kubernetes(七) Pod 调度
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kubernetes(七) Pod 调度相关的知识,希望对你有一定的参考价值。
参考技术A在默认情况下,一个Pod在哪个Node节点上运行,是由Scheduler组件采用相应的算法计算出来的,这个过程是不受人工控制的。但是在实际使用中,这并不满足的需求,因为很多情况下,我们想控制某些Pod到达某些节点上,那么应该怎么做呢?这就要求了解kubernetes对Pod的调度规则,kubernetes提供了四大类调度方式:
定向调度,指的是利用在pod上声明nodeName或者nodeSelector,以此将Pod调度到期望的node节点上。注意,这里的调度是强制的,这就意味着即使要调度的目标Node不存在,也会向上面进行调度,只不过pod运行失败而已。
NodeName
NodeName用于强制约束将Pod调度到指定的Name的Node节点上。这种方式,其实是直接跳过Scheduler的调度逻辑,直接将Pod调度到指定名称的节点。
接下来,实验一下:创建一个pod-nodename.yaml文件
NodeSelector
NodeSelector用于将pod调度到添加了指定标签的node节点上。它是通过kubernetes的label-selector机制实现的,也就是说,在pod创建之前,会由scheduler使用MatchNodeSelector调度策略进行label匹配,找出目标node,然后将pod调度到目标节点,该匹配规则是强制约束。
接下来,实验一下:
1 首先分别为node节点添加标签
2 创建一个pod-nodeselector.yaml文件,并使用它创建Pod
介绍了两种定向调度的方式,使用起来非常方便,但是也有一定的问题,那就是如果没有满足条件的Node,那么Pod将不会被运行,即使在集群中还有可用Node列表也不行,这就限制了它的使用场景。
基于上面的问题,kubernetes还提供了一种亲和性调度(Affinity)。它在NodeSelector的基础之上的进行了扩展,可以通过配置的形式,实现优先选择满足条件的Node进行调度,如果没有,也可以调度到不满足条件的节点上,使调度更加灵活。
Affinity主要分为三类:
NodeAffinity
首先来看一下 NodeAffinity 的可配置项:
接下来首先演示一下 requiredDuringSchedulingIgnoredDuringExecution ,创建pod-nodeaffinity-required.yaml
接下来再演示一下 requiredDuringSchedulingIgnoredDuringExecution ,创建pod-nodeaffinity-preferred.yaml
PodAffinity
PodAffinity主要实现以运行的Pod为参照,实现让新创建的Pod跟参照pod在一个区域的功能。首先来看一下 PodAffinity 的可配置项:
接下来,演示下 requiredDuringSchedulingIgnoredDuringExecution
1)首先创建一个参照Pod,pod-podaffinity-target.yaml:
2)创建pod-podaffinity-required.yaml,内容如下:
上面配置表达的意思是:新Pod必须要与拥有标签nodeenv=xxx或者nodeenv=yyy的pod在同一Node上,显然现在没有这样pod,接下来,运行测试一下。
关于 PodAffinity 的 preferredDuringSchedulingIgnoredDuringExecution ,这里不再演示。
PodAntiAffinity
PodAntiAffinity主要实现以运行的Pod为参照,让新创建的Pod跟参照pod不在一个区域中的功能。
它的配置方式和选项跟PodAffinty是一样的,这里不再做详细解释,直接做一个测试案例。
1)继续使用上个案例中目标pod
2)创建pod-podantiaffinity-required.yaml,内容如下:
上面配置表达的意思是:新Pod必须要与拥有标签nodeenv=pro的pod不在同一Node上,运行测试一下。
污点(Taints)
前面的调度方式都是站在Pod的角度上,通过在Pod上添加属性,来确定Pod是否要调度到指定的Node上,其实我们也可以站在Node的角度上,通过在Node上添加 污点 属性,来决定是否允许Pod调度过来。
Node被设置上污点之后就和Pod之间存在了一种相斥的关系,进而拒绝Pod调度进来,甚至可以将已经存在的Pod驱逐出去。
污点的格式为: key=value:effect , key和value是污点的标签,effect描述污点的作用,支持如下三个选项:
使用kubectl设置和去除污点的命令示例如下:
接下来,演示下污点的效果:
容忍(Toleration)
上面介绍了污点的作用,我们可以在node上添加污点用于拒绝pod调度上来,但是如果就是想将一个pod调度到一个有污点的node上去,这时候应该怎么做呢?这就要使用到 容忍 。
下面先通过一个案例看下效果:
创建pod-toleration.yaml,内容如下
下面看一下容忍的详细配置:
云原生训练营模块七 Kubernetes 控制平面组件:调度器与控制器
调度器与控制器
1、调度
kube-scheduler负责分配调度Pod到集群内的节点上,它监听kube-apiserver,查询还未分配Node的Pod,然后根据调度策略为这些Pod分配节点(更新Pod的NodeName字段)。
- 公平调度(顺序)
- 资源高效利用
- QoS
- affinity和anti-affinity
- 数据本地化(data locality)
- 内部负载干扰(inter-workload interface)
- deadlines
调度器:
kube-scheduler调度分为两个阶段,predicate和priority:
- predicate:过滤不符合条件的节点
- priority:优先级排序,选择优先级最高的节点
Predicates策略
- PodFitsHostPorts:检查是否有Host Ports冲突
- PodFitsPorts:同PodFitsHostPorts。
- PodFitsResrouces:检查Node的资源是否充足,包括允许的Pod数量、CPU、内存、GPU个数以及其他的OpaqueIntResources。
- HostName:检查pod.Spec.NodeName是否与候选节点一致。
- MatchNodeSelector:检查候选节点的pod.Spec.NodeSelector是否匹配。
- NoVolumeZoneConflict:检查volume zone是否冲突。
- MatchinterPodAffinity:检查是否匹配Pod的亲和性要求。
- NoDiskConflict:检查是否存在Volume冲突,仅限于GCEPD、AWSEBS、Ceph RBD以及i5CSl。
- PodToleratesNodeTaints:检查Pod是否容忍Node Taints。
- CheckNodeMemoryPressure:检查Pod 是否可以调度到MemoryPressure的节点上。
- CheckNodeDiskPressure:检查Pod是否可以调度到DiskPressure的节点上。
- NoVolumeNodeConflict:检查节点是否满足Pod所引用的Volume的条件。
Predicates plugin工作原理:一层层运行插件并过滤,最后剩可用的节点集合,然后就会往Priority策略
Priorities策略
工作原理:根据每一个插件会有权重打分机制,然后最后权重分数高的择优
- SelectorSpreadPriority:优先减少节点上属于同一个Service或Replication Controller的Pod数量(备份冗余)。
- InterPodAffinityPriority:优先将Pod调度到相同的拓扑上(如同一个节点、Rack、Zone等)。
- LeastRequestedPriority:优先调度到请求资源少的节点上。
- BalancedResourceAllocation:优先平衡各节点的资源使用。
- NodePreferAvoidPodsPriority:alpha.kubernetes.io/preferAvoidPods字段判断,权重为10000,避免其他优先级策略的影响。
- NodeAffinityPriority:优先调度到匹配NodeAffinity的节点上。
- TaintTolerationPriority:优先调度到匹配TaintToleration的节点上。
ServiceSpreadingPriority:尽量将同一个service的Pod分布到不同节点上,已经被SelectorSpreadPriority替代(默认未使用)。 - EqualPriority:将所有节点的优先级设置为1(默认未使用)。
- ImageLocalityPriority:尽量将使用大镜像的容器调度到已经下拉了该镜像的节点上(默认未使用)。
- MostRequestedPriority:尽量调度到已经使用过的Node上,特别适用于cluster-autoscaler(默认未使用)。
资源需求
CPU
- requests
Kubernetes调度Pod时,会判断当前节点正在运行的Pod的CPU Request的总和,再加上当前调度Pod的CPU request,计算其是否超过节点的CPU的可分配资源。 - limits
配置cgroup以限制资源上限。
内存
- requests
判断节点的剩余内存是否满足Pod的内存请求量,以确定是否可以将Pod调度到该节点。 - limits
配置cgroup以限制资源上限。
示例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: 1Gi
cpu: 1
requests:
memory: 256Mi
cpu: 100m
apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
spec:
limits:
- default:
memory: 512Mi
defaultRequest:
memory: 256Mi
type: Container
磁盘资源需求
- 容器临时存储(ephemeral storage)包含日志和可写层数据,可以通过定义Pod Spec中的limits.ephemeral-storage和requests.ephemeral-storage来申请。
- Pod调度完成后,计算节点对临时存储的限制不是基于CGroup的,而是由kubelet定时获取容器的日志和容器可写层的磁盘使用情况,如果超过限制,则会对Pod进行驱逐。
Init Container的资源需求
- 当kube-scheduler调度带有多个init容器的Pod时,只计算cpu.request最多的init容器,而不是计算所有的init容器总和。
- 由于多个init容器按顺序执行,并且执行完成立即退出,所以申请最多的资源init容器中的所需资源,即可满足所有init容器需求。
- kube-scheduler在计算该节点被占用的资源时,init容器的资源依然会被纳入计算。因为init容器在特定情况下可能会被再次执行,比如由于更换镜像而引起Sandbox重建时。
把Pod调度到指定Node上
nodeSelector
- 可以通过nodeSelector、nodeAffinity、podAffinity以及Taints 和tolerations等来将Pod 调度到需要的Node上。
- 也可以通过设置nodeName参数,将Pod 调度到指定node节点上。
- 比如,使用nodeSelector,首先给Node加上标签:
kubectl label nodes <your-node-name> disktype=ssd接着,指定该Pod 只想运行在带有 disktype=ssd标签的Node上。
apiversion:v1
kind:Pod
metadata:
name:nginx
labels:
env:test
spec:
containers:
- name:nginx
image:nginx
imagePullPolicy:IfNotPresent
nodeSelector:
disktype:ssd
NodeAffinity
NodeAffinity目前支持两种:
- requiredDuringSchedulinglgnoredDuringExecution(必须满足条件)
- preferredDuringSchedulinglgnoredDuringExecution(优选条件)
比如下面的例子代表调度到包含标签Kubernetes.io/e2e-az-name 并且值为e2e-az1或e2e-az2的Node上,并且优选还带有标签another-node-label-key=another-node-label-value的 Node。

