Hadoop+hive+flask+echarts大数据可视化项目之系统信息数据上传及上传的底层实现
Posted play_big_knife
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop+hive+flask+echarts大数据可视化项目之系统信息数据上传及上传的底层实现相关的知识,希望对你有一定的参考价值。
Hadoop+hive+flask+echarts大数据可视化项目(三)
--------------上传系统信息数据到hadoop平台及hadoop上传指令的底层实现----------------
关注过Hadoop+hive+flask+echarts大数据可视化项目的读者,这里是第三部分。前面的部分完成了系统数据信息的收集以及Hadoop环境的搭建。现在需要把系统数据信息上传到hadoop分布式存储平台中。
一、系统数据信息上传hadoop分布式存储平台
系统数据信息通过shell脚本已经整合了时间,ip地址,mac地址,cpu的用户使用率,cpu的系统使用率,内存总数,内存空闲数等内容。其收集的内容需要上传到hadoop分布式存储系统中。由于hadoop分布式文件存储系统存储的内容是基于文件的,那么上传到hadoop分布式存储系统中的数据就应该是以文件为单位,文件中存储的信息以时间为节点一条一条地建立起来的。这样,就会存在两个思路。
其一是linux系统本身产生以时间为节点的一条一条信息存储到本地节点,然后上传到hadoop平台。
其二是linux系统本身产生以时间为节点的一条信息存储到本地节点,然后累加式的一条一条上传到hadoop平台。
关于这两条思路,都存在着在一段时间内收集系统的信息,也就是一段时间内要进行脚本的执行,脚本的执行不能告人为地执行,也需要系统自动执行。这就需要linux提供的定时任务crontab。
在linux系统的etc目录下,有crontab文件,文件中指明了定时任务crontab的相关参数。如下图所示。

由图中可知,第一个参数表示分钟的量级,相当于每分钟执行的命令,第二个参数表示小时的量级,相当于每小时执行的命令,第三个参数表示天的量级,相当于每天执行的命令,第四个参数表示月的量级,相当于每月执行的命令,第五个参数表示星期的量级,相当于每个星期执行的命令。最后一个参数表示定时期间执行的命令。
crontab定时任务指令可以通过crontab -e编辑当前用户下的定时任务。如下图所示。
输入crontab -e后会出现编辑窗口,将定时任务的相关参数编辑到参数中,如每分钟执行其中的脚本指令。就可以将crontab参数中的第一个参数置1,执行脚本可以执行/home/data下的myrun.sh脚本,编辑内容如下图所示。

编辑脚本后,保存退出。此时每个以分钟为单位的间隔内就会运行myrun.sh脚本。这里比较关心的是每个为分钟为单位的间隔内info.txt中的内容。通过cat显示info.txt中的内容显示如下。

通过显示发现,有一些内容没有显示出来,如cpu的用户使用率,cpu的系统使用率等等。其根本内容需要查询出没有显示ip地址及cpu用户使用率等信息的原因,那么就需要注意命令的上方指示“您在/var/spool/mail/root中的新邮件”,这一句的指示表明root中的新邮件会指明错误的原因。进入到var中spool目录中的mail目录下,然后显示root文件的后面几行内容,企业中常用tail指令显示日志文件的后几行来查询故障原因。如下图所示。

在图中显示的root文件错误的信息指明了“ifconfig未找到命令”,其根本原因在于ifconfig是yum安装第三方包时安装的内容,不是centos系统本身所具有的。需要把ifconfig的第三方文件执行路径说明出来。可以通过指令whick ifconfig来找到ifconfig的执行指令,如下图所示。
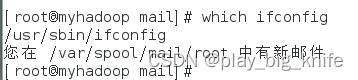
图中可以看到,执行完which ifconfig后,还是会报“您在/var/spool/mail/root中有新邮件”。此时肯定还是因为“ifconfig未找到命令”。最重要的是关注“which ifconfig”命令的输出,也就是ifconfig的执行路径,其路径在“/usr/sbin/ifconfig”中。将myrun.sh中涉及到ifconfig指令的内容前面都要加上“/usr/sbin/ifconfig”的前缀内容。具体修改效果如下图所示。
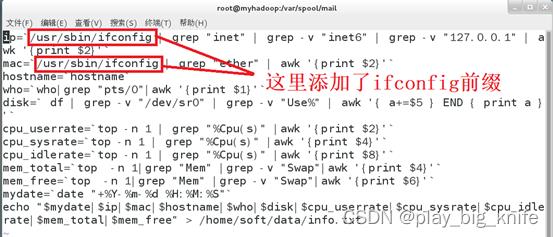
如图中所示,添加了前缀的ifconfig就可以进行脚本中ifconfig指令。这样的输出内容中可以包括ip地址的信息,可以通过cat显示info.txt的内容,具体指令如下图。

