爬虫与反爬虫技术简介
Posted 格格巫 MMQ!!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫与反爬虫技术简介相关的知识,希望对你有一定的参考价值。
互联网的大数据时代的来临,网络爬虫也成了互联网中一个重要行业,它是一种自动获取网页数据信息的爬虫程序,是网站搜索引擎的重要组成部分。通过爬虫,可以获取自己想要的相关数据信息,让爬虫协助自己的工作,进而降低成本,提高业务成功率和提高业务效率。
本文一方面从爬虫与反反爬的角度来说明如何高效的对网络上的公开数据进行爬取,另一方面也会介绍反爬虫的技术手段,为防止外部爬虫大批量的采集数据的过程对服务器造成超负载方面提供些许建议。
爬虫指的是按照一定规则自动抓取万维网信息的程序,本次主要会从爬虫的技术原理与实现,反爬虫与反反爬虫两个方面进行简单的介绍,介绍的案例均只是用于安全研究和学习,并不会进行大量爬虫或者应用于商业。
一、爬虫的技术原理与实现
1.1 爬虫的定义
爬虫分为通用爬虫和聚焦爬虫两大类,前者的目标是在保持一定内容质量的情况下爬取尽可能多的站点,比如百度这样的搜索引擎就是这种类型的爬虫,如图1是通用搜索引擎的基础架构:
首先在互联网中选出一部分网页,以这些网页的链接地址作为种子URL;
将这些种子URL放入待抓取的URL队列中,爬虫从待抓取的URL队列依次读取;
将URL通过DNS解析,把链接地址转换为网站服务器对应的IP地址;
网页下载器通过网站服务器对网页进行下载,下载的网页为网页文档形式;
对网页文档中的URL进行抽取,并过滤掉已经抓取的URL;
对未进行抓取的URL继续循环抓取,直至待抓取URL队列为空。
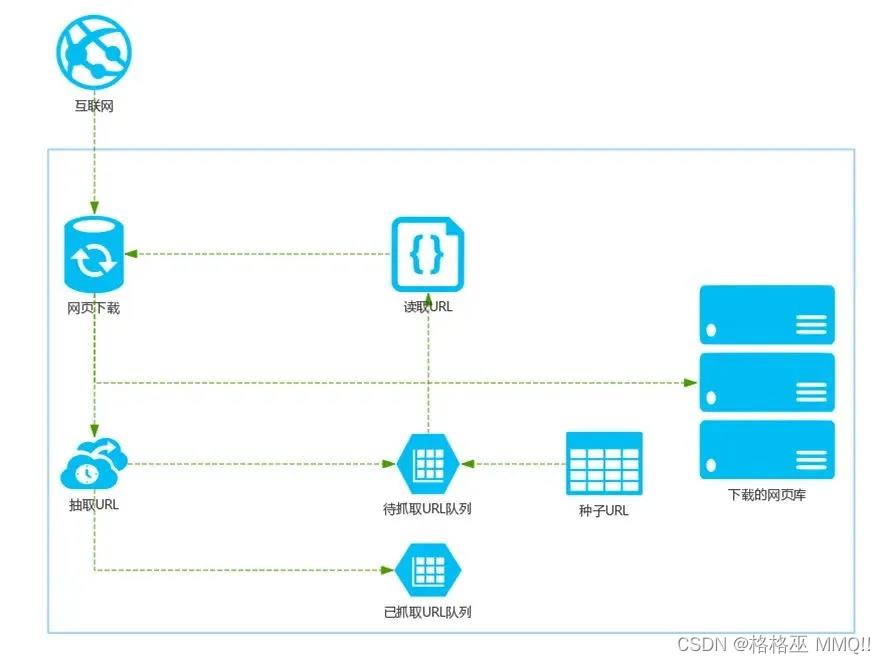
图1.通用搜索引擎的基础架构
爬虫通常从一个或多个 URL 开始,在爬取的过程中不断将新的并且符合要求的 URL 放入待爬队列,直到满足程序的停止条件。
而我们日常见到的爬虫基本为后者,目标是在爬取少量站点的情况下尽可能保持精准的内容质量。典型的比如图2抢票软件所示,就是利用爬虫来登录售票网络并爬取信息,从而辅助商业。