podAffinity
podAffinity基于Pod的标签来选择Node,仅调度到满足条件Pod所在的Node上,支持podAffinity和podAntiAffinity。这个功能比较绕,以下面的例子为例:
如果一个“Node所在Zone中包含至少一个带有 security=S1标签且运行中的Pod”,那么可以调度到该Node,不调度到“包含至少一个带有 security=S2标签且运行中Pod”的Node上。
Taints和Tolerations
Taints和Tolerations 用于保证Pod不被调度到不合适的Node上,其中Taint应用于Node上,而Toleration则应用于Pod上。
Taint node
kubectl taint nodes cadmin for-special-user=cadmin:NoSchedule
(kubectl taint nodes nodename key=value:policy)
Untaint node
kubectl taint nodes cadmin for-special-user=cadmin:NoSchedule-
tolerations:
- key: "for-special-user"
operator: "Equal"
value: "cadmin"
effect: "NoSchedule"
tolerationSeconds: 100
目前支持的Taint类型:
- NoSchedule:新的Pod不调度到该Node上,不影响正在运行的Pod;
- PreferNoSchedule:soft版的NoSchedule,尽量不调度到该Node上;
- NoExecute:新的Pod 不调度到该Node上,并且删除(evict)已在运行的Pod。Pod可以增加一个时间(tolerationSeconds)。
然而,当Pod的Tolerations 匹配Node的所有Taints的时候可以调度到该Node上;当Pod是已经运行的时候,也不会被删除(evicted)。另外对于NoExecute,如果Pod增加了一个tolerationSeconds,则会在该时间之后才删除 Pod。

优先级调度
从v1.8开始,kube-scheduler支持定义Pod的优先级,从而保证高优先级的Pod 优先调度。开启方法为:
- apiserver配置-feature-gates=PodPriority=true和-runtime-
config=scheduling.k8s.io/vlalphal=true - kube-scheduler配置–feature-gates=PodPriority=true


多调度器
如果默认的调度器不满足要求,还可以部署自定义的调度器。并且,在整个集群中还可以同时运行多个调度器实例,通过podSpec.schedulerName 来选择使用哪一个调度器(默认使用内置的调度器)。 —— (自定义设置容忍时间)

2、Controller Manager
Controller Manager 由 kube-controller-manager 和 cloud-controller-manager 组成,是 Kubernetes 的大脑,它通过 apiserver 监控整个集群的状态,并确保集群处于预期的工作状态。
- 获取kube-controller-manager其他参数:
kubectl exec -it kube-controller-manager-cadmin -- kube-controller-manager -h - 获取控制器版本信息:
kubectl get controllerrevision
控制器的工作流程
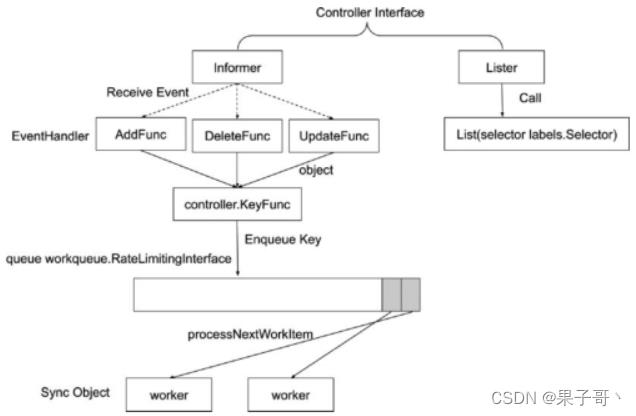
Informer的内部机制
Reflector会解析对象的key。
代码本地的Thread Safe Store会存储对象和键值,即存储namespace
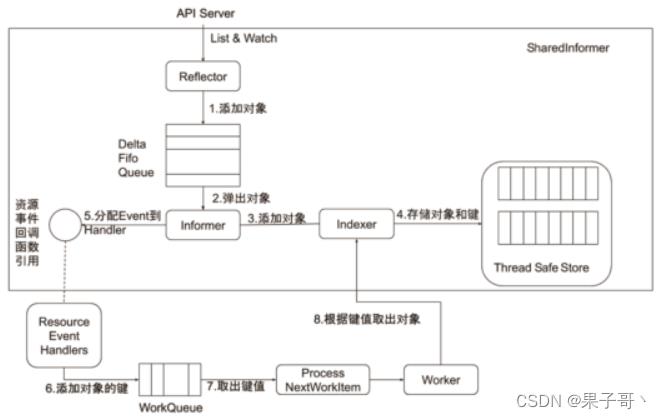
控制器的协同工作原理
Controller Manager
把结果写到API Server
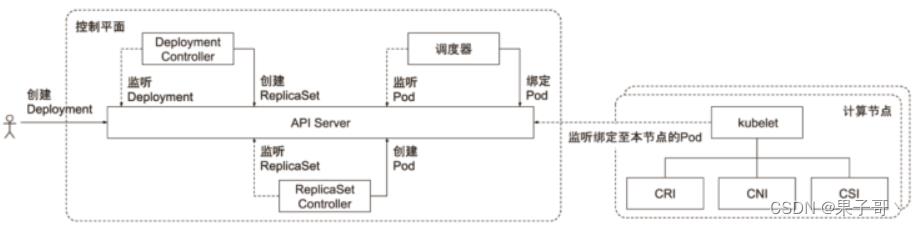
通用Controller
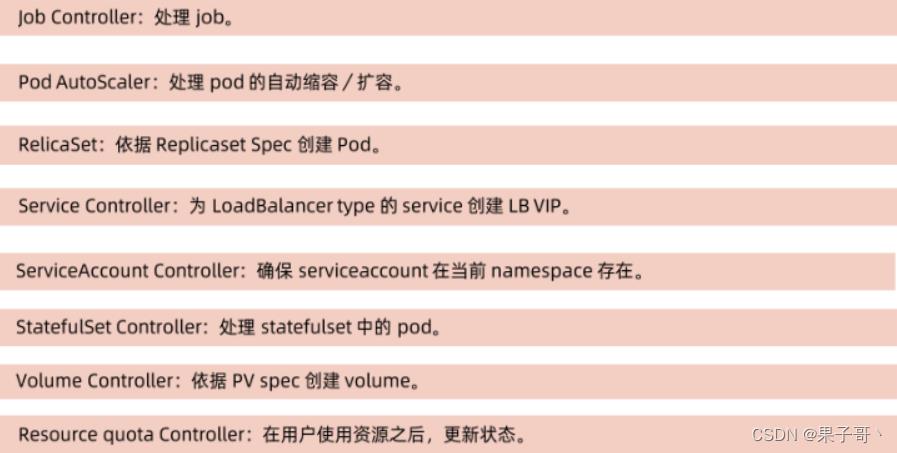

