深度学习5-从计算图直观认识“激活函数不以零为中心导致收敛变慢”
Posted 清风莫追
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习5-从计算图直观认识“激活函数不以零为中心导致收敛变慢”相关的知识,希望对你有一定的参考价值。
🚩 前言
活动地址:CSDN21天学习挑战赛
“众所周知,激活函数最好具有关于零点对称的特性,不关于零点对称会导致收敛变慢”,这种说法看到几次了,但对于背后的原因却一直比较模糊,今天就来捋一捋。
为此我阅读了一些文章,其中一篇个人觉得写得很棒(附在文末的参考中),但也花了一些时间才看懂(可能我比较笨?)。后面我发现从计算图来看这个问题会比较直观和容易理解一些。
如果不了解计算图,可以查阅 齐藤康毅 的 《深度学习入门 基于python的理论与实现》的第五章:误差反向传播法。
文章目录
1. 收敛变慢的原因
先上计算图(某层神经网络的一小部分):
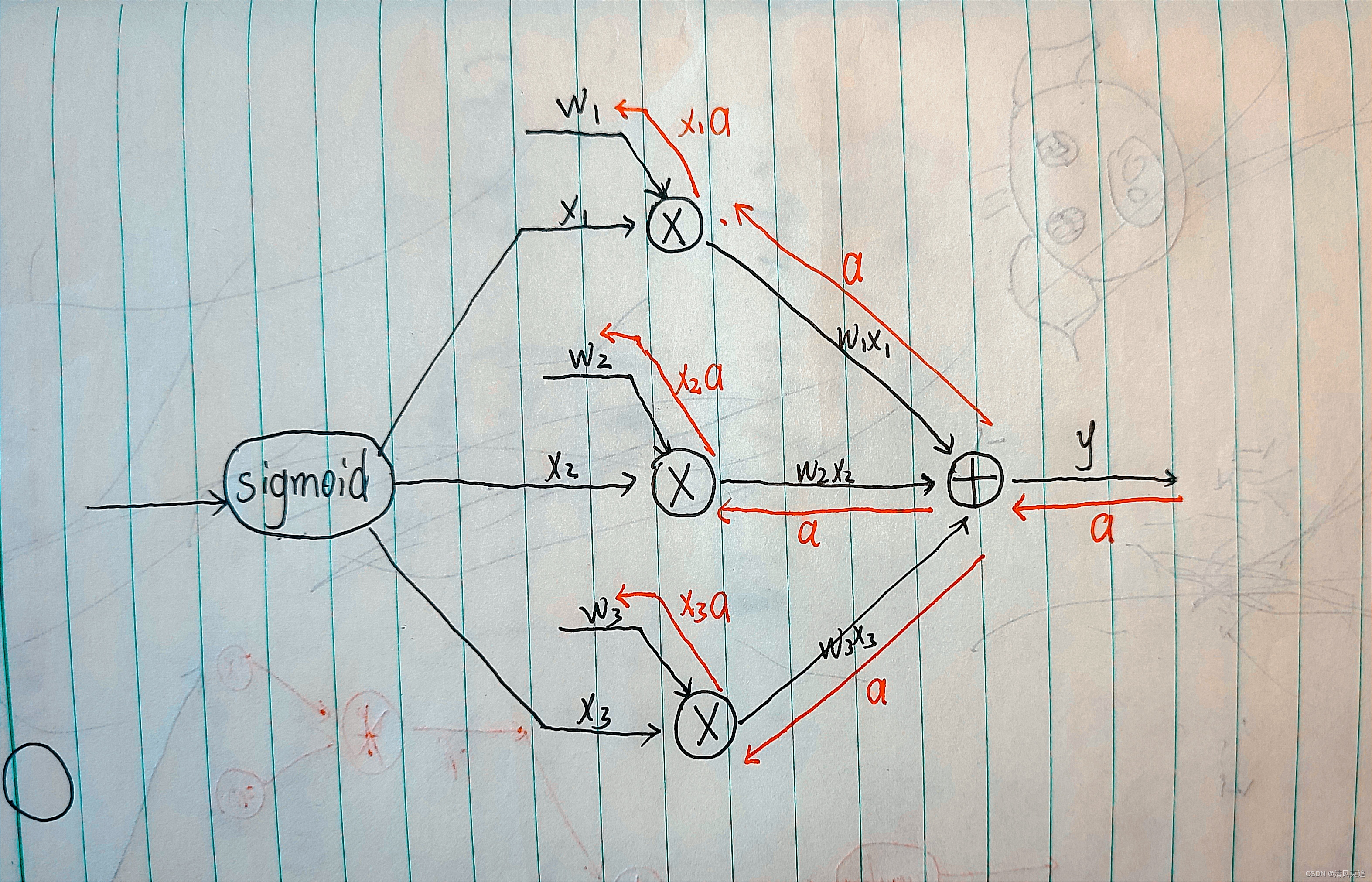
图中黑色箭头为正向推理,红色箭头为误差的反向传播。因为 s i g m o i d sigmoid sigmoid 函数的输出值都为正,故 x i x_i xi 的符号都相同且为正;则参数 w i w_i wi 的更新方向(增大\\减小) x i a x_ia xia 仅由 a a a 决定。
- 当 a a a 大于 0 ,所有参数更新时都增大
- 当 a a a 小于 0, 所有参数更新时均减小
所有参数更新方向始终一致会有什么影响?如果某次迭代收敛到最优参数,一个参数需要增大,另一个需要减小,那我们一致的参数更新方向就无法指向最优点,会形成一种锯齿型的路径,因此收敛到最优点的速度就慢。
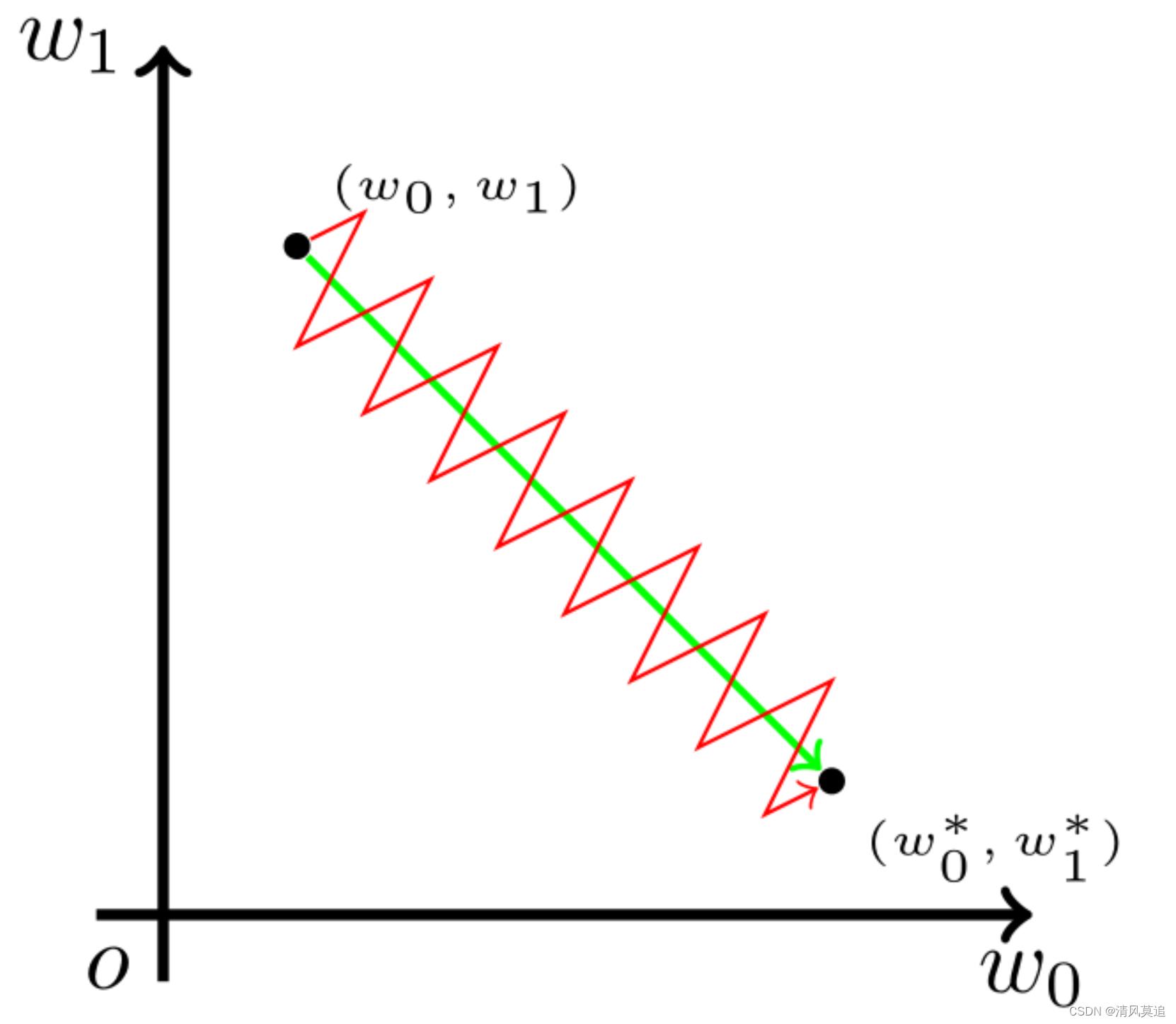
图片来源:谈谈激活函数以零为中心的问题
2. 为何要“对称”?
