Flink CDC 系列 - Flink MongoDB CDC 在 XTransfer 的生产实践
Posted XTransfer技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink CDC 系列 - Flink MongoDB CDC 在 XTransfer 的生产实践相关的知识,希望对你有一定的参考价值。
前言
XTransfer 专注为跨境 B2B 电商中小企业提供跨境金融和风控服务,通过建立数据化、自动化、互联网化和智能化的风控基础设施,搭建通达全球的财资管理平台,提供开立全球和本地收款账户、外汇兑换、海外外汇管制国家申报等多种跨境金融服务的综合解决方案。
在业务发展早期,我们选择了传统的离线数仓架构,采用全量采集、批量处理、覆盖写入的数据集成方式,数据时效性较差。随着业务的发展,离线数仓越来越不能满足对数据时效性的要求,我们决定从离线数仓向实时数仓进行演进。而建设实时数仓的关键点在于变更数据采集工具和实时计算引擎的选择。
经过了一系列的调研,在 2021 年 2 月份,我们关注到了 Flink CDC 项目,Flink CDC 内嵌了 Debezium,使 Flink 本身具有了变更数据捕获的能力,很大程度上降低了开发门槛,简化了部署复杂度。加上 Flink 强大的实时计算能力和丰富的外部系统接入能力,成为了我们构建实时数仓的关键工具。
另外,我们在生产中也大量使用到了 MongoDB,所以我们在 Flink CDC 基础上通过 MongoDB Change Streams 特性实现了 Flink MongoDB CDC Connector,并贡献给了 Flink CDC 社区,目前已在 2.1 版本中发布。很荣幸在这里能够在这里和大家分享一下实现细节和生产实践。
一、Flink CDC
Dynamic Table (动态表) 是 Flink 的支持流数据的 Table API 和 SQL 的核心概念。流和表具有对偶性,可以将表转换成一个变更流 (changelog stream),也可以回放变更流还原成一张表。
变更流有两种形式:Append Mode 和 Update Mode。Append Mode 只会新增,不会变更和删除,常见的如事件流。Update Mode 可能新增,也可能发生变更和删除,常见的如数据库操作日志。在 Flink 1.11之前,只支持在 Append Mode 上定义动态表。
Flink 1.11 在 FLIP-95 引入了新的 TableSource 和 TableSink,实现了对 Update Mode changelog 的支持。并且在 FLIP-105 中,引入了对 Debezium 和 Canal CDC format 的直接支持。通过实现 ScanTableSource,接收外部系统变更日志 (如数据库的变更日志),将其解释为 Flink 的能够识别的 changlog 并向下流转,便可以支持从变更日志定义动态表。
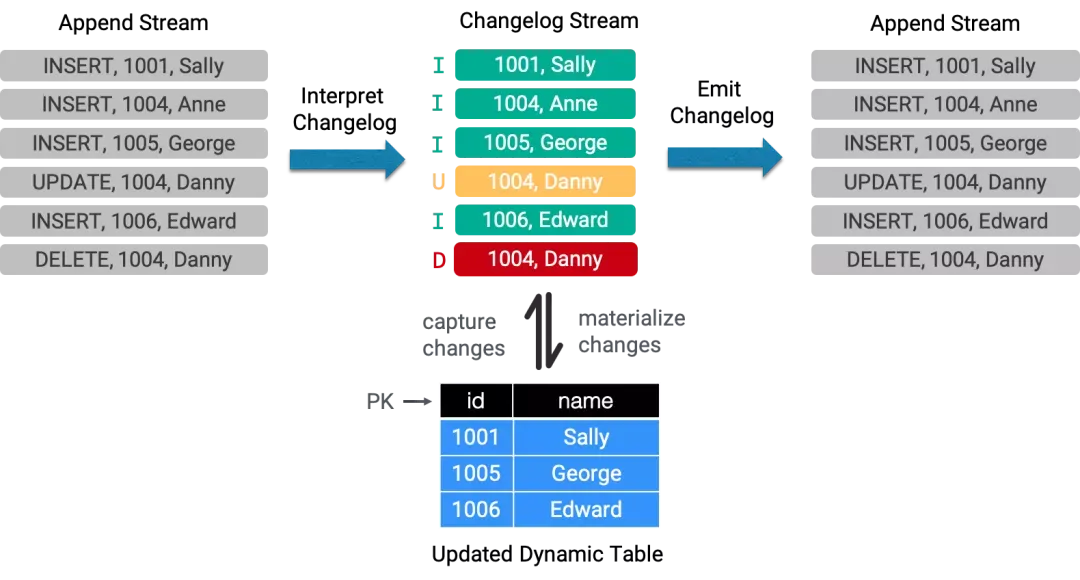
在 Flink 内部,changelog 记录由 RowData 表示,RowData 包括 4 种类型:+I (INSERT), -U (UPDATE_BEFORE),+U (UPDATE_AFTER), -D (DELETE)。根据 changelog 产生记录类型的不同,又可以分为 3 种 changelog mode。
- INSERT_ONLY:只包含 +I,适用于批处理和事件流。
- ALL:包含 +I, -U, +U, -D 全部的 RowKind,如 mysql binlog。
- UPSERT:只包含 +I, +U, -D 三种类型的 RowKind,不包含 -U,但必须按唯一键的幂等更新 , 如 MongoDB Change Streams。
二、MongoDB 复制机制
如上节所述,实现 Flink CDC MongoDB 的关键点在于:如何将 MongoDB 的操作日志转换为 Flink 支持的 changelog。要解决这个问题,首先需要了解一下 MongoDB 的集群部署和复制机制。
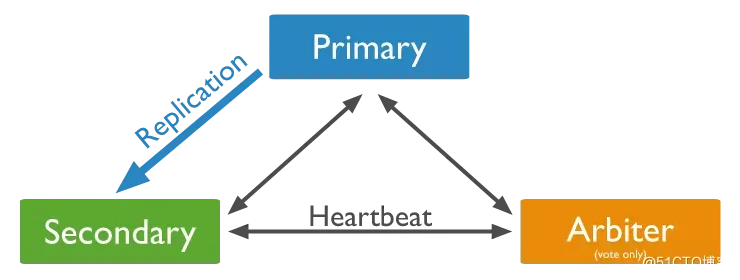
2.1 副本集和分片集群
副本集是 MongoDB 提供的一种高可用的部署模式,副本集成员之间通过 oplog (操作日志) 的复制,来完成副本集成员之间的数据同步。