kube-controller-manage
Job
- backoffLimit是Job模式里的restartPolicy为OnFailure的最大重启次数。
- parallelism:并行数
- completions:执行次数
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
parallelism: 2
completions: 5
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: OnFailure
StatefulSet:管理有状态应用的工作负载Api对象
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx-ss
spec:
serviceName: nginx-ss
replicas: 1
selector:
matchLabels:
app: nginx-ss
template:
metadata:
labels:
app: nginx-ss
spec:
containers:
- name: nginx-ss
image: nginx
---
apiVersion: v1
kind: Service
metadata:
name: nginx-ss
labels:
app: nginx-ss
spec:
ports:
- port: 80
clusterIP: None
selector:
app: nginx-ss
DaemonSet:日志场景
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nginx-ds
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ReplicaSet:kubernetes中的一种副本控制器,主要作用是控制由其管理的pod,使pod副本的数量始终维持在预设的个数。
Garbage Controller:watch集群里所有对象,ownerReference
控制垃圾收集器删除附属
当你删除对象时,可以指定该对象的附属是否也自动删除。 自动删除附属的行为也称为 级联删除(Cascading Deletion) 。 Kubernetes 中有两种 级联删除 模式:后台(Background) 模式和 前台(Foreground) 模式。
如果删除对象时,不自动删除它的附属,这些附属被称作 孤立对象(Orphaned)。
Kubernetes 会自动设置 ownerReference 的值。 例如,当创建一个 ReplicaSet 时,Kubernetes 自动设置 ReplicaSet 中每个 Pod 的 ownerReference 字段值。 在 Kubernetes 1.8 版本,Kubernetes 会自动为某些对象设置 ownerReference 的值。 这些对象是由 ReplicationController、ReplicaSet、StatefulSet、DaemonSet、Deployment、 Job 和 CronJob 所创建或管理的。
你也可以通过手动设置 ownerReference 的值,来指定属主和附属之间的关系。
apiVersion: v1
kind: Pod
metadata:
...
ownerReferences:
- apiVersion: apps/v1
controller: true
blockOwnerDeletion: true
kind: ReplicaSet
name: my-repset
uid: d9607e19-f88f-11e6-a518-42010a800195
...
cloud-controller-manager



确保scheduler和controller的高可用
Leader election加锁,能让主控制器通过心跳去获取控制器

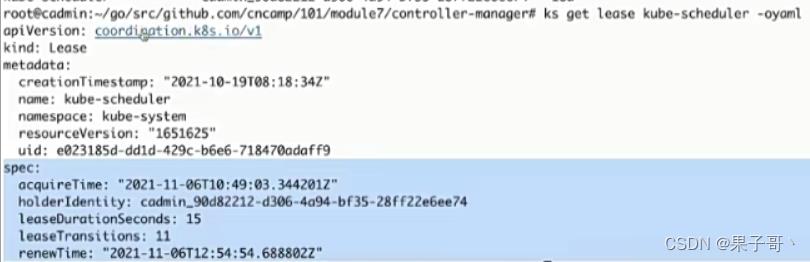
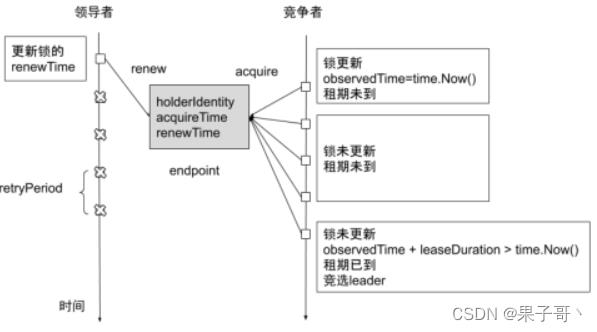
3、Kubelet
kubelet架构
每个节点上都运行一个kubelet服务进程,默认监听10250端口。
- 接收并执行master发来的指令;
- 管理Pod及Pod中的容器;
- 每个kubelet 进程会在API Server上注册节点自身信息,定期向master 节点汇报节点的资源使用情况,并通过CAdvisor 监控节点和容器的资源。
节点管理
节点管理主要是节点自注册和节点状态更新:
- Kubelet 可以通过设置启动参数–register-node来确定是否向API Server注册自己;
- 如果Kubelet 没有选择自注册模式,则需要用户自己配置Node 资源信息,同时需要告知Kubelet 集群上的API Server的位置;
- Kubelet 在启动时通过API Server 注册节点信息,并定时向API Server 发送节点新消息,APl Server在接收到新消息后,将信息写入etcd。
Pod管理
获取Pod清单:
- 文件:启动参数
--config指定的配置目录下的文件(默认/etc/Kubernetes/manifests/)。该文件每20秒重新检查一次(可配置)。 - HTTP endpoint(URL):启动参数
--manifest-url设置。每20秒检查一次这个端点(可配置)。 - API Server:通过API Server 监听etcd目录,同步Pod清单。
- HTTP server:kubelet侦听HTTP请求,并响应简单的API以提交新的Pod清单。
管理整个Pod的生命周期
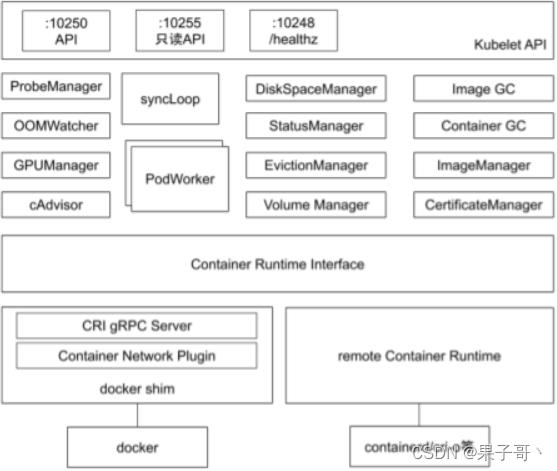
kubelet管理Pod的核心流程

