pandas索引取数
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas索引取数相关的知识,希望对你有一定的参考价值。
参考技术A 注:《利用python进行数据分析》的学习笔记-pandasimport pandas as pd
import numpy as np
一维数组,包含一个数组对象,一个索引对象,索引对象默认为0开始的递增数字,可通过index=[idx1, idx2, ...]参数指定
可通过索引选取/修改相应的数据,选取:data=series[idx], 修改:series[[idxm, idxn, ...]]=[dm, dn, ...]
series可看成定长有序字典,索引到数据的映射,series可用于字典参数的函数中。idxn in series返回True/False
多个series做算术操作,会自动对齐不同索引的数据,无此数据自动填充NaN
可看作多个series组成的表单,dataframe有两种索引,与series相同的index行索引,还有columns列索引
选取/修改一行数据 dataframe.loc['index']
选取/修改一列数据 dataframe['column'], dataframe.column
obj.reindex(newIndex) #适用于series与dataframe
obj.reindex(index=newIndex, columns=newcolumns) #dataframe需对行索引列索引都重新索引时
obj.reindex(index=newindex, columns=newcolumns, fill_value=100) #指定填充值,不指定时填充NaN
obj.reindex(index=newindex, columns=newcolumns, fill_value=100, method='ffill') #指定填充方法ffill/pad(前向填充),bfill/backfill(后向填充)
obj=obj.drop(index, axis=0)
