Kafka基础整理
Posted 恒哥~Bingo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka基础整理相关的知识,希望对你有一定的参考价值。
Kafka基本概念
Apache Kafka 是一个分布式发布 - 订阅消息系统和一个强大的消息队列,可以处理大量的数据,并使你能够将消息从一个端点传递到另一个端点。 Kafka 适合离线和在线消息消费。 Kafka 消息保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka 构建在 Zookeeper 同步服务之上。 它与 Apache Storm 和 Spark 非常好地集成,用于实时流式数据分析。
Kafka 是一个分布式消息队列,具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。一般在架构设计中起到解耦、削峰、异步处理的作用。
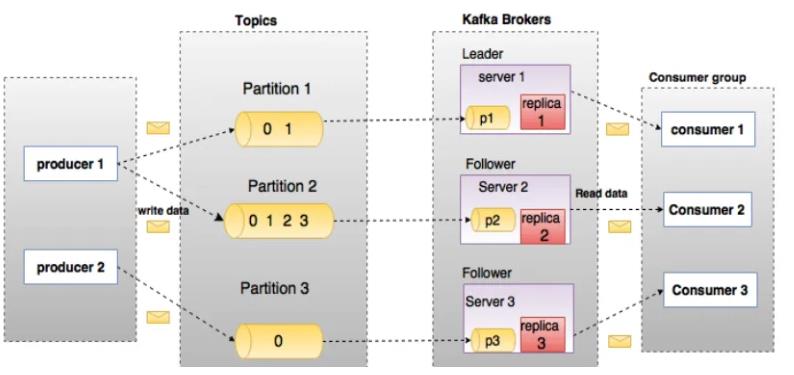
相关术语
-
Broker
Kafka集群包含多个服务器,每个服务器节点就叫Broker
-
Topic
Kafka消息分为不同的主题,按主题分开投递和处理
-
Partition
每个Topic将数据分为1个或N个分区来存储
-
Producer
消息生产者,负责投递消息
-
Consumer
消息消费者,负责接收消息
-
Consumer Group
消费者组,每个消费者属于特定的组
-
Leader
Kafka集群中会选取一个Broker,负责写数据,然后广播同步给其他Broker,挂掉后会重新选举
-
Follower
跟随Leader,负责读数据,Leader的数据会同步给Follower
-
Replica
Broker的副本,当前Broker挂掉后可以代替
Kafka安装和配置
1)下载kafka
https://kafka.apache.org/downloads
本例使用的版本是:kafka_2.11-2.4.1.tgz
2) 解压并修改目录
tar -xvf kafka_2.11-2.4.1.tgz
mv kafka_2.11-2.4.1 kafka
3) 配置
修改server.properties关键配置、其他的保持默认:
# 监听本机的9092端口
listeners=PLAINTEXT://:9092
# zk的ip和端口
zookeeper.connect=localhost:2181
4) 启动kafka
需要先启动zookeeper,kafka提供了内置的zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
执行bin目录中的脚本
bin/kafka-server-start.sh config/server.properties
如果出现Not enough space是因为堆内存不足,可以修改kafka-server-start.sh脚本,将"-Xmx1G -Xms1G"改为"-Xmx512M -Xms512M"

需要后台执行可以加入-daemon命令
bin/kafka-server-start.sh -daemon config/server.properties
日志在logs/server.log中查看
5) 停止kafka
bin/kafka-server-stop.sh config/server.properties
Kafka的基本使用
执行bin目录中的脚本
1) 创建主题
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
- –create 创建topic
- –zookeeper zk的地址
- –replication-factor 副本数,默认是1
- –partitions 分区数
- –topic 主题名称
2) 查看主题
bin/kafka-topics.sh --list --zookeeper localhost:2181
3) 发送消息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
4) 消费消息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
SpringBoot整合Kafka
1) 修改kafka配置
# 允许外部IP连接
listeners=PLAINTEXT://0.0.0.0:9092
# 为外部提供服务的代理地址,就是当前服务的IP
advertised.listeners=PLAINTEXT://192.168.7.188:9092
2) 重新启动Kafka
3) 创建SpringBoot项目
4) 添加依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
5) 配置文件
# Kafka集群地址
spring.kafka.bootstrap-servers=192.168.7.188:9092
# 生产者配置
# 重试次数
spring.kafka.producer.retries=0
# 批量大小
spring.kafka.producer.batch-size=16384
# 提交延时
spring.kafka.producer.properties.linger.ms=0
# 生产端缓冲区大小
spring.kafka.producer.buffer-memory = 33554432
# Kafka提供的序列化和反序列化类
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# 消费者配置
# 默认的消费组ID
spring.kafka.consumer.group-id=0
# 是否自动提交offset
spring.kafka.consumer.enable-auto-commit=true
spring.kafka.consumer.auto-offset-reset=earliest
spring.kafka.consumer.auto-commit-interval=100
# 设置获取一次数据的最大值,默认值为1M
spring.kafka.consumer.properties.max.partition.fetch.bytes=2097152
# Kafka提供的序列化和反序列化类
spring.kafka.consumer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.consumer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
参考官网的kafka配置:
https://docs.spring.io/spring-boot/docs/2.0.4.RELEASE/reference/htmlsingle/#common-application-properties
6) 配置类
@Configuration
public class KafkaConfig
/**
* 新建Topic,主题名、分区数,副本数
*/
@Bean
public NewTopic newTopic()
return new NewTopic("hello-topic",1, (short) 1);
7) 生产者
@RestController
public class KafkaProducerController
@Autowired
private KafkaTemplate<String,Object> kafkaTemplate;
@RequestMapping("/kafka/sendMessage")
public String sendMessage(String msg)
kafkaTemplate.send("hello-topic",msg);
return "发送成功:" + msg;
8) 消费者
@Component
public class KafkaMessageConsumer
@KafkaListener(topics = "hello-topic")
public void consumeMessage(ConsumerRecord<?,?> record)
System.out.println("Get Message:" + record.value());
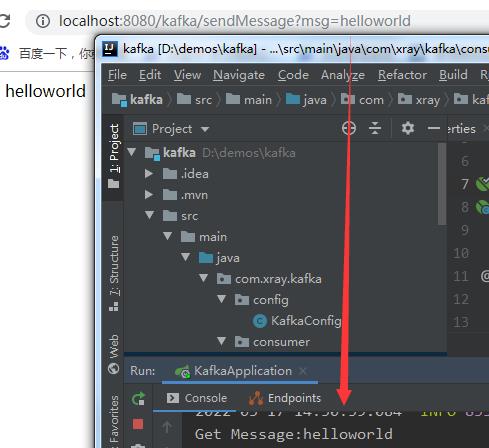
9) 浏览器测试
以上是关于Kafka基础整理的主要内容,如果未能解决你的问题,请参考以下文章