❤Pod启动流程
sandbox容器是一个pause容器,永远sleep的一个进程。作为一个pod的底座,为了稳定性,让网络挂载上去。
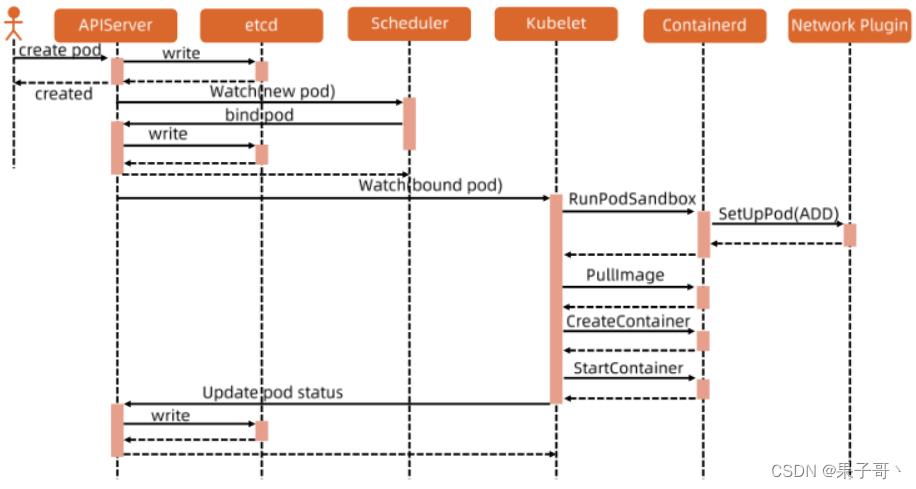
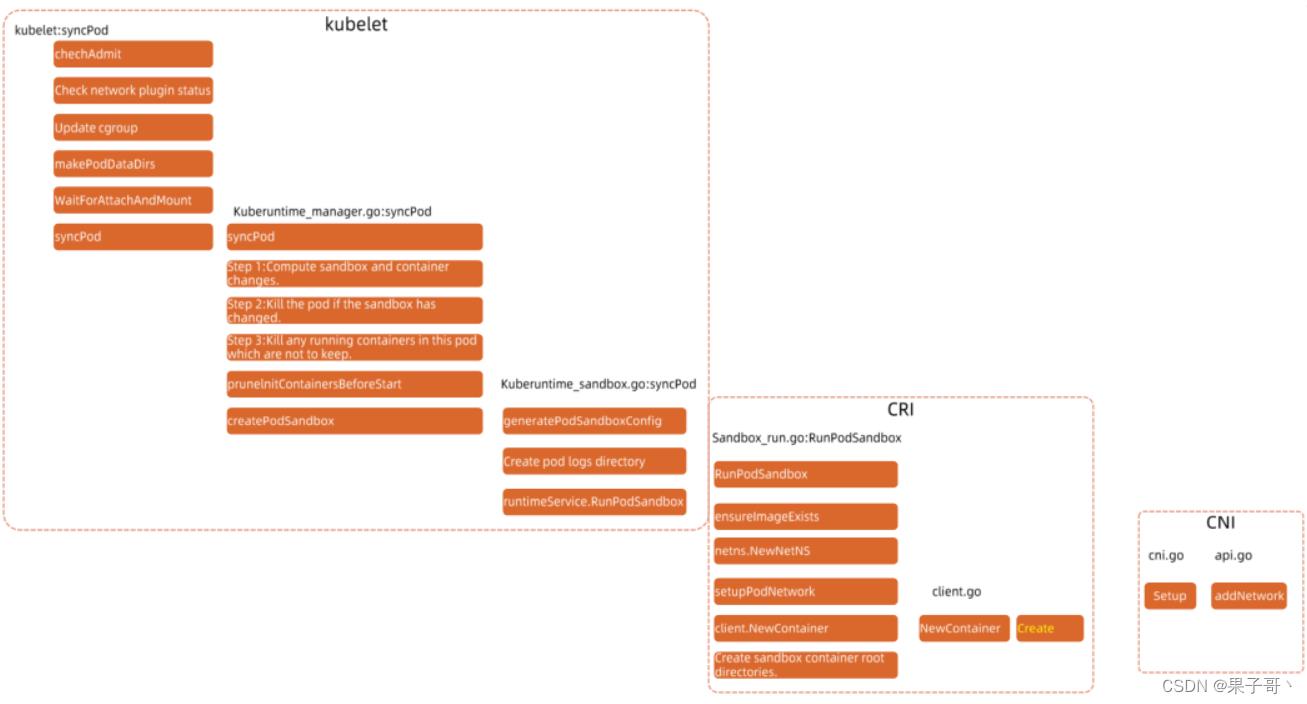
- makePodDataDirs,存储临时数据,如console日志
cAdvisor
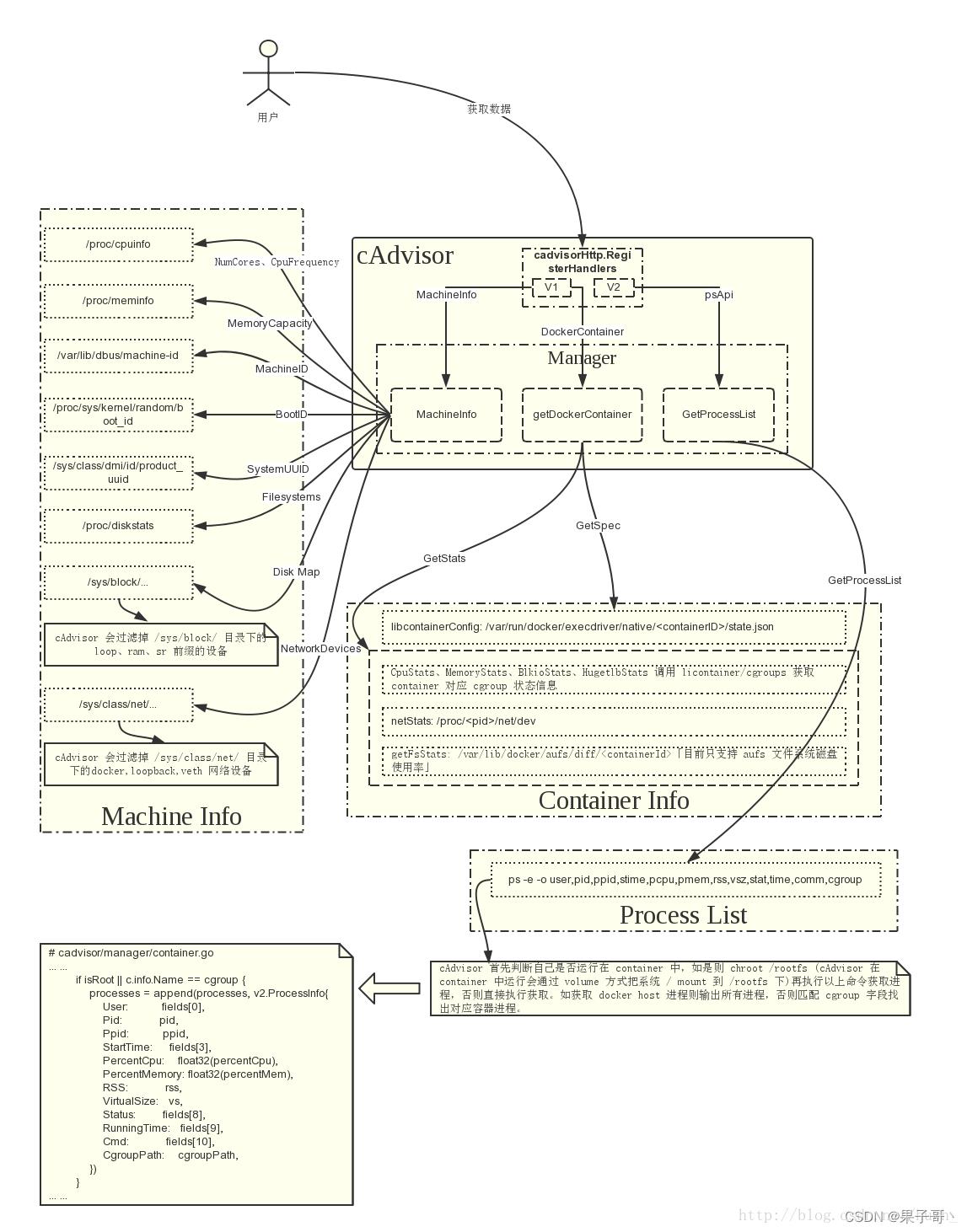
cAdvisor:cAdvisor对Node机器上的资源及容器进行实时监控和性能数据采集,包括CPU使用情况、内存使用情况、网络吞吐量及文件系统使用情况,采集资源指标并上报,cAdvisor集成在Kubelet中,当kubelet启动时会自动启动cAdvisor,即一个cAdvisor仅对一台Node机器进行监控。kubelet的启动参数–cadvisor-port可以定义cAdvisor对外提供服务的端口,默认为4194。
1.cAvisor简介:
cAdvisor是Google开源的容器资源监控和性能分析工具,它是专门为容器而生,在Kubernetes中,我们不需要单独去安装,cAdvisor作为kubelet内置的一部分程序可以直接使用,也就是我们可以直接使用cadvisor采集数据,可以采集到和容器运行相关的所有指标,单独安装cAdvisor时的数据路径为/api/v1/nodes/[节点名称]/proxy/metrics/cadvisor,如果cadvisor集成到kubelet,采集数据的路径是https://127.0.0.1:10250/metrics/cadvisor
2.查看cadvisor监控指标,在k8s-master节点操作
kubectl create ns monitor-sa #创建一个monitor-sa的名称空间
kubectl create serviceaccount monitor -n monitor-sa #创建一个sa账号
kubectl create clusterrolebinding monitor-clusterrolebinding -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor
#把sa账号monitor通过clusterrolebing绑定到clusterrole上
kubectl get secret -n monitor-sa #查看monitor-sa名称空间下的secret密钥
kubectl describe secret monitor-token-j4jwf -n monitor-sa #可看到token相关的内容如下所示
eyJhbGciOiJSUzI1NiIsImtpZCI6IkV5VUZuUmlPa0pMSF9sSFdUYktjdWdGVk9CR3owMlZhUDg4UzdVQWtveEEifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJtb25pdG9yLXNhIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6Im1vbml0b3ItdG9rZW4tajRqd2YiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoibW9uaXRvciIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImQ5NzJiNDA1LWEzZTYtNDJiYS04YzU3LTA2MjE2YmE3Nzk1MCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDptb25pdG9yLXNhOm1vbml0b3IifQ.U0fMb34xlIcMrC5g_v3jeTMwxg3L3VkAD6lUa84Ke3kor3aB9tT092PM4N5_8cVPRJkHkh5UXx3A7mWOErjftgux41azA2N1Zkuqt-7VXkvvBCOBAmv-95mRz9FPEbzbR9gG5EudcCFeJypYOO3n7Oipr1MS4YxGLYVjUTQ46f5GIMJli9Uw6MYkij9HwuoD8qbLulAq6W540qvJfK4Bd20kvjqzZQveD2Ej-hmUlHR2cqshgD64VgBOIAJJir4bQ04JthLqgpC9peTTYo2hJ8XK-Y5OCx2v419syb0xPC2jrzwcZabvTBG_QCB4Ly8BRAxjEDB4ox3R6EMw8Ie68A
通过下面命令可以获取到cadvisor采集的指标数据
curl https://127.0.0.1:10250/metrics/cadvisor -k -H "Authorization: Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6IkV5VUZuUmlPa0pMSF9sSFdUYktjdWdGVk9CR3owMlZhUDg4UzdVQWtveEEifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJtb25pdG9yLXNhIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6Im1vbml0b3ItdG9rZW4tajRqd2YiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoibW9uaXRvciIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImQ5NzJiNDA1LWEzZTYtNDJiYS04YzU3LTA2MjE2YmE3Nzk1MCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDptb25pdG9yLXNhOm1vbml0b3IifQ.U0fMb34xlIcMrC5g_v3jeTMwxg3L3VkAD6lUa84Ke3kor3aB9tT092PM4N5_8cVPRJkHkh5UXx3A7mWOErjftgux41azA2N1Zkuqt-7VXkvvBCOBAmv-95mRz9FPEbzbR9gG5EudcCFeJypYOO3n7Oipr1MS4YxGLYVjUTQ46f5GIMJli9Uw6MYkij9HwuoD8qbLulAq6W540qvJfK4Bd20kvjqzZQveD2Ej-hmUlHR2cqshgD64VgBOIAJJir4bQ04JthLqgpC9peTTYo2hJ8XK-Y5OCx2v419syb0xPC2jrzwcZabvTBG_QCB4Ly8BRAxjEDB4ox3R6EMw8Ie68A"