obj=obj.drop([col1, col2, ...], axis=1)
axis默认为0,删除列数据时指定axis为1
series
obj = pd.Series(range(5), index=list('abcde'))
取单数 obj[2], obj['c']
切片取数 obj[2:5], obj['a':'c']
不连续取数 obj[1,3], obj['a','c','d']
过滤 obj[obj>2],
修改 obj[3]=0,
注:series切片不用于python数据结构的切片,series的切片包含末端,即python:[start, end), series:[start, end]
dataframe
obj = pd.DataFrame(np.arange(15).reshape((3,5)),
index = ['one', 'two', 'three'],
columns = list('abcde') )
取单列 obj.loc[:, 'c'], obj.iloc[:, 2], obj.xs('c', axis=1), obj['c'],
取单行 obj.loc['one'], obj.iloc[1], obj.xs('one', axis=0),
取连续行 obj.loc['one':'three'], obj.iloc[1:3], obj[:2],
取连续列 obj.loc[:, 'b':'d'], obj.iloc[:, 2:4],
取不连续行 obj.loc[['one','three']] obj.iloc[[0,2]],
取不连续列 obj.loc[:, ['b', 'e']] obj.iloc[:, [1,4]],
取单行单列 obj.loc['two', 'd'] obj.iloc[2, 4]
取连续行列 obj.loc['one':'three', 'b':'d'] obj.iloc[:2, 2:4]
取不连续行列 obj.loc[['one','three'], ['b':'d']] obj.iloc[[0,2], [1,4]]
根据列值过滤行 obj.loc[obj['c']%2==0, :]