了解了爬虫的定义后,那么应该如何编写爬虫程序来爬取我们想要的数据呢。我们可以先了解下目前常用的爬虫框架,因为它可以将一些常见爬虫功能的实现代码写好,然后留下一些接口,在做不同的爬虫项目时,我们只需要根据实际情况,手写少量需要变动的代码部分,并按照需要调用这些接口,即可以实现一个爬虫项目。
1.2 爬虫框架介绍
常用的搜索引擎爬虫框架如图3所示,首先Nutch是专门为搜索引擎设计的爬虫,不适合用于精确爬虫。Pyspider和Scrapy都是python语言编写的爬虫框架,都支持分布式爬虫。另外Pyspider由于其可视化的操作界面,相比Scrapy全命令行的操作对用户更加友好,但是功能不如Scrapy强大。
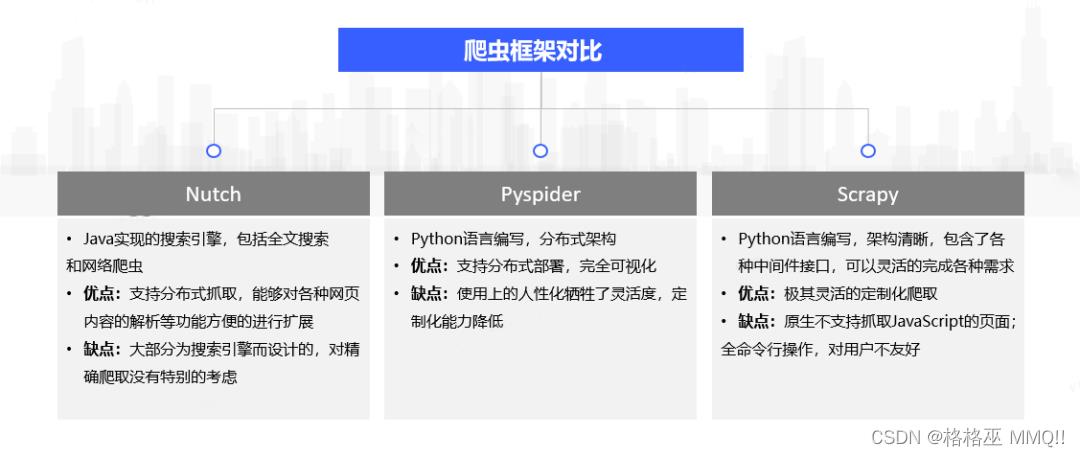
图3.爬虫框架对比
1.3 爬虫的简单示例
除了使用爬虫框架来进行爬虫,也可以从头开始来编写爬虫程序,步骤如图4所示:
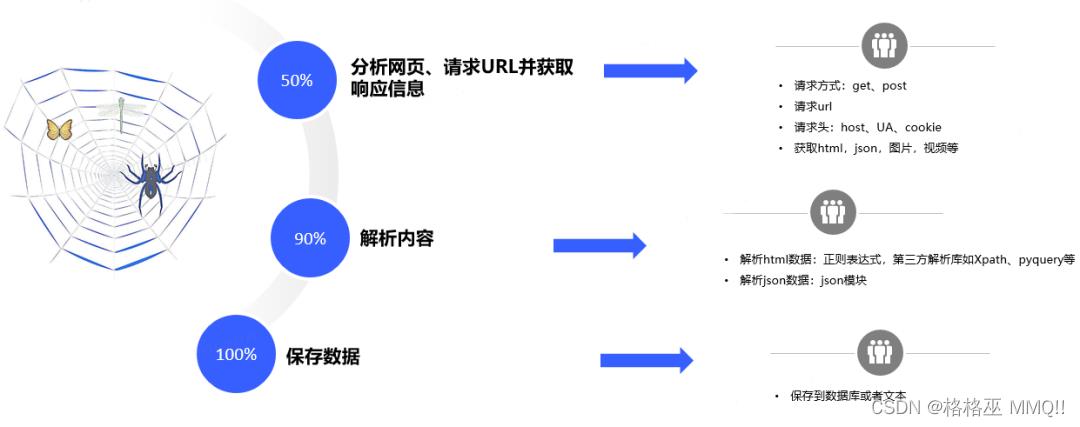
图4.爬虫的基本原理
接下来通过一个简单的例子来实际演示上述的步骤,我们要爬取的是某应用市场的榜单,以这个作为例子,是因为这个网站没有任何的反爬虫手段,我们通过上面的步骤可以轻松爬取到内容。

图5.网页与其对应的源代码
网页与其对应的源代码如图5所示,对于网页上的数据,假定我们想要爬取排行榜上每个app的名称以及其分类。
我们首先分析网页源代码,发现可以直接在网页源代码中搜索到“抖音”等app的名称,接着看到app名称、app类别等都是在一个
- 标签里,所以我们只需要请求网页地址,拿到返回的网页源代码,然后对网页源代码进行正则匹配,提取出想要的数据,保存下来即可,如图6所示。
-
复制代码
#获取网页源码
def get_one_page(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None#正则匹配提取目标信息并形成字典
def parse_one_page(html):
pattern = re.compile(‘ - .?data-src="(.?)".?
.?det.?>(.?).?p.?<a.?>(.?).*?