3.cadvisor中获取到的典型监控指标如下:
指标名称 类型 含义
container_cpu_load_average_10s gauge 过去10秒容器CPU的平均负载
container_cpu_usage_seconds_total counter 容器在每个CPU内核上的累积占用时间 (单位:秒)
container_cpu_system_seconds_total counter System CPU累积占用时间(单位:秒)
container_cpu_user_seconds_total counter User CPU累积占用时间(单位:秒)
container_fs_usage_bytes gauge 容器中文件系统的使用量(单位:字节)
container_fs_limit_bytes gauge 容器可以使用的文件系统总量(单位:字节)
container_fs_reads_bytes_total counter 容器累积读取数据的总量(单位:字节)
container_fs_writes_bytes_total counter 容器累积写入数据的总量(单位:字节)
container_memory_max_usage_bytes gauge 容器的最大内存使用量(单位:字节)
container_memory_usage_bytes gauge 容器当前的内存使用量(单位:字节
container_spec_memory_limit_bytes gauge 容器的内存使用量限制
machine_memory_bytes gauge 当前主机的内存总量
container_network_receive_bytes_total counter 容器网络累积接收数据总量(单位:字节)
container_network_transmit_bytes_total counter 容器网络累积传输数据总量(单位:字节)
4.当能够正常采集到cAdvisor的样本数据后,可以通过以下表达式计算容器的CPU使用率:
(1)sum(irate(container_cpu_usage_seconds_totalimage!=""[1m])) without (cpu)
容器CPU使用率
(2)container_memory_usage_bytesimage!=""
查询容器内存使用量(单位:字节):
(3)sum(rate(container_network_receive_bytes_totalimage!=""[1m])) without (interface)
查询容器网络接收量(速率)(单位:字节/秒):
(4)sum(rate(container_network_transmit_bytes_totalimage!=""[1m])) without (interface)
容器网络传输量 字节/秒
(5)sum(rate(container_fs_reads_bytes_totalimage!=""[1m])) without (device)
容器文件系统读取速率 字节/秒
(6)sum(rate(container_fs_writes_bytes_totalimage!=""[1m])) without (device)
容器文件系统写入速率 字节/秒
5.cadvisor 常用容器监控指标
(1)网络流量
sum(rate(container_network_receive_bytes_totalname=~".+"[1m])) by (name)
##容器网络接收的字节数(1分钟内),根据名称查询 name=~".+"
sum(rate(container_network_transmit_bytes_totalname=~".+"[1m])) by (name)
##容器网络传输的字节数(1分钟内),根据名称查询 name=~".+"
(2)容器 CPU相关
sum(rate(container_cpu_system_seconds_total[1m]))
###所用容器system cpu的累计使用时间(1min钟内)
sum(irate(container_cpu_system_seconds_totalimage!=""[1m])) without (cpu)
###每个容器system cpu的使用时间(1min钟内)
sum(rate(container_cpu_usage_seconds_totalname=~".+"[1m])) by (name) * 100
#每个容器的cpu使用率
sum(sum(rate(container_cpu_usage_seconds_totalname=~".+"[1m])) by (name) * 100)
#总容器的cpu使用率
4、CRI
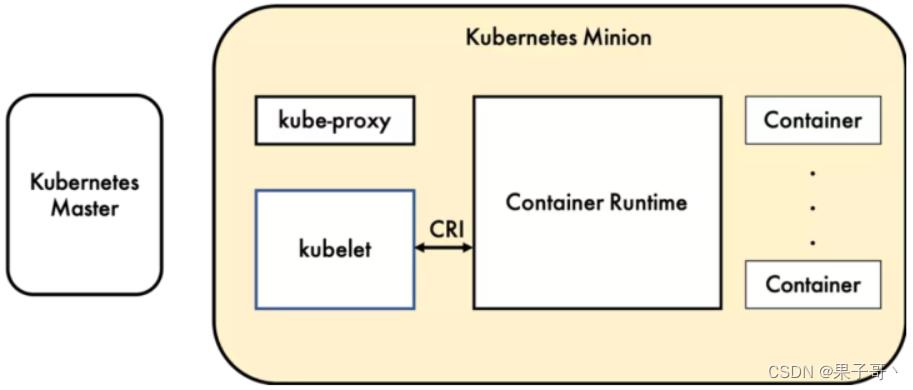
kubelet启动pod的时候是通过CRI进行启动。
CRI:
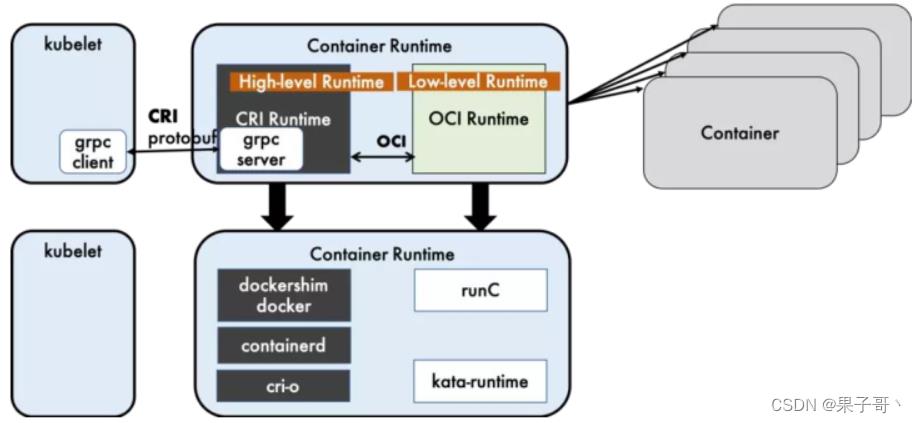
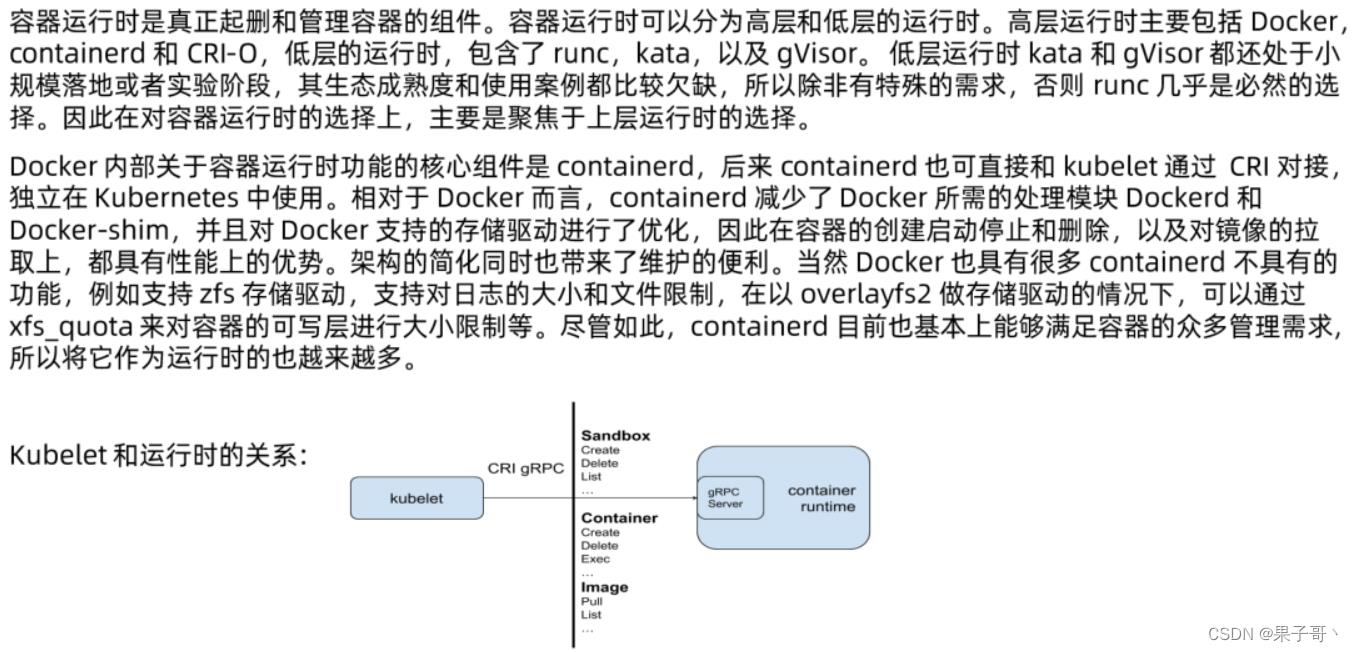
容器运行时(Container Runtime),运行于Kubernetes(k8s)集群的每个节点中,负责容器的整个生命周期。其中Docker是目前应用最广的。随着容器云的发展,越来越多的容器运行时涌现。为了解决这些容器运行时和Kubernetes的集成问题,在Kubernetes 1.5版本中,社区推出了CRI(
Container Runtime Interface,容器运行时接口)以支持更多的容器运行时。
CRI是Kubernetes定义的一组gRPC服务。kubelet作为客户端,基于gRPC框架,通过Socket和容器运行时通信。它包括两类服务:镜像服务(Image Service)和运行时服务(Runtime Service)。
- 镜像服务提供下载、检查和删除镜像的远程程序调用。
- 运行时服务包含用于管理容器生命周期,以及与容器交互的调用(exec/attach/port-forward)的远程程序调用。