******此处吐个槽,这个切片方法一会儿只能取单列,一会儿只能取连续行,一会儿包含终止项,一会儿不包含,我人都傻了...
******loc/iloc方法接收两个参数,第一个是行,第二个是列,都可切片,也都可指定索引,列参数可以不写,默认取所有列数据
******下面总结下这个花哨的切片!
dataframe有两种索引,行索引/列索引。每种索引包含两类用法,索引名称(对应df.loc)/索引下标对应(df.iloc)
① df[columnName] 取单列数据,只能用列名,不能使用列下标,不能用于取单行
② df[lineName1: lineName2] 取连续行数据,使用行名时,包含末尾项,即[start,end]
③ df[lineIndex1: lineIndex2] 取连续行数据,使用行下标时,不包含末尾项 ,即[start,end)
④ df.loc['line2':'line4'] 取连续行数据,使用行名时,包含末尾项,即[start,end]
⑤ df.iloc[2:4] 取连续行数据,使用行下标时,不包含末尾项 ,即[start,end)
⑥ df.loc[:, columnName1:columnName2] 取连续列,使用列名时,包含末尾项,即[start,end]
⑦ df.iloc[:, columnIndex1:columnIndex2] 取连续列,使用列下标时,不包含末尾项,即[start,end)
⑧ df.loc[[lineName1, ...], [columnName1, ...]] 使用行名/列名取不连续行列
⑨ df.iloc[[lineIndex1, ...], [columnIndex1, ...]] 使用行下标/列下标取不连续行列
以前用的时候总觉得奇奇怪怪的,花了一下午时间一个一个尝试终于捋顺了,欧耶! (〃 ̄︶ ̄) 人 ( ̄︶ ̄〃)
DataFrame直接切片,即df[args],可用于指定列名取单列数据,可用于指定行名/行下标取连续多行数据
取单行数据不可直接切片,需使用loc/iloc方法
