kubernetes Pod 调度策略
Posted 地表最强菜鸡
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kubernetes Pod 调度策略相关的知识,希望对你有一定的参考价值。
前言:
在 kubernetes 集群当中,我们很少直接创建一个 pod 来启动应用服务,而是通过控制器来创建 pod 从而运行应用实例,比如: Deployment、DaemonSet、Job 等控制器完成对一组 Pod 副本的创建。在大多数情况下我们使用 Deployment 控制创建 pod 的时候 pod 的副本集会被成功的调度在集群中任意一个可用的节点上运行,而忽略了副本集具体会被调度到那个节点上,但是在真正的生产环境中也会存在一定的需求,比如希望某个 pod 运行在指定的节点上,或者集群资源的利用率过高无法再运行 pod,但是这个 pod 又非常重要必须要运行到节点当中,此时就可以通过 pod 的调度策略来解决以上问题,下面来讲述 kubernetes 中 pod 的几种调度策略;
一、NodeSelector:定向调度
在默认情况下,创建 pod 之后会由 kubectl 发送请求至 kube-ApiServer ,由该接口去将请求转交给 kube-scheduler,并由 scheduler 通过一系列复杂的调度算法来实现自动调度的功能,从而将该 pod 调度到合适的节点上面去,而 NodeSelector 则是通过标签的方式来指定 pod 创建到指定节点上,该机制是通过在指定的 node 节点上设定标签(例如:disk=ssd),在编写 pod 运行的 yaml 文件内设置 NodeSelector 参数来指定该 pod 在那个节点上创建 pod;
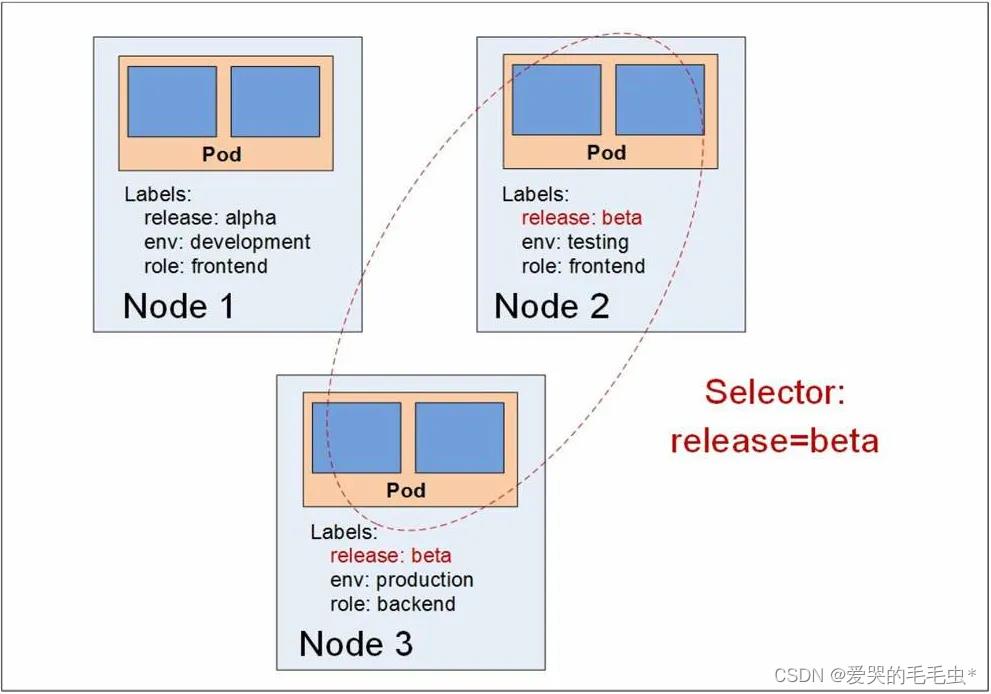
NodeSelector 案例:
首先在 master 节点给需要调度的目标 node 打上 label,并在创建 pod 的 yaml 文件中指定 label 来使得 pod 创建的时候调度到指定标签的 node 节点。
# 首先给指定的 node 节点加上标签
kubectl label nodes kube-node01 disk=ssd
kubectl get nodes kube-node01 --show-labels |grep disk
# 编写 yaml 文件引入标签
[root@kube-master scheduler]# vim nodeLabels-test.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-busybox
spec:
replicas: 1
selector:
matchLabels:
app: busybox
template:
metadata:
labels:
app: busybox
spec:
containers:
- name: busybox
image: busybox
imagePullPolicy: IfNotPresent
nodeSelector: # 定义 nodeSelector 参数
disk: ssd # 引入标签* 查看 node 节点标签

* 查看调度结果

二、NodeAffinity:Node 亲和性调度
NodeAffinity 亲和性调度策略和 NodeSelector 的区别就是 NodeSelector 是强制性的将 pod 调度在指定的 node 节点上,而 NodeAffinity 则是通过设置策略来将满足一定条件的 pod 创建到指定的 node 节点上,如果同时定义里两个调度策略 NodeSelector 和 NodeAffinity 则两个调度策略必须都满足才可以将 pod 创建到满足条件的 node 节点上;
