CSS位置偏移反爬虫绕过
Posted web安全工具库
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CSS位置偏移反爬虫绕过相关的知识,希望对你有一定的参考价值。
0x01 初始化浏览器对象
bs=webdriver.Chrome()0x02 访问网站
bs.get('https://antispider3.scrape.center/'0x03 等待出现结果,然后再获取数据
wt=WebDriverWait(bs,10)#创建一个等待的对象,等待10秒
wt.until(ec.presence_of_all_elements_located((By.CSS_SELECTOR,'.item')))#当节点id是item出现的时候获取数据
print(bs.page_source[:100]) #获取源码 前100个字节0x04 获取网页源码并通过PyQuery初始化
html=bs.page_source
doc=py(html)0x05 获取源码中所有类item下的类name
names=doc('.item .name')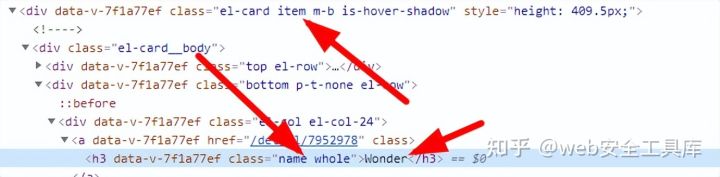
0x06 将获取的列表打印出来,并关闭创建的浏览器
for name in names.items():
print(name.text())
bs.close()0x07 运行结果,发现字体的顺序都不对
Wonder
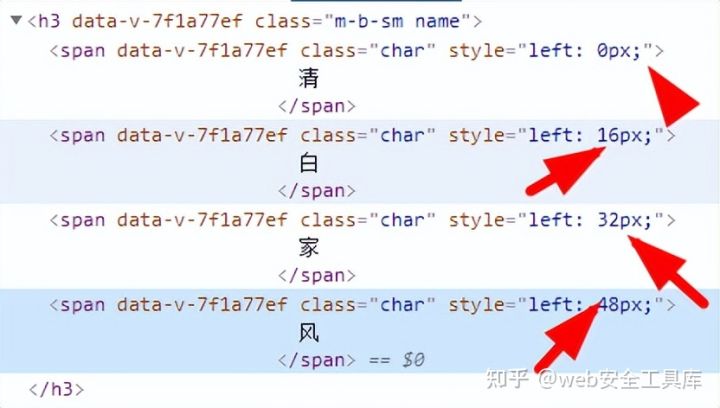
风 清 白 家
上 结 ( 宠 老 法 篇 终 的 妃 下 ) 册
士 为 知 己 ( 全 二 册 )
那 些 年 , 我 们 一 起 追 的 女 孩
全 倾 非 三 ( ) 城 我 册
明 些 儿 那 朝 事
我 和 你 的 笑 忘 书
王 小 波 全 集 第 一 卷
怦 然 动 心
龙枪编年史(全3册)
全 三 ( 奇 ) 传 册 枪 龙
明 黎 之 街
示 理 启 认 及 知 学 其 心
银河帝国2:基地与帝国
基 : 国 地 帝 河 银
解 四 年 - 材 教 学 下 文 小 全 级 语
越界言论(第3卷)0x08 分析原因
正确的顺序应该是按后面的值排序,所以我们只要再获取一个style的值,然后进行排序
def paixu(name):
ts=name('.whole')#一种根据类whole判断
if ts:
return name.text()
else:
chars=name('.char')#另一种根据类char判断
items=[]
for char in chars.items():#将过滤后的内容填写到一个列表里
items.append(
'text':char.text().strip(),'left':int(re.search('(\\d+)px',char.attr('style')).group(1))
)
items=sorted(items,key=lambda x: x['left'],reverse=False)#根据关键字left排序
return ''.join([item.get('text') for item in items])#只返回text的内容0x09 最终源码
import re
from selenium import webdriver
from pyquery import PyQuery as py
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
def paixu(name):
ts=name('.whole')
if ts:
return name.text()
else:
chars=name('.char')
items=[]
for char in chars.items():
items.append(
'text':char.text().strip(),'left':int(re.search('(\\d+)px',char.attr('style')).group(1))
)
items=sorted(items,key=lambda x: x['left'],reverse=False)
return ''.join([item.get('text') for item in items])
bs=webdriver.Chrome()
bs.get('https://antispider3.scrape.center/')
wt=WebDriverWait(bs,10)
wt.until(ec.presence_of_all_elements_located((By.CSS_SELECTOR,'.item')))
html=bs.page_source
doc=py(html)
names=doc('.item .name')
for i in names.items():
name=paixu(i)
print(name)
bs.close()0x10 声明
本内容摘自《Python3网络爬虫开发实战 第二版》作者:崔天才
仅供安全研究与学习之用,若将工具做其他用途,由使用者承担全部法律及连带责任,作者不承担任何法律及连带责任。
欢迎关注公众号编程者吧

以上是关于CSS位置偏移反爬虫绕过的主要内容,如果未能解决你的问题,请参考以下文章
24. CSS偏移反爬见过没,打开本文你就能学会 | 爬虫训练场