从入门到上手:什么是K8S持久卷?
Posted RancherLabs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从入门到上手:什么是K8S持久卷?相关的知识,希望对你有一定的参考价值。

本文是介绍Kubernetes的基本概念的系列文章之一, 在第一篇文章中,我们简单介绍了持久卷(Persistent Volumes)。在本文中,我们将学习如何设置数据持久性,并将编写Kubernetes脚本以将我们的Pod连接到持久卷。在此示例中,将使用Azure文件存储(Azure File Storage)来存储来自我们MongoDB数据库的数据,但您可以使用任何类型的卷来实现相同的结果(例如Azure Disk,GCE持久磁盘,AWS弹性块存储等)。
如果你想全面了解K8S其他概念的话,可以先查看此前发布的文章。
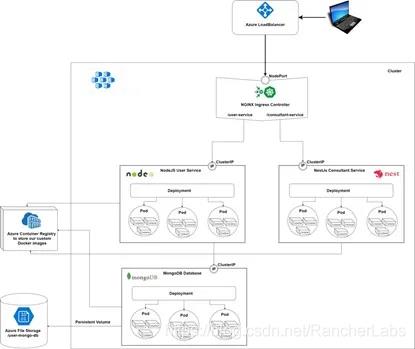
请注意:本文提供的脚本不限定于某个平台,因此您可以使用其他类型的云提供商或使用具有K3S的本地集群实践本教程。本文建议使用K3S,因为它非常轻,所有的依赖项被打包在单个二进制中包装大小小于100MB。它也是一种高可用的认证的Kubernetes发行版,用于在资源受限环境中的生产工作负载。想了解更多信息,请查看官方文档:
前期准备
在开始本教程之前,请确保已安装Docker。同时安装Kubectl(如果没有,请访问以下链接安装:
https://kubernetes.io/docs/tasks/tools/#install-kubectl-on-windows
在kubectl Cheat Sheet.中可以找到整个本教程中使用的kubectl命令:
https://kubernetes.io/docs/reference/kubectl/cheatsheet/
本教程中,我们将使用Visual Studio Code,您也可以使用其他的编辑器。
Kubernetes持久卷可以解决什么问题?
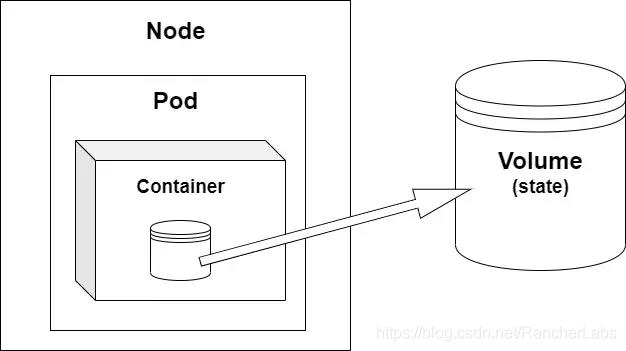
请记住,我们有一个节点(硬件设备或虚拟机)和在节点内部,我们有一个Pod(或多个Pod),在Pod中,我们有容器。Pod的状态是暂时的,所以他们神出鬼没(时常会被删除或重新调度等)。在这种情况下,如果你想在Pod被删除之后已经保存其中的数据,你需要数据移动到Pod外部。这样它就可以独立于任何Pod存在。此外部位置称为卷,它是存储系统的抽象。使用卷,您可以在多个Pod保持持久化状态。
什么时候使用持久卷
当容器开始被广泛应用时,它们旨在支持无状态工作负载,其持久性数据存储在其他地方。从那时起,人们做了很多努力以支持容器生态系统中的有状态应用。
每个项目都需要某种数据持久性,因此,您通常需要一个数据库来存储数据。但在简洁的设计中,你不想依赖具体的实现;您想写一个尽可能可以重复使用和独立于平台的应用程序。
一直以来,始终需要向应用程序隐藏存储实现的详细信息。但现在,在云原生应用的时代,云提供商创建了的环境中,想要访问数据的应用程序或用户需要与特定存储系统集成。例如,许多应用程序直接使用特定存储系统,诸如Amazon S3、AzureFile或块存储等,这造成了不健康的依赖。Kubernetes正在尝试通过创建一个名为持久卷的抽象来改变这一情况,它允许云原生应用程序连接到各种云存储系统,而无需与这些系统建立明确的依赖关系。这可以使云存储的消耗更加无缝和消除集成成本。它还可以更容易地迁移云并采用多云策略。
即使有时候,由于金钱,时间或人力等客观条件的限制,你需要做出一些妥协,将你的应用程序与特定的平台或提供商直接耦合,您应该尽量避免尽可能多的直接依赖项。从实际数据库实现中解耦应用程序的一种方法(还有其他解决方案,但这些解决方案更加复杂)是使用容器(和持久卷来防止数据丢失)。这样,您的应用程序将依赖于抽象而不是特定实现。
现在真正的问题是,我们是否应该总是使用带有持久性卷的容器化数据库,或者哪些存储系统类型不应该在容器中使用?