- ’,re.S)
items = re.findall(pattern, html)
j = 1
for item in items[:-1]:
yield ‘index’: str(j),
‘name’: item[1],
‘class’:item[2]
j = j+1#结果写入txt
def write_to_file(content):
with open(r’test.txt’, ‘a’, encoding=‘utf-8’) as f:
f.write(json.dumps(content, ensure_ascii=False)+‘\\n’)
复制代码
图6.爬虫的代码以及结果
二、反爬虫相关技术
在了解具体的反爬虫措施之前,我们先介绍下反爬虫的定义和意义,限制爬虫程序访问服务器资源和获取数据的行为称为反爬虫。爬虫程序的访问速率和目的与正常用户的访问速率和目的是不同的,大部分爬虫会无节制地对目标应用进行爬取,这给目标应用的服务器带来巨大的压力。爬虫程序发出的网络请求被运营者称为“垃圾流量”。开发者为了保证服务器的正常运转或降低服务器的压力与运营成本,不得不使出各种各样的技术手段来限制爬虫对服务器资源的访问。所以为什么要做反爬虫,答案是显然的,爬虫流量会提升服务器的负载,过大的爬虫流量会影响到服务的正常运转,从而造成收入损失,另一方面,一些核心数据的外泄,会使数据拥有者失去竞争力。
常见的反爬虫手段,如图7所示。主要包含文本混淆、页面动态渲染、验证码校验、请求签名校验、大数据风控、js混淆和蜜罐等,其中文本混淆包含css偏移、图片伪装文本、自定义字体等,而风控策略的制定则往往是从参数校验、行为频率和模式异常等方面出发的。

图7.常见的反爬虫手段
2.1 CSS偏移反爬虫
在搭建网页的时候,需要用CSS来控制各类字符的位置,也正是如此,可以利用CSS来将浏览器中显示的文字,在HTML中以乱序的方式存储,从而来限制爬虫。CSS偏移反爬虫,就是一种利用CSS样式将乱序的文字排版成人类正常阅读顺序的反爬虫手段。这个概念不是很好理解,我们可以通过对比两段文字来加深对这个概念的理解:HTML 文本中的文字:我的学号是 1308205,我在北京大学读书。
浏览器显示的文字:我的学号是 1380205,我在北京大学读书。
以上两段文字中浏览器显示的应该是正确的信息,如果我们按之前提到的爬虫步骤,分析网页后正则提取信息,会发现学号是错的。
接着看图8所示的例子,如果我们想爬取该网页上的机票信息,首先需要分析网页。红框所示的价格467对应的是中国民航的从石家庄到上海的机票,但是分析网页源代码发现代码中有 3 对 b 标签,第 1 对 b 标签中包含 3 对 i 标签,i 标签中的数字都是 7,也就是说第 1 对 b 标签的显示结果应该是 777。而第 2 对 b 标签中的数字是 6,第 3 对 b 标签中的数字是 4,这样的话我们会无法直接通过正则匹配得到正确的机票价格。
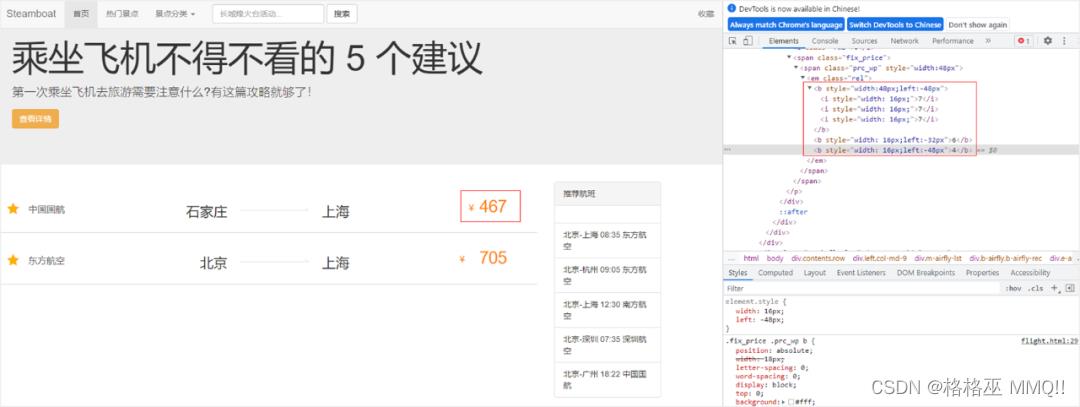
图8.CSS 偏移反爬虫例子
2.2 图片伪装反爬虫
图片伪装反爬虫,它的本质就是用图片替换了原来的内容,从而让爬虫程序无法正常获取,如图9所示。这种反爬虫的原理十分简单,就是将本应是普通文本内容的部分在前端页面中用图片来进行替换,遇到这种案例可以直接用ocr识别图片中的文字就可以绕过。而且因为是用图片替换文本显示,所以图片本身会相对比较清晰,没有很多噪声干扰,ocr识别的结果会很准确。
图9. 图片伪装反爬虫例子
2.3 自定义字体反爬虫
在 CSS3 时代,开发者可以使用@font-face为网页指定字体。开发者可将心仪的字体文件放在 Web 服务器上,并在 CSS 样式中使用它。用户使用浏览器访问 Web 应用时,对应的字体会被浏览器下载到用户的计算机上,但是我们在使用爬虫程序时,由于没有相应的字体映射关系,直接爬取就会无法得到有效数据。如图10所示,该网页中每个店铺的评价数、人均、口味、环境等信息均是乱码字符,爬虫无法直接读取到内容。

图10. 自定义字体反爬虫例子
2.4 页面动态渲染反爬虫
