LeetCode第三题(Longest Substring Without Repeating Characters)三部曲之三:两次优化
Posted 程序员欣宸
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LeetCode第三题(Longest Substring Without Repeating Characters)三部曲之三:两次优化相关的知识,希望对你有一定的参考价值。
欢迎访问我的GitHub
- 本文是《LeetCode第三题(Longest Substring Without Repeating Characters)三部曲》的第三篇,之前的两篇文章列出了思路并写出了Java代码,虽然在LeetCode网站提交通过,但是成绩并不理想,40多毫秒的速度,与诸多优秀的方案有不小差距,
今天就来一起优化代码,提升速度;
原有代码
- 这里再回顾一下原有代码:
public int lengthOfLongestSubstring(String s)
//窗口的起始位置,窗口的结束为止,最长记录
int left = 0, right = 0, max = 0;
//表示窗口内有哪些值
Set<Character> set = new HashSet<>();
while (right < s.length())
//例如"abcdc",窗口内是"abcd",此时right等于[4],
//发现窗口内有array[right]的值,就缩减窗口左边,
//缩到窗内没有array[right]的值为止,
//当left一路变大,直到left=3的时候,窗口内已经没有array[right]的值了
if (set.contains(s.charAt(right)))
//假如窗口内是"abc",当前是"c",那么下面的代码只会将"a"删除,left加一,再次循环
//而新一次循环依旧发现"c"还在set中,就再把"b"删除,left再加一...
set.remove(s.charAt(left++));
else
//窗口内没有array[right]的时候,就把array[right]的值放入set中,表示当前窗口内有哪些值
set.add(s.charAt(right++));
if ((right - left) > max)
max = right - left;
return max;
第一次优化
-
这次的重点是HashSet对象,此对象保存窗口中的所有元素,每加入一个新元素之前都检查HashSet中是否存在该元素;
-
如下图所示,代码中通过set.add和set.remove方法将HashSet中的内容始终与窗口中的内容保持一致:

- 优化前:判断一个元素是否在窗口中,现在的做法是以HashSet中为准,当判定某个元素要从窗口中移除,就调用HashSet的remove方法从HashSet中删除;
-
上述的代码可以优化,优化后可以不用执行HashSet的remove方法,具体的逻辑是使用HashMap替代HashSet,HashMap的key是字符串的元素,value是元素在数组中的位置,举个例子,当left=1,right=3时,整体的效果是下图这样的,HashMap中已经保存了"a"、"b"、"c"三个元素作为key,而value就是它们在数组中的下标:

- 现在要检查数组中下标为4的元素"b":以"b"为key查找HashMap,如果不存在就表示不在窗口中,如果存在,就用对应的value=1去和left比较,如果小于left就表示不在窗口中,如果大于或者等于left就表示在窗口中,如下图所示:

- 这里要注意的是:hashmap中任意一个value,表示的是某个元素在整个数组中的位置,而不是在窗口中的位置,因为程序中不会对hashmap做remove操作;
- 接着上面的图分析,"b"元素被发现在窗口中存在后,除了将left调整为2,right调整为4,还要调用HashMap的put方法,将"b"元素的位置从原来的1更新为4;
- 另外还有个优化点:假设当前窗口中是"abc",而检查的元素是"b",之前的代码中,要执行两次循环:先删除"a",left加一,再删除"b",left再加一,现在用了HashMap就能得到"b"的位置,直接将left改为"b"的下一个位置即可,不需要执行两次循环了;
- 以上就是优化思路了,用HashMap取代HashSet,不再执行remove方法,对代码的调整并不大,调整后的完整代码如下:
public int lengthOfLongestSubstring(String s)
int left =0, right =0, max = 0;
Map<Character,Integer> map = new HashMap<>();
while (right<s.length())
//map中如果不存在就表示不在窗口中
if(map.containsKey(s.charAt(right)))
int pos = map.get(s.charAt(right));
//map中如果存在,再检查value和left,来判断是否在窗口中
if(pos>=left)
//注意这又是个优化点,假设当前窗口中是"abc",而检查的元素是"b",
//之前的代码中,要执行两次循环:先删除"a"再删除"b",
//现在用了HashMap就能得到"b"的位置,直接将left改为"b"的下一个位置即可,不需要执行两次循环了
left = pos + 1;
map.put(s.charAt(right), right++);
if((right-left)>max)
max = right-left;
return max;
-
提交上述代码到LeetCode,这次的成绩是27毫秒,比之前好了不少,如下图:

- 然而,这个成绩依然很平庸,因为它还有可优化之处,接下来再次优化;
第二次优化
- 第一次的优化点是消除remove方法和while循环次数,第二次优化则是针对HashMap,每次处理新的元素都涉及到HashMap的操作,如果您对HashMap的内容有所了解,就知道计算hashcode、创建EntrySet,调用equals方法这些操作会被频繁执行,如果能省去这些操作,那么性能应该会有明显提升,问题是:如何才能去掉HashMap而不影响功能呢?
- 我们先明确HashMap在程序中的作用:保存一个元素在数组中的位置,所以优化的方向就是寻找HashMap的替代品;
-
假设一共可能出现二十六种字符:从"a"到"z",那就简单了,用一个长度为26的int数组来记录每个字符的位置,array[0]的值就是元素"a"的位置,array[1]的值就是元素"b"的位置,array[2]的值就是元素"c"的位置,如下图所示,图中的数字97是"a"的ASCII码:

-
按照上面的设计,array[0]=3就表示"a"元素在整个数组中最后一次出现的位置是3,array[1]=1表示"b"元素在整个数组中最后一次出现的位置是1,array[2]=2就表示"c"元素在整个数组中最后一次出现的位置是2,如下图:
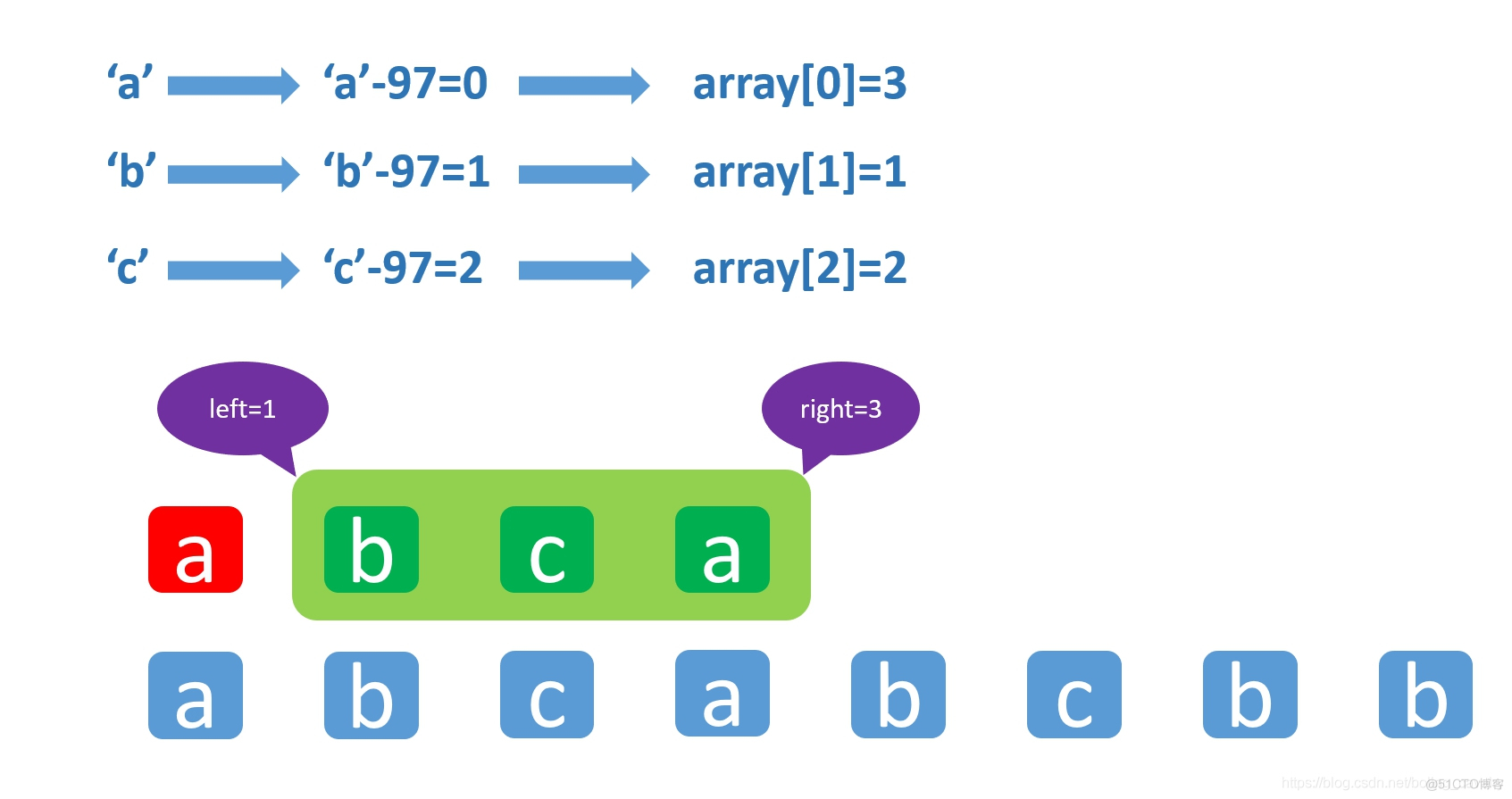
-
按照以上设计是不是就可以立即编码并提交到LeetCode了呢?我当时就是这么做的,很不幸因为测试没有通过而提交失败了,没通过的原因是:字符串中不仅会有"a"到"z"的小写,还有大写字母、空格字符、加减乘除等字符,遇到这些字符时,我们之前设计的长度26的数组就不够用了,看来要重新设计数组;
- 新的数组总长度是95,这是因为所有英文可见字符一共是95个,从空格开始,到"`"结束,如下图的三个红框所示:

-
如上所示,长度为95的数组,可以将所有可见字符都纳入进来,array[0]保存的是空格字符的位置,因此计算字符"a"在array数组中的下标就从之前的a-97=0变成了a-32=65;
- 另外要注意的是,这个数组中每个元素初始值都是-1,表示字符串中没有这个元素(或者说还没有处理到);
- 按照上述思路优化后的代码如下所示,可见改动并不大,只是把HashMap相关的地方全部改成了上述的数组逻辑:
public int lengthOfLongestSubstring(String s)
int left =0, right =0, max = 0;
int[] array = -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1;
int offset;
while (right<s.length())
//offset表示当前处理的元素在array数组中的下标,
//如果当前元素是空格,那么减去32后等于0,array[offset]即array[0],
//这个array[0]的值就是空格字符在字符串中的位置
offset = s.charAt(right) - 32;
if(array[offset]>-1)
int pos = array[offset];
if(pos>=left)
left = pos + 1;
array[offset] = right++;
if((right-left)>max)
max = right-left;
return max;
-
将以上代码提交到LeetCode,顺利通过,成绩提升到17ms,超过了99.94%的java方案,如下图:

-
最终效果证明这次优化的方向和结果都是正确的,之前已经有朋友问过优化思路从何而来,其实灵感来自桶排序,思想是类似的;
- 至此,LeetCode第三题的解题思路、编码实现、优化实战就全部完成了,希望能给读者您在解题过程中带来一些参考,刷题之路,大家一起努力!
欢迎关注51CTO博客:程序员欣宸
以上是关于LeetCode第三题(Longest Substring Without Repeating Characters)三部曲之三:两次优化的主要内容,如果未能解决你的问题,请参考以下文章
leedcode Longest Palindromic Substring