GAN的理解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GAN的理解相关的知识,希望对你有一定的参考价值。
参考技术A生成器(Generator,G)即假钞制造者,辨别器(Discriminator,D)的任务是识别假钞,前者想要尽力蒙混过关,而后者则是努力识别出是真钞(来自于原样本)还是假钞(生成器生成的样本)。两者左右博弈,最后达到一种平衡:生成器能够以假乱真(或者说生成的与原样本再也没差),而判别器以1/2概率来瞎猜。
GAN的主要结构包括一个生成器G(Generator)和一个判别器D(Discriminator)。
我们举手写字的例子来进行进一步窥探GAN的结构。
我们现在拥有大量的手写数字的数据集,我们希望通过GAN生成一些能够以假乱真的手写字图片。主要由如下两个部分组成:
目标函数的理解:
其中判别器D的任务是最大化右边这个函数,而生成器G的任务是最小化右边函数。
首先分解一下式子,主要包含:D(x)、(1-D(G(z))。
D(x)就是判别器D认为样本来自于原分布的概率,而D(G(z))就是判别器D误把来自于生成器G造的假样本判别成真的概率。那么D的任务是最大化D(x)同时最小化D(G(z))(即最大化1-D(G(z))),所以综合一下就是最大化D(x)(1-D(G(z)),为了方便取log,增减性不变,所以就成了logD(x)+log(1-D(G(z))。
而G想让 和 足够像,也就是D(G(z))足够大;而logD(x)并不对它本身有影响,所以他的衡量函数可以只是minlog(1-D(z)),也可以加一个对他来说的常数后变为
目标函数的推导、由来
判别器在这里是一种分类器,用于区分样本的真伪,因此我们常常使用交叉熵(cross entropy)来进行判别分布的相似性,交叉熵公式如下:
公式中 和 为真实的样本分布和生成器的生成分布。 关于交叉熵的内容
在当前模型的情况下,判别器为一个二分类问题,因此可以对基本交叉熵进行更具体地展开如下:
为正确样本分布,那么对应的( )就是生成样本的分布。 D 表示判别器,则 表示判别样本为正确的概率, 则对应着判别为错误样本的概率。
将上式推广到N个样本后,将N个样本相加得到对应的公式如下:
到目前为止还是基本的二分类,下面加入GAN中特殊的地方。
对于GAN中的样本点 ,对应于两个出处,要么来自于真实样本,要么来自于生成器生成的样本 ~ ( 这里的 是服从于投到生成器中噪声的分布)。
其中,对于来自于真实的样本,我们要判别为正确的分布 。来自于生成的样本我们要判别其为错误分布( )。将上面式子进一步使用概率分布的期望形式写出(为了表达无限的样本情况,相当于无限样本求和情况),并且让 为 1/2 且使用 表示生成样本可以得到如下:
与原式 其实是同样的式子
若给定一个样本数据的分布 和生成的数据分布 那么 GAN 希望能找到一组参数 使分布 和 之间的距离最短,也就是找到一组生成器参数而使得生成器能生成十分逼真的图片。
现在我们可以从训练集抽取一组真实图片来训练 分布中的参数 使其能逼近于真实分布。因此,现在从 中抽取 个真实样本 ,对于每一个真实样本,我们可以计算 ,即在由 确定的生成分布中, 样本所出现的概率。因此,我们就可以构建似然函数:
从该似然函数可知,我们抽取的 个真实样本在 分布中全部出现的概率值可以表达为 L。又因为若 分布和 分布相似,那么真实数据很可能就会出现在 分布中,因此 个样本都出现在 分布中的概率就会十分大。
下面我们就可以最大化似然函数 L 而求得离真实分布最近的生成分布(即最优的参数θ):
在上面的推导中,我们希望最大化似然函数 L。若对似然函数取对数,那么累乘 ∏ 就能转化为累加 ∑ ,并且这一过程并不会改变最优化的结果。因此我们可以将极大似然估计化为求令 期望最大化的θ,而期望 可以展开为在 x 上的积分形式: 。又因为该最优化过程是针对θ的,所以我们添加一项不含θ的积分并不影响最优化效果,即可添加 。添加该积分后,我们可以合并这两个积分并构建类似 KL 散度的形式。该过程如下:
这一个积分就是 KL 散度的积分形式,因此,如果我们需要求令生成分布 尽可能靠近真实分布 的参数 θ,那么我们只需要求令 KL 散度最小的参数θ。若取得最优参数θ,那么生成器生成的图像将显得非常真实。