网页按渲染方式的不同,大体可以分为客户端和服务端渲染。服务端渲染,页面的结果是由服务器渲染后返回的,有效信息包含在请求的 HTML 页面里面,通过查看网页源代码可以直接查看到数据等信息;
客户端渲染,页面的主要内容由 javascript 渲染而成,真实的数据是通过 Ajax 接口等形式获取的,通过查看网页源代码,无有效数据信息。
客户端渲染和服务器端渲染的最重要的区别就是究竟是谁来完成html文件的完整拼接,如果是在服务器端完成的,然后返回给客户端,就是服务器端渲染,而如果是前端做了更多的工作完成了html的拼接,则就是客户端渲染。
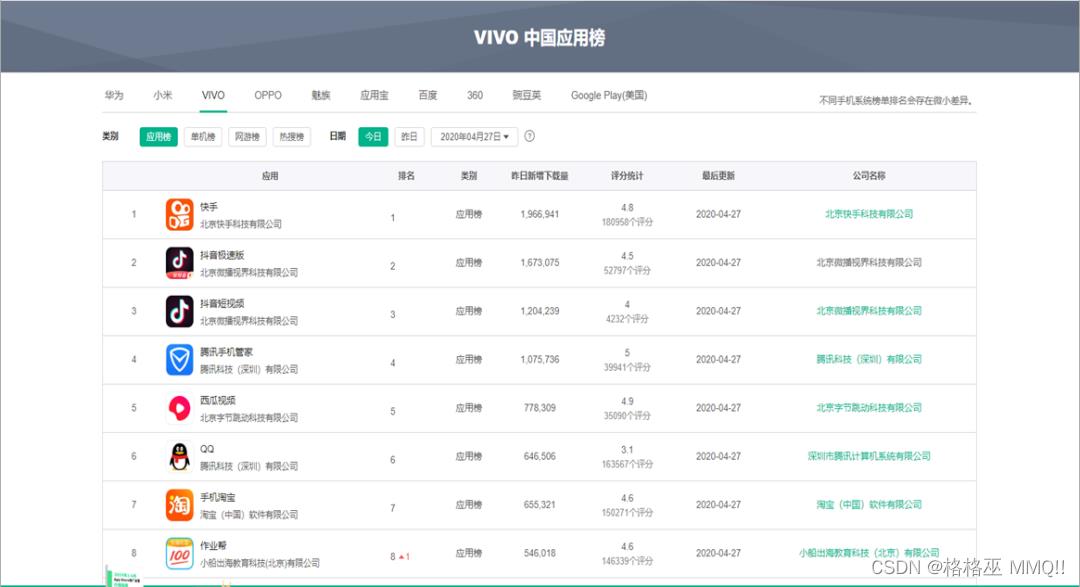
图11.客户端渲染例子
2.5 验证码反爬虫
几乎所有的应用程序在涉及到用户信息安全的操作时,都会弹出验证码让用户进行识别,以确保该操作为人类行为,而不是大规模运行的机器。那为什么会出现验证码呢?在大多数情形下是因为网站的访问频率过高或者行为异常,或者是为了直接限制某些自动化行为。归类如下:很多情况下,比如登录和注册,这些验证码几乎是必现的,它的目的就是为了限制恶意注册、恶意爆破等行为,这也算反爬的一种手段。
一些网站遇到访问频率过高的行为的时候,可能会直接弹出一个登录窗口,要求我们登录才能继续访问,此时的验证码就直接和登录表单绑定在一起了,这就算检测到异常之后利用强制登录的方式进行反爬。
一些较为常规的网站如果遇到访问频率稍高的情形的时候,会主动弹出一个验证码让用户识别并提交,验证当前访问网站的是不是真实的人,用来限制一些机器的行为,实现反爬虫。
常见的验证码形式包括图形验证码、行为验证码、短信、扫码验证码等,如图12所示。对于能否成功通过验证码,除了能够准确的根据验证码的要求完成相应的点击、选择、输入等,通过验证码风控也至关重要;比如对于滑块验证码,验证码风控可能会针对滑动轨迹进行检测,如果检测出轨迹非人为,就会判定为高风险,导致无法成功通过。
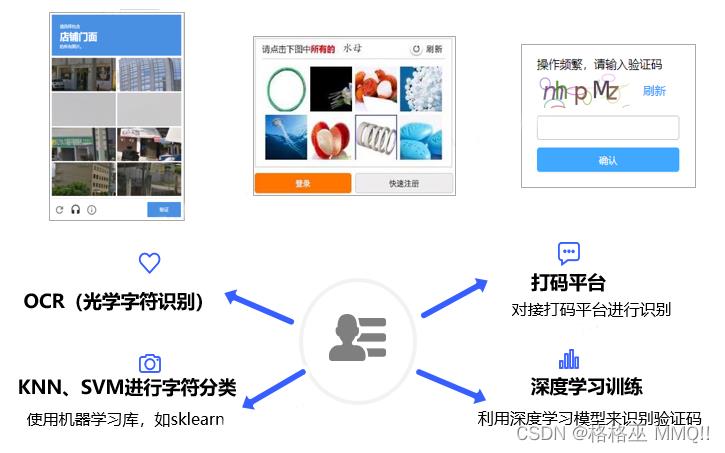
图12.验证码反爬虫手段
2.6 请求签名校验反爬虫
签名验证是防止服务器被恶意链接和篡改数据的有效方式之一,也是目前后端API最常用的防护方式之一。签名是一个根据数据源进行计算或者加密的过程,用户经过签名后会一个具有一致性和唯一性的字符串,它就是你访问服务器的身份象征。由它的一致性和唯一性这两种特性,从而可以有效的避免服务器端,将伪造的数据或被篡改的数据当初正常数据处理。前面在2.4节提到的网站是通过客户端渲染网页,数据则是通过ajax请求拿到的,这种在一定程度上提升了爬虫的难度。接下来分析ajax请求,如图13所示,会发现其ajax请求是带有请求签名的,analysis就是加密后的参数,而如果想要破解请求接口,就需要破解该参数的加密方法,这无疑进一步提升了难度。

图13. 请求榜单数据的ajax请求
2.7 蜜罐反爬虫
标签却有 8 对。该 CSS 样式的作用是隐藏标签,所以我们在页面只看到 6 件商品,爬虫程序会提取到 8 件商品的 URL。
蜜罐反爬虫,是一种在网页中隐藏用于检测爬虫程序的链接的手段,被隐藏的链接不会显示在页面中,正常用户无法访问,但爬虫程序有可能将该链接放入待爬队列,并向该链接发起请求,开发者可以利用这个特点区分正常用户和爬虫程序。如图14所示,查看网页源码,页面只有6个商品,col-md-3的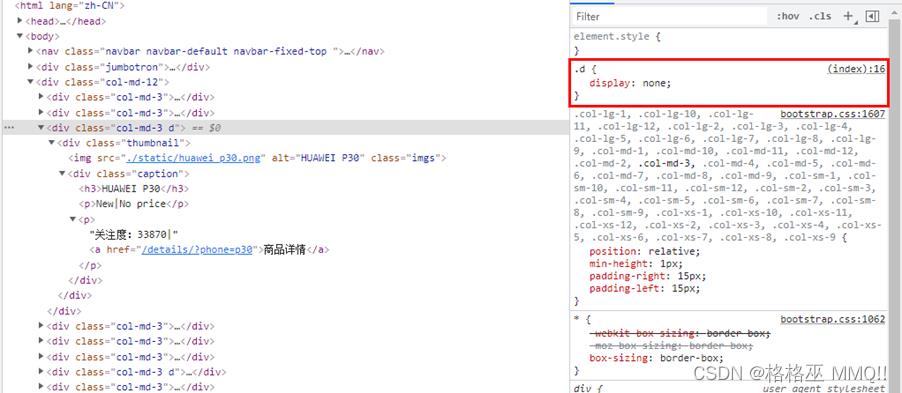
图14.蜜罐反爬虫例子
三、反反爬相关技术
针对上一节提到的反爬虫相关技术,有以下几类反反爬技术手段:css偏移反反爬、自定义字体反反爬、页面动态渲染反反爬、验证码破解等,下面对这几类方法进行详细的介绍。3.1 CSS偏移反反爬
3.1.1 CSS偏移逻辑介绍
那么对于以上2.1css偏移反爬虫的例子,怎么才能得到正确的机票价格呢。仔细观察css样式,可以发现每个带有数字的标签都设定了样式,第 1 对 b 标签内的i 标签对的样式是相同的,都是width: 16px;另外,还注意到最外层的 span 标签对的样式为width:48px。如果按照 css样式这条线索来分析的话,第 1 对 b 标签中的 3 对 i 标签刚好占满 span 标签对的位置,其位置如图15所示。此时网页中显示的价格应该是 777,但是由于第 2 和第 3 对 b 标签中有值,所以我们还需要计算它们的位置。由于第 2 对 b 标签的位置样式是 left:-32px,所以第 2 对 b 标签中的值 6 就会覆盖原来第 1 对 b 标签中的中的第 2 个数字 7,此时页面应该显示的数字是 767。
