这AI保熟吗?大谷Stable Diffusion巨制:《华强买瓜》好莱坞巨星版来了!
Posted 程序员的店小二
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了这AI保熟吗?大谷Stable Diffusion巨制:《华强买瓜》好莱坞巨星版来了!相关的知识,希望对你有一定的参考价值。
这段时间,Stable Diffusion简直不要太火。
前两天,大谷就用它做了个《华强买瓜》——好莱坞国际巨星版。
瓜熟不熟不知道,但这AI保熟吗?

一句话,就换了1、2、3、4个…演员。

大谷表示,这些画面是在加载原视频之后,直接根据输入文字的变化生成的。

都认出来的朋友请扣1。
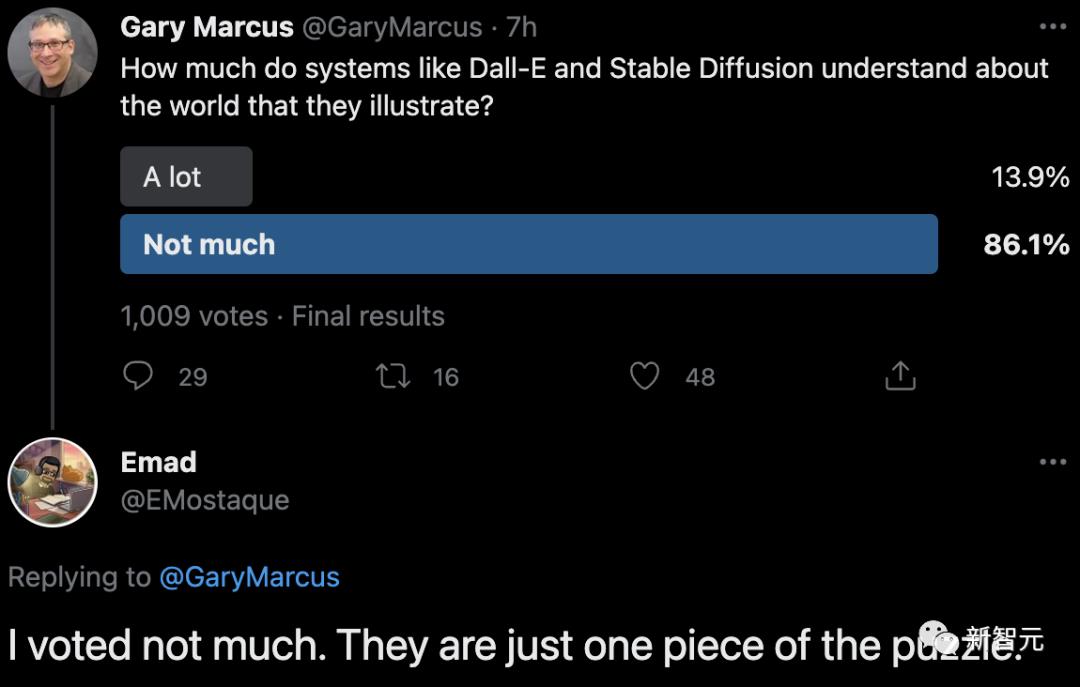
画得很好,但这对AGI有啥帮助么?
毫无疑问的是,像Dall-E、Imagen、Midjourney和Stable Diffusion这样的工具,在绘图方面已经非常出色了。
但在评估AGI的发展进程时,还有一个关键性的问题:这些「AI」对世界到底有多少了解,以至于它们可以根据这些知识进行推理和反馈?
对此,马库斯在他最新的文章中,提出了质疑:
-
图像合成系统能产生高质量的图像吗?
-
它们能将其语言输入与它们产生的图像联系起来吗?
-
它们是否理解它们所代表的图像背后的世界?

关于第1点,答案显然是肯定的。除了那些经过训练的人类艺术家,才能做得比AI更好。
关于第2点,答案是好坏参半。AI在某些输入上做得很好(比如宇航员骑马),但在其他输入上做得就不怎么理想(比如马骑宇航员)。
而第3点,也是最重要的的一点。它的答案最终决定了这些AI系统能否在构建通用智能,也就是AGI时派上用场。

虽说它们生成的图像十分绚丽,而且很可能会彻底改变艺术实践,但这仍然不能说明或代表AGI方面的进展。
就拿平面设计师Irina Blok的这张非常有名的「有很多洞的咖啡杯」来说吧。
马库斯表示,自己8岁的孩子看完之后都无法理解:「咖啡为何不会从杯子的洞里漏出来?」

