rabbitMQ的详细介绍
Posted 源码CRMEB
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了rabbitMQ的详细介绍相关的知识,希望对你有一定的参考价值。
1.概述
RabbitMQ是一个消息中间件:它接受并转发消息。你可以把它当做一个快递站点,当你要发送一个包裹时,你把你的包裹放到快递站,快递员最终会把你的快递送到收件人那里,按照这种逻辑RabbitMQ是一个快递站,一个快递员帮你传递快件。RabbitMQ与快递站的主要区别在于,它不处理快件而是接收,存储和转发消息数据。
2.下载
rabbitMQ下载详情可见
如何下载安装RabbitMQ
https://www.crmeb.com/ask/thread/23689 Copy
3.工作原理
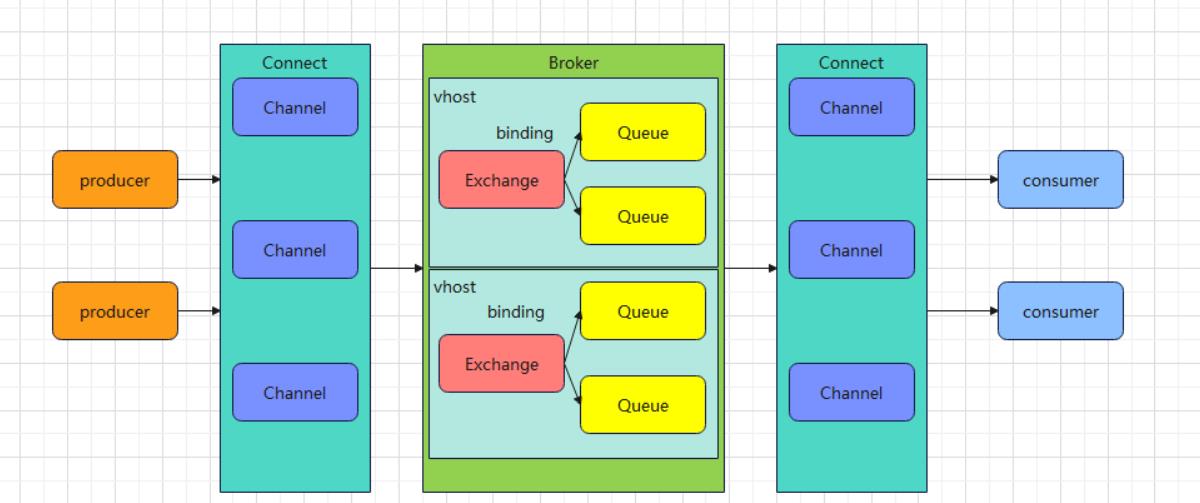
4.名词介绍
Broker:接收和分发消息的应用,RabbitMQ Server就是Message Broker
Connection: publisher / consumer和 broker之间的TCP连接
Channel:如果每一次访问RabbitMQ都建立一个Connection,在消息量大的时候建立TCP
Connection的开销将是巨大的,效率也较低。Channel是在connection 内部建立的逻辑连接,如果应用程序支持多线程,通常每个thread创建单独的channel进行通讯,AMQP method包含了channel id 帮助客户端和message broker识别 channel,所以channel 之间是完全隔离的。Channel作为轻量级的Connection极大减少了操作系统建TCP connection的开销
Exchange: message 到达 broker 的第一站,根据分发规则,匹配查询表中的 routing key,分发消息到queue 中去。常用的类型有: direct (point-to-point), topic(publish-subscribe) and fanout
(multicast)
Routing Key:生产者将消息发送到交换机时会携带一个key,来指定路由规则
binding Key:在绑定Exchange和Queue时,会指定一个BindingKey,生产者发送消息携带的RoutingKey会和bindingKey对比,若一致就将消息分发至这个队列
vHost 虚拟主机:每一个RabbitMQ服务器可以开设多个虚拟主机每一个vhost本质上是一个mini版的RabbitMQ服务器,拥有自己的 "交换机exchange、绑定Binding、队列Queue",更重要的是每一个vhost拥有独立的权限机制,这样就能安全地使用一个RabbitMQ服务器来服务多个应用程序,其中每个vhost服务一个应用程序。
5.交换机类型
1.direct Exchange(直接交换机)
匹配路由键,只有完全匹配消息才会被转发
2.Fanout Excange(扇出交换机)