分片集群是 MongoDB 支持大规模数据集和高吞吐量操作的部署模式,每个分片由一个副本集组成。
2.2 Replica Set Oplog
操作日志 oplog,在 MongoDB 中是一个特殊的 capped collection (固定容量的集合),用来记录数据的操作日志,用于副本集成员之间的同步。oplog 记录的数据结构如下所示。
"ts" : Timestamp(1640190995, 3),
"t" : NumberLong(434),
"h" : NumberLong(3953156019015894279),
"v" : 2,
"op" : "u",
"ns" : "db.firm",
"ui" : UUID("19c72da0-2fa0-40a4-b000-83e038cd2c01"),
"o2" :
"_id" : ObjectId("61c35441418152715fc3fcbc")
,
"wall" : ISODate("2021-12-22T16:36:35.165Z"),
"o" :
"$v" : 1,
"$set" :
"address" : "Shanghai China"
字段 | 是否可空 | 描述 |
ts | N | 操作时间,BsonTimestamp |
t | Y | 对应raft协议里面的term,每次发生节点down掉,新节点加入,主从切换,term都会自增。 |
h | Y | 操作的全局唯一id的hash结果 |
v | N | oplog版本 |
op | N | 操作类型:"i" insert, "u" update, "d" delete, "c" db cmd, "n" no op |
ns | N | 命名空间,表示操作对应的集合全称 |
ui | N | session id |
o2 | Y | 在更新操作中记录_id和sharding key |
wall | N | 操作时间,精确到毫秒 |
o | N | 变更数据描述 |
从示例中可以看出,MongoDB oplog 的更新记录即不包含更新前的信息,也不包含更新后的完整记录,所以即不能转换成 Flink 支持的 ALL 类型的 changelog,也难以转换成 UPSERT 类型的 changelog。
另外,在分片集群中,数据的写入可能发生在不同的分片副本集中,因此每个分片的 oplog 中仅会记录发生在该分片上的数据变更。因此需要获取完整的数据变更,需要将每个分片的 oplog 按照操作时间排序合并到一起,加大了捕获变更记录的难度和风险。
Debezium MongoDB Connector 在 1.7 版本之前是通过遍历 oplog 来实现变更数据捕获,由于上述原因,我们没有采用 Debezium MongoDB Connector 而选择了 MongoDB 官方的基于 Change Streams 的 MongoDB Kafka Connector。
2.3 Change Streams
Change Streams 是 MongoDB 3.6 推出的一个新特性,屏蔽了遍历 oplog 的复杂度,使用户通过简单的 API 就能订阅集群、数据库、集合级别的数据变更。
■ 2.3.1 使用条件
- WiredTiger 存储引擎
- 副本集 (测试环境下,也可以使用单节点的副本集) 或分片集群部署
- 副本集协议版本:pv1 (默认)
- 4.0 版本之前允许 Majority Read Concern: replication.enableMajorityReadConcern = true (默认允许)
- MongoDB 用户拥有 find 和 changeStream 权限
■ 2.3.2 Change Events
Change Events 是 Change Streams 返回的变更记录,其数据结构如下所示:
_id : <BSON Object> ,
"operationType" : "<operation>",
"fullDocument" : <document> ,
"ns" :
"db" : "<database>",
"coll" : "<collection>"
,
"to" :
"db" : "<database>",
"coll" : "<collection>"
,
"documentKey" : "_id" : <value> ,
"updateDescription" :