然而,这种创作的麻烦在于,你没有一个关于不存在的东西应该是什么样子的事实性证据,所以只讨论结果的话,就会陷入死循环。
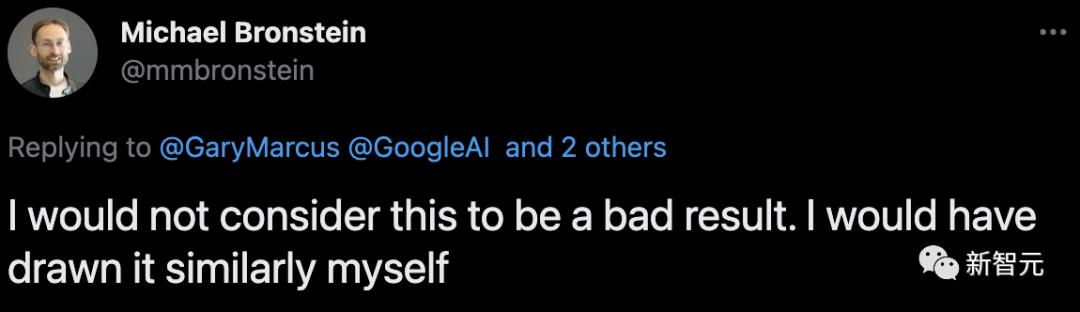
正如Michael Bronstein所指出的那样:「换做是人,也会选择这么画」。
因此,我们可以换一个不同的方式来追问同一个问题:
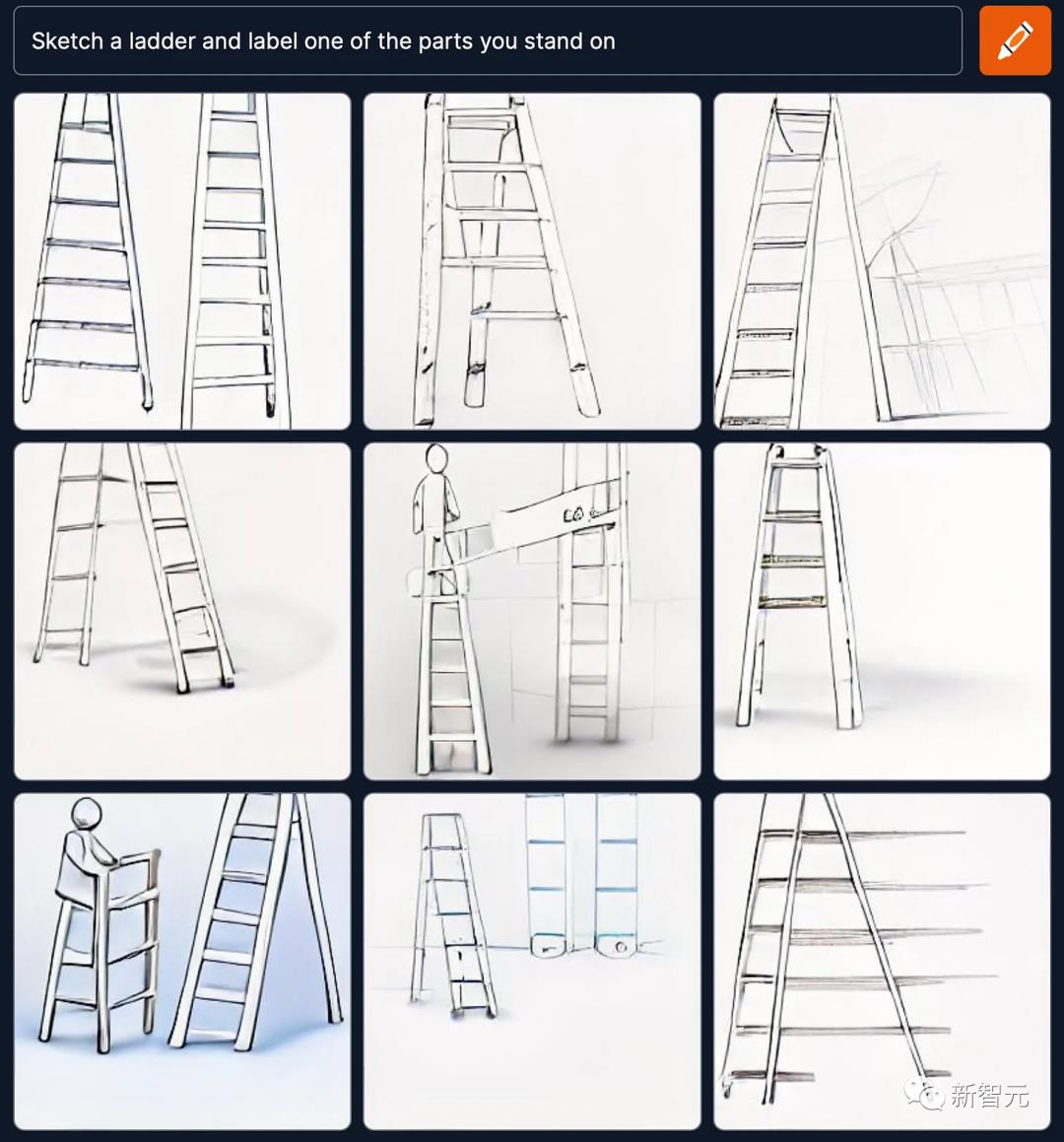
如果我们在一项基于事实的任务中,试图了解系统对(a)部分和整体,以及(b)功能的认识,比如「画出一个梯子并标出你站在上面的部分」这样的提示,会怎么样?
显然,Craiyon(DALL-E mini)对此一窍不通。
也许这是DALL-E Mini特有的问题?其实不然。
马库斯发现,在「Stable Diffusion」中也会出现类似的结果。
比如,「画一个人,并填充紫色」。