将消息发送至所有的队列
3.Topic Exchange(主题交换机)
将路由按模式匹配,此时队列需要绑定要一个模式上。符号“#”匹配一个或多个词,符号“匹配不多不少一个词。因此“abc.#”能够匹配到“abc.def.ghi”,但是“abc.” 只会匹配到“abc.def”。
4.Header Exchange
在绑定Exchange和Queue的时候指定一组键值对,header为键,根据请求消息中携带的header进行路由
6.工作模式
1.simple (简单模式)
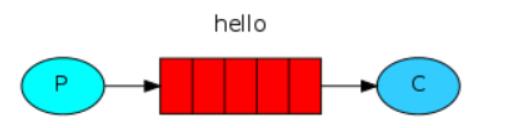
一个消费者消费一个生产者生产的信息
2.Work queues(工作模式)
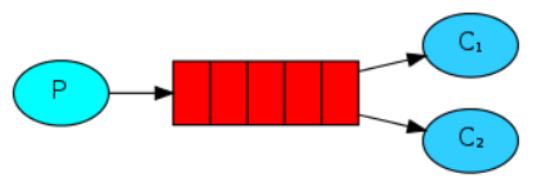
一个生产者生产信息,多个消费者进行消费,但是一条消息只能消费一次
3.Publish/Subscribe(发布订阅模式)
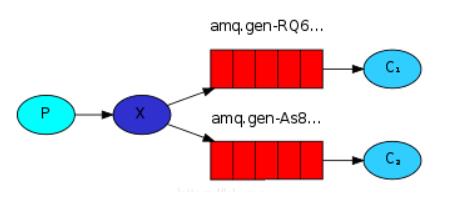
生产者首先投递消息到交换机,订阅了这个交换机的队列就会收到生产者投递的消息
4.Routing(路由模式)
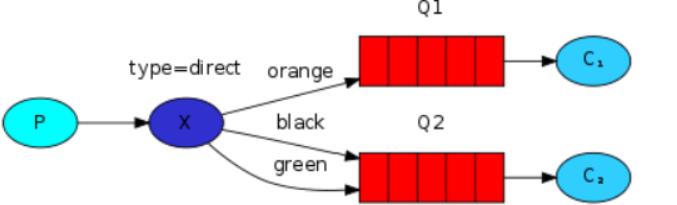
生产者生产消息投递到direct交换机中,扇出交换机会根据消息携带的routing Key匹配相应的队列
5.Topics(主题模式)

生产者生产消息投递到topic交换机中,上面是完全匹配路由键,而主题模式是模糊匹配,只要有合适规则的路由就会投递给消费者
7.保证消息的稳定性
1.消息持久化
RabbitMQ的消息默认存在内存中的,一旦服务器意外挂掉,消息就会丢失
消息持久化需做到三点
- Exchange设置持久化
- Queue设置持久化
- Message持久化发送:发送消息设置发送模式deliveryMode=2,代表持久化消息
2.ACK确认机制
多个消费者同时收取消息,收取消息到一半,突然某个消费者挂掉,要保证此条消息不丢失,就需要acknowledgement机制,就是消费者消费完要通知服务端,服务端才将数据删除
这样就解决了,及时一个消费者出了问题,没有同步消息给服务端,还有其他的消费端去消费,保证了消息不丢的case。
3.设置集群镜像模式
我们先来介绍下RabbitMQ三种部署模式:
1)单节点模式:最简单的情况,非集群模式,节点挂了,消息就不能用了。业务可能瘫痪,只能等待。
2)普通模式:默认的集群模式,某个节点挂了,该节点上的消息不能用,有影响的业务瘫痪,只能等待节点恢复重启可用(必须持久化消息情况下)。
3)镜像模式:把需要的队列做成镜像队列,存在于多个节点,属于RabbitMQ的HA方案
为什么设置镜像模式集群,因为队列的内容仅仅存在某一个节点上面,不会存在所有节点上面,所有节点仅仅存放消息结构和元数据。下面自己画了一张图介绍普通集群丢失消息情况
4.消息补偿机制
持久化的消息,保存到硬盘过程中,当前队列节点挂了,存储节点硬盘又坏了,消息丢了,怎么办?