DataFrame.loc(line, column) 用于按索引名称取行/列数据,此时,首尾项都会被取出
参数line指定行索引名称,参数2指定列索引名称(可省略,默认选取所有列)。
DataFrame.iloc(line, column) 用于按索引下标取行/列数据,此时,尾项数据不会被取出
参数line指定行索引下标,参数2指定列索引下标(可省略,默认选取所有列)。
pandas花样取数_中
公众号:尤而小屋
作者:Peter
编辑:Peter
大家好,我是Peter~
今天继续带来Pandas的花样取数技巧,本文中重点介绍的方法:
- 表达式取数
- query、evel
- filter
- where、mask

扩展阅读
关于pandas的连载文章,请阅读:
模拟数据
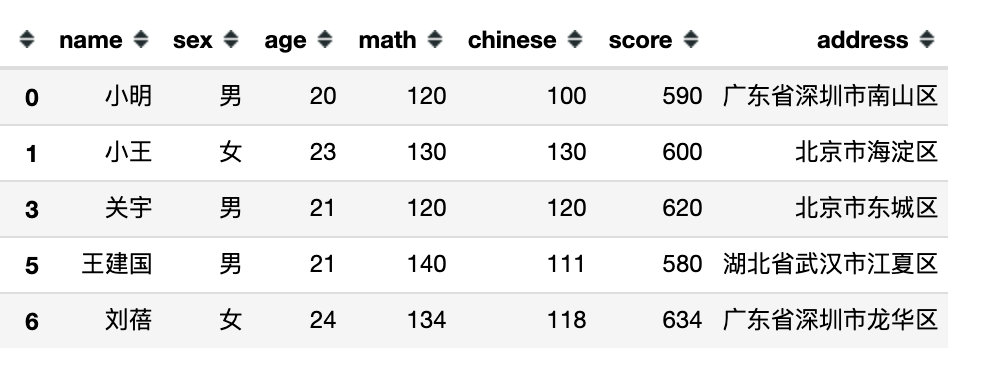
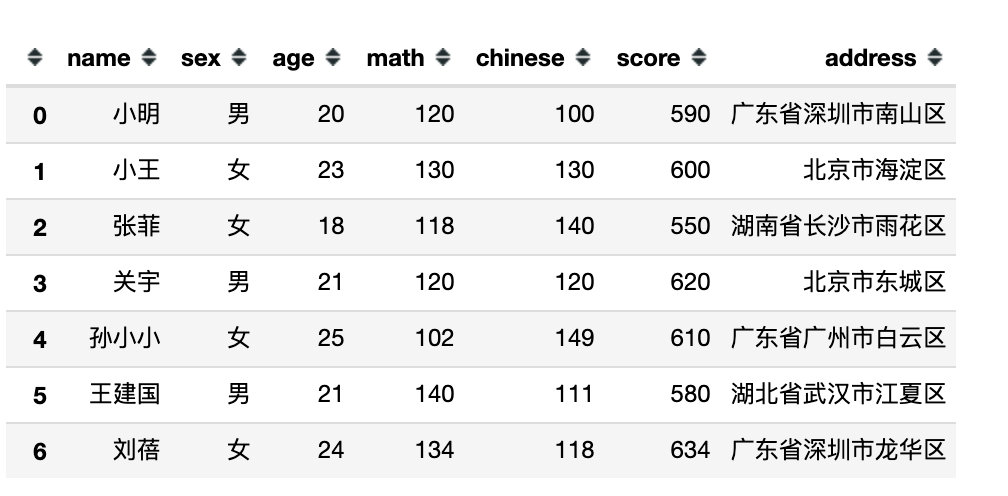
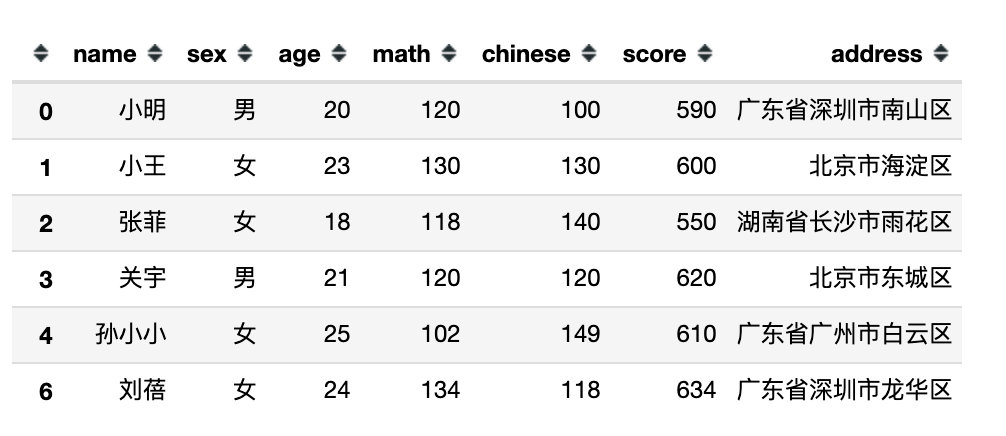
下面是完全模拟的一份数据,包含:姓名、性别、年龄、数学、语文、总分、地址共7个字段信息。
import pandas as pd
import numpy as np
df = pd.DataFrame({
"name":['小明','小王','张菲','关宇','孙小小','王建国','刘蓓'],
"sex":['男','女','女','男','女','男','女'],
"age":[20,23,18,21,25,21,24],
"math":[120,130,118,120,102,140,134],
"chinese":[100,130,140,120,149,111,118],
"score":[590,600,550,620,610,580,634],
"address":["广东省深圳市南山区",
"北京市海淀区",
"湖南省长沙市雨花区",
"北京市东城区",
"广东省广州市白云区",
"湖北省武汉市江夏区",
"广东省深圳市龙华区"
]
})
df

下面开始详细介绍5种取数方法:
- 表达式取数
- query()取数