从图中显示可以看出,ip地址和mac地址已经显示出来的,所不同的是还是没有显示出cpu的用户使用率,系统使用率相关的信息。这就需要再次查看/var/spool/mail文件夹中的root信息。
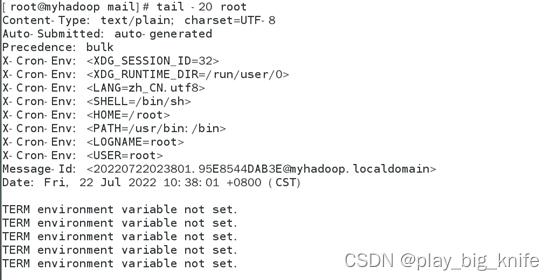
通过root文件中错误信息的查看,可以找到错误“TERM environment variable not set”,其中心意思在于“TERM的环境变量没有设置”,这是top指令需要的环境变量。环境变量的值可以通过set指令结合grep去查看“TERM”的环境变量的值。如下图所示。

通过图中获知,“TERM”环境变量的值为xterm-256color,这里还需要在shell脚本中加入“TERM”环境变量的值。继续编辑shell脚本内容如下。
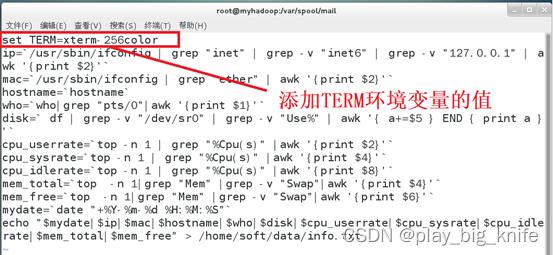
添加“TERM”环境变量的值之后,继续查看info.txt中的内容。看一下是否显示cpu的用户使用率及系统使用率等信息。如下图所示。

从图中可以看出,还是没有显示出cpu的用户使用率、系统使用率及内存的相关信息,继续通过tail查看/var/spool/mail目录中的root文件来查看具体原因。如下图所示。

图中显示top指令的报错信息“failed tty get”,这是由于top需要把指令输出到某个程序和者文件中,需要开启-b的批处理模式,修改shell脚本中涉用到top指令的都加入-b来保证批处理模式,使top输出的信息输出到某个程序或者文件中。如下图所示。
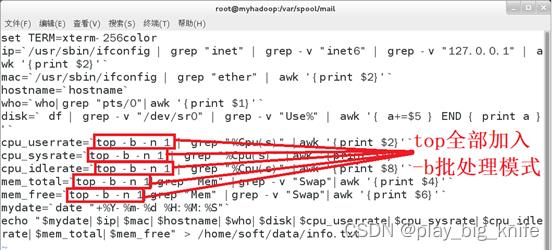
上图所示top指令中加入-b批处理模式后,再次使用cat查看产生的info.txt中的文件内容。如下图所示。

从图中的信息可以看到,此时cpu的用户使用率,cpu的系统使用率,及内存总数,内存的空闲数都被取出并写入到文件中。
根据前面分析的两个思路。
(1)将文件累加式地写入到本地,然后再上传到hadoop中。
如果需要把linux定时任务产生的信息累加式写入到本地文件,需要将输出的“>”号改成“>>”号,两个大于号的结合相当于在原有的本地文件上实现追加。具体内容修改如下。
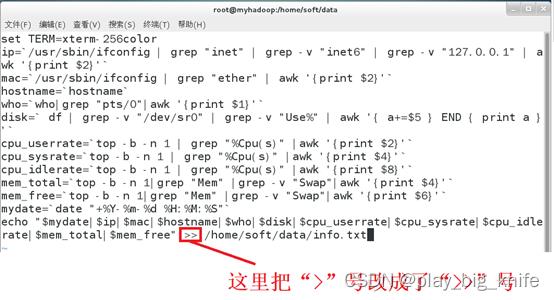
从图中可知,在shell脚本中把“>”号改成了“>>”号,这样产生的输出info.txt文件就会出现内容的叠加。可以通过cat查询info.txt文件内容来证实最终结果。如下图所示。