下面,我们必须证明该最优化问题有唯一解 G*,并且该唯一解满足 。不过在开始推导最优判别器和最优生成器之前,我们需要了解 Scott Rome 对原论文推导的观点,他认为原论文忽略了可逆条件,因此最优解的推导不够完美。
在 GAN 原论文中,有一个思想和其它很多方法都不同,即生成器 G 不需要满足可逆条件。Scott Rome 认为这一点非常重要,因为实践中 G 就是不可逆的。而很多证明笔记都忽略了这一点,他们在证明时错误地使用了积分换元公式,而积分换元却又恰好基于 G 的可逆条件。Scott 认为证明只能基于以下等式的成立性:
该等式来源于测度论中的 Radon-Nikodym 定理,它展示在原论文的命题 1 中,并且表达为以下等式:
我们看到该讲义使用了积分换元公式,但进行积分换元就必须计算 ,而 G 的逆却并没有假定为存在。并且在神经网络的实践中,它也并不存在。可能这个方法在机器学习和统计学文献中太常见了,因此我们忽略了它。
在极小极大博弈的第一步中,给定生成器 G,最大化 V(D,G) 而得出最优判别器 D。其中,最大化 V(D,G) 评估了 P_G 和 P_data 之间的差异或距离。因为在原论文中价值函数可写为在 x 上的积分,即将数学期望展开为积分形式:
其实求积分的最大值可以转化为求被积函数的最大值。而求被积函数的最大值是为了求得最优判别器 D,因此不涉及判别器的项都可以看作为常数项。如下所示,P_data(x) 和 P_G(x) 都为标量,因此被积函数可表示为 a D(x)+b log(1-D(x))。
若令判别器 D(x) 等于 y,那么被积函数可以写为:
为了找到最优的极值点,如果 a+b≠0,我们可以用以下一阶导求解:
如果我们继续求表达式 f(y) 在驻点的二阶导:
其中 a,b∈(0,1)。因为一阶导等于零、二阶导小于零,所以我们知道 a/(a+b) 为极大值。若将 a=P_data(x)、b=P_G(x) 代入该极值,那么最优判别器 D(x)=P_data(x)/(P_data(x)+P_G(x))。
最后我们可以将价值函数表达式写为:
如果我们令 D(x)=P_data/(P_data+p_G),那么我们就可以令价值函数 V(G,D) 取极大值。因为 f(y) 在定义域内有唯一的极大值,最优 D 也是唯一的,并且没有其它的 D 能实现极大值。
其实该最优的 D 在实践中并不是可计算的,但在数学上十分重要。我们并不知道先验的 P_data(x),所以我们在训练中永远不会用到它。另一方面,它的存在令我们可以证明最优的 G 是存在的,并且在训练中我们只需要逼近 D。
当然 GAN 过程的目标是令 P_G=P_data。这对最优的 D 意味着什么呢?我们可以将这一等式代入 D_G*的表达式中:
这意味着判别器已经完全困惑了,它完全分辨不出 P_data 和 P_G 的区别,即判断样本来自 P_data 和 P_G 的概率都为 1/2。基于这一观点,GAN 作者证明了 G 就是极小极大博弈的解。该定理如下:
「当且仅当 P_G=P_data,训练标准 C(G)=maxV(G,D) 的全局最小点可以达到。」
以上定理即极大极小博弈的第二步,求令 V(G,D ) 最小的生成器 G(其中 G 代表最优的判别器)。之所以当 P_G(x)=P_data(x) 可以令价值函数最小化,是因为这时候两个分布的 JS 散度 [JSD(P_data(x) || P_G(x))] 等于零,这一过程的详细解释如下。
原论文中的这一定理是「当且仅当」声明,所以我们需要从两个方向证明。首先我们先从反向逼近并证明 C(G) 的取值,然后再利用由反向获得的新知识从正向证明。设 P_G=P_data(反向指预先知道最优条件并做推导),我们可以反向推出:
该值是全局最小值的候选,因为它只有在 P_G=P_data 的时候才出现。我们现在需要从正向证明这一个值常常为最小值,也就是同时满足「当」和「仅当」的条件。现在放弃 P_G=P_data 的假设,对任意一个 G,我们可以将上一步求出的最优判别器 D* 代入到 C(G)=maxV(G,D) 中:
因为已知 -log4 为全局最小候选值,所以我们希望构造某个值以使方程式中出现 log2。因此我们可以在每个积分中加上或减去 log2,并乘上概率密度。这是一个十分常见并且不会改变等式的数学证明技巧,因为本质上我们只是在方程加上了 0。
采用该技巧主要是希望能够构建成含 log2 和 JS 散度的形式,上式化简后可以得到以下表达式:
因为概率密度的定义,P_G 和 P_data 在它们积分域上的积分等于 1,即:
此外,根据对数的定义,我们有:
因此代入该等式,我们可以写为:
现在,如果读者阅读了前文的 KL 散度(Kullback-Leibler divergence),那么我们就会发现每一个积分正好就是它。具体来说:
KL 散度是非负的,所以我们马上就能看出来-log4 为 C(G) 的全局最小值。
如果我们进一步证明只有一个 G 能达到这一个值,因为 P_G=P_data 将会成为令 C(G)=−log4 的唯一点,所以整个证明就能完成了。
从前文可知 KL 散度是非对称的,所以 C(G) 中的 KL(P_data || (P_data+P_G)/2) 左右两项是不能交换的,但如果同时加上另一项 KL(P_G || (P_data+P_G)/2),它们的和就能变成对称项。这两项 KL 散度的和即可以表示为 JS 散度(Jenson-Shannon divergence):
假设存在两个分布 P 和 Q,且这两个分布的平均分布 M=(P+Q)/2,那么这两个分布之间的 JS 散度为 P 与 M 之间的 KL 散度加上 Q 与 M 之间的 KL 散度再除以 2。
JS 散度的取值为 0 到 log2。若两个分布完全没有交集,那么 JS 散度取最大值 log2;若两个分布完全一样,那么 JS 散度取最小值 0。
因此 C(G) 可以根据 JS 散度的定义改写为:
这一散度其实就是 Jenson-Shannon 距离度量的平方。根据它的属性:当 P_G=P_data 时,JSD(P_data||P_G) 为 0。综上所述,生成分布当且仅当等于真实数据分布式时,我们可以取得最优生成器。
前面我们已经证明 P_G=P_data 为 minV(G,D) 的最优点。此外,原论文还有额外的证明白表示:给定足够的训练数据和正确的环境,训练过程将收敛到最优 G。
证明:将V(G,D)=U(pg,D)视作pg的函数,则U为pg的凸函数,其上确界的次导数一定包括该函数最大值处的导数,所以给定D时,通过梯度下降算法更新pg从而优化G时,pg一定会收敛到最优值。而之前又证明了目标函数只有唯一的全局最优解,所以pg会收敛到pdata。
实际上优化G时是更新θg而不是pg。
参考链接:
Generative Adversarial Nets
通俗理解生成对抗网络GAN - 陈诚的文章 - 知乎
机器之心GitHub项目:GAN完整理论推导与实现,Perfect!
论文阅读之Generative Adversarial Nets
关于gan的流程理解
关于gan的流程理解,
最近再看cyclegan所以慢慢来看,最后了解了原理来跑代码就好
先说第一点:
架构
gan的架构就是两个重要的点:1 生成器 2 分辨器
生成器的作用就是生成假的图片
分辨器的作用就是在给一个正确的图片和一个生成的假的图片之后,他可以把正确的找出来
由此,其实我这里提出好多问题:
1 如何生成假的图片:反卷积
2 如何判断,好像是一个二分类,两个图片都给过去,<0.5就是假的,>0.5就是真的,当然这个0.x就是sigmoid(wx+b)(也就是距离的sigmoid值,)可是还是有问题,同时给两个图片吗?应该是给一个图片,然后算距离?不是,给两个图片,都算标定值的距离,两个物体只能二分类?
3 如何梯度下降?
带着这几个问题去读源码
面对第一个问题:如何生成图片,源码给出的解决方案是反卷积,
那么如何反卷积呢?
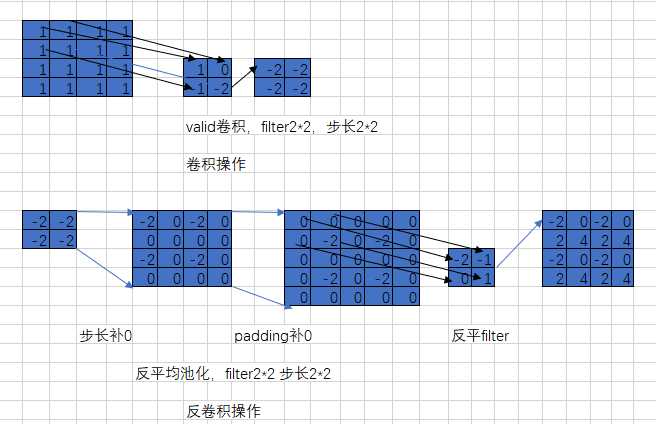
就是这样:
具体函数就一个:nn.ConvTranspose2d(ngf * mult, int(ngf * mult / 2),
kernel_size=3, stride=2,
padding=1, output_padding=1,
bias=use_bias),
首先的操作是:
1 进行卷积上图第一行 feature:4*4 filter: 2*2 stride: 2 得到结果:2*2
2 进行反卷积:首先第一步:
1 补0:让卷积后的结果,每一个元素后面都补(stride-1)个0 成为了 下左2
2 补0:对整体再补0,这个整体补0的个数是取决于补0之后,把卷积核完全颠倒过来,按照stride=1进行卷积,卷积之后要得到原始大小(上左一)的结果
以上是关于GAN的理解的主要内容,如果未能解决你的问题,请参考以下文章