- eval()取数
- filter()取数
- where/mask取数
表达式取数
表达式取数指的是通过表达式来指定一个或者多个筛选条件来取数。
1、指定一个数学表达式
# 1、数学表达式
df[df['math'] > 125]
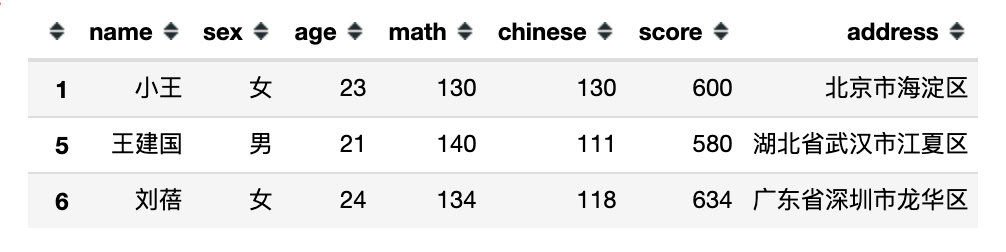
2、取反操作
取反操作是通过符号~来实现的
# 2、取反操作
df[~(df['sex'] == '男')] # 取出不是男生的数据
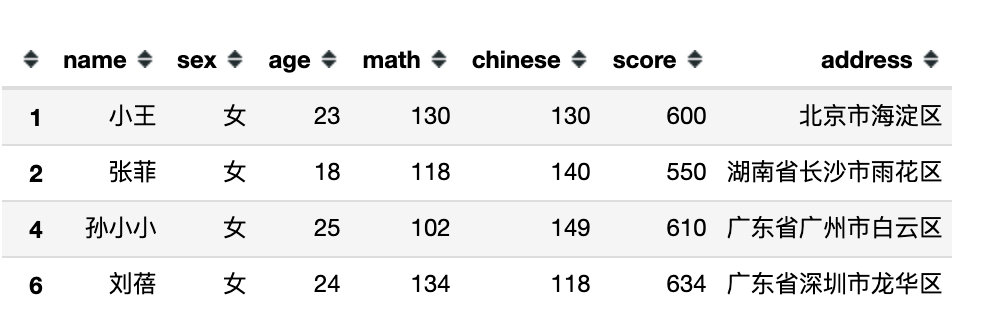
3、指定某个属性的值为具体的数据
# 3、指定具体数据
df[df.sex == '男'] # 等同于 df[df['sex'] == '男']
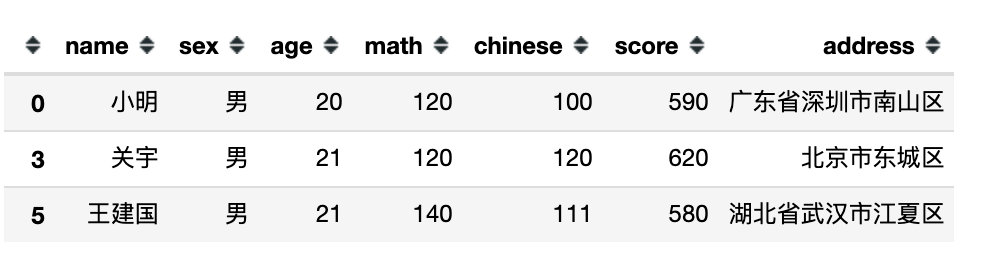
4、不等式表达式
# 4、比较表达式
df[df['math'] > df['chinese']]
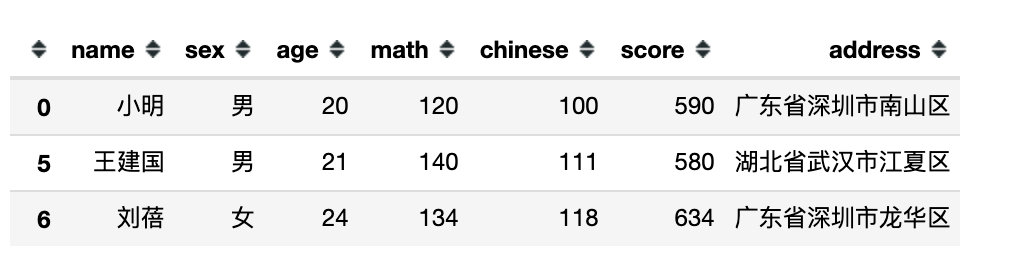
5、逻辑运算符
# 5、逻辑运算符
df[(df['math'] > 120) & (df['chinese'] < 140)]
query()函数
使用说明

⚠️在使用的时候需要注意的是:如果我们列属性中存在空格,我们需要使用反引号将其括起来再进行使用。
使用案例
1、使用数值型表达式
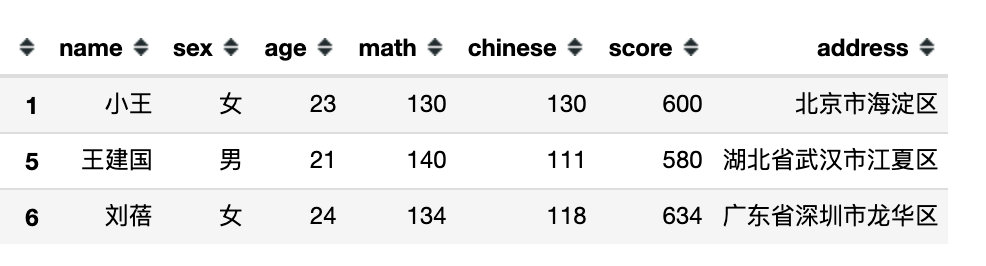
df.query('math > chinese > 110')
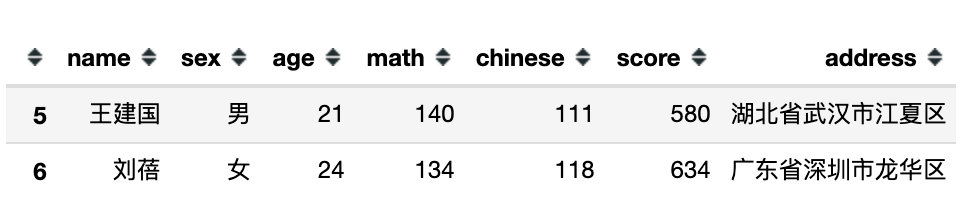
df.query('math + chinese > 255')
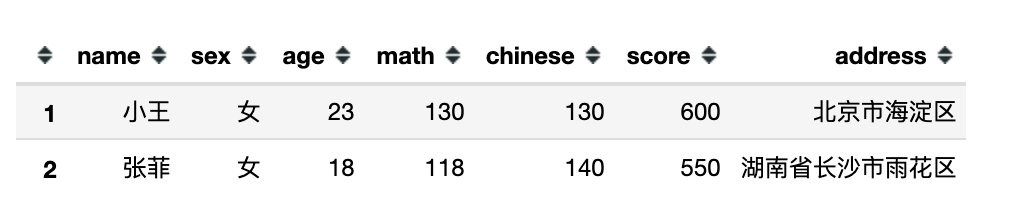
df.query('math == chinese')

df.query('math == chinese > 120')

df.query('(math > 110) and (chinese < 135)') # 两个不等式
