zookeeper原理及搭建
Posted zzc-log
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了zookeeper原理及搭建相关的知识,希望对你有一定的参考价值。
zookeeper
? zookeeper 是什么?
– ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务
? ZooKeeper能干什么哪?
– ZooKeeper是用来保证数据在集群间的事务性一致
? zookeeper 应用场景
– 集群分布式锁
– 集群统一命名服务
– 分布式协调服务
? zookeeper 角色与特性
– Leader:
– 接受所有Follower的提案请求并统一协调发起提案的投票,负责与所有的Follower进行内部的数据交换
– Follower:
– 直接为客户端服务并参与提案的投票,同时与Leader进行数据交换
– Observer:
– 直接为客户端服务但并不参与提案的投票,同时也与Leader进行数据交换
? zookeeper 角色与选举
– 服务在启动的时候是没有角色的 (LOOKING)
– 角色是通过选举产生的
– 选举产生一个 leader,剩下的是 follower
– 选丼 leader 原则:
– 集群中超过半数机器投票选择leader.
– 假如集群中拥有n台服务器,那么leader必须得到n/2+1台服务器投票
? zookeeper 角色与选举
– 如果 leader 死亡,从新选举 leader
– 如果死亡的机器数量达到一半,集群挂起
– 如果无法得到足够的投票数量,就重新发起投票,如果参与投票的机器不足 n/2+1 集群停止工作
– 如果 follower 死亡过多,剩余机器不足 n/2+1 集群也会停止工作
– observer 不计算在投票总设备数量里面
? zookeeper 可伸缩扩展性原理与设计
– leader 所有写相关操作
– follower 读操作不响应leader提议
– 在Observer出现以前,ZooKeeper的伸缩性由Follower来实现,我们可以通过添加Follower节点的
数量来保证ZooKeeper服务的读性能。但是随着Follower节点数量的增加,ZooKeeper服务的写性
能受到了影响。为什么会出现这种情况?在此,我们需要首先了解一下这个"ZK服务"是如何工作的。
? zookeeper 可伸缩扩展性原理与设计
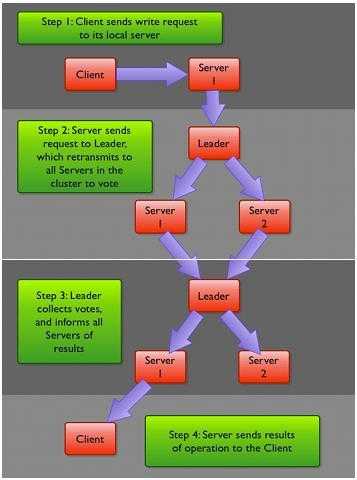
– 客户端提交一个请求,若是读请求,则由每台Server的本地副本数据库直接响应。若是写请求,
需要通过一致性协议(Zab)来处理
– Zab协议规定:来自Client的所有写请求,都要转发给ZK服务中唯一的Leader,由Leader根据该
请求发起一个Proposal。然后,其他的Server对该Proposal进行Vote。之后,Leader对Vote进行收集,
当Vote数量过半时Leader会向所有的Server发送一个通知消息。最后,当Client所连接的Server收到
该消息时,会把该操作更新到内存中并对Client的写请求做出回应
– ZooKeeper 服务器在上述协议中实际扮演了两个职能。它们一方面从客户端接受连接不操作请求,
另一方面对操作结果进行投票。这两个职能在 ZooKeeper集群扩展的时候彼此制约
– 从Zab协议对写请求的处理过程中我们可以发现,增加follower的数量,则增加了对协议中投票过程的压力。
因为Leader节点必须等待集群中过半Server响应投票,于是节点的增加使得部分计算机运行较慢,从而拖慢
整个投票过程的可能性也随之提高,随着集群变大,写操作也会随之下降
– 所以,我们不得不,在增加Client数量的期望和我们希望保持较好吞吐性能的期望间进行权衡。
要打破这一耦合关系,我们引入了不参与投票的服务器,称为Observer。 Observer可以接受客户端
的连接,并将写请求转发给Leader节点。但是,Leader节点不会要求 Observer参加投票。相反,
Observer不参与投票过程,仅仅在上述第3歩那样,和其他服务节点一起得到投票结果
– Observer的扩展,给 ZooKeeper 的可伸缩性带来了全新的景象。我们现在可以加入很多 Observer 节点,
而无须担心严重影响写吞吐量。但他并非是无懈可击的,因为协议中的通知阶段,仍然与服务器的数量呈
线性关系。但是,这里的串行开销非常低。因此,我们可以认为在通知服务器阶段的开销不会成为瓶颈
– Observer提升读性能的可伸缩性
– Observer提供了广域网能力
zookeeper 工作模式
zookeeper 安装
1 、配置 /etc/hosts ,所有集群主机可以相互 ping 通
2、安装java 环境
yum -y install java-1.8.0-openjdk-devel
3、 zookeeper 解压拷贝到 /usr/local/zookeeper
tar -xf zookeeper-3.4.10.tar.gz -C .
mv zookeeper-3.4.10 /usr/local/zookeeper
4、配置文件改名,并在最后添加配置
mv zoo_sample.cfg zoo.cfg
vim zoo.cfg 最后添加配置
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
server.4=nn01:2888:3888:observer
5、拷贝zoo.cfg 到集群其他节点
for i in {11..13} ;do scp /usr/local/zookeeper/conf/zoo.cfg 192.168.1.$i:/usr/local/zookeeper/conf/
6、 拷贝 /usr/local/zookeeper 到其他集群主机
for i in {11..13} ;do scp -r /usr/local/zookeeper 192.168.1.10:/usr/local/zookeeper ; done
7、 所有节点创建 mkdir /tmp/zookeeper
mkdir /tmp/zookeeper
ssh node1 mkdir /tmp/zookeeper
ssh node2 mkdir /tmp/zookeeper
ssh node3 mkdir /tmp/zookeeper
8、 创建 myid 文件,id 必须与配置文件里主机名对应的 server.(id) 一致 echo 1 >/tmp/zookeeper/myid
echo 4 > /tmp/zookeeper/myid
ssh node1 ‘echo 1 > /tmp/zookeeper/myid‘
ssh node2 ‘echo 2 > /tmp/zookeeper/myid‘
ssh node3 ‘echo 3 > /tmp/zookeeper/myid‘
关于myid文件:
– myid文件中只有一个数字
– 注意,请确保每个server的myid文件中id数字丌同
– server.id 中的 id 不 myid 中的 id 必须一致
– id的范围是1~255
9 、启动服务,单启动一台无法查看状态,需要启动全部集群以后才能查看状态
/usr/local/zookeeper/bin/zkServer.sh start
10、 查看状态
/usr/local/zookeeper/bin/zkServer.sh status
11、利用 api 查看状态的脚本
#!/bin/bash
function getstatus(){
exec 9<>/dev/tcp/$1/2181 2>/dev/null
echo stat >&9
MODE=$(cat <&9 |grep -Po "(?<=Mode:).*")
exec 9<&-
echo ${MODE:-NULL}
}
for i in node{1..3} nn01;do
echo -ne "${i} "
getstatus ${i}
done
以上是关于zookeeper原理及搭建的主要内容,如果未能解决你的问题,请参考以下文章