5、CNI
Kubernetes网络模型设计的基础原则是:
- 所有的Pod能够不通过NAT就能相互访问。
- 所有的节点能够不通过NAT就能相互访问。
- 容器内看见的IP地址和外部组件看到的容器IP是一样的。
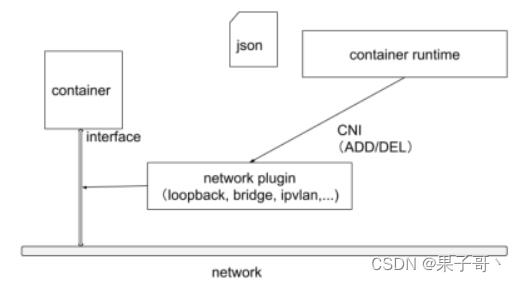
Kubernetes的集群里,IP地址是以Pod为单位进行分配的,每个Pod都拥有一个独立的IP地址。一个Pod内部的所有容器共享一个网络栈,即宿主机上的一个网络命名空间,包括它们的IP地址、网络设备、配置等都是共享的。也就是说,Pod 里面的所有容器能通过localhost:port来连接对方。在Kubernetes中,提供了一个轻量的通用容器网络接口CNI(Container Network Interface),专门用于设置和删除容器的网络连通性。容器运行时通过CNI 调用网络插件来完成容器的网络设置。
CNI插件分类和常见插件
- IPAM:IP地址分配
- 主插件:网卡设置
- bridge:创建一个网桥,并把主机端口和容器端口插入网桥
- ipvlan:为容器添加ipvlan网口
- loopback:设置loopback网口
- Meta:附加功能
- portmap:设置主机端口和容器端口映射
- bandwidth:利用Linux Traffic Control限流
- firewall:通过iptables或firewall的为容器设置防火墙规则
CNI插件运行机制
容器运行时在启动时会从CNI的配置目录中读取JSON格式的配置文件,文件后缀为".conf”“.conflist””.json"。如果配置目录中包含多个文件,一般情况下,会以名字排序选用第一个配置文件作为默认的网络配置,并加载获取其中指定的CNI插件名称和配置参数。
插件设计考量