2、使用字符型表达式
df.query('sex != "女"') # 不等于女,就是全部男
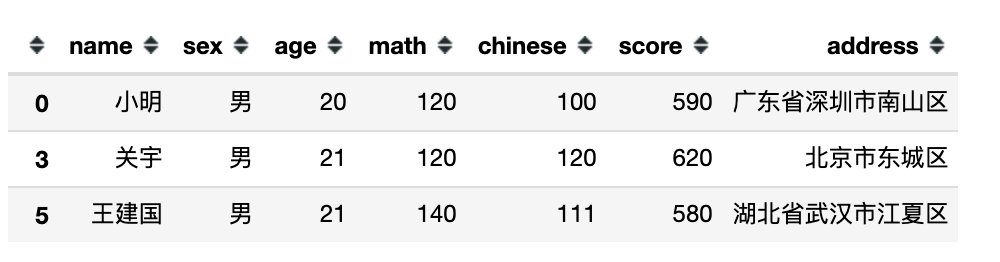
df.query('sex not in ("女")') # 不在女中就是男
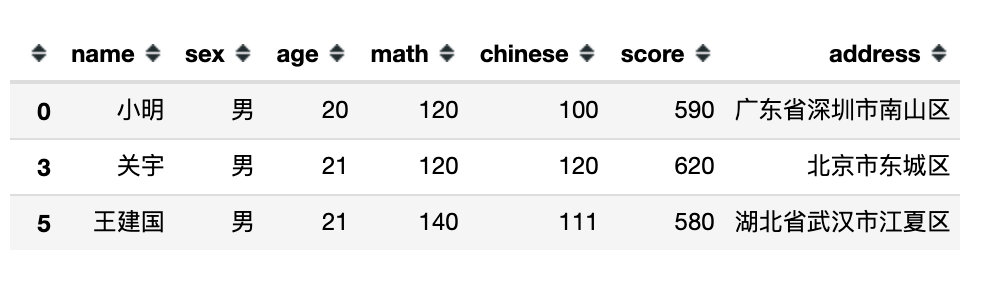
df.query('sex in ("男","女")') # 性别在男女中就是全部人
3、传入变量;变量在使用的时候需要在前面加上@
# 设置变量
a = df.math.mean()
a
df.query('math > @a + 10')
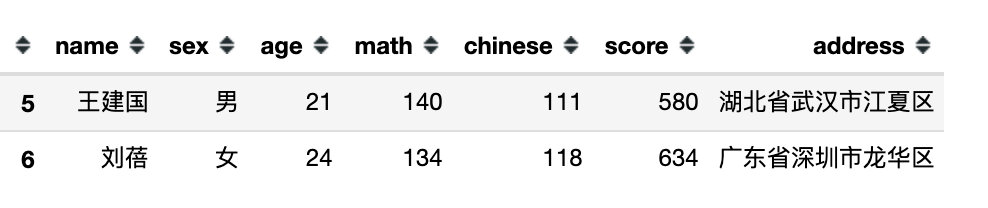
df.query('math < (`chinese` + @a) / 2')
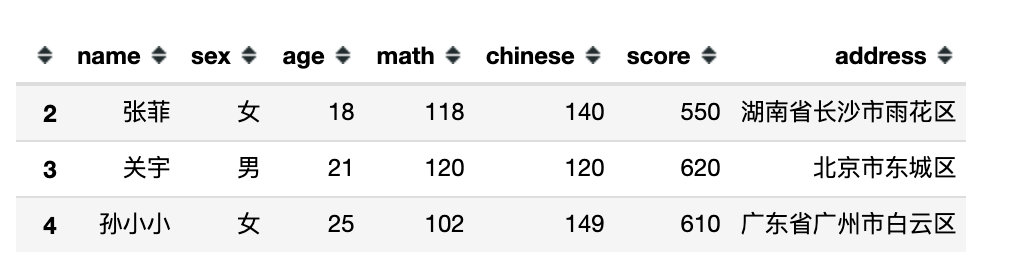
eval()函数
eval函数的使用方法和query函数是相同的
1、使用数值型表达式
# 1、数值型表达式
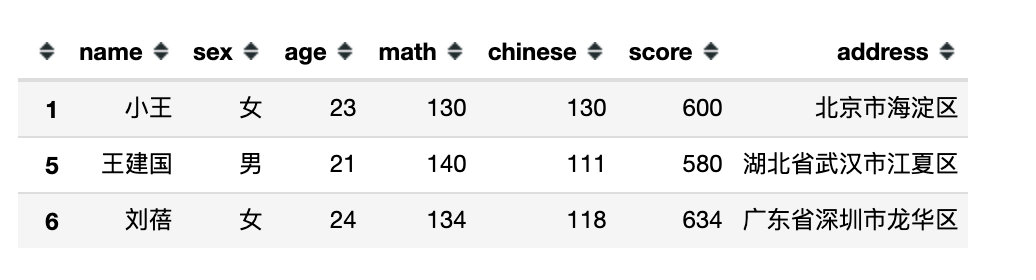
df.eval('math > 125') # 得到的是bool表达式

df[df.eval('math > 125')]
df[df.eval('math > 125 and chinese < 130')]
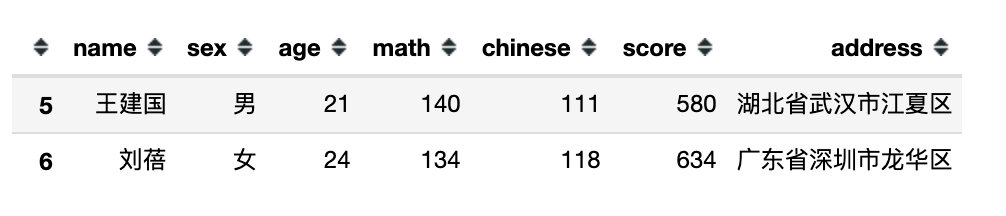
2、字符型表达式
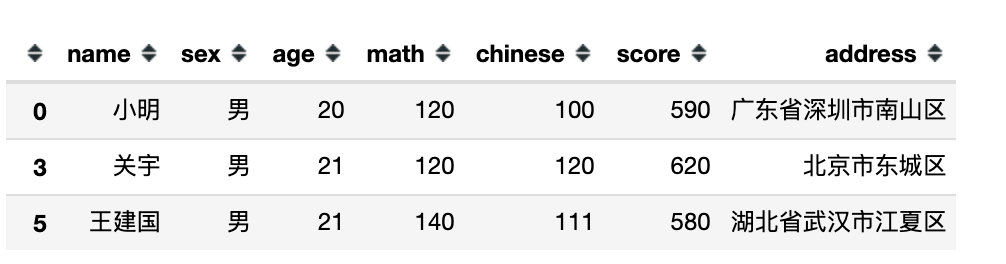
# 2、字符型表达式
df[df.eval('sex in ("男")')]
3、使用变量
# 3、使用变量
b = df.chinese.mean() # 求均值
df[df.eval('math < @b+5')]
filter函数
我们使用filter可以对列名或者行名进行筛选,使用方法:
- 直接指定
- 正则指定
- 模糊指定
其中axis=1指定列名;axis=0指定索引
使用说明

使用案例
