spss数据库打开只有一个视图
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spss数据库打开只有一个视图相关的知识,希望对你有一定的参考价值。
spss数据库打开只有一个视图的原因:第一,由于下载过程中,系统的软件的源代码发生丢失,导致系统无法被识别,出现错误。
第二,由于软件在安装完毕后,子文件或者执行程序的文件收到损坏,导致系统无法运行这个软件,从而导致出现错误,
第三,由于系统与软件当前版本不兼容导致。
希望能帮到您。 参考技术A 菜单栏显示各项基本的功能,工具栏显示常用的功能。标签栏包含数据窗口标签和变量窗口标签。其余基本与EXCEL类似。
定制SPSS视图
定制SPSS视图,主要通过菜单栏的视图选项卡实现。
1.菜单栏。菜单栏内容可以根据实际需要进行调整,依次单击“视图-菜单编辑器”,弹出菜单编辑器窗口,可以根据需要对菜单栏内容进行个性化调整。2.工具栏。工具栏可以隐藏,也可以定制工具栏内容。依次单击“视图-工具栏”,取消勾选数据编辑器,可以实现隐藏工具栏。依次单击“视图-工具栏-定制”,系统弹出“显示工具栏”窗口,可以根据需求对工具栏内容进行调整。
如何使用spss进行交叉列联表分析
1、首先我们打开之前导入的spps文件。

2、然后我们选择变量视图。
3、然后我们选择分析,定义多重变量。

4、然后我们从分析处,将单选与多选交叉分析。

5、然后我们定义交叉分析格式,点击选项。

6、然后我们定义范围,点击“确定”,输出结果即可。

1、首先打开spss依次打开文件,打开、最后打开数据导入选项,导入sav数据:

2、这里选择好数据直接双击打开即可:
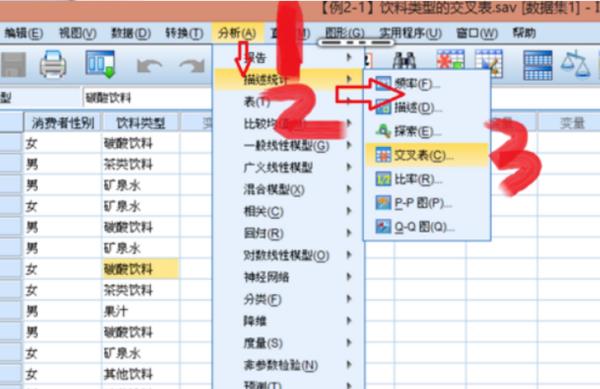
3、然后点击菜单中分析,描述统计,交叉表,弹出交叉表的选项:
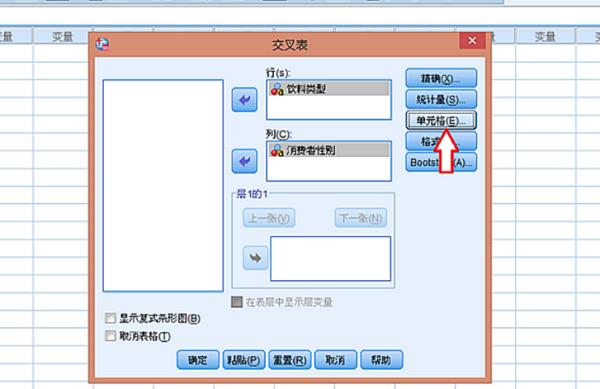
4、打开交叉表以后,将对应的数据拖拽到对应的行和列下方的方框里,然后直接单击下方的确定即可:
5、然后继续勾选总计,点击下方继续按钮,如果需要百分比可以勾选百分比的选项:

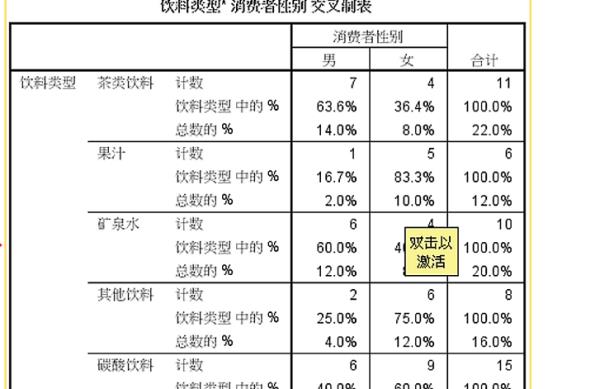
6、随后就会生成实力中的饮料类型和消费者性别的列联表及其分析表了,表中对饮料的消费情况也是一目了然的。以上就是使用spss进行交叉列联表分析的方法:
1、首先打开spss,按照“文件”-“打开”-“数据”导入sav数据。
2、本例使用的数据是“饮料类型的交叉表”,选中直接打开即可。
3、制作列联表,按照图中步骤,点击“分析”-“描述统计”-“交叉表”即可。
4、打开“交叉表”。将对应的数据拖拽到对应的“行”(“列”)下方的方框里(或者点击最左边方框中的数据,点击中间的箭头,也能实现相同的动作)。