产线网络环境太复杂,所以不知数太多,消息补偿机制需要建立在消息要写入DB日志,发送日志,接受日志,两者的状态必须记录。
然后根据DB日志记录check 消息发送消费是否成功,不成功,进行消息补偿措施,重新发送消息处理。
8.如何实现延迟队列
RabbitMQ本身没有延迟队列,需要靠TTL和DLX模拟出延迟的效果
TTL(Time To Live)
RabbitMQ可以针对Queue和Message设置 x-message-tt,来控制消息的生存时间,如果超时,则消息变为dead letter
RabbitMQ针对队列中的消息过期时间有两种方法可以设置。
A: 通过队列属性设置,队列中所有消息都有相同的过期时间。
B: 对消息进行单独设置,每条消息TTL可以不同。
如果同时使用,则消息的过期时间以两者之间TTL较小的那个数值为准。消息在队列的生存时间一旦超过设置的TTL值,就成为dead letter
DLX (Dead-Letter-Exchange)
RabbitMQ的Queue可以配置x-dead-letter-exchange 和x-dead-letter-routing-key(可选)两个参数,如果队列内出现了dead letter,则按照这两个参数重新路由。
x-dead-letter-exchange:出现dead letter之后将dead letter重新发送到指定exchange
x-dead-letter-routing-key:指定routing-key发送
队列出现dead letter的情况有:
消息或者队列的TTL过期
队列达到最大长度
消息被消费端拒绝(basic.reject or basic.nack)并且requeue=false
利用DLX,当消息在一个队列中变成死信后,它能被重新publish到另一个Exchange。这时候消息就可以重新被消费。
RabbitMQ消息队列: Detailed Introduction 详细介绍
RabbitMQ消息队列(一): Detailed Introduction 详细介绍
版权声明:本文为博主原创文章,未经博主允许不得转载。
1. 历史
RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现。AMQP 的出现其实也是应了广大人民群众的需求,虽然在同步消息通讯的世界里有很多公开标准(如 COBAR的 IIOP ,或者是 SOAP 等),但是在异步消息处理中却不是这样,只有大企业有一些商业实现(如微软的 MSMQ ,IBM 的 Websphere MQ 等),因此,在 2006 年的 6 月,Cisco 、Redhat、iMatix 等联合制定了 AMQP 的公开标准。
RabbitMQ是由RabbitMQ Technologies Ltd开发并且提供商业支持的。该公司在2010年4月被SpringSource(VMWare的一个部门)收购。在2013年5月被并入Pivotal。其实VMWare,Pivotal和EMC本质上是一家的。不同的是VMWare是独立上市子公司,而Pivotal是整合了EMC的某些资源,现在并没有上市。
RabbitMQ的官网是http://www.rabbitmq.com
2. 应用场景
言归正传。RabbitMQ,或者说AMQP解决了什么问题,或者说它的应用场景是什么?
对于一个大型的软件系统来说,它会有很多的组件或者说模块或者说子系统或者(subsystem or Component or submodule)。那么这些模块的如何通信?这和传统的IPC有很大的区别。传统的IPC很多都是在单一系统上的,模块耦合性很大,不适合扩展(Scalability);如果使用socket那么不同的模块的确可以部署到不同的机器上,但是还是有很多问题需要解决。比如:
1)信息的发送者和接收者如何维持这个连接,如果一方的连接中断,这期间的数据如何方式丢失?
2)如何降低发送者和接收者的耦合度?
3)如何让Priority高的接收者先接到数据?
4)如何做到load balance?有效均衡接收者的负载?
5)如何有效的将数据发送到相关的接收者?也就是说将接收者subscribe 不同的数据,如何做有效的filter。
6)如何做到可扩展,甚至将这个通信模块发到cluster上?
7)如何保证接收者接收到了完整,正确的数据?
AMDQ协议解决了以上的问题,而RabbitMQ实现了AMQP。
3. 系统架构
成为系统架构可能不太合适,可能叫应用场景的系统架构更合适。

这个系统架构图版权属于sunjun041640。
RabbitMQ Server: 也叫broker server,它不是运送食物的卡车,而是一种传输服务。原话是RabbitMQisn’t a food truck, it’s a delivery service. 他的角色就是维护一条从Producer到Consumer的路线,保证数据能够按照指定的方式进行传输。但是这个保证也不是100%的保证,但是对于普通的应用来说这已经足够了。当然对于商业系统来说,可以再做一层数据一致性的guard,就可以彻底保证系统的一致性了。
Client A & B: 也叫Producer,数据的发送方。createmessages and publish (send) them to a broker server (RabbitMQ).一个Message有两个部分:payload(有效载荷)和label(标签)。payload顾名思义就是传输的数据。label是exchange的名字或者说是一个tag,它描述了payload,而且RabbitMQ也是通过这个label来决定把这个Message发给哪个Consumer。AMQP仅仅描述了label,而RabbitMQ决定了如何使用这个label的规则。
Client 1,2,3:也叫Consumer,数据的接收方。Consumersattach to a broker server (RabbitMQ) and subscribe to a queue。把queue比作是一个有名字的邮箱。当有Message到达某个邮箱后,RabbitMQ把它发送给它的某个订阅者即Consumer。当然可能会把同一个Message发送给很多的Consumer。在这个Message中,只有payload,label已经被删掉了。对于Consumer来说,它是不知道谁发送的这个信息的。就是协议本身不支持。但是当然了如果Producer发送的payload包含了Producer的信息就另当别论了。
对于一个数据从Producer到Consumer的正确传递,还有三个概念需要明确:exchanges, queues and bindings。
Exchanges are where producers publish their messages.
Queuesare where the messages end up and are received by consumers
Bindings are how the messages get routed from the exchange to particular queues.