前面我们看到,参数更新方向一致将导致锯齿状的更新路径。只要激活函数的值域分布在零的两边,就不会出现更新方向始终一致的问题了。
那对称的意义是什么?像下图中,函数曲线偏向 y 的正半轴,那么更新参数时参数就更容易增大而不容易减小,但如何确定参数更应该增大还是减小呢?

3. 与“参数值全相同”情况的对比
下面对比一下两个问题。
- 激活函数输出值全为正:参数更新路径为锯齿状,更新慢
- 参数值全相同:完全无法正常训练
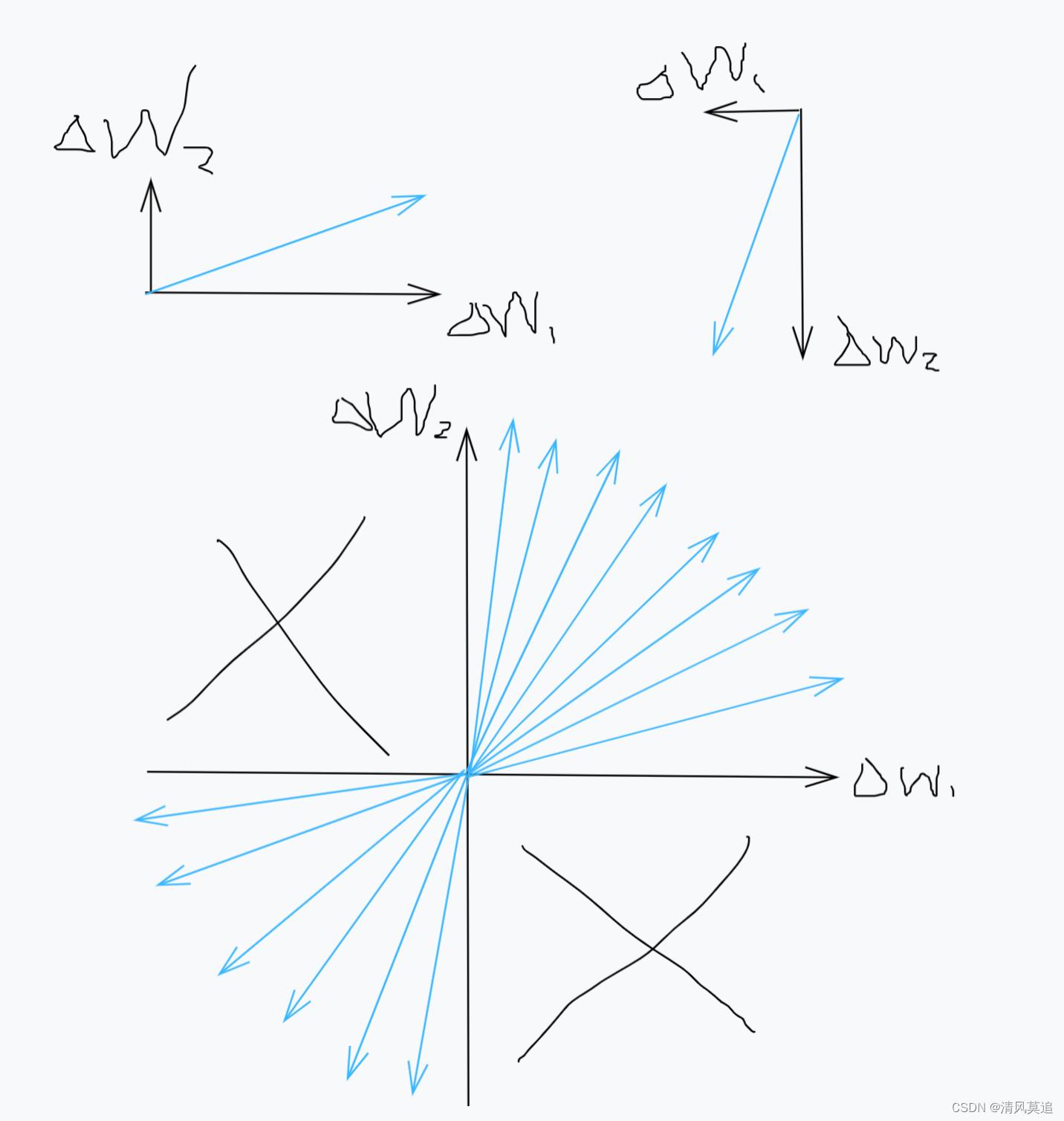
3.1. 激活函数输出值全为正
对于激活函数输出值全为正,以二维的参数空间为例,它失去的是一半的方向。一对参数值更新量
(
Δ
w
1
,
Δ
w
2
)
(\\Delta w1, \\Delta w2)
(Δw1,Δw2) ,虽然
Δ
w
1
\\Delta w1
Δw1 与
Δ
w
2
\\Delta w2