何时使用持久卷并没有通用的黄金法则,但作为起点,您应该考虑可扩展性和集群中节点丢失的处理。
根据可扩展性,我们可以有两种类型的存储系统:
- 垂直伸缩——包括传统的RDMS解决方案,例如mysql、PostgreSQL以及SQL Server
- 水平伸缩——包括“NoSQL”解决方案,例如ElasticSearch或基于Hadoop的解决方案
像MySQL、Postgres、Microsoft SQL等垂直伸缩的解决方案不应进入容器。这些数据库平台需要高I / O、共享磁盘、块存储等,并且不能优雅地处理集群中的节点丢失,这通常发生在基于容器的生态系统中。
对于水平伸缩的应用程序(Elastic、Cassandra、Kafka等),您应该使用容器,因为它们可以承受数据库集群中的节点丢失,并且数据库应用程序可以独立地再平衡。
通常,您可以并且应该分布式数据库容器化,这些数据库使用冗余存储技术,可以承受数据库集群中的节点丢失(Elasticsearch是一个非常好的例子)。
Kubernetes持久卷的类型
我们可以根据其生命周期和配置方式对Kubernetes卷进行分类。
考虑到卷的生命周期,我们可以分为:
- 临时卷,即与节点的生命周期紧密耦合(例如ExpertDir或HostPath),如果节点倒闭,则删除它们的截阵数量。
- 持久卷,即长期存储,并且与Ppd或节点生命周期无关。这些可以是云卷(如gcePersistentDisk、awselasticBlockStore、AzureFile或AzureDisk),NFS(网络文件系统)或Persistent
Volume Claim(一系列抽象来连接到底层云提供存储卷)。
根据卷的配置方式,我们可以分为:
-
直接访问
-
静态配置
- 动态配置
直接访问持久卷
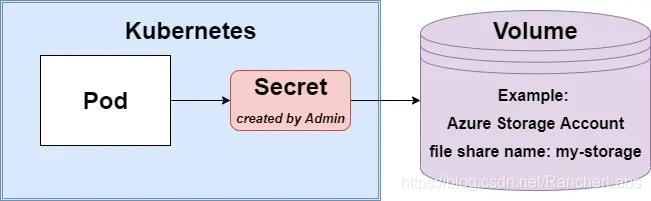
在这种情况下,Pod将直接与Volume耦合,因此它将知道存储系统(例如,Pod将与Azure存储帐户耦合)。该解决方案与云无关,它取决于具体实施而不是抽象。因此,如果可能的话尽量避免这样的解决方案。它唯一的优点是速度快,在Pod中创建Secret,并指定应使用的Secret和确切的存储类型。
创建Secret脚本如下:
apiVersion: v1
kind: Secret
metadata:
name: static-persistence-secret
type: Opaque
data:
azurestorageaccountname: "base64StorageAccountName"
azurestorageaccountkey: "base64StorageAccountKey"在任何Kubernetes脚本中,在第2行我们指定了资源的类型。在这种情况下,我们称之为Secret。在第4行,我们给它一个名字(我们称之为静态,因为它是由管理员手动创建的,而不是自动生成的)。从Kubernetes的角度来看,Opaque类型意味着该Secret的内容(数据)是非结构化的(它可以包含任意键值对)。要了解有关Kubernetes Secrets的更多信息,可以参阅Secrets Design Document和ConfigureKubernetes Secrets。