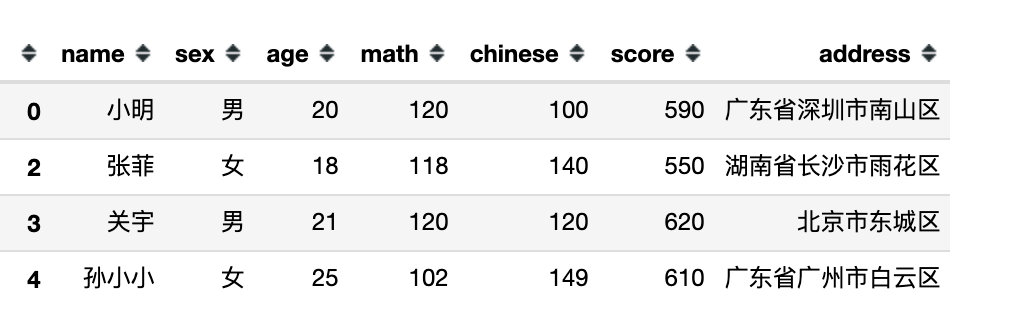
1、直接指定属性名
df.filter(items=["chinese","score"]) # 列名操作
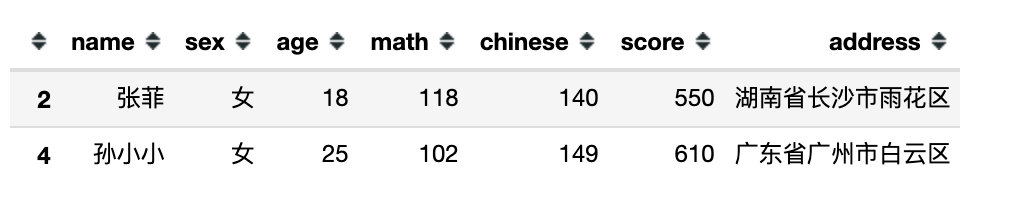
直接指定行索引
df.filter(items=[2,4],axis=0) # 行筛选
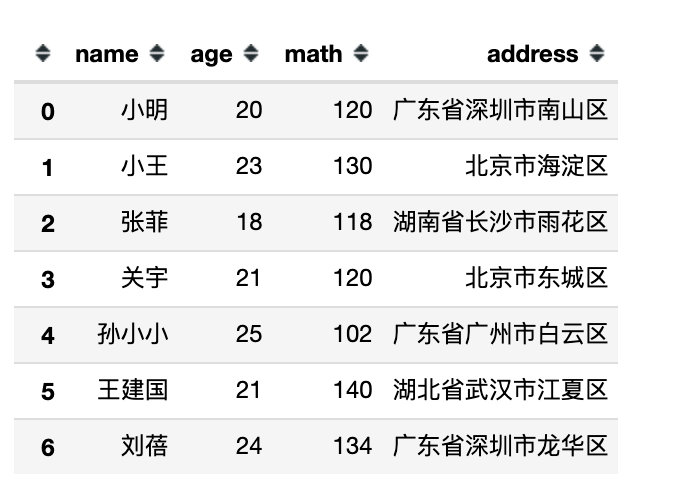
2、通过正则指定
df.filter(regex='a',axis=1) # 列名中包含
df.filter(regex='^s',axis=1) # 列名以s开始
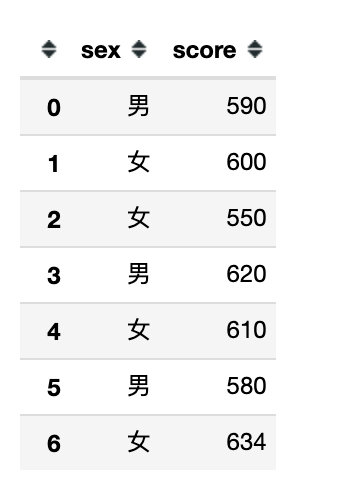
df.filter(regex='e$',axis=1) # 列名以e结束
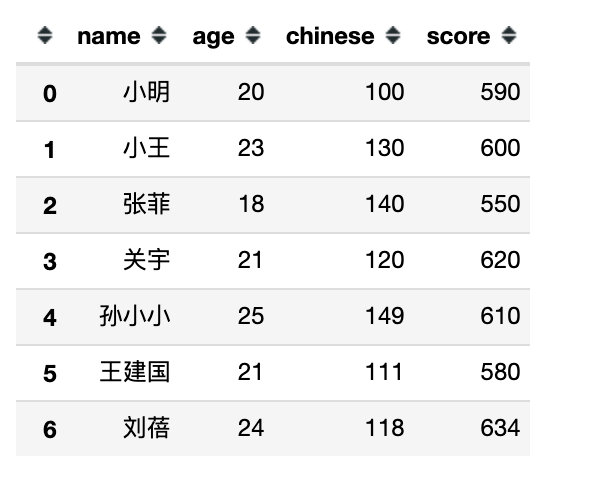
df.filter(regex='3$',axis=0) # 行索引包含3

3、模糊指定
df.filter(like='s',axis=1) # 列名中包含s
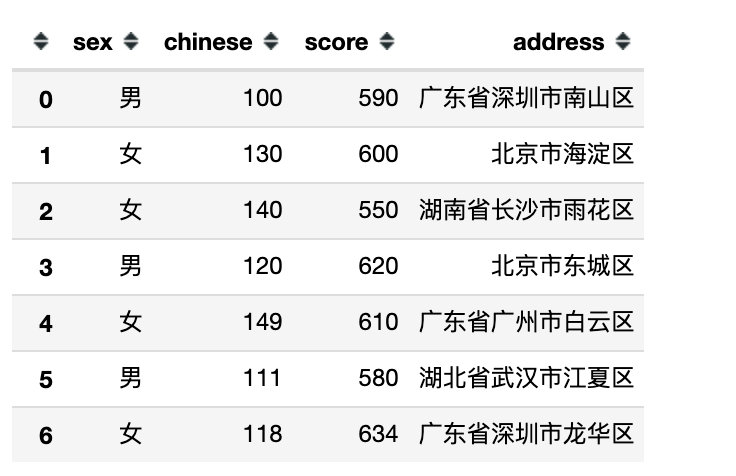
df.filter(like='2',axis=0) # 行索引包含2

# 同时指定列名和索引
df.filter(regex='^a',axis=1).filter(like='2',axis=0)

where和mask函数
where和mask函数是一对相反的函数,取出来的结果刚好是相反的:
- where:取出满足要求的数据,不满足的显示为NaN
- mask:取出不满足要求的数据,满足的显示为NaN
两种方法都可以将将NaN值设置我们指定的数据
where使用
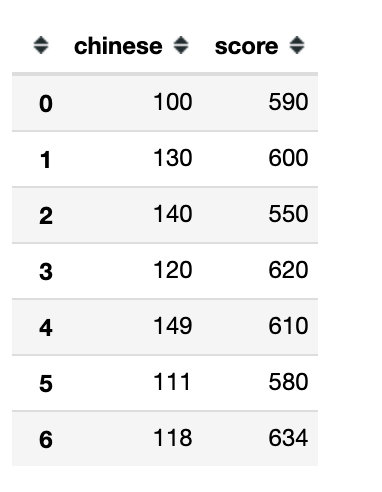
s = df["score"]
s
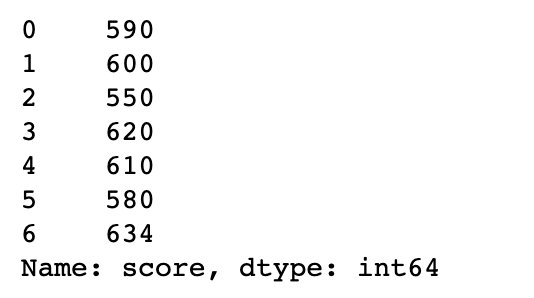
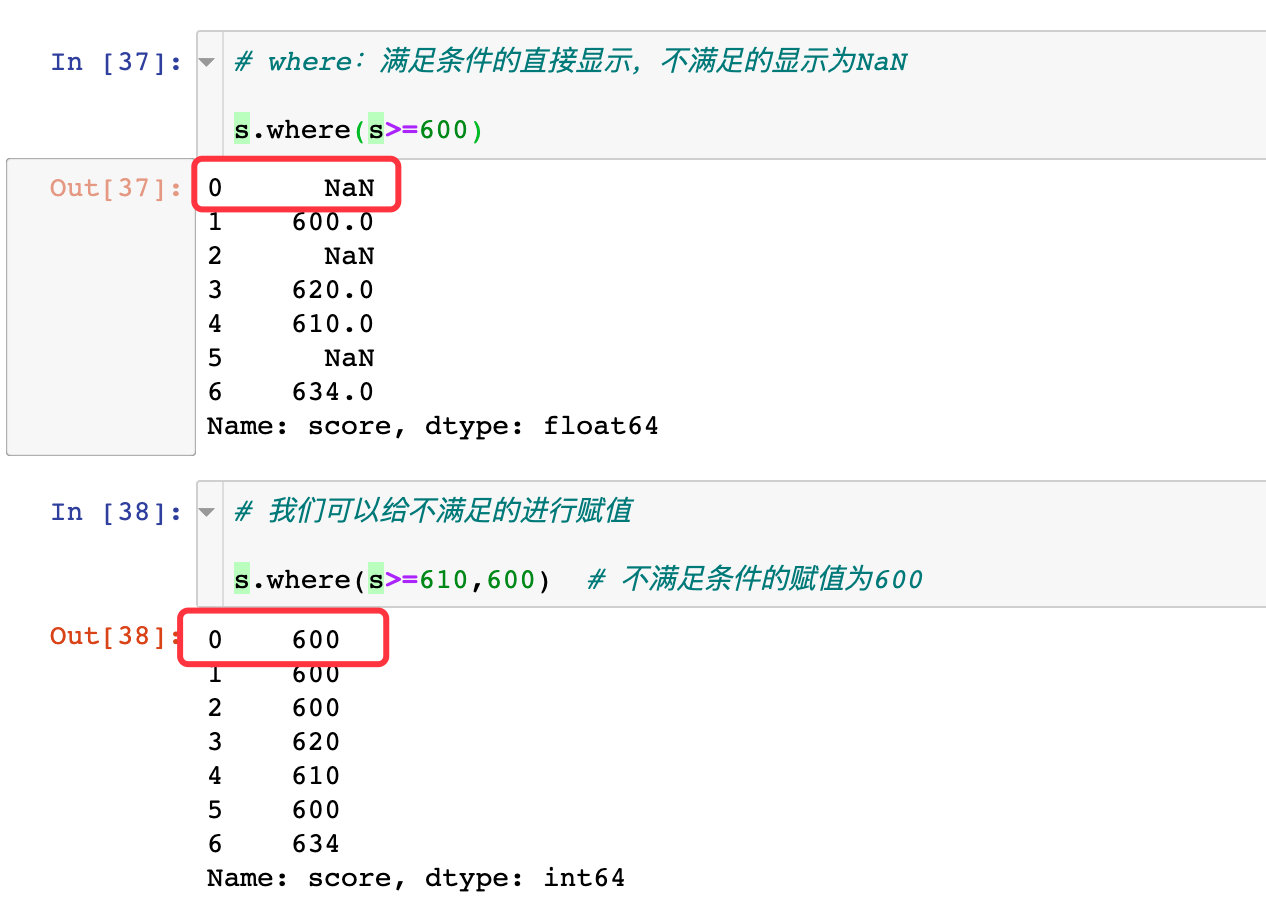