* NodeAffinity 两种调度策略:
1、requiredDuringSchedulingIgnoredDuringExecution:硬策略、必须满足指定的规则才可以调度 Pod 到 Node 上(功能和 NodeSelector 很像,使用的语法不同),相当于硬限制;
2、preferredDuringSchedulingIgnoredDuringExecution:软策略、强调优先满足指定规则,调度器会尝试调度 Pod 到 Node 上,但并不强求相当于软限制,多个优先级可以通过权重值来设置执行的先后顺序;
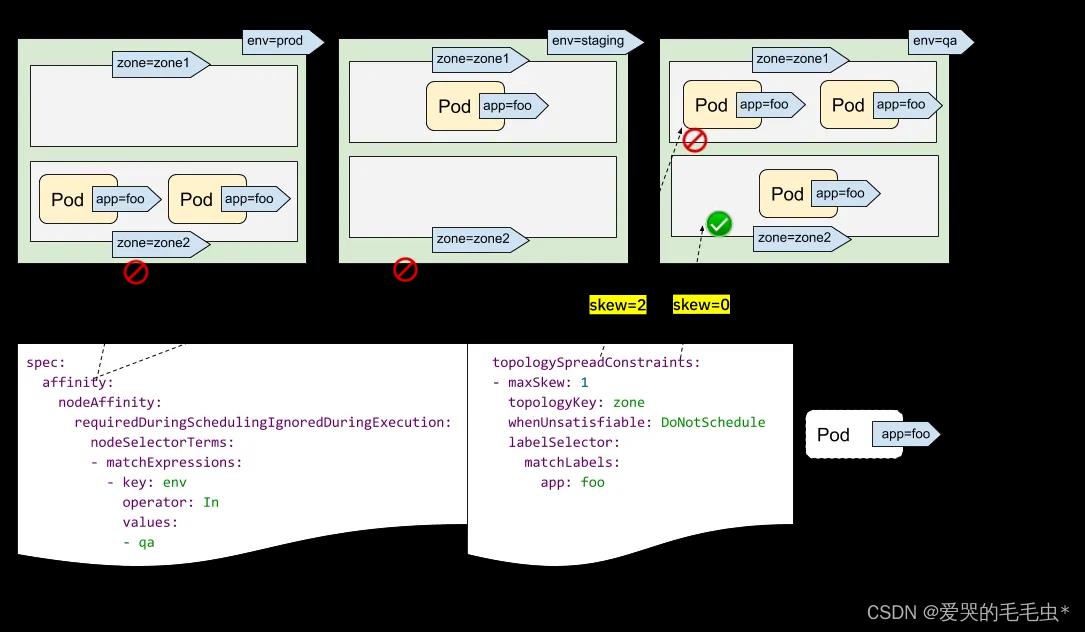
NodeAffinity 案例
还是和 NodeSelector 操作一样,在 master 节点给指定的 node 打上 label ,之后编写创建 pod 的 yaml 当中在策略上指定需要调度的节点;
# 首先给指定的 node 节点加上标签
kubectl label nodes kube-node01 disk-type=ssd
kubectl get nodes kube-node01 --show-labels |grep disk-type
# 编辑 yaml 文件,设置 NodeAffinity 参数;
apiVersion: apps/v1
kind: Deployment
metadata:
name: busybox
spec:
replicas: 1
selector:
matchLabels:
app: busybox
template:
metadata:
labels:
app: busybox
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution: # 设置 node 亲和性硬策略
nodeSelectorTerms: # 设置 node 标签
- matchExpressions: # 定义标签详细信息
- key: beta.kubernetes.io/arch # 指定标签的 key
operator: In # 设置语法为 In,代表是其它语法还有 NotIn、Exists、DoesNotExist、Gt、Lt;
values: # 设置标签对应的 value
- amd64
preferredDuringSchedulingIgnoredDuringExecution: # 设置 node 亲和性软策略
- weight: 1 # 设置权重值为 1
preference: # 定义权重策略
matchExpressions: # 定义 node 标签
- key: disk-type
operator: In
values:
- ssd
containers:
- name: mybusybox
image: busybox
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080* node 节点标签

* 查看运行结果

三、Pod Priority Preemption:Pod 优先级