按此规律推算,第 3 对 b 标签的位置样式是 left:-48px,这个标签的值会覆盖第 1 对 b 标签中的第 1 个数字 7,最后显示的票价就是 467。
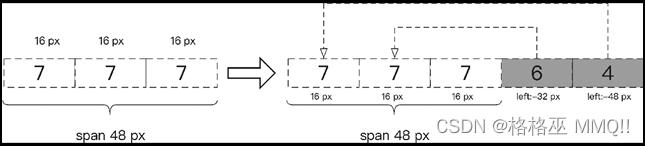
图15.偏移逻辑
3.1.2 CSS偏移反反爬代码实现
因此接下来我们按以上css样式的规律来编写代码对该网页爬取获取正确的机票价格,代码和结果如图16所示。复制代码
if name == ‘main’:
url = ‘http://www.porters.vip/confusion/flight.html’
resp = requests.get(url)
sel = Selector(resp.text)
em = sel.css(‘em.rel’).extract()
for element in range(0,1):
element = Selector(em[element])
element_b = element.css(‘b’).extract()
b1 = Selector(element_b.pop(0))
base_price = b1.css(‘i::text’).extract()
print(‘css偏移前的价格:’,base_price)alternate_price = [] for eb in element_b: eb = Selector(eb) style = eb.css('b::attr("style")').get() position = ''.join(re.findall('left:(.*)px', style)) value = eb.css('b::text').get() alternate_price.append('position': position, 'value': value) print('css偏移值:',alternate_price) for al in alternate_price: position = int(al.get('position')) value = al.get('value') plus = True if position >= 0 else False index = int(position / 16) base_price[index] = value print('css偏移后的价格:',base_price)复制代码

图16. CSS 偏移反反爬代码与结果
3.2 自定义字体反反爬
针对于以上2.3自定义字体反爬虫的情况,解决思路就是提取出网页中自定义字体文件(一般为WOFF文件),并将映射关系包含到爬虫代码中,就可以获取到有效数据。解决的步骤如下:发现问题:查看网页源代码,发现关键字符被编码替代,如

分析:检查网页,发现应用了css自定义字符集隐藏


查找:查找css文件url,获取字符集对应的url,如PingFangSC-Regular-num
查找:查找和下载字符集url
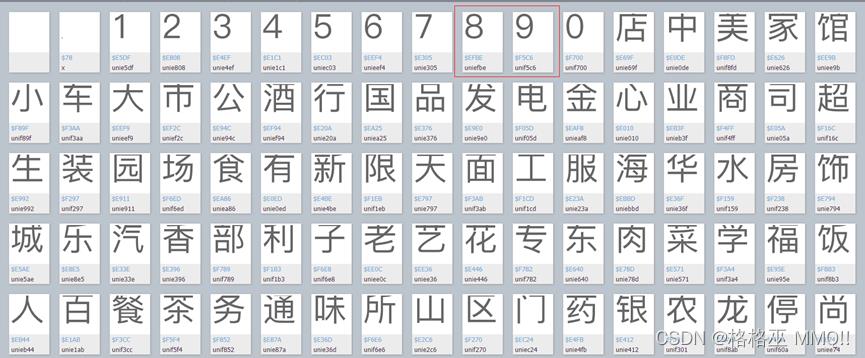
比对:比对字符集中的字符与网页源代码中的编码,发现编码的后四位与字符对应,也即网页源代码对应的口味是8.9分

3.3 页面动态渲染反反爬
客户端渲染的反爬虫,页面代码在浏览器源代码中看不到,需要执行渲染并进一步获取渲染后结果。针对这种反爬虫,有以下几种方式破解:在浏览器中,通过开发者工具直接查看ajax具体的请求方式、参数等内容;
通过selenium模拟真人操作浏览器,获取渲染后的结果,之后的操作步骤和服务端渲染的流程一样;
如果渲染的数据隐藏在html结果的JS变量中,可以直接正则提取;
如果有通过JS生成的加密参数,可以找出加密部分的代码,然后使用pyexecJS来模拟执行JS,返回执行结果。