「画一辆白色的自行车,并将用脚踩的部分涂成橙色」。

「画出一辆自行车,并标出在地上滚动的部分。」

「画一辆没有轮子的白色自行车。」

「画一辆轮子是绿色的白色自行车。」

看得出来,AI可以一定程度上地get到部分和整体的关系,但并不能理解一个事物的功能以及复杂人类复杂的句法。
不过,马库斯这波确实有股「甲方爸爸提需求」的味道了。
基于这些结果,马库斯质问道:「我们真的可以说,一个不了解轮子是什么,或者说不了解轮子用途的系统,是人工智能的一个重大进步吗?」
对此,Stability AI的CEO,Emad Mostique,谦逊地表示:「它们还只是拼图的一个部分。」
Stable Diffusion为何能如此流行?
Diffusion最早是2015年的一篇文章提出的。
其核心思想,就是把生成的过程拆成一个个简单的小步骤,而不是像其他模型一样「一步到位」,这样拟合起来相对容易,做出来效果也好。

只是像大多数新生事物一样,Diffusion刚提出时,还有些粗糙。
直到2020年,生成模型DDPM(Denoising Diffusion Probabilistic Model)对之前的扩散模型进行了简化,Diffusion的发展才走上快车道。
相比GAN来说,Diffusion模型训练更稳定,而且能够生成更多样的样本。
因而,从2021年底到现在,先后有OpenAI的GLIDE、DALL·E-2和Google的Imagen都用上了Diffusion。
既然大家都用Diffusion模型,Stable Diffusion有啥特别之处,让它变得如此炙手可热?
简单来说,Stable Diffusion有三大优点。
首先,Stable Diffusion做到了开源,在商业/非商业使用上有超高的自由度。
只要遵循 OpenRAIL-M 许可证的规定,并且不用于非法和非道德的场景,任何人都可以对该模型进行商业或非商业使用、改造和再发布。
虽然Google的Imagen和OpenAI的DALL·E-2,画图的效果也很出色,可这些工具都是封闭或半封闭的。
为何Stable Diffusion可以做到开源,而其他却做不到呢?
这是因为Stable Diffusion背后有Stability AI的加持。
Stability AI由英国富豪Emad Mostaque创办,他除了有钱,更重要的是有情怀:他希望利用自己的技术和资金,来推动社会平等和技术普及。

因而做出Stable Diffusion的目标,就是创造开源的AI工具,大家可以把它当成真正的「Open AI」。
而谷歌也好,OpenAI都有商业上的追求,因而没有动力做这样的「慈善事业」。
其次,Stable Diffusion很轻量。
即便OpenAI「良心发现」,让DALL·E-2开源,普通人也是用不起的:需要使用高端显卡,等待时间也比较长。
虽然可以在网上找到 DALL·E mini,但那是一个与OpenAI完全无关的个人开发者,所做的业余开源项目。
而Stable Diffusion可以在10G显存的消费级显卡上使用,生成 512*512 尺寸的图片只需要几秒。
最后,Stable Diffusion的成功,离不开Stable Diffusion的效果好。
如果只是开源,Stable Diffusion未必就一定能大火,毕竟Craiyon、Disco Diffusion模型也是开源的。
Stable Diffusion在4000台 A100 显卡集群上,训练了一个月时间,再加上有近59亿条图片-文字平行数据的高质量数据集LAION-Aesthetics加持,生成结果完全不亚于DALL·E、Imagen 等基于超大模型的结果。

未来,Stable Diffusion在功能上,还有一些亮点值得期待,比如结果复现。
在目前的Stable Diffusion上,即使你重用了之前成功渲染的种子,如果提示符或源图像在后续渲染上发生了更改,那么想要复现之前的结果是很难的。

未来的Stable Diffusion,在保持一致性上,还会有改进。
再比如外画,意思是用户可通过语义逻辑和视觉连贯性将图像扩展到其边界之外。
总之,虽然Stable Diffusion不一定真的理解它在画什么,其画出的作品也见得「符合逻辑」,但AI从来不是「一个人在战斗」。
Stable Diffusion其实是从科研团队、公司和无数用户组成的复杂网络中「长出来的」,未来它还会迭代,变得更强大,也会给我们带来更多的惊喜。
参考资料:
https://weibo.com/2395607675/M61L994kN
https://garymarcus.substack.com/p/form-function-and-the-giant-gulf
https://www.unite.ai/how-stable-diffusion-could-develop-as-a-mainstream-consumer-product/
本文来自微信公众号“新智元”
以上是关于这AI保熟吗?大谷Stable Diffusion巨制:《华强买瓜》好莱坞巨星版来了!的主要内容,如果未能解决你的问题,请参考以下文章