CNI的运行机制
原理:启动一个Pod,Container RunTime会去调用CNI,CNI会去调用IPAM插件,然后为Pod分配一个IP,然后会配置带宽,把配置结果告诉Container RunTime,Container RunTime就会把这个IP带给kubelet, kubelet会把状态上报到API Server,然后Pod的IP就会更新到Pod的状态里,这个Pod就有IP了
关于容器网络管理,容器运行时一般需要配置两个参数–cni-bin-dir和–cni-conf-dir。有一种特殊情况,kubelet内置的Docker作为容器运行时,是由kubelet来查找CNI插件的,运行插件来为容器设置网络,这两个参数应该配置在kubelet处:
- cni-bin-dir:网络插件的可执行文件所在目录。默认是
/opt/cni/bin。 - cni-conf-dir:网络插件的配置文件所在目录。默认是
/etc/cni/net.d。

打通主机层网络
原理:启动一个Pod,Container RunTime会去调用CNI,CNI会去调用IPAM插件,然后为Pod分配一个IP,然后会配置带宽,把配置结果告诉Container RunTime,Container RunTime就会把这个IP带给kubelet, kubelet会把状态上报到API Server,然后Pod的IP就会更新到Pod的状态里,这个Pod就有IP了
CNI插件外,Kubernetes还需要标准的CNI插件lo,最低版本为0.2.0版本。网络插件除支持设置和清理Pod网络接口外,该插件还需要支持Iptables。如果Kube-proxy 工作在lptables模式,网络插件需要确保容器流量能使用lptables转发。例如,如果网络插件将容器连接到Linux网桥,必须将net/bridge/bridge-nf-call-iptables参数sysctt 设置为1,网桥上数据包将遍历Iptables规则。如果插件不使用Linux桥接器(而是类似Open vSwitch或其他某种机制的插件),则应确保容器流量被正确设置了路由。
Flannel
- Flannel是由CoreOS开发的项目,是CNI插件早期的入门产品,简单易用。
- Flannel使用Kubernetes集群的现有etcd集群来存储其状态信息,从而不必提供专用的数据存储,只需要在每个节点上运行flanneld 来守护进程。
- 每个节点都被分配一个子网,为该节点上的Pod分配IP地址。
- 同一主机内的Pod可以使用网桥进行通信,而不同主机上的Pod将通过flanneld将其流量封装在UDP数据包中,以路由到适当的目的地。
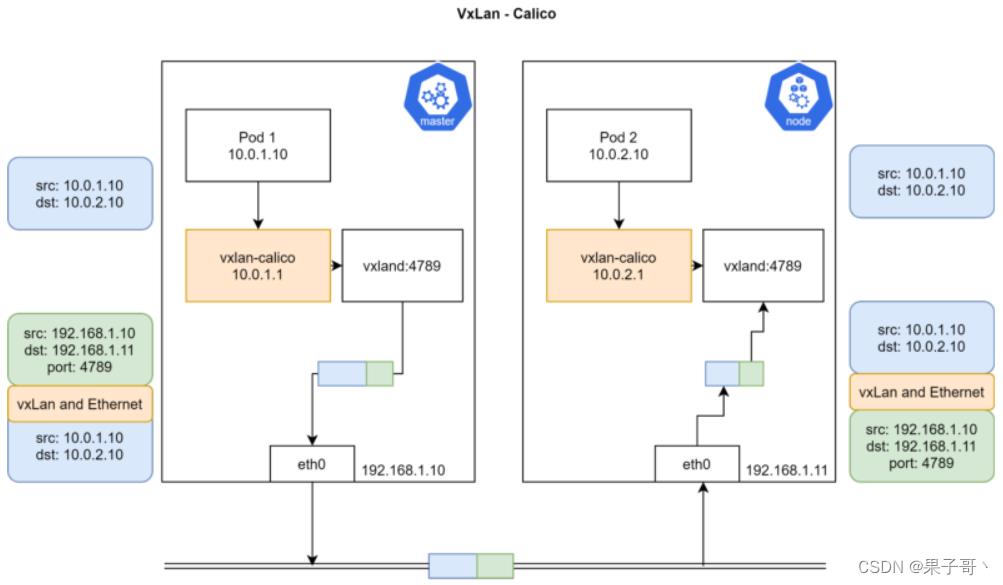
- 封装方式默认和推荐的方法是使用VXLAN,因为它具有良好的性能,并且比其他选项要少些人为干预。虽然使用VXLAN之类的技术封装的解决方案效果很好,但缺点就是该过程使流量跟踪变得困难。
- 缺点:对应网络策略没有,而且需要额外网络开销
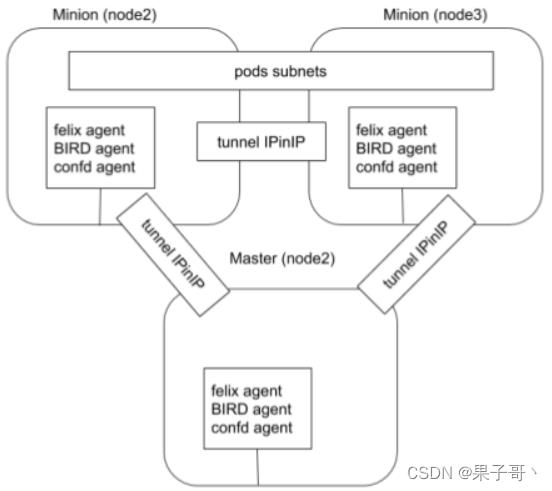
Calico
- Calico以其性能、灵活性和网络策略而闻名,不仅涉及在主机和Pod之间提供网络连接,而且还涉及网络安全性和策略管理。
- 对于同网段通信,基于第3层,Calico使用BGP路由协议在主机之间路由数据包,使用BGP路由协议也意味着数据包在主机之间移动时不需要包装在额外的封装层中。
- 对于跨网段通信,基于IPinlP使用虚拟网卡设备tunt0,用一个IP数据包封装另一个IP数据包,外层IP数据包头的源地址为隧道入口设备的IP地址,目标地址为隧道出口设备的IP地址。
- 网络策略是Calico最受欢迎的功能之一,使用ACLs协议和kube-proxy 来创建iptables过滤规则,从而实现隔离容器网络的目的。
- 此外,Calico还可以与服务网格Istio集成,在服务网格层和网络基础结构层上解释和实施集群中工作负载的策略。
这意味着您可以配置功能强大的规则,以描述Pod应该如何发送和接收流量,提高安全性及加强对网络环境的控制。 - Calico属于完全分布式的横向扩展结构,允许开发人员和管理员快速和平稳地扩展部署规模。对于性能和功能(如网络策略)要求高的环境,Calico是一个不错选择。
Calico初始化

