如何查看linux的cpu使用率
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何查看linux的cpu使用率相关的知识,希望对你有一定的参考价值。
CPU使用率是一个很常见的查询项可以查询的命令也有很多种
举例说明如下:
1.top
使用权限:所有使用者
使用方式:top [-] [d delay] [q] [c] [S] [s] [i] [n] [b]
说明:即时显示process的动态
d :改变显示的更新速度,或是在交谈式指令列( interactive command)按s
q :没有任何延迟的显示速度,如果使用者是有superuser的权限,则top将会以最高的优先序执行
c :切换显示模式,共有两种模式,一是只显示执行档的名称,另一种是显示完整的路径与名称S :累积模式,会将己完成或消失的子行程( dead child process )的CPU time累积起来
s :安全模式,将交谈式指令取消,避免潜在的危机
i :不显示任何闲置(idle)或无用(zombie)的行程
n :更新的次数,完成后将会退出top
b :批次档模式,搭配"n"参数一起使用,可以用来将top的结果输出到档案内
范例:
显示更新十次后退出;
top -n 10
使用者将不能利用交谈式指令来对行程下命令:
top -s
将更新显示二次的结果输入到名称为top.log的档案里:
top -n 2 -b < top.log
另附一个命令简介linux traceroutewindows tracert两个命令相当,跟踪网络路由
2.vmstat
正如我们之前讨论的任何系统的性能比较都是基于基线的,并且监控CPU的性能就是以上3点,运行队列、CPU使用率和上下文切换。以下是一些对于CPU很普遍的性能要求:
1.对于每一个CPU来说运行队列不要超过3,例如,如果是双核CPU就不要超过6;
2.如果CPU在满负荷运行,应该符合下列分布,
a) User Time:65%~70%
b) System Time:30%~35%
c) Idle:0%~5%
3. mpstat
对于上下文切换要结合CPU使用率来看,如果CPU使用满足上述分布,大量的上下文切换也是可以接受的。
常用的监视工具有:vmstat, top,dstat和mpstat.
# vmstat 1
procs -----------memory---------- ---swap-- -----io---- --system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 104300 16800 95328 72200 0 0 5 26 7 14 4 1 95 0
0 0 104300 16800 95328 72200 0 0 0 24 1021 64 1 1 98 0
0 0 104300 16800 95328 72200 0 0 0 0 1009 59 1 1 98 0
r表示运行队列的大小,
b表示由于IO等待而block的线程数量,
in表示中断的数量,
cs表示上下文切换的数量,
us表示用户CPU时间,
sys表示系统CPU时间,
wa表示由于IO等待而是CPU处于idle状态的时间,
id表示CPU处于idle状态的总时间。
dstat可以给出每一个设备产生的中断数:
# dstat -cip 1
----total-cpu-usage---- ----interrupts--- ---procs---
usr sys idl wai hiq siq| 15 169 185 |run blk new
6 1 91 2 0 0| 12 0 13 | 0 0 0
1 0 99 0 0 0| 0 0 6 | 0 0 0
0 0 100 0 0 0| 18 0 2 | 0 0 0
0 0 100 0 0 0| 0 0 3 | 0 0 0
我们可以看到这里有3个设备号15,169和185.设备名和设备号的关系我们可以参考文件/proc/interrupts,这里185代表网卡eth1.
# cat /proc/interrupts
CPU0
0: 1277238713 IO-APIC-edge timer
6: 5 IO-APIC-edge floppy
7: 0 IO-APIC-edge parport0
8: 1 IO-APIC-edge rtc
9: 1 IO-APIC-level acpi
14: 6011913 IO-APIC-edge ide0
15: 15761438 IO-APIC-edge ide1
169: 26 IO-APIC-level Intel 82801BA-ICH2
185: 16785489 IO-APIC-level eth1
193: 0 IO-APIC-level uhci_hcd:usb1
mpstat可以显示每个CPU的运行状况,比如系统有4个CPU。我们可以看到:
# mpstat –P ALL 1
Linux 2.4.21-20.ELsmp (localhost.localdomain) 05/23/2006
05:17:31 PM CPU %user %nice %system %idle intr/s
05:17:32 PM all 0.00 0.00 3.19 96.53 13.27
05:17:32 PM 0 0.00 0.00 0.00 100.00 0.00
05:17:32 PM 1 1.12 0.00 12.73 86.15 13.27
05:17:32 PM 2 0.00 0.00 0.00 100.00 0.00
05:17:32 PM 3 0.00 0.00 0.00 100.00 0.00
总结的说,CPU性能监控包含以下方面:
检查系统的运行队列,确保每一个CPU的运行队列不大于3.