https://github.com/kubernetes/community/blob/master/contributors/design-proposals/auth/secrets.md
https://kubernetes.io/docs/concepts/configuration/secret/
在数据部分中,我们必须指定帐户名称(在Azure中,它是存储帐户的名称)和Access键(在Azure中,选择存储帐户下的“Settings ”,Access key)。别忘了两者应该使用Base64进行编码。
下一步是修改我们的Deployment脚本以使用卷(在这种情况下,卷是Azure File Storage)。
apiVersion: apps/v1
kind: Deployment
metadata:
name: user-db-deployment
spec:
selector:
matchLabels:
app: user-db-app
replicas: 1
template:
metadata:
labels:
app: user-db-app
spec:
containers:
- name: mongo
image: mongo:3.6.4
command:
- mongod
- "--bind_ip_all"
- "--directoryperdb"
ports:
- containerPort: 27017
volumeMounts:
- name: data
mountPath: /data/db
resources:
limits:
memory: "256Mi"
cpu: "500m"
volumes:
- name: data
azureFile:
secretName: static-persistence-secret
shareName: user-mongo-db
readOnly: false我们可以发现,唯一的区别是,从第32行我们指定了使用的卷,给它一个名称并指定底层存储系统的确切详细信息。secretName必须是先前创建的Secret的名称。
Kubernetes存储类
要了解静态或动态配置,首先我们必须了解Kubernetes存储类。
通过StorageClass,管理员可以提供关于可用存储的配置文件或“类”。不同的类可能映射到不同服务质量级别,或备份策略或由集群管理员确定的任意策略。
例如,你可以有一个在HDD上存储数据的配置文件,命名为慢速存储,或一个在SSD上存储数据的配置文件,命名为快速存储。这些存储的类型由供应者确定。对于Azure,有两种提供者:AzureFile和AzureDisk(区别在于AzureFile可以与Read Wriite Many访问模式一起使用,而AzureDisk只支持Read Write Once访问,当您希望同时使用多个Pod时,这可能是不利因素)。您可以在此处了解有关不同类型的Storage Classes:
https://kubernetes.io/docs/concepts/storage/storage-classes/
以下是Storage Class的脚本:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: azurefilestorage
provisioner: kubernetes.io/azure-file
parameters:
storageAccount: storageaccountname
reclaimPolicy: Retain
allowVolumeExpansion: trueKubernetes预定义提供者属性的值(请参阅Kubernetes存储类)。保留回收策略意味着在我们删除PVC和PV之后,未清除实际存储介质。我们可以将其设置为删除和使用此设置,一旦删除PVC,它也会触发相应的PV以及实际存储介质(此处实际存储是Azure文件存储)的删除。
持久卷及Persistent Volume Claim
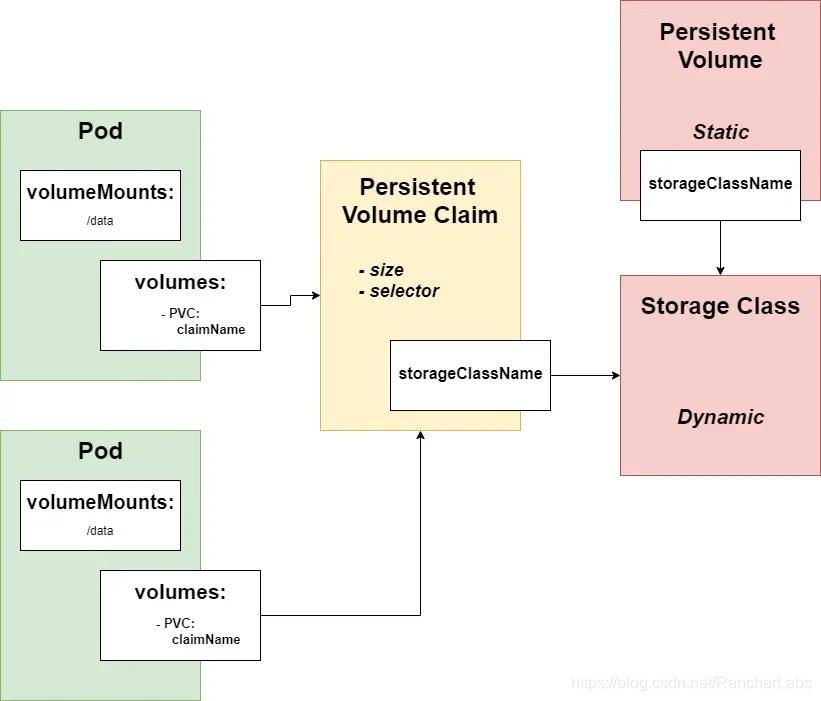
Kubernetes对每一个传统的存储操作活动(供应/配置/附加)都有一个匹配的原语。持久卷是供应,存储类正在配置,并且持久卷Claim是附加的。
来自初始文档:
Persistent Volume(PV)是集群中的存储,它已由管理员配置或使用存储类动态配置。
Persistent Volume Claim(PVC)是用户存储的请求。它类似于Pod。Pod消耗节点资源与PVC消耗PV资源是类似的。Pod可以请求特定的资源级别(CPU和内存)。Claim可以请求特定的大小和访问模式(例如,它们可以安装一次读/写或多次只读)。
这意味着管理员将创建持久卷以指定Pod可以使用的存储大小、访问模式和存储类型。开发人员将创建Persistent Volume Claim,要求提供一个卷、访问权限和存储类型。这样一来,在“开发侧”和“运维侧”之间就有了明显的区分。开发人员负责要求必要的卷(PVC),运维人员负责准备和配置要求的卷(PV)。
静态和动态配置之间的差异是,如果没有持久卷和管理员手动创建的Secret,Kubernetes将尝试自动创建这些资源。
动态配置
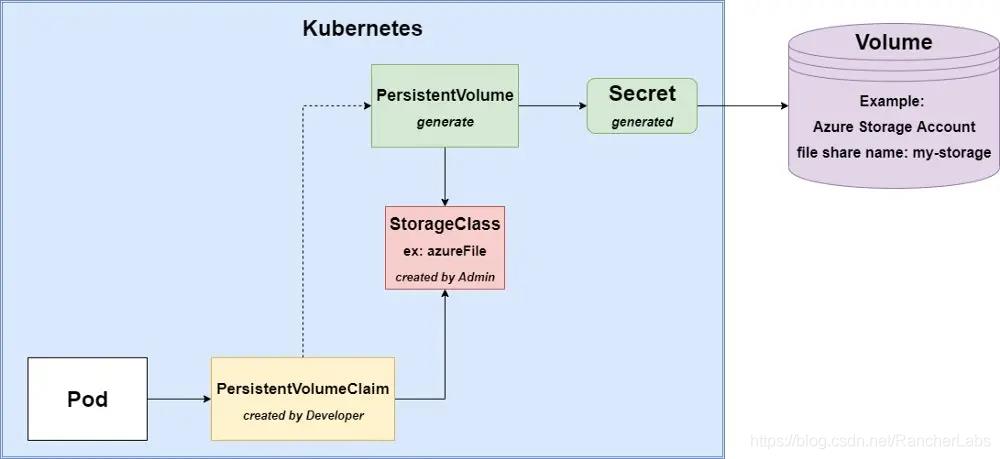
在这种情况下,没有手动创建的持久卷和Secret,因此Kubernetes将尝试生成它们。Storage Class是必要的,我们将使用在前文中创建的Storage Class。
PersistentVolumeClaim的脚本如下所示:
apiVersion: v1
kind:Persistent Volume Claim
metadata:
name: persistent-volume-claim-mongo
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
storageClassName: azurefilestorage以及我们更新的Deployment脚本:
apiVersion: apps/v1
kind: Deployment
metadata:
name: user-db-deployment
spec:
selector:
matchLabels:
app: user-db-app
replicas: 1
template:
metadata:
labels:
app: user-db-app
spec:
containers:
- name: mongo
image: mongo:3.6.4
command:
- mongod
- "--bind_ip_all"
- "--directoryperdb"
ports:
- containerPort: 27017
volumeMounts:
- name: data
mountPath: /data/db
resources:
limits:
memory: "256Mi"
cpu: "500m"
volumes:
- name: data
Persistent Volume Claim:
claimName: persistent-volume-claim-mongo如你所见,在第34行中,我们通过名称引用了先前创建的PVC。在这种情况下,我们没有手动为它创建持久卷或Secret,因此它将自动创建。
这种方法的最重要的优势是您不必手动创建PV和Secret,而且Deployment是与云无关的。存储的底层细节不存在于Pod的spec中。但是也有一些缺点:您无法配置存储帐户或文件共享,因为它们是自动生成的,并且您无法重复使用PV或Secret ——它们将为每个新Claim重新生成。
静态配置
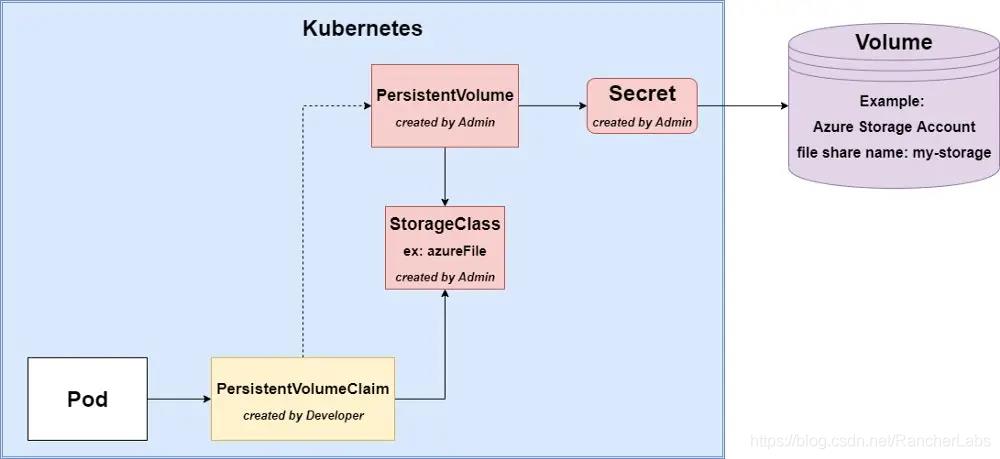
静态和动态配置之间的唯一区别是我们手动创建静态配置中的持久卷和Secret。这样,我们就可以完全控制在集群中创建的资源。
持久卷脚本如下:
apiVersion: v1
kind: PersistentVolume
metadata:
name: static-persistent-volume-mongo
labels:
storage: azurefile
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteMany
storageClassName: azurefilestorage
azureFile:
secretName: static-persistence-secret
shareName: user-mongo-db
readOnly: false重要的是,在第12行我们按名称引用Storage Class。此外,在第14行我们引用了Secret,用于访问底层存储系统。
本文更推荐这个解决方案,即使它需要更多的工作,但它是与云无关的(cloud-agnostic)。它还允许您应用有关角色(集群管理员与开发人员)的关注点分离,并让您控制命名和创建资源。
总结
在本文中,我们了解了如何使用Volume持久化数据和状态,并提出了三种不同的方法来设置系统,即为直接访问、动态配置和静态配置,并讨论了每个系统的优缺点。
以上是关于从入门到上手:什么是K8S持久卷?的主要内容,如果未能解决你的问题,请参考以下文章