"updatedFields" : <document> ,
"removedFields" : [ "<field>", ... ],
"truncatedArrays" : [
"field" : <field>, "newSize" : <integer> ,
...
]
,
"clusterTime" : <Timestamp>,
"txnNumber" : <NumberLong>,
"lsid" :
"id" : <UUID>,
"uid" : <BinData>
字段类型描述_iddocument表示resumeTokenoperationTypestring操作类型,包括:insert, delete, replace, update, drop, rename, dropDatabase, invalidatefullDocumentdocument完整文档记录,insert, replace默认包含,update需要开启updateLookup,delete和其他操作类型不包含nsdocument操作记录对应集合的完全名称todocument当操作类型为rename时,to表示重命名后的完全名称documentKeydocument包含变更文档的主键 _id,如果该集合是一个分片集合,documentKey中也会包含分片建updateDescriptiondocument当操作类型为update时,描述有变更的字段和值clusterTimeTimestamp操作时间txnNumberNumberLong事务号lsidDocumentsession id
■ 2.3.3 Update Lookup
由于 oplog 的更新操作仅包含了有变更后的字段,变更后完整的文档无法从 oplog 直接获取,但是在转换为 UPSERT 模式的 changelog 时,UPDATE_AFTER RowData 必须拥有完整行记录。Change Streams 通过设置 fullDocument = updateLookup,可以在获取变更记录时返回该文档的最新状态。另外,Change Event 的每条记录都包含 documentKey (_id 以及 shard key),标识发生变更记录的主键信息,即满足幂等更新的条件。所以通过 Update Lookup 特性,可以将 MongoDB 的变更记录转换成 Flink 的 UPSERT changelog。
三、Flink MongoDB CDC
在具体实现上,我们集成了 MongoDB 官方基于 Change Streams 实现的 MongoDB Kafka Connector。通过 Debezium EmbeddedEngine,可以很容易地在 Flink 中驱动 MongoDB Kafka Connector 运行。通过将 Change Stream 转换成 Flink UPSERT changelog,实现了 MongoDB CDC TableSource。配合 Change Streams 的 resume 机制,实现了从 checkpoint、savepoint 恢复的功能。
如 FLIP-149 所述,一些运算 (如聚合) 在缺失 -U 消息时难以正确处理。对于 UPSERT 类型的 changelog,Flink Planner 会引入额外的计算节点 (Changelog Normalize) 来将其标准化为 ALL 类型的 changelog。
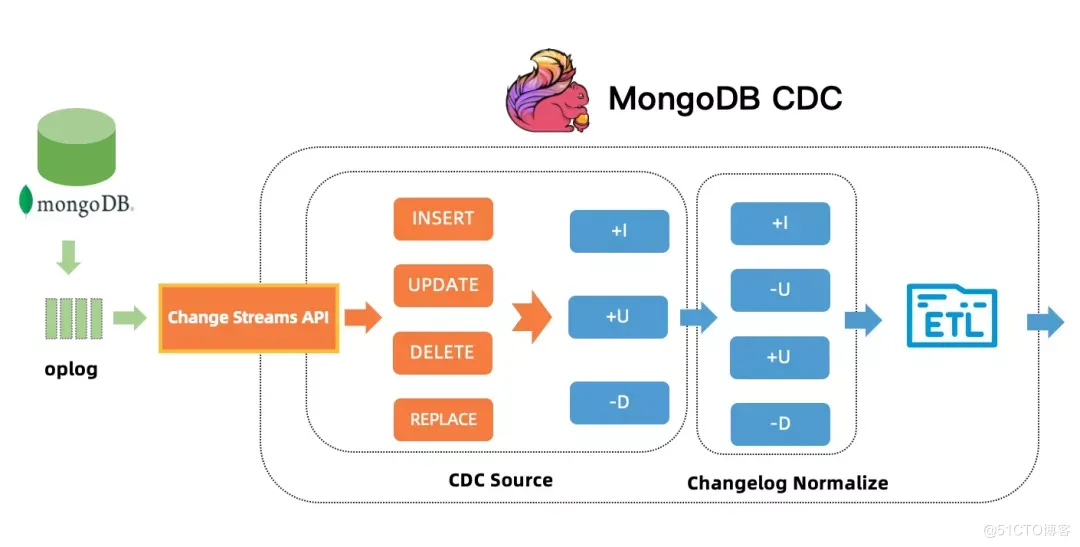
支持特性
- 支持 Exactly-Once 语义
- 支持全量、增量订阅
- 支持 Snapshot 数据过滤
- 支持从检查点、保存点恢复
- 支持元数据提取
四、生产实践
4.1 使用 RocksDB State Backend
Changelog Normalize 为了补齐 -U 的前置镜像值,会带来额外的状态开销,在生产环境中推荐使用 RocksDB State Backend。
4.2 合适的 oplog 容量和过期时间
MongoDB oplog.rs 是一个特殊的有容量集合,当 oplog.rs 容量达到最大值时,会丢弃历史的数据。Change Streams 通过 resume token 进行恢复,太小的 oplog 容量可能导致 resume token 对应的 oplog 记录不再存在,因而导致恢复失败。
