分布式服务治理zookeeper原理及使用大全
Posted 烟花散尽13141
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式服务治理zookeeper原理及使用大全相关的知识,希望对你有一定的参考价值。
文章目录
zookeeper动物管理员全局把控。提供了配置管理、服务发现等服务。其本身也是可以集群化的。实现上是基于观察者模式。不想eureka/consul等同类产品需要心跳机制。他本身支持观察与主动触发机制;千里之行始于足下,我们已经探索了eureka、consul两个服务注册的中间件了。今天我们继续学习另外一个作为服务注册的服务。
本文将从zookeeper单机到集群的安装讲解;在从集群leader选举机制的讲解及数据同步的梳理。到最终的基于zookeeper实现的配置管理及分布式锁的应用。从点到面在到应用带你体会一把过山车
简介
- Zookeeper 大家都知道是动物管理员的意思。在大数据全家桶中他的作用也是管理。下面我们分别从安装到使用来看看zk的优美
中心化
| 服务 | 特点 | 中心化 | CAP |
|---|---|---|---|
| eureka | peer to peer 每个eureka服务默认都会向集群中其他server注册及拉去信息 | 去中心化 | AP |
| consul | 通过其中节点病毒式蔓延至整个集群 | 多中心化 | CP |
| zookeeper | 一个leader多个followes | 中心化 | CP |
事务
-
上面提到zookeeper是一个leader多个followers。
-
除了中心化思想外,zookeeper还有个重要的特性就是事务。zookeeper数据操作是具有原子性的。
-
如何理解zookeeper的事务呢,其实内部是通过版本管理数据实现事务性的。zookeeper每个客户端初始化时都会初始化一个operation。每个client连接是都有个内部的session管理。同一个session操作都会有对应的版本记录,zxid这样能保证数据的一个一致性。
downlaod
单机安装
- 在上面的地址下载后进行解压
tar -zxvf apache-zookeeper-3.5.9-bin.tar.gz

- 官方提供的相当于是个模板,这个时候直接启动会报错的。

- 根据报错信息我们知道缺失zoo.cfg默认配置文件。在conf目录下官方给我们提供了zoo_sample.cfg模板配置文件。我们只需要复制改文件为zoo.cfg在此基础上进行修该
cp zoo_sample.cfg zoo.cfg
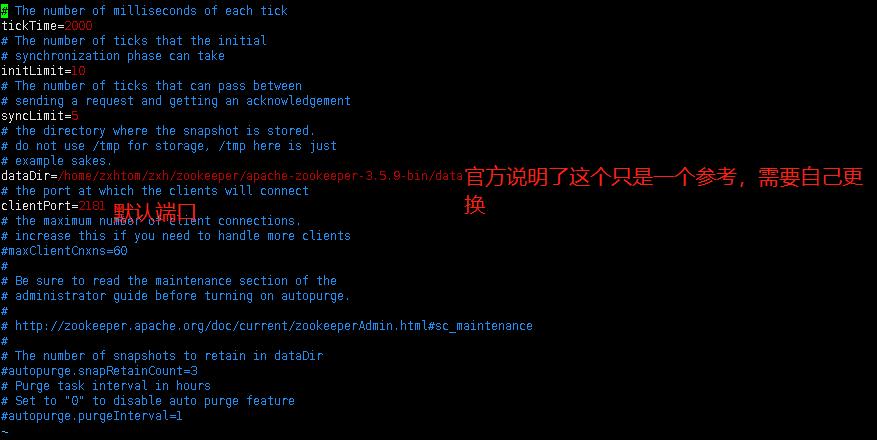
- 我们修改下data路径就可以启动了。
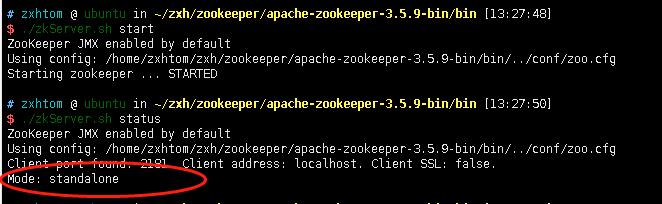
- 启动之后通过’zkServer.sh status’查看zookeeper运行状态。我们可以看到此时是单机模式启动的。

