优达学城深度学习之三(下)——卷积神经网络
Posted 小小谢先生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了优达学城深度学习之三(下)——卷积神经网络相关的知识,希望对你有一定的参考价值。
一、One—Hot编码
计算机在表示多结果的分类时,使用One-Hot编码是比较常见的处理方式。即每个对象都有对应的列。

二、最大似然率
下面是两幅图像,比较两幅图像,试通过概率的方法来讨论一下为什么右边的模型会更好。

假设第一幅图像的每个点是对应颜色的概率为下图:

如果假设点的颜色是相互独立的,则整个图表的概率为相互乘积:0.6*0.1*0.7*0.2=0.0084,低于1%
第二个图概率如下图所示:

则整个图表的概率为相互乘积:0.6*0.8*0.9*0.7=0.3024约等于30%。由此可知,右边的模型更靠谱。

如果我们可以通过一种方式最大化这个概率,则这种方法叫最大似然法。
三、最大化概率
3.1 交叉熵1:损失函数

对他们每个点的概率进行对数运算,然把他们的相反数进行求和,我们称之为交叉熵。好的模型交叉熵比较低,坏的模型交叉熵会比较高。如下图的两个模型。

我们遇到了某种规律,概率和误差函数之间肯定有一定的联系,这种联系叫做交叉熵。这个概念在很多领域都非常流行,包括机器学习领域。下图表示三个门后面有礼物的概率,分别为0.8、0.7、0.1,当后面有礼物时,yi=1,所以交叉熵如下图所示:

代码实现:
import numpy as np
# Write a function that takes as input two lists Y, P,
# and returns the float corresponding to their cross-entropy.
def cross_entropy(Y, P):
Y=np.float_(Y)
P=np.float_(P)
return -np.sum(Y * np.log(P) + (1 - Y) * np.log(1 - P))四、多类别交叉熵
由单个类推出多种类别,假设每个门后面有三种不同的生物,概率不一样,则每种动物的概率和交叉熵如下图所示:



则 Cross-Entropy = ∑ ∑ [ yij ln(Pij) ] ( i = 1, 2, 3 ... n ) ( j = 1, 2, 3 ...m ) = ∑ [ y1j ln(P1j) + y2j ln(P2j) + ..... yij ln(Pij) ] 且 ( P1j + P2j + P3j + ......Pij = 1 )
五、logistic回归
现在,我们终于要讲解机器学习中最热门和最有用的算法之一,它也是所有机器学习的基石——对数几率回归算法。基本上是这样的:
- 获得数据
- 选择一个随机模型
- 计算误差
- 最小化误差,获得更好模型
- 完成
计算随机误差

备注:图片中的 log 应全为 ln。

最小化误差函数:梯度下降法

误差函数为△E。
在上几个视频中,我们了解到为了最小化误差函数,我们需要获得一些导数。我们开始计算误差函数的导数吧。首先要注意的是 s 型函数具有很完美的导数。即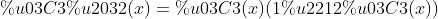
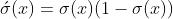
梯度运算如下图:



以上是关于优达学城深度学习之三(下)——卷积神经网络的主要内容,如果未能解决你的问题,请参考以下文章