在没有显示指定 oplog 容量时,WiredTiger 引擎的 oplog 默认容量为磁盘大小的 5%,下限为 990MB,上限为 50GB。在 MongoDB 4.4 之后,支持设置 oplog 最短保留时间,在 oplog 已满并且 oplog 记录超过最短保留时间时,才会对该 oplog 记录进行回收。
可以使用 replSetResizeOplog 命令重新设置 oplog 容量和最短保留时间。在生产环境下,建议设置 oplog 容量不小于 20GB,oplog 保留时间不少于 7 天。
db.adminCommand(
replSetResizeOplog: 1, // 固定值1
size: 20480, // 单位为MB,范围在990MB到1PB
minRetentionHours: 168 // 可选项,单位为小时
)
4.3 变更慢的表开启心跳事件
Flink MongoDB CDC 会定期将 resume token 写入 checkpoint 对 Change Stream 进行恢复,MongoDB 变更事件或者心跳事件都能触发 resume token 的更新。如果订阅的集合变更缓慢,可能造成最后一条变更记录对应的 resume token 过期,从而无法从 checkpoint 进行恢复。因此对于变更缓慢的集合,建议开启心跳事件 (设置 heartbeat.interval.ms > 0),来维持 resume token 的更新。
WITH (
connector = mongodb-cdc,
heartbeat.interval.ms = 60000
)
4.4 自定义 MongoDB 连接参数
当默认连接无法满足使用要求时,可以通过 connection.options 配置项传递 MongoDB 支持的连接参数。https://docs.mongodb.com/manual/reference/connection-string/#connection-string-options
WITH (
connector = mongodb-cdc,
connection.options = authSource=authDB&maxPoolSize=3
)
4.5 Change Stream 参数调优
可以在 Flink DDL 中通过 poll.await.time.ms 和 poll.max.batch.size 精细化配置变更事件的拉取。
- poll.await.time.ms
变更事件拉取时间间隔,默认为 1500ms。对于变更频繁的集合,可以适当调小拉取间隔,提升处理时效;对于变更缓慢的集合,可以适当调大拉取时间间隔,减轻数据库压力。
- poll.max.batch.size
每一批次拉取变更事件的最大条数,默认为 1000 条。调大改参数会加快从 Cursor 中拉取变更事件的速度,但会提升内存的开销。
4.6 订阅整库、集群变更
database = "db",collection = "",可以订阅 db 整库的变更;database = "",collection = "",可以订阅整个集群的变更。
DataStream API 可以使用 pipeline 可以过滤需要订阅的 db 和 collection,对于 Snapshot 集合的过滤目前还不支持。
MongoDBSource.<String>builder()
.hosts("127.0.0.1:27017")
.database("")
.collection("")
.pipeline("[$match: ns.db: $regex: /^(sandbox|firewall)$/]")
.deserializer(new JsonDebeziumDeserializationSchema())
.build();
4.7 权限控制
MongoDB 支持对用户、角色、权限进行细粒度的管控,开启 Change Stream 的用户需要拥有 find 和 changeStream 两个权限。
- 单集合
resource: db: <dbname>, collection: <collection> , actions: [ "find", "changeStream" ]
- 单库
resource: db: <dbname>, collection: "" , actions: [ "find", "changeStream" ]
- 集群