- 通过jps我们也能够看到zookeeper启动成功了。
集群搭建
-
这里的集群为了方便就演示伪集群版。即在一台服务器上布置三台zk服务。
-
mkdir zk1,zk2,zk3, 首先创建zk1,zk2,zk3三个文件夹存放zk -
将之前解压好的zk文件夹分别复制到三个创建zk中

- 在zookeeper进群中,每台服务都需要有一个编号。我们还需要写入每台机器的编号
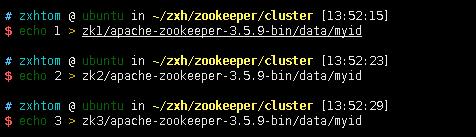
- 然后重复我们单机版的过程。在根目录创建data文件夹,然后修改conf中对应的data配置。只不过这里还需要我们修改一下端口号。因为在同一台机器上所以需要不同的端口号才行。
- 最后新增集群内部通讯端口
server.1=192.168.44.130:28881:38881
server.2=192.168.44.130:28882:38882
server.3=192.168.44.130:28883:38883
- 上述的端口只要保证可用就行了。

-
上面是zk1的配置,其他读者自行配置。
-
在配置总我们多了server的配置。这个server是集群配置的重点
server.1=192.168.44.139:28881:38881
- server是固定写法
- .1 : 1就是我们之前每台zk服务写入的myid里的数字
- 192.168.44.130: 表示我们zk所在服务ip
- 28881: 在zookeeper集群中leader和follewers数据备份通信端口
- 38881: 选举机制的端口

- 上面我是通过zkServer启动不同配置文件。你们也可以在不同的zk包下分别启动。最终效果是一样的。启动完成之后我们通过jps查看可以看到多了三个zk服务。在单机版的时候jps我们知道zk的主启动是QuorumPeerMain。

-
上图是其中一个zk服务的目录结构。我们可以看到data目录有数据产生了。这是zk集群启动之后生成的文件。
-
集群启动完成了。但是我们现在对zk集群好像还是没有太大的感知。比如说我们不知道谁是leader。 可以通过如下命令查看每台zk的角色

- 我们的zk2是leader角色。其他是follower
Cli连接
- 在zookeeper包中还有一个zkCli.sh这个是zk的客户端。通过他我们可以连接zookeeper服务并进行操作。
zkCli.sh -server 192.168.44.131:1181 可以连接zk服务
- 下面我们测试下对zk的操作会不会是集群化的。

-
我们zkCli连接了zk1服务1181,并且创建的一个zk节点名为node。我们在去zk2服务上同样可以看到这个node节点。
-
至此,我们zookeeper集群搭建完成,并且测试也已经通过了。
集群容错
Master选举