3.4 验证码破解
下面举例一个识别滑块验证码的例子,如图17所示,是使用目标检测模型来识别某滑块验证码缺口位置的结果示例,这种破解滑块验证码的方式对应的是模拟真人的方式。不采用接口破解的原因一方面是破解加密算法有难度,另一方面也是加密算法可能每天都会变,这样破解的时间成本也比较大。
图17. 通过目标检测模型识别滑块验证码的缺口
3.4.1 爬取滑块验证码图片
因为使用的目标检测模型yolov5是有监督学习,所以需要爬取滑块验证码的图片并进行打标,进而输入到模型中训练。通过模拟真人的方式在某场景爬取部分验证码。
图18. 爬取的滑块验证码图片
3.4.2 人工打标
本次使用的是labelImg来对图片人工打标签的,人工打标耗时较长,100张图片一般耗时40分钟左右。自动打标代码写起来比较复杂,主要是需要分别提取出验证码的所有背景图片和缺口图片,然后随机生成缺口位置,作为标签,同时将缺口放到对应的缺口位置,生成图片,作为输入。

图19. 对验证码图片打标签以及打标签后生成的xml文件
3.4.3 目标检测模型yolov5
直接从github下clone yolov5的官方代码,它是基于pytorch实现。接下来的使用步骤如下:
数据格式转换:将人工标注的图片和标签文件转换为yolov5接收的数据格式,得到1100张图片和1100个yolov5格式的标签文件;
新建数据集:新建custom.yaml文件来创建自己的数据集,包括训练集和验证集的目录、类别数目、类别名;
训练调优:修改模型配置文件和训练文件后,进行训练,并根据训练结果调优超参数。
转换xml文件为yolov5格式的部分脚本:
复制代码
for member in root.findall(‘object’):
class_id = class_text.index(member[0].text)xmin = int(member[4][0].text) ymin = int(member[4][1].text) xmax = int(member[4][2].text) ymax = int(member[4][3].text) # round(x, 6) 这里我设置了6位有效数字,可根据实际情况更改 center_x = round(((xmin + xmax) / 2.0) * scale / float(image.shape[1]), 6) center_y = round(((ymin + ymax) / 2.0) * scale / float(image.shape[0]), 6) box_w = round(float(xmax - xmin) * scale / float(image.shape[1]), 6) box_h = round(float(ymax - ymin) * scale / float(image.shape[0]), 6) file_txt.write(str(class_id)) file_txt.write(' ') file_txt.write(str(center_x)) file_txt.write(' ') file_txt.write(str(center_y)) file_txt.write(' ') file_txt.write(str(box_w)) file_txt.write(' ') file_txt.write(str(box_h)) file_txt.write('\\n') file_txt.close()复制代码
训练参数设置:
复制代码
parser = argparse.ArgumentParser()
parser.add_argument(‘–weights’, type=str, default=‘yolov5s.pt’, help=‘initial weights path’)
parser.add_argument(‘–cfg’, type=str, default=‘./models/yolov5s.yaml’, help=‘model.yaml path’)