如图所示,会在每隔1分钟的时间点,产生不同的数据记录。
然后在shell脚本的最后添加hadoop fs -put的指令,实现文件的上传。Shell脚本编辑内容如下图。

通过linux的定时器,每隔1分路就会进行脚本的执行,然后通过hadoop fs -ls来查看上传到hadoop平台中的info.txt文件是否存在。如下图所示。

从图中的输出结果中可以看出,又显示出了“您在/var/spool/mail/root中有新邮件”,从此信息判断shell脚本中可能还存在错误,继续tail指令查看/var/spool/mail目录下的root文件后面几行,查看产生错误的具体原因。如下图所示。
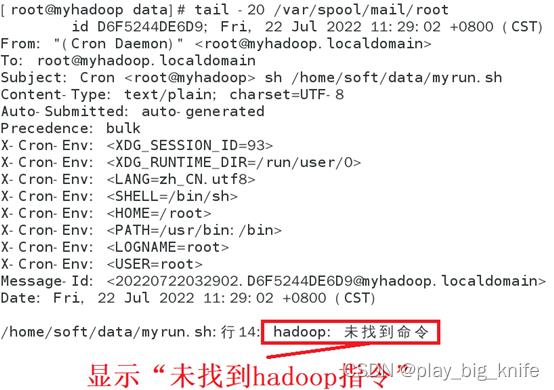
从图中可知,root文件中显示错误信息“hadoop:未找到命令”,其根本原因还是在于hadoop是第三方安装包,需要指定第三方安装包的执行路径,只有指定其执行路径,才能执行hadoop的命令,可认通过which hadoop来查找hadoop包的具体执行路径,如下图所示。

通过图中的输出可以得到hadoop的输出路径,把hadoop的执行路径添加到shell脚本中,这样shell脚本在执行的时候就会找到hadoop的执行文件,如下图所示。

添加执行路径后,再次通过定时器执行shell脚本后,就会把本地的info.txt上传到hadoop平台中。通过hadoop fs -ls查看hadoop平台中的info.txt文件是否存要在如下图所示。
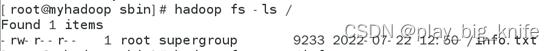
通过显示hadoop平台中info.txt的内容可以看出存储在hadoop平台的info.txt文件也是时间点叠加的系统信息采集,如下图所示。

虽然数据已经上传到了hadoop当中,但是不得不注意的问题是,现在思路决定了服务器的情况是本地有一个info.txt文件,hadoop远程服务器中还有一个info.txt文件,两个文件的内容是相同的,都是采集时间的叠加生成的系统信息。这样,在服务器中就相当于存储了两份文件,随着文件中数据的增加,本地和远程hadoop不断耗费着资源,既耗费本地资源,也耗费着远程hadoop资源。因此,对于这种思路来说是不可取的。
再看第二种思路。
(2)本地文件中只有一个时刻的系统数据采集,远程hadoop服务器中存储叠加时刻的系统数据采集。
在本地文件中只产生一个时刻的系统数据采集,因此在本地的info.txt文件中只存有一行数据。这样,就需要把原来修改脚本的“>>”号修改成“>”号。如下图所示。
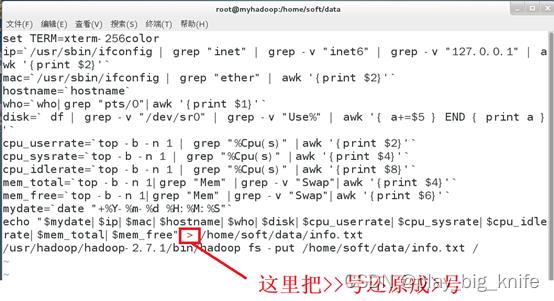
保存退出后,在本地的info.txt中每一个时刻只产生一行系统信息数据,可以用cat显示info.txt 的具体内容。