- 我们已上述集群启动是为例,简述下集群选举流程。
①、zk1启动时,这个时候集群中只有一台服务就是zk1。此时zk1给集群投票自然被zk1自己获取。 此时zk1有一票
②、zk2启动时,zk1,zk2都会都一票给集群。因为进群中zk1(myid)小于zk2(myid),所以这两票被zk2获取。这里为什么会是zk2获取到呢。zookeeper节点都一份坐标zk=(myid,zxid);myid是每个zk服务配置的唯一项。zxid是zk服务的一个64位内容。高32没master选举一次递增一次并同时清空低32位。低32位是每发生一次数据事务递增一次。所以zxid最高说明此zk服务数据越新。
③、zk2获得两票后,此时已经获得了集群半数以上的票数,少数服从多数此时zk2已经是准leader了同时zk1切换为following 。此时zk1已经是zk2的跟班了
④、zk3启动时,按道理zk3应该会收到三票。但是因为zk1已经站队到zk2了。zk2作为准leader是不可能给zk3投票的。所以zk3最多只有自己一票,zk3明知zk2获得半数以上,已经是民意所归了。所以zk3为了自己的前途也就将自己的一票投给了zk2.
- zookeeper的投票选举机制赤裸裸的就是一个官场。充满的人心
leader宕机重新选举
-
其实在启动阶段zk2获取到两张投票是有一个PK的逻辑在里面的。上述启动阶段的投票是个人的一个抽象化理解。
-
在上面说myid高的不会给myid低的投票实际上是一种片面的理解。实际上是会进行投票的,投票之后会进行两张票PK,将权重高的一张票投出去选举leader。有集群管理者进行统计投票并计数。
-
下面我们来看看重新选举是的逻辑。也是真正的leader选举的逻辑。
①、zk2服务挂了,这个时候zk1,zk3立马切换为looking状态,并分别对集群内其他服务进行投票
②、zk1收到自己的和其他服务投过来的票(1,0)、(3,0) 。zk1会斟酌这两张票,基于我们提到的算法num=10*zxid+myid ,所以zk1会将(3,0)这张票投入计数箱中
③、zk3收到两种票(3,0)、(1,0),同样会将(3,0)投入计数箱
④、最终统计zk3获得两票胜出。
- 上面的选举才是真正的选举。启动时期我们只是加入了我们自己的理解在里面。选举完之后服务会切换成leader、follower状态进行工作
数据同步
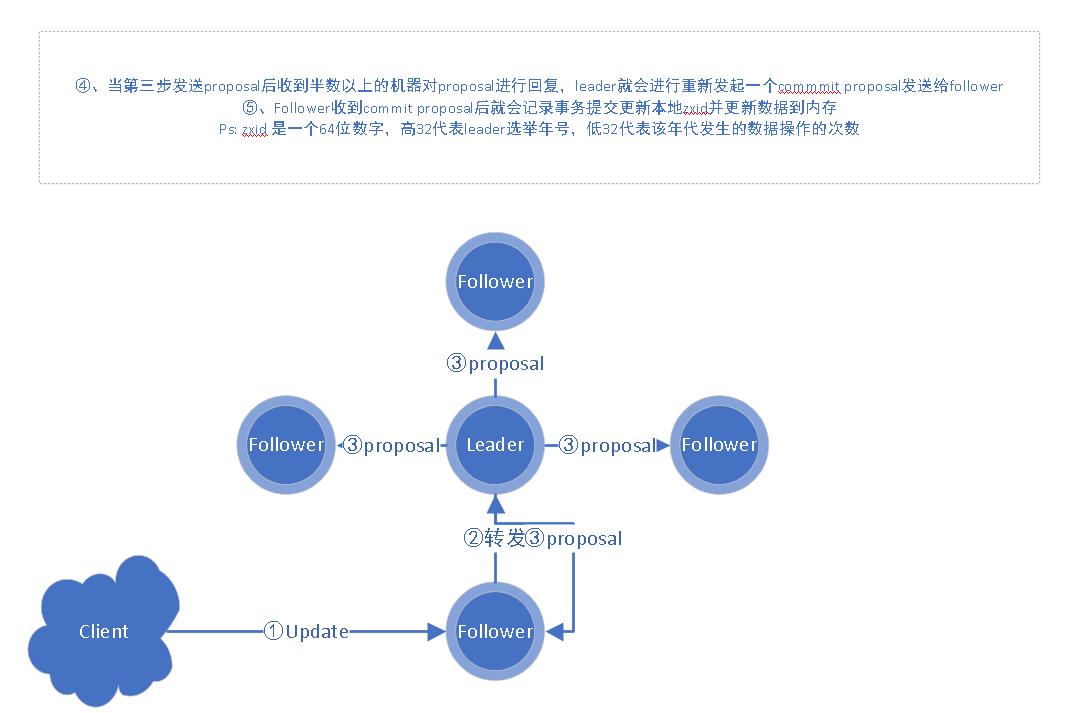
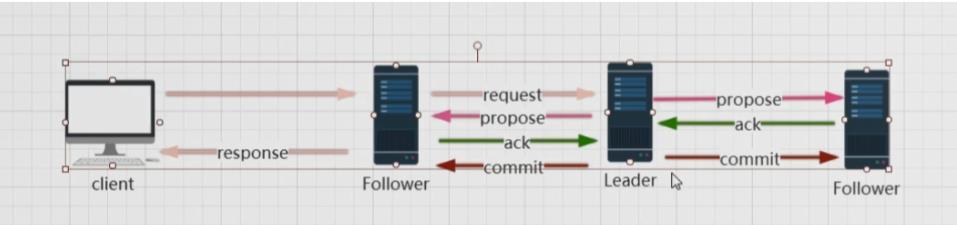
- 同样先上图
- client如果直接将数据变更请求发送到leader端,则直接从图中第三步开始发送proposal请求等待过半机制后再发送commit proposal。follower则会开始更新本地zxid并同步数据。
- 如果client发送的是follower,则需要follower先将请求转发至leader然后在重复上面的步骤。
- 在数据同步期间为了保障数据强一致性。leader发送的proposal都是有序的。follower执行的数据变更也都是有顺序的。这样能保证数据最终一致性。
在一段时间内比如说需要对变量a=5和1=1操作。如果a=5和a=1是两个事物。如果leader通知follower进行同步,zk1先a=1在a=5。则zk1中的a为5.zk3反之来则zk3中a=1;这样就会造成数不一致。但是zookeeper通过znode节点有序排列保证了follower数据消费也是有序的。在莫一时刻zk1执行了a=5,这时候client查了zk1的a是5,虽然表面上是脏数据实际上是zk1未执行完。等待zk1执行完a=1.这就叫数据最终一致性。 - 下面一张图可能更加的形象,来自于网络图片
特色功能
服务治理
- 在我们eureka、consul章节已经介绍了springcloud注册的细节了。今天我们还是同样的操作。已payment和order模块来讲服务注册到zookeeper上。看看效果。
<!-- SpringBoot整合zookeeper客户端 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zookeeper-discovery</artifactId>
</dependency>
- 配置文件配置添加zookeeper
spring:
cloud:
zookeeper:
connect-string: 192.168.44.131:2181
- 和consul一样,这里的注册会将spring.application.name值注册过去。eureka是将spring.application.name的大写名称注册过去。这个影响的就是order订单中调用的地址区别。