parser.add_argument(‘–data’, type=str, default=‘data/custom.yaml’, help=‘data.yaml path’)
parser.add_argument(‘–hyp’, type=str, default=‘data/hyp.scratch.yaml’, help=‘hyperparameters path’)parser.add_argument(‘–epochs’, type=int, default=300)
parser.add_argument(‘–epochs’, type=int, default=50)
parser.add_argument(‘–batch-size’, type=int, default=16, help=‘total batch size for all GPUs’)
parser.add_argument(‘–batch-size’, type=int, default=8, help=‘total batch size for all GPUs’)
parser.add_argument(‘–img-size’, nargs=‘+’, type=int, default=[640, 640], help=‘[train, test] image sizes’)
parser.add_argument(‘–rect’, action=‘store_true’, help=‘rectangular training’)
parser.add_argument(‘–resume’, nargs=‘?’, const=True, default=False, help=‘resume most recent training’)
parser.add_argument(‘–nosave’, action=‘store_true’, help=‘only save final checkpoint’)
parser.add_argument(‘–notest’, action=‘store_true’, help=‘only test final epoch’)
parser.add_argument(‘–noautoanchor’, action=‘store_true’, help=‘disable autoanchor check’)
parser.add_argument(‘–evolve’, action=‘store_true’, help=‘evolve hyperparameters’)
parser.add_argument(‘–bucket’, type=str, default=‘’, help=‘gsutil bucket’)
parser.add_argument(‘–cache-images’, action=‘store_true’, help=‘cache images for faster training’)
parser.add_argument(‘–image-weights’, action=‘store_true’, help=‘use weighted image selection for training’)
parser.add_argument(‘–device’, default=‘cpu’, help=‘cuda device, i.e. 0 or 0,1,2,3 or cpu’)
parser.add_argument(‘–multi-scale’, action=‘store_true’, help=‘vary img-size +/- 50%%’)
parser.add_argument(‘–single-cls’, action=‘store_true’, help=‘train multi-class data as single-class’)
parser.add_argument(‘–adam’, action=‘store_true’, help=‘use torch.optim.Adam() optimizer’)