确保CPU使用分布满足70/30原则(用户70%,系统30%)。
如果系统时间过长,可能是因为频繁的调度和改变优先级。
CPU Bound进程总是会被惩罚(降低优先级)而IO Bound进程总会被奖励(提高优先级)。
4.prstat命令
要显示系统上当前运行的进程和项目的各种统计信息,请使用带有-J选项的prstat命令:
%prstat -J
PID USERNAME SIZE RSS STATE PRI NICE TIME CPU PROCESS/NLWP
21634 jtd 5512K 4848K cpu0 44 0 0:00.00 0.3% prstat/1
324 root 29M 75M sleep 59 0 0:08.27 0.2% Xsun/1
15497 jtd 48M 41M sleep 49 0 0:08.26 0.1% adeptedit/1
328 root 2856K 2600K sleep 58 0 0:00.00 0.0% mibiisa/11
1979 jtd 1568K 1352K sleep 49 0 0:00.00 0.0% csh/1
1977 jtd 7256K 5512K sleep 49 0 0:00.00 0.0% dtterm/1
192 root 3680K 2856K sleep 58 0 0:00.36 0.0% automountd/5
1845 jtd 24M 22M sleep 49 0 0:00.29 0.0% dtmail/11
1009 jtd 9864K 8384K sleep 49 0 0:00.59 0.0% dtwm/8
114 root 1640K 704K sleep 58 0 0:01.16 0.0% in.routed/1
180 daemon 2704K 1944K sleep 58 0 0:00.00 0.0% statd/4
145 root 2120K 1520K sleep 58 0 0:00.00 0.0% ypbind/1
181 root 1864K 1336K sleep 51 0 0:00.00 0.0% lockd/1
173 root 2584K 2136K sleep 58 0 0:00.00 0.0% inetd/1
135 root 2960K 1424K sleep 0 0 0:00.00 0.0% keyserv/4
PROJID NPROC SIZE RSS MEMORY TIME CPU PROJECT
10 52 400M 271M 68% 0:11.45 0.4% booksite
0 35 113M 129M 32% 0:10.46 0.2% system
Total: 87 processes, 205 lwps, load averages: 0.05, 0.02, 0.02
要显示系统上当前运行的进程和任务的各种统计信息,请使用带有-T选项的prstat命令:
%prstat -T
PID USERNAME SIZE RSS STATE PRI NICE TIME CPU PROCESS/NLWP
23023 root 26M 20M sleep 59 0 0:03:18 0.6% Xsun/1
23476 jtd 51M 45M sleep 49 0 0:04:31 0.5% adeptedit/1
23432 jtd 6928K 5064K sleep 59 0 0:00:00 0.1% dtterm/1
28959 jtd 26M 18M sleep 49 0 0:00:18 0.0% .netscape.bin/1
23116 jtd 9232K 8104K sleep 59 0 0:00:27 0.0% dtwm/5
29010 jtd 5144K 4664K cpu0 59 0 0:00:00 0.0% prstat/1
200 root 3096K 1024K sleep 59 0 0:00:00 0.0% lpsched/1
161 root 2120K 1600K sleep 59 0 0:00:00 0.0% lockd/2
170 root 5888K 4248K sleep 59 0 0:03:10 0.0% automountd/3
132 root 2120K 1408K sleep 59 0 0:00:00 0.0% ypbind/1
162 daemon 2504K 1936K sleep 59 0 0:00:00 0.0% statd/2
146 root 2560K 2008K sleep 59 0 0:00:00 0.0% inetd/1
122 root 2336K 1264K sleep 59 0 0:00:00 0.0% keyserv/2
119 root 2336K 1496K sleep 59 0 0:00:02 0.0% rpcbind/1
104 root 1664K 672K sleep 59 0 0:00:03 0.0% in.rdisc/1
TASKID NPROC SIZE RSS MEMORY TIME CPU PROJECT
222 30 229M 161M 44% 0:05:54 0.6% group.staff
223 1 26M 20M 5.3% 0:03:18 0.6% group.staff
12 1 61M 33M 8.9% 0:00:31 0.0% group.staff
1 33 85M 53M 14% 0:03:33 0.0% system
Total: 65 processes, 154 lwps, load averages: 0.04, 0.05, 0.06
注–
-J和-T选项不能一起使用。 参考技术A $ top -u oracle 可以去看看 《Linux就该这么学》
linux查看cpu占用率
参考技术A使用top命令即可,直接打开终端输入top,望采纳。
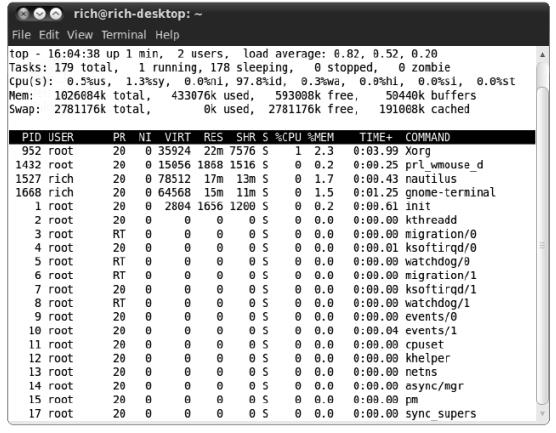
top命令跟ps命令相似,能够显示进程信息,但它是实时显示。
输出的第一部分显示的是系统的概况:第一行显示了当前时间、系统的运行时间、登录的用
户数以及系统的平均负载。
平均负载有3个值:最近1分钟的、最近5分钟的和最近15分钟的平均负载。值越大说明系统
的负载越高。由于进程短期的突发性活动,出现最近1分钟的高负载值也很常见,但如果近15分钟内的平均负载都很高,就说明系统可能有问题。
通常,如果系统的负载值超过了2,就说明系统比较繁忙了。
第二行显示了进程概要信息——top命令的输出中将进程做任务(task):有多少进程处在
运行、休眠、停止或是僵化状态(僵化状态是指进程完成了,但父进程没有响应)。
下一行显示了CPU的概要信息。top根据进程的属主(用户还是系统)和进程的状态(运行、
空闲还是等待)将CPU利用率分成几类输出。
紧跟其后的两行说明了系统内存的状态。第一行说的是系统的物理内存:总共有多少内存,
当前用了多少,还有多少空闲。后一行说的是同样的信息,不过是针对系统交换空间(如果分配了的话)的状态而言的。
最后一部分显示了当前运行中的进程的详细列表,有些列跟ps命令的输出类似。
以上是关于如何查看linux的cpu使用率的主要内容,如果未能解决你的问题,请参考以下文章