- 还是一样的操作。启动order、两个payment之后我们调用
http://localhost/order/getpayment/123可以看到结果是负载均衡了。
配置管理
- 熟悉springcloud的都知道,springcloud是有一个配置中心的。里面主要借助git实现配置的实时更新。具体细节我们后面章节会慢慢展开,本次我们展示通过zookeeper实现配置中心管理。
- 首先我们在我们的payment模块继续开发,引入zookeeper-config模块
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zookeeper-config</artifactId>
</dependency>
- 然后我们需要有个储备知识,在spring加载配置文件的顺序,会先加载bootstrap文件然后是application文件。这里bootstrap我们也用yml格式文件。
spring:
application:
name: cloud-payment-service
profiles:
active: dev
cloud:
zookeeper:
connect-string: 192.168.44.131:2181
config:
enabled: true
root: config
profileSeparator: ','
discovery:
enabled: true
enabled: true
- 上面这部分需要解释下
| key | 解释 |
|---|---|
| spring.application.name | 服务名 |
| spring.profiles | 环境名 |
| spring.cloud.enabled | 用于激活config自动配置 |
| spring.cloud.zookeeper.config.root | zookeeper根路径 |
| spring.cloud.zookeeper.profilSeparator | key分隔符 |
@Component
@ConfigurationProperties(prefix = "spring.datasources")
@Data
@RefreshScope
public class Db
private String url;
-
系统中会读取配置文件中的spring.datasources.url这个属性值。结合我们的bootstrap.yml文件中。此时会去zookeeper系统中查找/config/cloud-payment-service,dev/spring.datasources.url这个值。
-关于那个zookeeper的key是如何来的。细心观察下可以发现他的规律 -
/$spring.cloud.zookeeper.root/$spring.application.name$spring.cloud.zookeeper.profileSeparator$spring.profiles/$实际的key -
唯一注意的是需要在类上添加
@RefreshScope, 这个注解是cloud提供的。包括到后面的config配置中心都离不开这个注解 -
此时通过前文提到的zkCli连接zk服务,然后创建对应节点就可以了。zookeeper服务需要逐层创建。比如上面提到的
/config/cloud-payment-services/spring.datasources.url,我们需要create /config然后create /config/cloud-payment-services在创建最后的内容。 -
我们可以提前在zk中创建好内容。然后
localhost:8001/payment/getUrl获取内容。然后通过set /config/cloud-payment-services/spring.datasources.url helloworld在刷新接口就可以看到最新的helloworld了。这里不做演示。 -
zookeeper原生的创建命令因为需要一层一层创建这还是很麻烦。还有我们有zkui这个插件。这个提供了zookeeper的可视化操作。还支持我们文件导入。上述的配置内容我们只需要导入以下内容的文件即可
/config/cloud-payment-services=spring.datasources.url=hello
zkui安装使用
- 上面我们提到了一个工具
zkui,顾名思义他是zookeeper可视化工具。我们直接下载github源码。
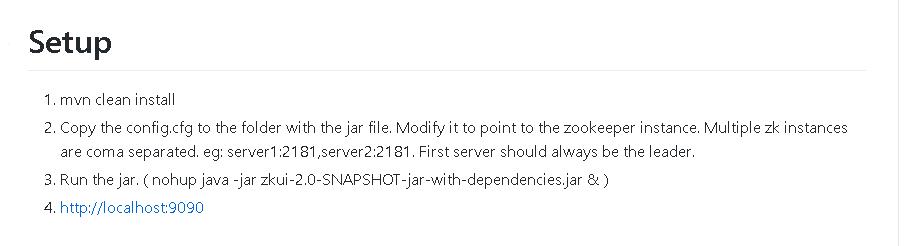
- 官网安装步骤也很简单,因为他就是一个jar服务。