# where:满足条件的直接显示,不满足的显示为NaN
s.where(s>=600)

我们可以给不满足要求的数据进行赋值:
# 我们可以给不满足的进行赋值
s.where(s>=610,600) # 不满足条件的赋值为600

看看两组结果的对比:
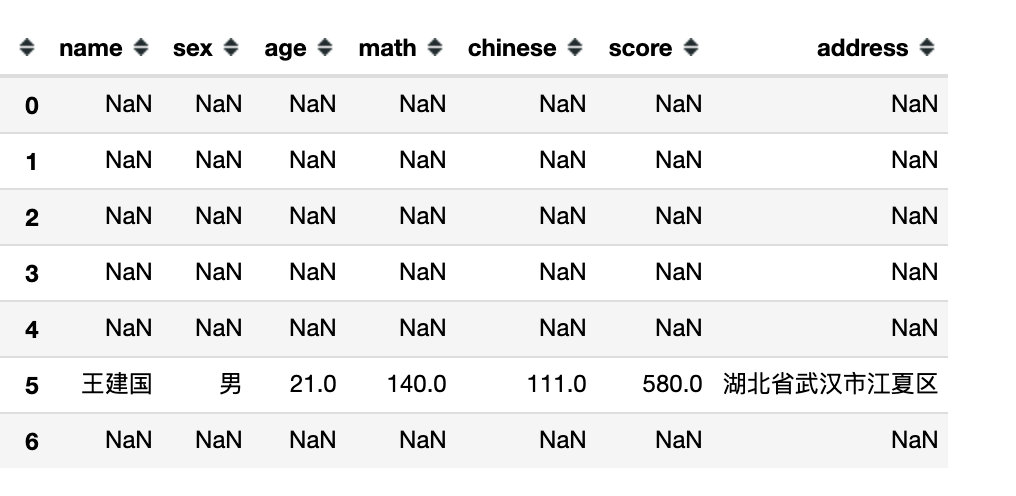
where函数还可以指定多个条件:
# 符合条件的返回True,不符合的返回False
df.where((df.sex=='男') & (df.math > 125))
选出我们想要的数据:
df[(df.where((df.sex=='男') & (df.math > 125)) == df).name]
# df[(df.where((df.sex=='男') & (df.math > 125)) == df).sex] 效果相同

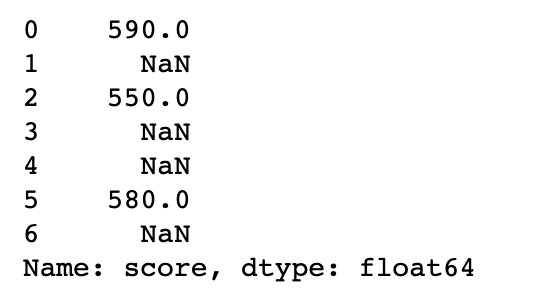
mask函数
mask函数获取到的结果和where是相反的
s.mask(s>=600) # 和where相反:返回的都是小于600的数据
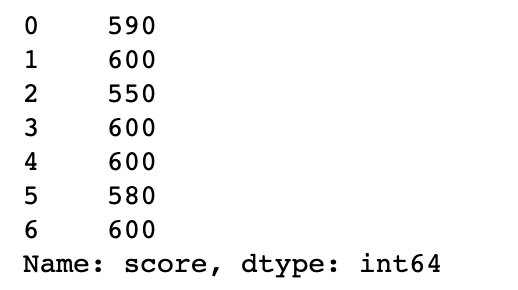
s.mask(s>=610, 600) # 不满足条件的赋值为600
mask函数接受多个条件:
# 取值和where相反
df[(df.mask((df.sex=='男') & (df.math > 125)) == df).sex]
总结
Pandas中取数的方法真的五花八门,太多技巧可以获取到我们想要的数据,有时候不同的方式也可以得到相同的数据。本文中着重介绍的通过表达式和5个函数来取数,下篇文章中将会重点讲解3对函数筛选数据的方法。
以上是关于pandas索引取数的主要内容,如果未能解决你的问题,请参考以下文章
pandas构建复合索引数据(multiple index dataframe)pandas索引复合索引dataframe数据
pandas中dataframe索引排序实战:pandas中dataframe索引降序排序pandas中dataframe索引升序排序