resource: db: "", collection: "" , actions: [ "find", "changeStream" ]
在生产环境下,建议创建 Flink 用户和角色,并对该角色进行细粒度的授权。需要注意的是,MongoDB 可以在任何 database 下创建用户和角色,如果用户不是创建在 admin 下,需要在连接参数中指定 authSource =< 用户所在的 database>。
use admin;
// 创建用户
db.createUser(
user: "flink",
pwd: "flinkpw",
roles: []
);
// 创建角色
db.createRole(
role: "flink_role",
privileges: [
resource: db: "inventory", collection: "products" , actions: [ "find", "changeStream" ]
],
roles: []
);
// 给用户授予角色
db.grantRolesToUser(
"flink",
[
// 注意:这里的db指角色创建时的db,在admin下创建的角色可以包含不同database的访问权限
role: "flink_role", db: "admin"
]
);
// 给角色追加权限
db.grantPrivilegesToRole(
"flink_role",
[
resource: db: "inventory", collection: "orders" , actions: [ "find", "changeStream" ]
]
);
在开发环境和测试环境下,可以授予 read 和 readAnyDatabase 两个内置角色给 Flink 用户,即可对任意集合开启 change stream。
use admin;
db.createUser(
user: "flink",
pwd: "flinkpw",
roles: [
role: "read", db: "admin" ,
role: "readAnyDatabase", db: "admin"
]
);
五、后续规划
- 支持增量 Snapshot
目前,MongoDB CDC Connector 还不支持增量 Snapshot,对于数据量较大的表还不能很好发挥 Flink 并行计算的优势。后续将实现 MongoDB 的增量 Snapshot 功能,使其支持 Snapshot 阶段的 checkpoint,和并发度设置。
- 支持从指定时间进行变更订阅
目前,MongoDB CDC Connector 仅支持从当前时间开始 Change Stream 的订阅,后续将提供从指定时间点的 Change Stream 订阅。
- 支持库和集合的筛选
目前,MongoDB CDC Connector 支持集群、整库的变更订阅和筛选,但对于是否需要进行 Snapshot 的集合的筛选还不支持,后续将完善这个功能。
参考文档
[1] Duality of Streams and Tables[2] FLIP-95: New TableSource and TableSink interfaces[3] FLIP-105: Support to Interpret Changelog in Flink SQL (Introducing Debezium and Canal Format)[4] FLIP-149: Introduce the upsert-kafka Connector[5] Apache Flink 1.11.0 Release Announcement[6] Introduction to SQL in Flink 1.11[7] MongoDB Manual[8] MongoDB Connection String Options[9] MongoDB Kafka Connector
跨境支付独角兽企业XTransfer在招技术/产品运营类岗位,包括系统架构师、开发工程师、算法工程师、测试工程师、产品经理、UI/交互设计师等数十个人员。产研方向的同学简历直达渠道:wenjuan.he@xtransfer.cn
以上是关于Flink CDC 系列 - Flink MongoDB CDC 在 XTransfer 的生产实践的主要内容,如果未能解决你的问题,请参考以下文章
Flink 实战系列Flink CDC 实时同步 Mysql 全量加增量数据到 Hudi