- pom同级执行maven clean install 打包jar 然后
nohup java -jar zkui-2.0-SNAPSHOT-jar-with-dependencies.jar &后台启动就行了。默认端口9090 - 默认用户名密码 官网都给了。 admin:manager


- 在jar包同级官网提供了一份zookeeper配置模板。在里面我们可以配置我们的zookeeper。 如果是集群就配置多个就行了。

-
关于这个zkui的使用这里不多介绍,就是一个可视化。程序员必备技能应该都会使用的。
-
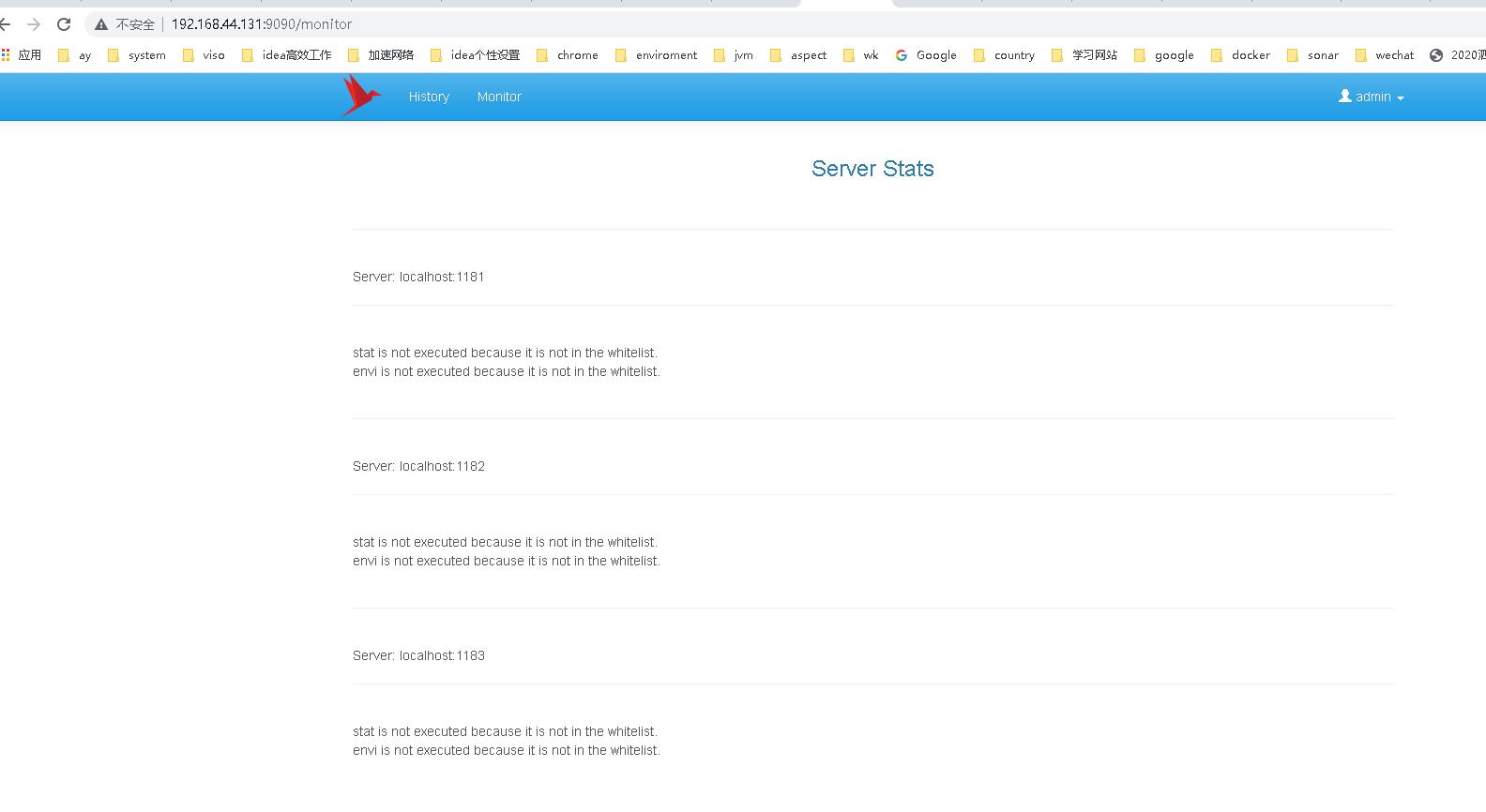
我们项目里使用的都是单机的zookeeper,但是在上面安装的时候我们也有集群zookeeper。端口分别是1181,1182,1183. 我们在zkui的配置文件config.cfg中配置集群即可。
分布式锁
分布式锁常用在共享资源的获取上。在分布式系统的中我们需要协调每个服务的调度。如果不进行控制的话很大程度会造成资源的浪费甚至是资源溢出。常见的就是我们的库存。
- 之前我们springcloud中有一个order和两个payment服务。payment主要用来做支付操作。如果订单成功之后需要调用payment进行扣款。这时候金额相当于资源。这种资源对payment两个服务来说是互斥操作。两个payment过来操作金额时必须先后顺序执行。
mysql隔离控制
- 在以前分布式还不是很普及的时候我们正常处理这些操作时都是结束数据库的事务隔离级别。
| 隔离级别 | 隔离级别 | 现象 |
|---|---|---|
| read uncommit | 读未提交 | 产生脏读 |
| read commited | 读已提交 | 幻读(insert、delete)、不可重复读(update) |
| repeatable read | 可重复度 | 幻读 |
| serializable | 串行化 | 无问题、效率变慢 |
- 基于mysql隔离级别我们可以设置数据库为串行模式。但是带来的问题是效率慢,所有的sql执行都会串行。
mysql锁
