不需要知道当前的位置是 p1 还是 p2,只需要将当前的位置和 hash(fp) 进行异或计算就可以得到对偶位置。而且只需要确保 hash(fp) != 0 就可以确保 p1 != p2,如此就不会出现自己踢自己导致死循环的问题。
也许你会问为什么这里的 hash 函数不需要对数组的长度取模呢?实际上是需要的,但是布谷鸟过滤器强制数组的长度必须是 2 的指数,所以对数组的长度取模等价于取 hash 值的最后 n 位。在进行异或运算时,忽略掉低 n 位 之外的其它位就行。将计算出来的位置 p 保留低 n 位就是最终的对偶位置。
链接:www.cnblogs.com/Courage129/p/14337466.html
想知道更多?扫描下面的二维码关注我后台回复"技术",加入技术群
后台回复“k8s”,可领取k8s资料
【精彩推荐】ClickHouse到底是什么?为什么如此牛逼!
原来ElasticSearch还可以这么理解
面试官:InnoDB中一棵B+树可以存放多少行数据?
架构之道:分离业务逻辑和技术细节
星巴克不使用两阶段提交
面试官:Redis新版本开始引入多线程,谈谈你的看法?
喜马拉雅自研网关架构演进过程
收藏:存储知识全面总结
微博千万级规模高性能高并发的网络架构设计
以上是关于面试官:大量请求 Redis 不存在的数据,从而影响数据库,该如何解决?的主要内容,如果未能解决你的问题,请参考以下文章
面试官:大量请求 Redis 不存在的数据,从而影响数据库,该如何解决?
面试官:大量请求 Redis 不存在的数据,从而影响数据库,该如何解决?