5、根据需要勾选百比分框里的“行”或者“列”(此例以行为例),继续勾选“总计”,点击下方“继续”按钮。

6、生成的是饮料类型和消费者性别的列联表及其分析表。

SPSS提供了多种适用于不同类型数据的相关系数表达,这些相关性检验的零假设都是:行和列变量之间相互独立,不存在显著的相关关系。根据SPSS检验后得出的相伴概率(Concomitant Significance)判断是否存在相关关系。如果相伴概率小于显著性水平0.05,那么拒绝零假设,行列变量之间彼此相关;如果相伴概率大于显著性水平0.05,那么接受原假设,行列变量之间彼此独立。
在交叉列联表分析中,SPSS所提供的相关关系的检验方法主要有以下3种:
(1)卡方(χ2)统计检验:常用于检验行列变量之间是否相关。计算公式为:
其中,f0表示实际观察频数,fe表示期望频数。

卡方统计量服从(行数 1) (列数 1)个自由度的卡方统计。SPSS在计算卡方统计量时,同时给出相应的相伴概率,由此判断行列变量之间是否相关。
(2)列联系数(Contingency coefficient):常用于名义变量之间的相关系数计算。计算公式由卡方统计量修改而得,公式如下:

(3) 系数(Phi and Cramer's V):常用于名义变量之间的相关系数计算。计算公式由卡方统计量修改而得,公式如下:
系数介于0和1之间,其中,K为行数和列数较小的实际数。
交叉列联表分析的具体操作步骤如下:
打开数据文件,选择【分析】(Analyze)菜单,单击【描述统计】(Descriptive Statistics)命令下的【交叉表】(Crosstabs)命令。"交叉表"(Crosstabs)主对话框如图3-13所示。

在该主对话框中,左边的变量列表为原变量列表,通过单击 按钮可选择一个或者几个变量进入右边的"行"(Row(s))变量列表框、"列"(Column(s))变量列表框和"层"(Layer)变量列表框中。
如果是二维列联表分析,只需选择行列变量即可,但如进行三维以上的列联表分析,可以将其他变量作为控制变量选到"层"(Layer)变量列表框中。有多个层控制变量时,可以根据实际的分析要求确定它们的层次,既可以是同层次的也可以是逐层叠加的。
在"交叉表"对话框底端有两个可选择项:
显示复式条形图(Display clustered bar chart):指定绘制各个变量不同交叉取值下关于频数分布的柱形图;
取消表格(Suppress table):不输出列联表的具体表格,而直接显示交叉列联表分析过程中的统计量,如果没有选中统计量,则不产生任何结果。所以,一般情况下,只有在分析行列变量间关系时选择此项。
该对话框的右端有4个按钮,从上到下依次为【精确】(Exact)按钮、【统计量】(Statistics)按钮、【单元格】(Cells)按钮和【格式】(Format)按钮。单击可进入对应的对话框。
单击【精确】(Exact)按钮,打开"精确检验"(Exact Tests)对话框,如图3-14所示。
该对话框提供了3种用于不同条件的检验方式来检验行列变量的相关性。用户可选择以下3种检验方式之一:
仅渐近法(Asymptotic only):适用于具有渐近分布的大样本数据,SPSS默认选择该项。
Monte Carlo(蒙特卡罗法):此项为精确显著性水平值的无偏估计,无需数据具有渐近分布的假设,是一种非常有效的计算确切显著性水平的方法。在"置信水平"(Confidence Level)参数框内输入数据,可以确定置信区间的大小,一般为90、95、99。在"样本数"(Number of samples)参数框中可以输入数据的样本容量。
精确(Exact):观察结果概率,同时在下面的"每个检验的时间限制为"(Time limit per test)的参数框内,选择进行精确检验的最大时间限度。
用户在本对话框内进行选择后,单击【继续】(Continue)按钮即可返回"交叉表"主对话框。一般情况下,"精确检验"(Exact Tests)对话框的选项都默认为系统默认值,不作调整。

单击【统计量】(Statistics)按钮,打开"交叉表:统计量"(Crosstabs:Statistics)对话框,如图3-15所示。
在该对话框中,用户可以选择输出合适的统计检验统计量。对话框中各选项的意义如下:
(1)卡方(Chi-square)检验复选框:检验列联表行列变量的独立性检验,也被称为Pearson chi-square检验、χ2检验。
(2)相关性(Correlations)检验复选框:输出列联表行列变量的Pearson相关系数或Spearman相关系数。
(3)名义(Nominal)栏:适用于名称变量统计量。
相依系数(Contingency coefficient):即Pearson相关系数或Spearman相关系数。
Phi 和Cramer变量( 系数):常用于名义变量之间的相关系数计算。计算公式由卡方统计量修改而得,如公式(3.13)所示。ψ系数介于0和1之间,其中,K为行数和列数较小的实际数。
Lambda(λ系数):在自变量预测中用于反映比例缩减误差,其值为1时表明自变量预测因变量好,为0时表明自变量预测因变量差。
不定性系数(Uncertainty coefficient):以熵为标准的比例缩减误差,其值接近1时表明后一变量的信息很大程度上来自前一变量,其值接近0时表明后一变量的信息与前一变量无关。