现在需要在远程的hadoop服务器中产生一个info.txt文件,这个info.txt文件实现不同时刻采集的系统信息的叠加。但是需要注意hadoop上传同名文件时,nanenode管理者会检查文件是否重名,如果重名,就会报错,如下图所示。

如上图所示,出现的报错信息“put ‘/info.txt’:File exists”表明文件已经存在,文件既然存在,hadoop默认是不能上传该文件的,这里可以用-f参数强行上传该文件,后面会分析-f文件上传的底层实现。如下图所示。

通过图示可以看到命令执行后没有任何错误的输出,证明文件被正确上传。但是文件并没有实现追加的功能,hadoop中存储的文件实现追加需要使用appendToFile的指令,appendToFile需要指定两个参数,第一个参数是文件名,第二个参数是与第一个参数同名的文件名。其目的在于前面的文件内容追加式地填写到后面的文件内容中。命令使用格式如下。

使用命令后,在hadoop的分布式文件存储系统下info.txt文件会出现叠加的数据效果,如下图所示。

如上图所示,在info.txt中出现了两行叠加的不同采集时刻的数据。现在,可以修改shell脚本,实现上传hadoop时把数据追加到info.txt,而在本地只产生一行数据。Shell脚本修改如下图所示。

这样保存脚本后,在本地只会产生一行数据的info.txt,在远程hadoop服务器中会产生时间叠加的info.txt系统信息记录。可以通过hadoop fs -cat显示远程info.txt的内容如下图所示。

在本地形成一行采集数据的info.txt,在远程hadoop服务器中产生叠加时刻的系统信息数据实际上是比较理想的采集情况。Hadoop分布式文件存储系统可以把文件存储在多个计算机上,这也不仅仅限于一台机器的一个硬盘,大大扩充了系统信息采集的容量,是值得推广的思路。
二、hadoop中Put和appendToFile的文件底层实现
这里通过下面的操作步骤去分析put和appendToFile的底层实现
第一步:启动虚拟机
第二步:上传文件info.txt
第三步:删除文件info.txt
第四步:继续上传文件info.txt
第五步:删除文件info.txt
第六步:追加式上传文件info.txt
第七步:追加式上传文件info.txt
第八步:put -f强制上传文件info.txt
注意,实现这几步实验目的前可以使用crontab -r删除前面设置的定时任务,通过上传info.txt,再删除,再上传同名的info.txt,其目的在于验证info.txt的block块存储是否会智能地连续,相当于一本书,删除了一页,而后发现删除了,又粘上去了一个同样的页,最理想的情况是页数不变,如果一本书撕掉的页数多了,页数又不能连续,这样读起书来,也很难去找到对应的页。读起来也很不方便。删除同名文件再上传就是验证一下撕掉页数是否会连续,后面的appendToFile和put -f其实是来验证一下put和appendToFile及put -f 之间存在的差别与联系。
第一步:启动虚拟机,这一步比较简单,略过不说。
第二步:上传文件info.txt,命令如下图所示。

第三步:删除文件info.txt,命令如下图所示。

第四步:继续上传文件info.txt,命令如下图所示。

第五步:继续删除文件info.txt,命令如下图所示。

第六步:使用appendToFile上传文件,命令如下图所示。

第七步:继续使用appendToFile上传文件,命令如图所示。

第八步:使用hadoop fs -put上传文件时携带参数-f强制覆盖同名文件。命令如图所示。

八步操作结束后,重启虚拟机,使namenode中的edits文件和fsimage文件进行合并,合并后通过关闭的edits文件查看hadoop对上述操作的底层具体实现。
重启虚拟机后,启动hadoop服务。
先进入到hadoop的数据目录tmp中,再进入到dfs分布式文件存储系统的数据记录中,在这里有name和data两个目录,分别是namenode的角色工作目录,datanode角色的工作目录。在name目录中有current目录,进入到current的目录中,在current目录中会有很多的edits文件,如下图所示。

这里通过比对,最近的edits文件是尾数从074-106的edits文件,把这个edits操作文件导出,导出edits文件可以使用hdfs oev指令来实现,其携带参数-i,指明了输入参数,也就是需要导出的edits文件是哪一个edits文件,-o指明输出参数,也就是需要导出edits文件的最终文件名是什么,这里默认的导出文件扩展名都是.xml。因此具体导出指令如下。