parser.add_argument(‘–sync-bn’, action=‘store_true’, help=‘use SyncBatchNorm, only available in DDP mode’)
parser.add_argument(‘–local_rank’, type=int, default=-1, help=‘DDP parameter, do not modify’)
parser.add_argument(‘–workers’, type=int, default=8, help=‘maximum number of dataloader workers’)
parser.add_argument(‘–project’, default=‘runs/train’, help=‘save to project/name’)
parser.add_argument(‘–entity’, default=None, help=‘W&B entity’)
parser.add_argument(‘–name’, default=‘exp’, help=‘save to project/name’)
parser.add_argument(‘–exist-ok’, action=‘store_true’, help=‘existing project/name ok, do not increment’)
parser.add_argument(‘–quad’, action=‘store_true’, help=‘quad dataloader’)
parser.add_argument(‘–linear-lr’, action=‘store_true’, help=‘linear LR’)
parser.add_argument(‘–label-smoothing’, type=float, default=0.0, help=‘Label smoothing epsilon’)
parser.add_argument(‘–upload_dataset’, action=‘store_true’, help=‘Upload dataset as W&B artifact table’)
parser.add_argument(‘–bbox_interval’, type=int, default=-1, help=‘Set bounding-box image logging interval for W&B’)
parser.add_argument(‘–save_period’, type=int, default=-1, help=‘Log model after every “save_period” epoch’)
parser.add_argument(‘–artifact_alias’, type=str, default=“latest”, help=‘version of dataset artifact to be used’)
opt = parser.parse_args()
复制代码3.4.4 目标检测模型的训练结果
模型基本在50次迭代的时候在precision和recall以及mAP上已经达到了瓶颈。预测结果也有如下问题:大部分能够是能够准确框出缺口,但也出现少量框错、框出两个缺口、框不出缺口的情况。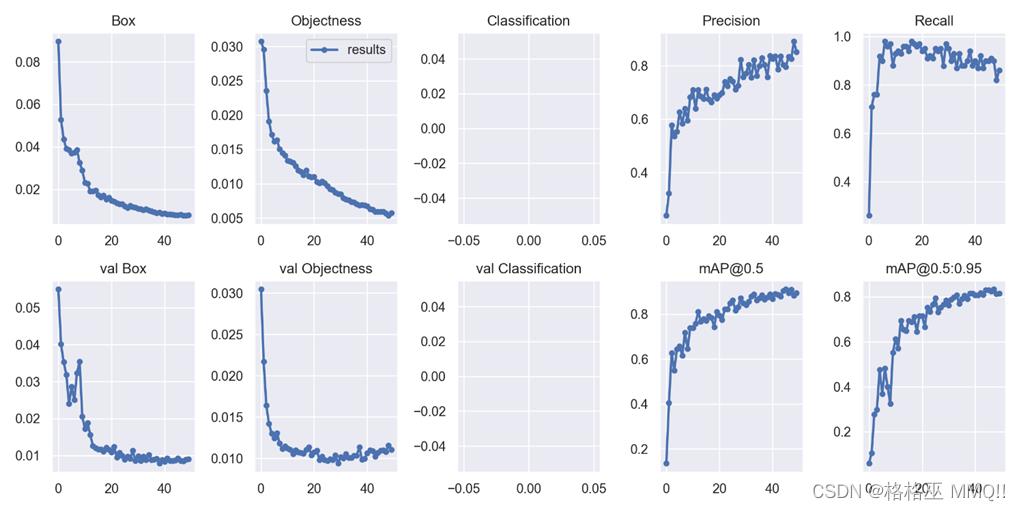

图20. 上:模型的训练结果走势图;下:模型对部分验证集的预测结果
四、总结
本次简单对爬虫以及反爬虫的技术手段进行了介绍,介绍的技术和案例均只是用于安全研究和学习,并不会进行大量爬虫或者应用于商业。对于爬虫,本着爬取网络上公开数据用于数据分析等的目的,我们应该遵守网站robots协议,本着不影响网站正常运行以及遵守法律的情况下进行数据爬取;对于反爬虫,因为只要人类能够正常访问的网页,爬虫在具备同等资源的情况下就一定可以抓取到。所以反爬虫的目的还是在于能够防止爬虫在大批量的采集网站信息的过程对服务器造成超负载,从而杜绝爬虫行为妨碍到用户的体验,来提高用户使用网站服务的满意度。
以上是关于爬虫与反爬虫技术简介的主要内容,如果未能解决你的问题,请参考以下文章