(4)有序(Ordinal)栏:适用于有序变量的统计量。
Gamma(伽马系数,γ系数):两有序变量之间的关联性的对称检验。其数值界于0和1之间,所有观察实际数集中于左上角和右下角时,取值为1,表示两个变量之间有很强的相关;取值为0时,表示两个变量之间相互独立。
Somers'd值:两有序变量之间的关联性的检验,取值范围为[-1,1]。
Kendall s tau-b值:考虑有结的秩或等级变量关联性的非参数检验,相同的观察值选入计算过程中,取值范围为[-1,1]。
Kendall s tau-c值:忽略有结的秩或等级变量关联性的非参数检验,相同的观察值不选入计算过程,取值范围界为[-1,1]。
(5)按区间标定(Nominal by interval)栏:适用于一个名义变量与一个等距变量的相关性检验。
Kappa系数:检验数据内部的一致性,仅适用于具有相同分类值和相同分类数量的变量交叉表。
Eta值:其平方值可认为是因变量受不同因素影响所致方差的比例。
风险(相对危险度):检验事件发生和某因素之间的关联性。
McNemar检验:主要用于检验配对的资料率(相当于配对卡方检验)。
(6)Cochran's and Mantel-Haenszel统计量复选框:适用于在一个二值因素变量和一个二值响应变量之间的独立性检验。
用户在"交叉表:统计量"对话框中进行选择后,单击【继续】(Continue),即可返回"交叉表"(Crosstabs)主对话框。一般情况下,对"交叉表:统计量"对话框内的选项不作选择或选择较为常用的卡方检验。
单击【单元格】(Cells)按钮,打开"交叉表:单元显示"(Crosstabs:Cell Display)对话框,如图3-16所示。

在该对话框中,用户可以指定列联表单元格中的输出内容。SPSS17.0默认在交叉列联表中输出实际的观察值,但观察值有时候不能确切地反映事物的实质,因此还需要输出其他的数据项。对话框中各选项的具体意义如下:
(1)计数(Counts)栏:
观察值(Observed):系统默认选项,表示输出为实际观察值。
期望值(Expected):表示输出为理论值。
(2)百分比(Percentages)栏:
行(Row)百分比:以行为单元,统计行变量的百分比。
列(Column)百分比:以列为单元,统计列变量的百分比。
总计(Total)百分比:行列变量的百分比都进行输出。
(3)残差(Residuals)栏:
未标准化(Unstandardized):输出非标准化残差,为实际数与理论数的差值。
标准化(Standardized):输出标准化残差,为实际数与理论数的差值除以理论数。
调节的标准化(Adjusted standardized):输出修正标准化残差,为标准误确定的单元格残差。
(4)非整数权重(Noninteger Weights)栏:
四舍五入单元格计数(Round cell counts,系统默认):将单元格计数的非整数部分的尾数四舍五入为整数。
截短单元格计数(Truncate cell counts):将单元格计数的非整数部分的尾数舍去,直接化为整数。
四舍五入个案权重(Round case Weights):将观测量权数的非整数部分的尾数四舍五入为整数。
截短个案权重(Truncate case Weights):将观测量权数的非整数部分的尾数舍去,化为整数。
无调节(No adjustments):不对计数数据进行调整。
用户在"交叉表:单元显示"对话框中进行选择后,单击【继续】(Continue)按钮,即可返回"交叉表"主对话框。一般情况下,对"交叉表:单元显示"对话框的选项都默认为系统默认值,不作调整。
单击【格式】(Format)按钮,打开"交叉表:表格格式"(Crosstabs:Table Format)对话框,如图3-17所示。
在该对话框中,用户可以指定列联表的输出排列顺序。对话框中各选项的具体意义如下:
在行序(Row Order)栏中有如下两个选项:
升序(Ascending):系统默认,以升序显示各变量值;
降序(Descending):以降序显示各变量值。
用户在该对话框中进行选择后,单击【继续】(Continue)按钮,即可返回"交叉表"主对话框。
在"交叉表"对话框中单击【确定】(OK)按钮,可在输出窗口中得到数据概述、交叉列联表、卡方检验表、交叉分组下频率分布柱形图、相对危险性估计等图表。
本回答被提问者和网友采纳 参考技术D 用SPSS打开数据文件,然后依次打开“分析”--“描述统计”--“交叉表格”,即可打开交叉分析对...2.
选中“您的年龄"放入“行”,选中“您是否使用过知识付费”放入到“列”。
3.
选中右上角第二个按钮“Statistics",出现统计对话框。选中“卡方”和“Phi和Crame...
以上是关于spss数据库打开只有一个视图的主要内容,如果未能解决你的问题,请参考以下文章