Calico配置一览

Calico VXLan
封包解包
kubectl get crd
kubectl get ippools.crd.projectcalico.org -o yaml
- IPPool用来定义一个集群的预定义IP段
apiVersion: crd.projectcalico.org/v1
kind: IPPool
metadata:
name: default-ipv4-ippool
spec:
blockSize: 26
cidr: 192.168.0.0/16
ipipMode: Never
natOutgoing: true
nodeSelector: all()
vxlanMode: CrossSubnet
- IPAMBlock用来定义每个主机预分配的IP段
- IPAMHandle用来记录IP分配的具体细节
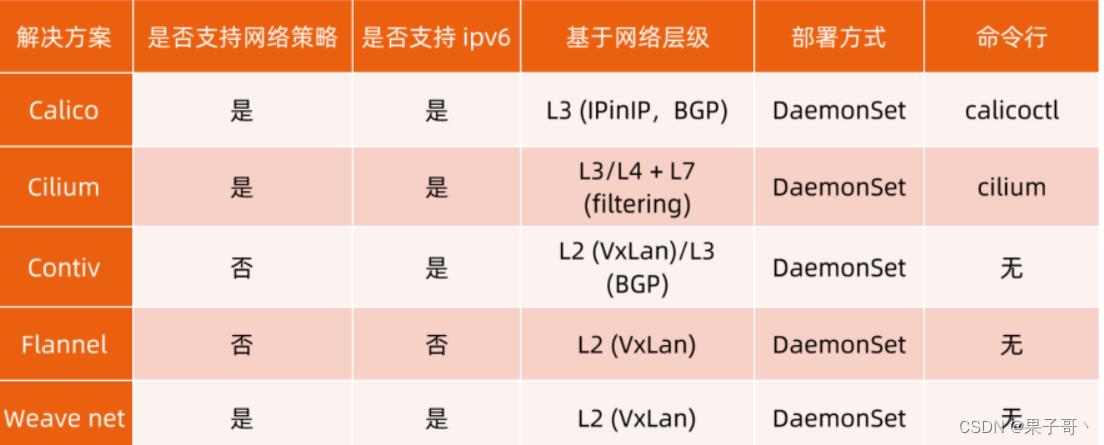
CNI Plugin的对比
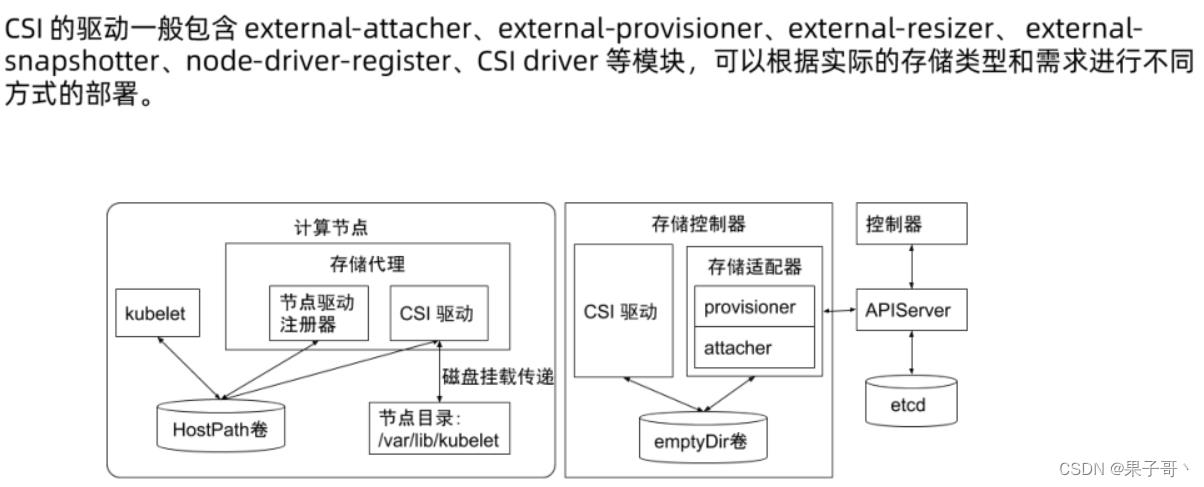
6、CSI
容器运行时存储
- 除外挂存储卷外,容器启动后,运行时所需文件系统性能直接影响容器性能;
- 早期的Docker 采用Device Mapper作为容器运行时存储驱动,因为OverlayFS尚未合并进Kernel;
- 目前Docker 和containerd都默认以OverlayFS作为运行时存储驱动;
- OverlayFS目前已经有非常好的性能,与DeviceMapper 相比优20%,与操作主机文件性能几乎一致。
存储卷插件 out-of-tree 管理
K8s支持以插件的形式来实现对不同存储的支持和扩展。
out-of-tree CSI插件
CSI通过RPC与存储驱动进行交互。
在设计CSI的时候,Kubernetes对CSI存储驱动的打包和部署要求很少,主要定义了Kubernetes的两个相关模块。
-
kube-controller-manager:
- kube-controller-manager 模块用于感知CSI驱动存在。
- Kubernetes的主控模块通过Unix domain socket(而不是CSl驱动)或者其他方式进行直接地交互。
- Kubernetes的主控模块只与Kubernetes相关的API进行交互。
- 因此CSI驱动若有依赖于KubernetesAPI的操作,例如卷的创建、卷的attach、卷的快照等,需要在CSI驱动里面通过Kubernetes的APl,来触发相关的CSl操作。
-
kubelet:
- kubelet模块用于与CSI驱动进行交互
- kubelet 通过Unix domain socket 向CSI 驱动发起CSI 调用(如NodeStageVolume、NodePublishVolume等),再发起mount卷和umount卷。
- kubelet 通过插件注册机制发现CSI驱动及用于和CSI驱动交互的Unix Domain Socket.
- 所有部署在Kubernetes集群中的CSI驱动都要通过kubelet的插件注册机制来注册自己。
CSI驱动
临时存储 emptyDir卷
- 常见的临时存储主要就是emptyDir卷。
- emptyDir是一种经常被用户使用的卷类型,顾名思义,“卷”最初是空的。当Pod从节点上删除时,emptyDir 卷中的数据也会被永久删除。但当Pod的容器因为某些原因退出再重启时,emptyDir卷内的数据并不会丢失。
- 默认情况下,emptyDir卷存储在支持该节点所使用的存储介质上,可以是本地磁盘或网络存储。
emptyDir 也可以通过将emptyDir.medium字段设置为“Memory”来通知Kubernetes为容器安装tmpfs,此时数据被存储在内存中,速度相对于本地存储和网络存储快很多。但是在节点重启的时候,内存数据会被清除;而如果存在磁盘上,则重启后数据依然存在。另外,使用tmpfs的内存也会计入容器的使用内存总量中,受系统的Cgroup限制。 - emptyDir 设计的初衷主要是给应用充当缓存空间,或者存储中间数据,用于快速恢复。然而,这并不是说满足以上需求的用户都被推荐使用emptyDir,我们要根据用户业务的实际特点来判断是否使用emptyDir。因为emptyDir的空间位于系统根盘,被所有容器共享,所以在磁盘的使用率较高时会触发Pod的eviction操作,从而影响业务的稳定。
- 使用emptydir对应的主机 存在存储信息
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir:
半持久化存储
常见的半持久化存储主要是hostPath卷。hostPath卷能将主机节点文件系统上的文件或目录挂载到指定Pod中。对普通用户而言一般不需要这样的卷,但是对很多需要获取节点系统信息的Pod而言,却是非常必要的。
例如,hostPath的用法举例如下:
- 某个Pod需要获取节点上所有Pod的log,可以通过hostPath 访问所有Pod的stdout输出存储目录,例如/var/log/pods路径。
- 某个Pod需要统计系统相关的信息,可以通过hostPath访问系统的/proc目录。
使用hostPath的时候,除设置必需的path属性外,用户还可以有选择性地为hostPath 卷指定类型,支持类型包含目录、字符设备、块设备等。
hostPath注意点
- 使用同一个目录的Pod可能会由于调度到不同的节点,导致目录中的内容有所不同。
- Kubernetes在调度时无法顾及由hostPath使用的资源。
- Pod被删除后,如果没有特别处理,那么hostPath上写的数据会遗留到节点上,占用磁盘空间(pod的生命周期与hostPath是解耦的)。
持久化存储(StorageClass、PV、PVC)
支持持久化的存储是所有分布式系统所必备的特性。针对持久化存储,Kubernetes引入了 StorageClass、Volume、PVC(Persistent Volume Claim)、PV(Persitent Volume) 的概念,将存储独立于Pod的生命周期来进行管理。
Kuberntes目前支持的持久化存储包含各种主流的块存储和文件存储,譬如awsElasticBlockStore、azureDisk、cinder、NFS、cephfs、iscsi等,在大类上可以将其分为网络存储和本地存储两种类型。
pv.yaml (可用的持久化存储卷)
apiVersion: v1
kind: PersistentVolume
metadata:
name: task-pv-volume
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 100Mi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data"
pvc.yaml (用户需要使用的话需要创建pvc声明去使用哪个存储卷)
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: task-pv-claim
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Mi
pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: task-pv-pod
spec:
volumes:
- name: task-pv-storage
persistentVolumeClaim:
claimName: task-pv-claim
containers:
- name: task-pv-container
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: task-pv-storage
StorageClass
StorageClass 用于指示存储的类型,不同的存储类型可以通过不同的StorageClass来为用户提供服务。
StorageClass主要包含存储插件 provisioner、卷的创建和mount参数等字段。

PVC:由用户创建,代表用户对存储需求的声明,主要包含需要的存储大小、存储卷的访问模式、StroageClass 等类型,其中存储卷的访问模式必须与存储的类型一致
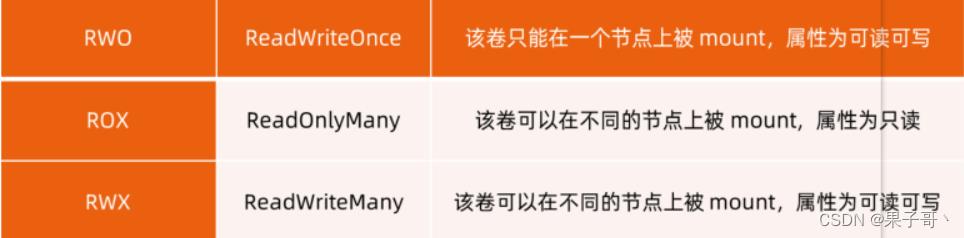
PV:由集群管理员提前创建,或者根据PVC的申请需求动态地创建,它代表系统后端的真实的存储空间,可以称之为卷空间。
存储对象关系
用户通过创建PVC来申请存储。控制器通过PVC的StorageClass和请求的大小声明来存储后端创建卷,进而创建PV,Pod 通过指定PVC来引用存储。

生产实践经验

以上是关于kubernetes(七) Pod 调度的主要内容,如果未能解决你的问题,请参考以下文章
云原生训练营模块七 Kubernetes 控制平面组件:调度器与控制器