还有几个概念是上述图中没有标明的,那就是Connection(连接),Channel(通道,频道)。
Connection: 就是一个TCP的连接。Producer和Consumer都是通过TCP连接到RabbitMQ Server的。以后我们可以看到,程序的起始处就是建立这个TCP连接。
Channels: 虚拟连接。它建立在上述的TCP连接中。数据流动都是在Channel中进行的。也就是说,一般情况是程序起始建立TCP连接,第二步就是建立这个Channel。
那么,为什么使用Channel,而不是直接使用TCP连接?
对于OS来说,建立和关闭TCP连接是有代价的,频繁的建立关闭TCP连接对于系统的性能有很大的影响,而且TCP的连接数也有限制,这也限制了系统处理高并发的能力。但是,在TCP连接中建立Channel是没有上述代价的。对于Producer或者Consumer来说,可以并发的使用多个Channel进行Publish或者Receive。有实验表明,1s的数据可以Publish10K的数据包。当然对于不同的硬件环境,不同的数据包大小这个数据肯定不一样,但是我只想说明,对于普通的Consumer或者Producer来说,这已经足够了。如果不够用,你考虑的应该是如何细化split你的设计。
4. 进一步的细节阐明
4.1 使用ack确认Message的正确传递
默认情况下,如果Message 已经被某个Consumer正确的接收到了,那么该Message就会被从queue中移除。当然也可以让同一个Message发送到很多的Consumer。
如果一个queue没被任何的Consumer Subscribe(订阅),那么,如果这个queue有数据到达,那么这个数据会被cache,不会被丢弃。当有Consumer时,这个数据会被立即发送到这个Consumer,这个数据被Consumer正确收到时,这个数据就被从queue中删除。
那么什么是正确收到呢?通过ack。每个Message都要被acknowledged(确认,ack)。我们可以显示的在程序中去ack,也可以自动的ack。如果有数据没有被ack,那么:
RabbitMQ Server会把这个信息发送到下一个Consumer。
如果这个app有bug,忘记了ack,那么RabbitMQ Server不会再发送数据给它,因为Server认为这个Consumer处理能力有限。
而且ack的机制可以起到限流的作用(Benefitto throttling):在Consumer处理完成数据后发送ack,甚至在额外的延时后发送ack,将有效的balance Consumer的load。
当然对于实际的例子,比如我们可能会对某些数据进行merge,比如merge 4s内的数据,然后sleep 4s后再获取数据。特别是在监听系统的state,我们不希望所有的state实时的传递上去,而是希望有一定的延时。这样可以减少某些IO,而且终端用户也不会感觉到。
4.2 Reject a message
有两种方式,第一种的Reject可以让RabbitMQ Server将该Message 发送到下一个Consumer。第二种是从queue中立即删除该Message。
4.3 Creating a queue
Consumer和Procuder都可以通过 queue.declare 创建queue。对于某个Channel来说,Consumer不能declare一个queue,却订阅其他的queue。当然也可以创建私有的queue。这样只有app本身才可以使用这个queue。queue也可以自动删除,被标为auto-delete的queue在最后一个Consumer unsubscribe后就会被自动删除。那么如果是创建一个已经存在的queue呢?那么不会有任何的影响。需要注意的是没有任何的影响,也就是说第二次创建如果参数和第一次不一样,那么该操作虽然成功,但是queue的属性并不会被修改。
那么谁应该负责创建这个queue呢?是Consumer,还是Producer?
如果queue不存在,当然Consumer不会得到任何的Message。但是如果queue不存在,那么Producer Publish的Message会被丢弃。所以,还是为了数据不丢失,Consumer和Producer都try to create the queue!反正不管怎么样,这个接口都不会出问题。
queue对load balance的处理是完美的。对于多个Consumer来说,RabbitMQ 使用循环的方式(round-robin)的方式均衡的发送给不同的Consumer。
4.4 Exchanges
从架构图可以看出,Procuder Publish的Message进入了Exchange。接着通过“routing keys”, RabbitMQ会找到应该把这个Message放到哪个queue里。queue也是通过这个routing keys来做的绑定。
有三种类型的Exchanges:direct, fanout,topic。 每个实现了不同的路由算法(routing algorithm)。
· Direct exchange: 如果 routing key 匹配, 那么Message就会被传递到相应的queue中。其实在queue创建时,它会自动的以queue的名字作为routing key来绑定那个exchange。
· Fanout exchange: 会向响应的queue广播。
· Topic exchange: 对key进行模式匹配,比如ab*可以传递到所有ab*的queue。
4.5 Virtual hosts
每个virtual host本质上都是一个RabbitMQ Server,拥有它自己的queue,exchagne,和bings rule等等。这保证了你可以在多个不同的application中使用RabbitMQ。
接下来我会使用Python来说明RabbitMQ的使用方法。
以上是关于rabbitMQ的详细介绍的主要内容,如果未能解决你的问题,请参考以下文章