上图中导出edits文件没有报任何错误,直接进入到指定的输出目录,这里是home的soft 目录下的data目录中,有一个导出的myedits.xml文件。
现在可以使用vi编辑工具查看myedits.xml的文件内容。具体操作如下图所示。
进入vi编辑器后,可以查看到myedits.xml的内容。
回顾前面的八步操作。
第一步上传info.txt文件,其对应了下面的hadoop底层操作。
(1)OP_ADD操作
ADD操作的目的是先在HDFS上创建一个同名文件.COPYING,可以通过OP_ADD中的PATH看到这样的信息,如下图所示。

上图中标黄的部分产生一个info.txt的_COPYING复本文件。
(2)OPALLOCATEBLOCK_ID
ADD操作之后就是ALLOCATEBLOCKID实现分配BLOCK_ID的操作,也就是块id的分配操作。注意下图中分配的块ID是什么样的数字。

上图中标黄的块ID为1073741827,这步为后续删除此文件产生新的块ID提供一个伏比,也就是后期会跟后面的块ID进行比较。
(3)OPSETGENSTAMP_V2
此步分配时间戳,由此判断文件产生的时间。
(4)OPADDBLOCK
此步利用流将数据写入到对应的Block上,会有相关的块ID参数,表示在哪一个块上写数据,同时还有一个NUMBYTES参数,表示从块的哪一个位置开始写数据。Hadoop中只要PUT一个数据,都需要新建一个块ID,并从NUMBYTES为0的位置开始写数据。这里写的数据仍是备份的info.txt数据,这引起参数可以从下图中找到。

图中标黄的部分PATH指明文件还是一个COPYING,后面的BLOCKID表示块ID,NUMBYTES表示从块的哪个位置开始写数据。
(5)OP_CLOSE
此步为关闭文件,关闭文件是文件名称还是info.txt的复本文件。
此信息可以从下图中的PATH获取。

(6)OPRENAMEOLD
此步重命名文件。会将前一步关闭的COPYING文件更名为正式的info.txt文件。也就是最终PUT到hadoop平台中的文件。
综合各个元操作步骤,hadoop上传文件需要先产生复本文件,再分配块信息,产生时间戳,接下来才是真正的写数据到复本文件,关闭文件。最后要把复本文件更名为正式的上传文件。
第二步执行了删除操作。
Hadoop删除文件操作的底层就只有一步元操作OP_DELETE,没有其它的附加元操作内容。
第三步再次PUT一个同名info.txt文件,这里关注的是第二步,也就是OPALLOCATEBLOCK_ID,在这一步中分配的块ID与前面的块ID是否一致,如下图所示。

在前面PUT操作中记录的块ID为1073741827,此次上传的块ID为1073741828,两者的块ID相差值为1,也就意味着如果上传了一个文件,再删除了这个文件,不管是同名文件还是不同名的文件,都是需要重新分配块ID的。这就提醒了我们,如果hadoop中存有数据,我们进行了删除操作,其实造成了hadoop后续块id的不连续,相当于一本书,撕掉了几页后,后面的页数也就不连续了。这也就造成了对不连续的页查询数据时所花费的时间和效率也是很高的。
第四步删除操作,没什么可说的,只有一步元操作OP_DELETE。
第五步采用appendToFile上传文件info.txt,其对应了下面的hadoop底层操作。
(1)OP_ADD
也是添加一个文件的操作,不过这里添加的是info.txt,与PUT添加的info.txt的复本文件是不同的。如下图所示的PATH标明了添加的info.txt文件。