Δw2 的符号相同,但参数不同的绝对值仍可以组合出丰富的更新方向,足以抵达这二维空间中的任意一点,因为第二、四象限中的任一个向量,都可以分解为第一、三象限中的两个向量。
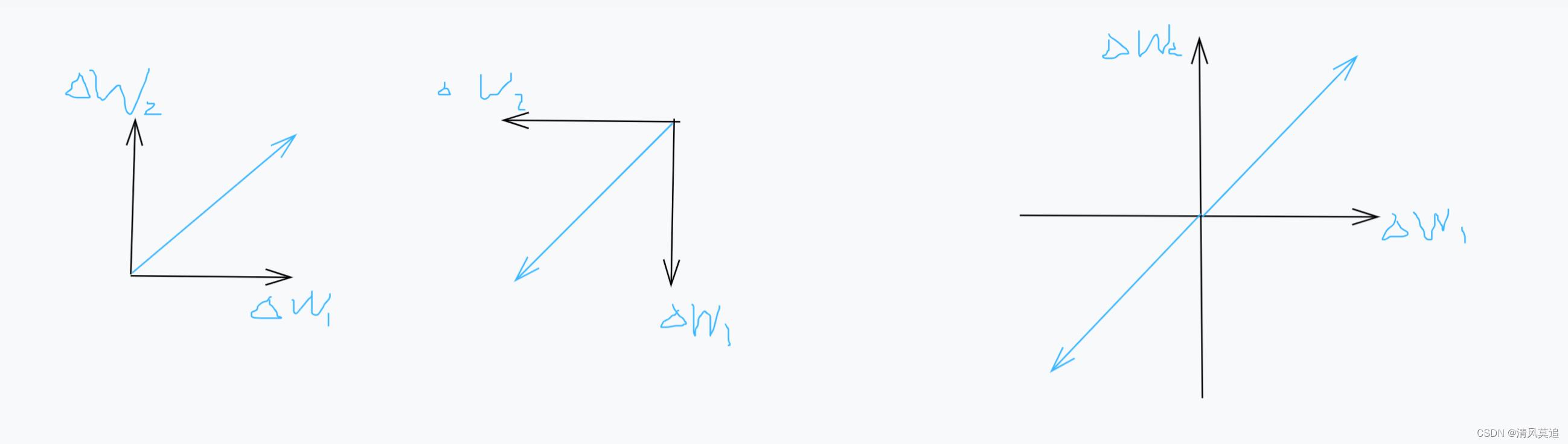
3.2. 参数值全相同
参数值全相同将导致所有参数的更新方向和幅度也相同(可参考:权重参数全相同值初始化,导致无法训练),此时模型完全报废,因为参数更新将只能在同一条直线上移动。
参考
- 《深度学习入门 基于python的理论与实现》齐藤康毅
- 谈谈激活函数以零为中心的问题
博主主页:清风莫追_CSDN
原文链接:http://t.csdn.cn/nIA0d
以上是关于深度学习5-从计算图直观认识“激活函数不以零为中心导致收敛变慢”的主要内容,如果未能解决你的问题,请参考以下文章
Pytorch深度学习实战3-5:详解计算图与自动微分机(附实例)
深度学习核心技术精讲100篇(四十三)-人工智能新技术-知识普及篇:一文带你深入认识下联邦学习的前世今生