- 隔离级别虽然可以满足但是带来的问题确实不可接受。下面就会衍生出mysql锁。我们可以单独建一张表有数据代表上述成功。否则上锁失败。这样我们在操作金额扣减时先判断下这张表有没有数据进行上锁。但是如果上锁之后会造成死锁现象。因为程序异常迟迟没有释放锁就会造成程序瘫痪。
- 这个时候我们可以定时任务清除锁。这样至少保证其他线程可用。
redis锁
- 因为redis本身有失效属性,我们不必担心死锁问题。且redis是内存操作速度比mysql快很多。关于redis锁的实现可以参考我的其他文章redis分布式锁.
zookeeper锁
- 因为zookeeper基于观察者模式,我们上锁失败后可以监听对应的值直到他失效时我们在进行我们的操作这样能够保证我们有序处理业务,从而实现锁的功能。

- 上图是两个线程上锁的简易图示。在zookeeper中实现分布式锁主要依赖
CuratorFramework、InterProcessMutex两个类
CuratorFramework client = CuratorFrameworkFactory.newClient("192.168.44.131:2181", new ExponentialBackoffRetry(1000, 3));
client.start();
InterProcessMutex mutex = new InterProcessMutex(client, "/config/test");
long s = System.currentTimeMillis();
boolean acquire = mutex.acquire(100, TimeUnit.SECONDS);
if (acquire)
long e = System.currentTimeMillis();
System.out.println(e - s+"@@@ms");
System.out.println("lock success....");
- 最终InterProcessMutex实现加锁。加锁会在指定的key上添加一个新的key且带有编号。此时线程中的编号和获取的/config/test下集合编号最小值相同的话则上锁成功。T2则上锁失败,此时会想前一个序号的key添加监听。即当00001失效时则00002对应的T2就会获取到锁。这样可以保证队列的有序进行。
以上是关于分布式服务治理zookeeper原理及使用大全的主要内容,如果未能解决你的问题,请参考以下文章