Flink系列之:Flink CDC实现海量数据入湖
Posted 勇敢羊羊在飞奔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink系列之:Flink CDC实现海量数据入湖相关的知识,希望对你有一定的参考价值。
Flink系列之:Flink CDC实现海量数据入湖
一、历史数据入湖架构
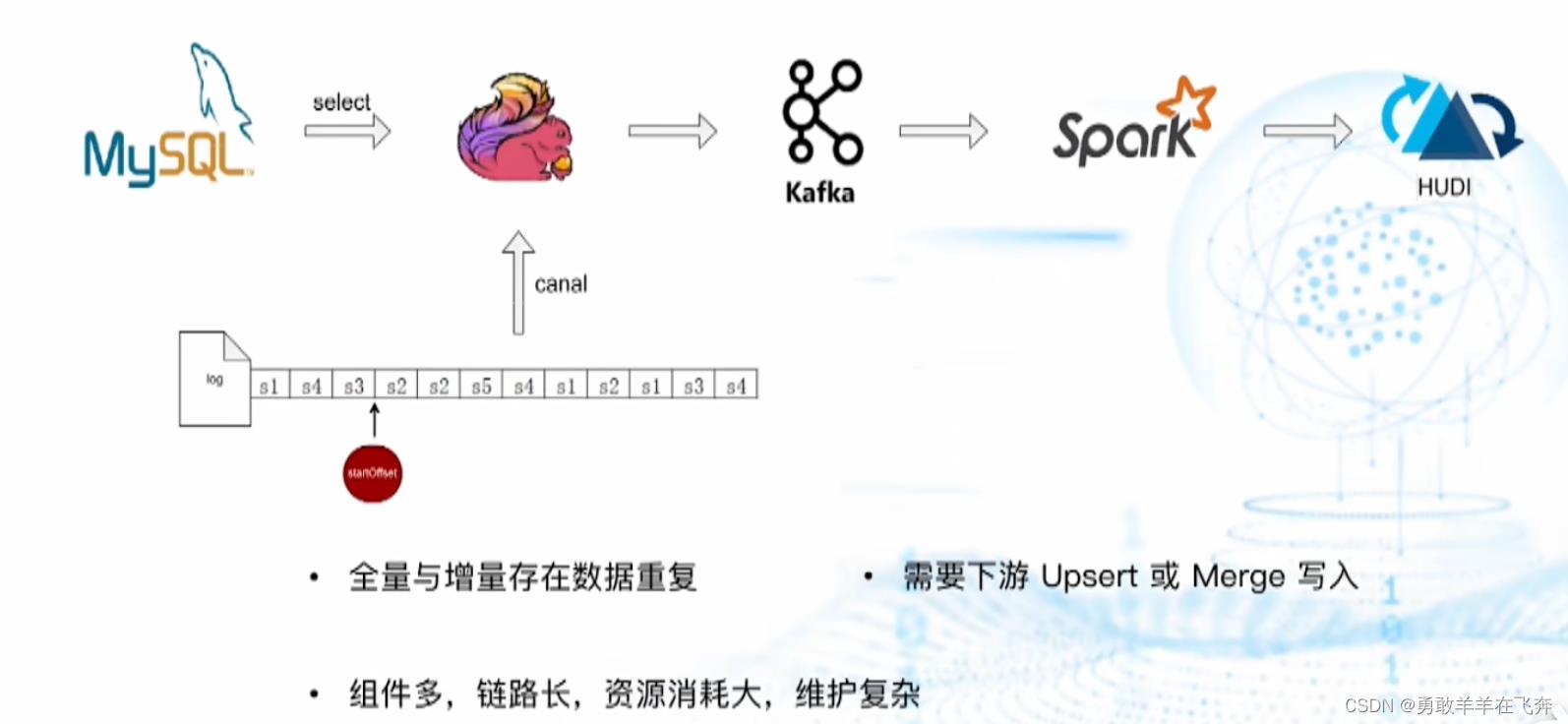
二、核心需求
- 全量增量自动切换,并保证数据准确性
- 最大限度地减少对源数据库的影响,尽量不使用锁
- 能在已存在的任务中,添加新表的数据采集。避免一张表一个任务把DB机器带宽打满
- 能同时进行全量与增量(日志)采集,不能暂停日志采集,以降低新增表对其他表日志采集带来的延迟
- 能确保数据在同一主键ID下是按历史顺序发生的,不能有后发生的事件先发送到下游
三、选择Flink CDC原因
- 无缝对接Flink生态
- 全量与增量自动切换,保证数据准确性
- 无锁读取,断点续传,水平扩展
四、Flink CDC 2.0原理
- 基于FLIP-27架构实现,先全量同步,在Enumerator把表切分成多个split块。把切分好的SnapshotSplit分配给Sourceread执行全量数据采集。
- 采集完成后,SourceRead向Enumerator汇报完成的SnapshotSplit信息。
- 重复步骤1、2。
- 全量采集完成之后,构造BinlogSplit分配给SourceRead执行增量日志数据采集。
五、支持全量与增量日志流并行读取
- 新增表后,停止增量日志数据采集任务,与核心需求4不符,造成新增表对其他表日志采集带来延迟。
解决方法:
- 全量与增量日志并行读取
全量与增量日志并行读取流程:
- 程序启动后,在Enumerator中,先执行增量同步去,创建BinlogSplit,放在分配列表的第一个,然后分配给SourceRead执行增量日志数据采集。
- Enumerator把全量采集切分成多个split块。然后把切分好的SnapshotSplit分配给SourceRead执行全量数据采集。
- 全量split采集完成后,SourceRead向Enumerator汇报完成的split信息。
- 重复步骤2、3,直到把所有表的全量数据都采集完毕。
以上是关于Flink系列之:Flink CDC实现海量数据入湖的主要内容,如果未能解决你的问题,请参考以下文章