接下来是第二步元操作。
(2)OP_CLOSE
此步直接关闭了这个文件,没有把数据上传就关闭了这个文件,相当于在namenode中创建了这个文件的目录,但是还没有分配block id,这步是可以这样理解的。先把文件记录在案,但没有数据生成。
(3)OP_APPEND
此步相当于对前面关闭的文件发送一个添加的指令,也就相当于告知namenode即将在datanode中记录相关的数据。
(4)OPALLOCATEBLOCK_ID
此步分配了块ID,也就是通知namenode打算要更新前面关闭的文件,需要对文件实现写数据操作,这时开始分配块ID。
(5)OPSETGENSTAMP_V2
此步分配时间戳,也是记录文件追加的具体时间。
(6)OPADDBLOCK
此步才把数据流写入到block块ID中,这里需要提供BLOCKID从哪一个块ID来写,需要提供NUMBYTES从块的哪一个字节来写,如下图所示。
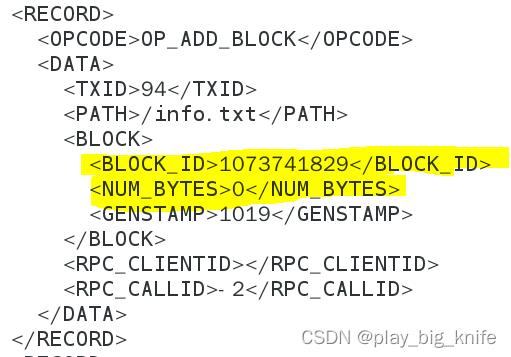
上图中标黄的部分BLOCKID为写入数据的块ID,NUMBYTES为写入数据块ID的起始位置。注意,这里的块ID是1073741829,后续再发生appendToFile操作时,这个块ID是否发生变化也是我们研究的问题,还有NUM_BYTES是否做一定容量的偏移,都是我们关心的。
(7)OP_CLOSE
此步写完数据后,关闭文件。
综合appendToFile的元操作步骤,就会发现appendToFile会首先通过namenode有一个文件需要去管理,这里创建文件并关闭文件,后续操作对文件进行增加数据操作,分配块ID,分配时间戳,把数据写入块ID中,然后关闭文件。
如果后续再发生appendToFile,会有什么样的变化。
第五步采用appendToFile继续上传文件info.txt。
这一步的appendToFile的元操作步骤就比上一步简单一点,因为文件已经存在,在这一步中直接发送OPAPPEND元操作指令,表示需要更新文件数据,接下来会先发生更新时间戳OPSETGENSTAMPV2来记录文件更新时间,而后采用OPUPDATEBLOCKS元操作来更新块信息,在更新块信息中的BLOCKID信息来上一步appendToFile的BLOCKID信息是相同的,还要注意NUM_BYTES不再是从0开始,而是偏移了一段距离,这段距离恰好就是上一步info.txt的大小。如下图所示。

图中标黄的BLOCKID还是上一步appendToFile追加文件时BLOCKID,其值还是1073741829,注意图中标黄的NUMBYTES发生了变化,不再是0值,而是99,这个99其实也是info.txt的文件大小,也就说明了appendToFile追加的文件内容是可以实现无缝连接的,是继续前面没有写完的BLOCKID基础上继续追加后面的数据,达到了数据存储的连续性。
最后一步是hadoop fs -put上传文件时携带参数-f
通过元步骤的分解会发现,其前面的操作跟hadoop fs -put的操作是一致的,都是OPADD一个副本文件,然后OPALLOCATEBLOCKID分配一个块ID,继续OPSETGENSTAMPV2分配时间戳,OPADD_BLOCK将流信息写入到BLOCK块中,再OPCLOSE关闭文件。这几步元操作都是针对于COPYING的操作。操作完COPYING之后,对需要覆盖的原有文件采用了OPDELETE的删除操作,删除原有文件后发生OPRENAMEOLD的更名操作。注意-f参数的使用是先在hadoop平台中把COPYING副本的操作操作结束后,再进行删除原有的重名文件,最后再把COPYING副本文件更名为需要更新内容的文件。所以使用put -f覆盖式的上传文件会发现有一段时间是副本与原文件共存的情况,也就是hadoop平台中的存储容量翻倍的情况,因此put -f参数覆盖同名文件不可取,第一它不会在原有的BLOCKID上写数据,仍然会发生新的BLOCKID,也会造成不连续,第二它会先产生副本,再删除,会出现hadoop平台存储容量翻倍的情况。
欢迎关注Hadoop+hive+flask+echarts大数据可视化项目,后续会有持续的精彩。
博客中代码github地址:
https://github.com/wawacode/system_info_bigdata_analyse以上是关于Hadoop+hive+flask+echarts大数据可视化项目之系统信息数据上传及上传的底层实现的主要内容,如果未能解决你的问题,请参考以下文章
#导入MD文档图片#Flask结合ECharts实现在线可视化效果,超级详细!
Flask+Echarts+sqlite搭建股票实时行情监控