上述讲解的是 node 节点的亲和性调度通过设置软硬策略来决定 pod 调度到那个节点上运行,而在实际的生产环境中可能会遇到另外一种情况就是 pod 优先级的问题,也就是在大规模的集群当中由于各种原因,需要尽可能的提高集群资源的利用率,保证集群中的资源能够被合理的利用起来,而提高利用率的常规做法就是采用优先级的方法来很好的完善这个问题,比如在一个单 master 和两个 node 集群当中,podA 和 podB 两个 pod ,podB 已经在 node 节点上面运行了,而此时集群中的资源已经满了,两个 node 节点已经无法再扩展新的 pod 在节点上面运行了,此时 podA 在创建的过程中在集群中的状态为 Pending ,需要等待其它 pod 被释放才能够运行。当发生集群资源不足的情况时,系统可以选择释放一些不重要的负载(比如 podB 优先级最低),保障最重要的负载(podA 优先级比较高)能够获取足够的资源稳定运行;
Pod Priority Preemption 调度的策略:
1、驱逐(Eviction):是 kubelet 进程的行为,当 node 节点上面的资源不足时,该节点上的 kubelet 进程会对优先级比较低的 pod 进行驱逐动作,在驱逐的过程中 kubelet 会综合考虑 pod 的优先级、资源申请量、实际使用量等信息来计算那个 pod 需要被驱逐,其中实际使用的资源量超过申请量最大倍数的高耗能 pod 会被首先驱逐。比如:对于 Qos 等级为 "Best Effort" 的 pod 来说,由于没有定义资源申请(CPU/MEM 的 Request),所以它们所使用的资源可能非常大。
2、抢占(Preemption):与 Eviction 不同的是,Preemption 属于 Scheduler 上的操作行为,当 Scheduler 需要调度到集群中的某个节点上面时发生了资源不足的情况,Scheduler 有权决定将优先级比较低的 pod 剔除集群当中,使得优先级高的 pod 在集群中能够稳定运行,需要注意的是,Scheduler 可能会剔除 node A 上面的 pod 从而满足 nodeB 上面的调度任务,原因是两个 node 节点都在同一个机架上运行(机架R),而新调度的 pod 上定义了 anti-affinit 规则(不允许调度在同一个机架上),此时为了满足这个规则 Scheduler 会将不是调度目标的 node 节点上面的 pod 剔除从而满足这个策略;
Preemption 调度流程:
如果发生抢占调度策略,那么高优先级的 pod 就有可能会被调度到指定的节点(比如 N),并将低优先级的 pod 驱逐出 N 节点,此时高优先级的 status 信息中的 nominatedName 字段会记录目标节点 N 的名称。需要注意的是高优先级的 pod 无法保证百分百调度到指定的节点,在低优先级的 pod 被驱逐的过程中可能会出现比目前需要调度的 pod 的优先级更高的 pod 需要被调度,此时就需要等待更高的优先级的 pod 被调度完成之后才会再次开始调度目前的 pod,并且在调度的过程中如果有新节点满足高优先级 pod 的需求,就会把它调度到新的 node 节点上。
Preemption 调度死循环问题:
在一个集群当中假如有两个 scheduler 来对某一批 pod 进行调度,比如 SchedulerA 调度了一批 pod 并清除了某个节点上面低优先级的 pod,然后 SchedulerB 也调度了一批 pod 并且比 SchedulerA 抢先一步调度到了集群当中,当 SchedulerA 在准备调度的时候发现资源已经被占用,此时就会陷入一个调度循环状态,为了避免这个问题的发生,最好的解决办法就是让多个 scheduler 共同协作完成一个调度目标;
Preemption 与 job 任务 pod 问题:
优先级在普通的 pod 执行优先级的剔除是没什么问题的,但是在 job 控制器来运行的 pod 上就是一个灾难,如果 job 控制器运行的任务计划 pod 正在执行任务,此时因为集群节点的资源不够用导致 job 的 pod 被剔除集群节点,从而导致指定运行的任务被搁置,为了解决这个问题,可以在 PriorityClass 中设置属性 preemptionPolicy ,当它的值为 preemptionLowerPriorty(默认)时,则正常执行抢占策略(表示优先级低会被剔除)。如果将值设置为 Never 时则为默认不抢占,不会被剔除而是等待调度机会。
Preemption 策略的弊端:
使用优先级抢占策略可能会导致有些 pod 永远无法被成功调度,因此优先级调度策略不但增加了集群调度的复杂性,还可能会带来额外不稳定的因素。因此,一旦发生资源紧张的局面,首先考虑的应该是能否对集群的节点进行扩容,如果无法扩容再考虑使用优先级调度策略特性,比如基于命名空间的资源配额限制来约束任意优先级的行为。
Pod Priority Preemption 案例
因为本人物理资源有限无法验证该策略的结果,以下是 PodAffinity 的配置;
# 优先级定义
[root@kube-master scheduler]# vim podAffinity-preemption.yaml
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass # 定义优先级策略
metadata:
name: high-priority # 优先级策略的名称
value: 1000000 # 定义优先级,数值越高优先级越高;
globalDefault: false # 表示 PriorityClass 的值应该给那些没有设置 PriorityClassName 的 Pod 使用。
description: "This priority class should be used for wyj service pods only"
# 编辑 deployment 控制器的文件内容
[root@kube-master scheduler]# vim podAffinity-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: busybox
spec:
replicas: 1
selector:
matchLabels:
app: busybox
template:
metadata:
labels:
app: busybox
spec:
priorityClassName: high-priority # 引入优先级策略
containers:
- name: busybox
image: busybox
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80总结:以上是本人总结的部分调度策略,后期会更新 kubernetes 之 pod 调度策略(二),以上调度策略是应用在不同场景下的调度策略,根据公司环境来配置不同的调度策略,其中 NodeSelector 为硬性调度策略,根据标签指定那个节点就调度在指定的节点上,而 NodeAffinity 则是可以根据软硬策略来将 pod 合理的调度到指定的 node 节点上,而 PodAffinity 则是在集群资源不满足 pod 调度的情况下,根据设置的优先级来定义 pod 在集群的 “重要性” ,从而将优先级比较低的 pod 剔除集群,让优先级高(重要)的 pod 能够在集群中稳定运行,以上就是个人总结感谢各位大佬点赞关注。
以上是关于kubernetes Pod 调度策略的主要内容,如果未能解决你的问题,请参考以下文章